






 文章介绍了DD3D,一种结合深度预训练优势的端到端单阶段3D目标检测器,旨在解决伪激光雷达方法的过拟合和复杂性问题。DD3D在无须额外深度微调的情况下,通过深度估计和3D检测之间的信息传输实现性能提升,在KITTI-3D和NuScenes基准测试中取得最新结果。
文章介绍了DD3D,一种结合深度预训练优势的端到端单阶段3D目标检测器,旨在解决伪激光雷达方法的过拟合和复杂性问题。DD3D在无须额外深度微调的情况下,通过深度估计和3D检测之间的信息传输实现性能提升,在KITTI-3D和NuScenes基准测试中取得最新结果。
BEV感知火了很久了,最近才有时间开始调研这个方向。(有点晚了
打算根据TPAMI的一篇综述开始缕清BEV感知的进化过程。所以开一个小坑。
Abstract
之前的问题
在单目3D目标检测方面,最近的进展是利用单目深度估计作为产生3D点云的一种方式,将相机变成伪激光雷达传感器。这些两阶段检测器随着中间深度估计网络的准确性而提高,中间深度估计网络本身可以通过大规模自监督学习而无需手动标记而得到改进。然而,与端到端方法相比,它们往往存在过拟合的问题,而且更复杂,与类似的基于激光雷达的探测器之间的差距仍然很大。
创新点
在本文呢中,我们提出了一种端到端、单阶段、单目3D目标检测器DD3D,它可以受益于像伪激光雷达方法那样的深度预训练,但没有它们的局限性。
我们的架构是为深度估计和3D检测之间的有效信息传输而设计的,允许我们根据未标记的预训练数据量进行扩展。
我们的方法在两个具有挑战性的基准上取得了最新的结果,在KITTI-3D上,汽车和行人的AP分别为16.34%和9.28%,在NuScenes上,mAP为41.5%。
Introduction
motivation
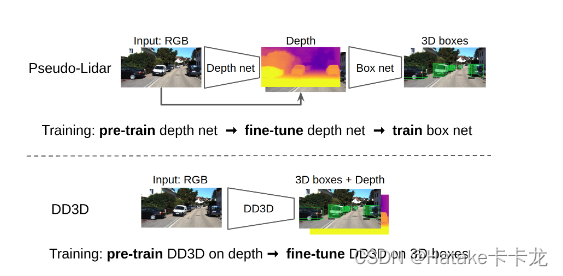

图1: 我们介绍了一种单阶段3D目标探测器DD3D,它结合了伪激光雷达方法(深度预训练缩放)和端到端方法(简单性和泛化性能)的优点。与伪激光雷达方法相比,我们的检测器具有深度预训练和检测微调的简单训练协议,而伪激光雷达方法需要额外的深度微调步骤并且倾向于深度误差过拟合。
单目三维目标检测的本质就是从一张图片上估计出确实的三维信息,先前的方法(图1上)将预训练好的深度估计算法加入到网络中,形成了两阶段算法(非端到端训练)。这种做法容易产生过拟合,以及domain gap。
作者提出了一个端到端的单阶段解决办法。同时能检测也能做深度预测。

Method
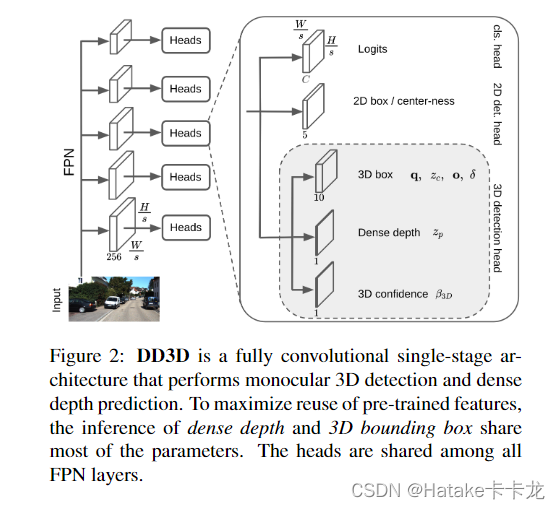
利用大规模数据集的深度预测任务来做DD3D的预训练模型,加载进来后再将两个监督(KITTI中的深度预测和3D检测)同时加入模型。
实验
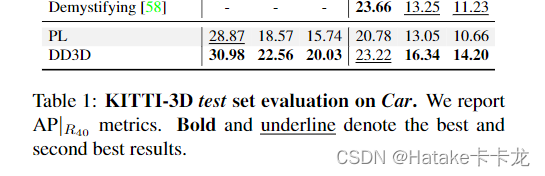
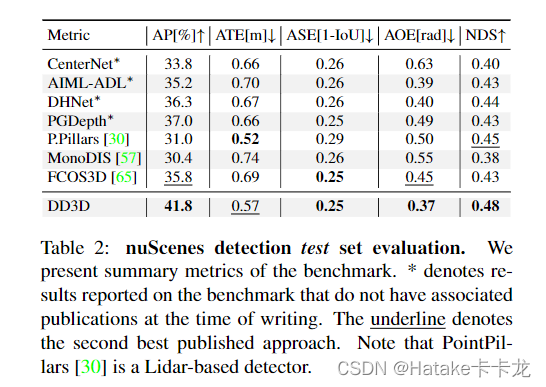
个人总结
一个两任务的目标检测器,故事主要讲的是可以利用预训练的深度预测网络来检测,和检测共享参数训练,解决以前只做预训练不fine-tune的中过拟合和domain gap问题。刷了SOTA(不太熟悉KITTI单目,nuScenes上的mono检测SOTA是mAP62.4了)。
没有看的很详细,和BEV感知没什么关系,算是BEV感知的砖块之一吧。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









