







目录
什么是 Transformer
Transformer是第一个完全采用self-attention机制,对序列输入数据(eg:自然语言)各部分的重要性进行差分加权,从而得到序列输出的转换模型。由Google Brain团队推出,现在已经成为了NLP领域的首选模型。
论文地址:https://arxiv.org/pdf/1706.03762.pdf
论文翻译:Transformer论文翻译_tomeasure的博客-优快云博客_transformer论文翻译
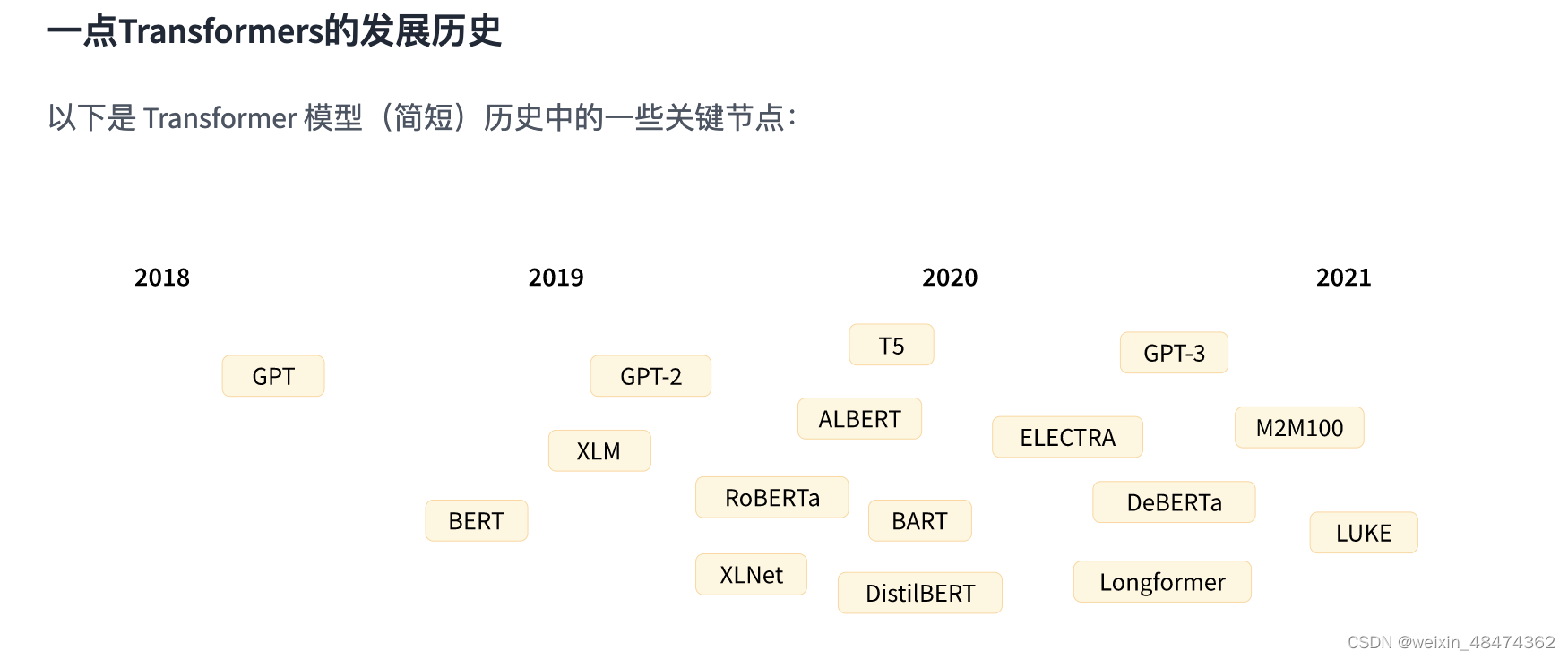
(图片来自:Transformers 是如何工作的? - Hugging Face Course)
Transformer结构理解
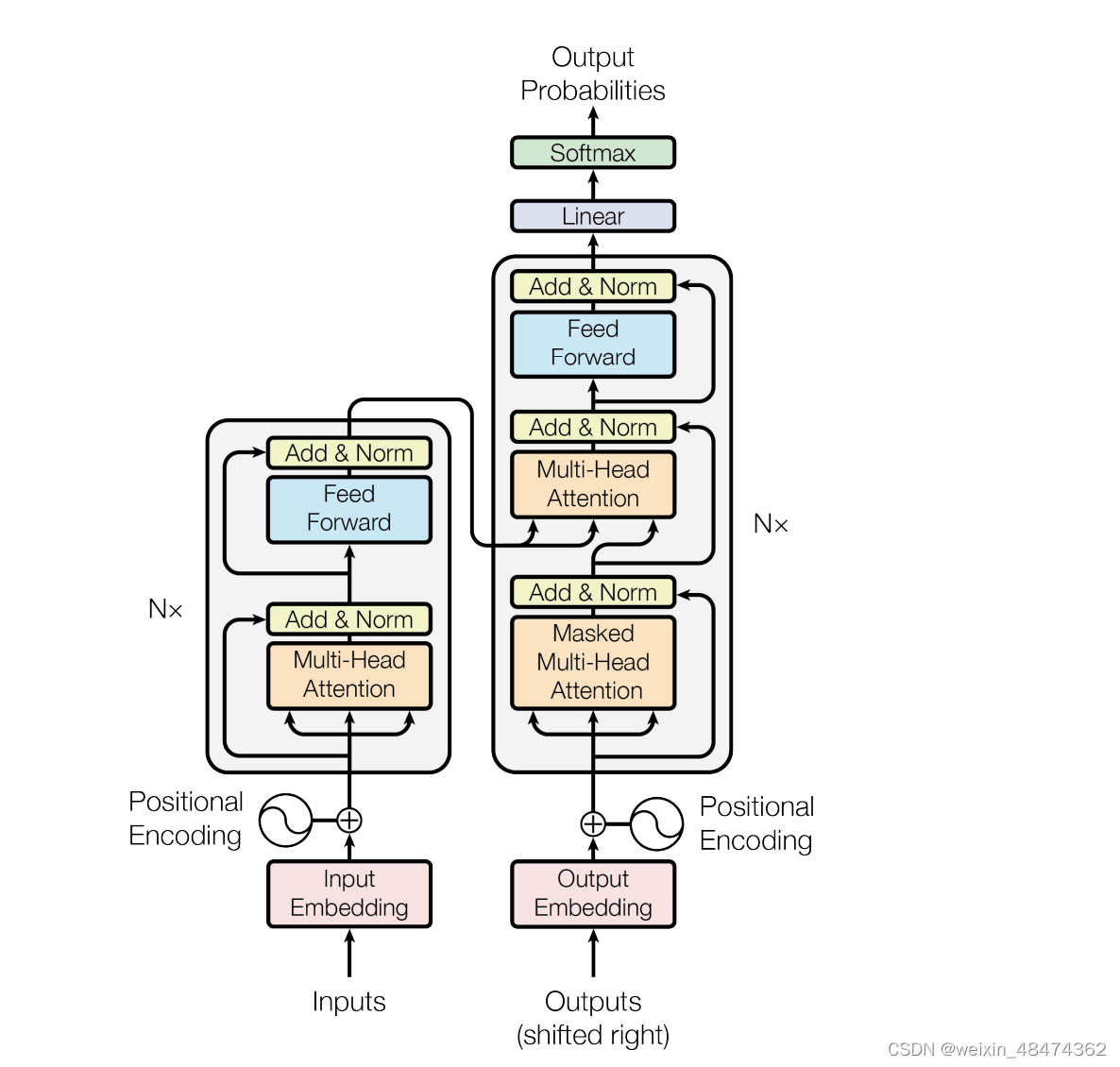
(图片来自论文)
Transformer结构
可以看成两个部分:左边“inputs”一列为编码器(encoder),右边“output”一列为解码器。论文里设置了N=6,也就是左边有6个堆叠起来的编码器,右边有6个堆叠起来的解码器。
编码器的细节:
编码器有三部分组成:
- Multi-Head Attention (包括self-attention)
- Add&Norm (Add指attention的输入和输出相加)
- Feed Forward
解码器的细节:
- Masked Multi-Head Self-Attention
- Multi-Head Encoder-Decoder Attention
- FeedForward Network
- Add&Norm
Transformer大致流程:
- 将 input:“I am a student” (4个单词),output:“<start>我是一个学生”,都进行Embedding
- 让Embedding的input经过左边6层编码器得到一个带有所有input信息的矩阵A (n x 512), (这里n是4,4个单词)
- 把A传到右边编码器中,从Embedding的output的第一个字开始输入,A 和 <start>一起经过6层解码器和Linear,softmax得到第一个翻译:我
- 把 A 和 [<start>,我]一起经过6层解码器和Linear,softmax得到第二个翻译:是
- 把 A 和 [<start>,我,是]一起经过6层解码器和Linear,softmax得到第三个翻译:一个
- 把 A 和 [<start>,我,是,一个]一起经过6层解码器和Linear,softmax得到第三个翻译:学生
Transformer的优点
- RNN不能并行计算,Transformer模型能够一次性处理所有输入数据,并以此减少训练时间,允许其在更大的数据集上进行训练。
- 注意力机制可以为输入序列中的任意位置提供上下文。
- 自注意力可以产生更具可解释性的模型。
- 相比 CNN,计算两个位置之间的关联所需的操作次数不随距离增长。
Transformer模型已在TensorFlow、PyTorch等标准深度学习框架中实现。
Transformers是由Hugging Face制作的一个库,提供基于Transformer的架构和预训练模型。它的目标是提供一个API,通过它可以加载、训练和保存任何Transformer模型[1]


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









