







案例:泰坦尼克生存预测,数据来源于Kaggle官网
看了关于这个案例的好多代码,慢慢感觉数据处理和特征筛选的过程太重要了,一个模型可以有千百种结果,完全取决于前期数据处理过程。
###########################################################################
1、导入框架
下面的三个文件就是从Kaggle下载的data文件
import pandas as pd
train = pd.read_csv('C:/Python-Project/决策树/Titanic Survived data/train.csv')
test_x = pd.read_csv('C:/Python-Project/决策树/Titanic Survived data/test.csv')
test_y = pd.read_csv('C:/Python-Project/决策树/Titanic Survived data/gender_submission.csv')2、观察数据
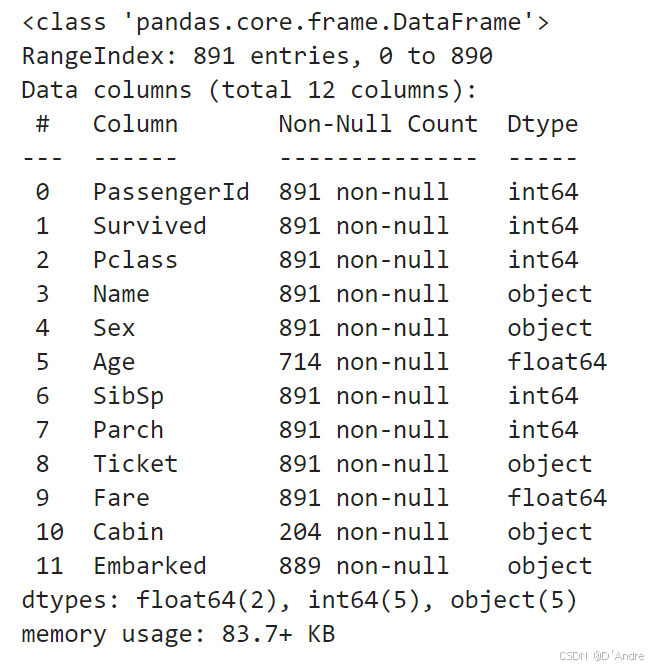
train.info()从这个案例学会了对导入数据的初步观察,为什么要观察?是为了观察数据中有没有缺失值和处理掉对结果没有意义的特征。train.info()会呈现如下信息:
a,总共有891列数据。
b,其中AgeCabin列数据有缺失。
3、对object类型数据处理
此类数据要转换成整型或者浮点型数据,否则无法在训练时被有效识别,用到了一个方法LabelEncoder
- 编码分类数据:
LabelEncoder的核心功能是将文本形式的分类数据,比如字符串类型的类别,转换为整数编码。它为每个唯一的类别分配一个从 0 开始的连续整数。这种转换对于许多机器学习算法至关重要,因为大多数算法要求输入数据是数值形式。例如,在一个预测客户购买行为的模型中,客户的性别(“男”,“女”)、地区(“北京”,“上海”,“广州” 等)等分类特征,就需要先转换为数值才能被模型处理。
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
train['Sex'] = le.fit_transform(train['Sex'])
test_x['Sex'] = le.fit_transform(test_x['Sex'])4、对缺失数据进行处理
上面已经有所描述,Age列的数据只有714行,所以就是有177列数据是缺失的,所以要对这些缺失的数据进行处理。
train['Age'] = train['Age'].fillna(train['Age'].mean())
# train.Age.fillna(train.Age.mean(),inplace = True)
test_x['Age'] = test_x['Age'].fillna(train['Age'].mean())
# test_x.Age.fillna(test_x.Age.mean(),inplace = True)-
train['Age'].mean():-
这部分代码计算
train数据集中Age列的均值。mean()是pandas中用于计算均值的方法。在DataFrame的列(Series对象)上调用该方法时,它会忽略缺失值并返回该列数值的平均值。例如,如果Age列包含[25, 30, NaN, 35],mean()方法会计算(25 + 30 + 35) / 3的结果。
-
-
train['Age'].fillna(...):-
fillna()是pandas中用于填充缺失值的方法。这里它使用前面计算出的均值来填充Age列中的缺失值。fillna()方法会返回一个新的Series对象,其中缺失值已被指定的值(这里是均值)替换,而原始的train['Age']Series保持不变。
-
-
最后,通过将train['Age'] =...:fillna()方法返回的新Series重新赋值给train['Age'],实现对train数据集中Age列缺失值的更新。这意味着train数据集中的Age列现在包含填充后的数值,缺失值已被均值替代。
train.Age.fillna(train.Age.mean(),inplace = True)这段被注释掉了的代码和上面一句功能完全一致,可以替代用。
5、划分训练测试集
最终选取Pclass,Age和Sex列作为预测数据集的特征,没有根据纯属感觉判断(这里面有个问题,就是如果不确定哪个特征到底对结果有多大的影响的话,就全部拿去训练行不行,不筛选了),这里面没有用到train_test_split,因为基础数据已经把训练集和测试集分开了,所以就手动取出Survived列当作目标值即可
feature = ['Pclass','Age','Sex']
x_train = train[feature]
y_tarin = train['Survived']
x_test = test_x[feature]
y_test = test_y['Survived']
# y_test.head(30)6、训练数据
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier(criterion = 'entropy',splitter = 'best')
clf.fit(x_train,y_tarin)
y_pre = clf.predict(x_test)criterion参数的其他选项'gini':- 含义:基尼不纯度(Gini impurity)是一种衡量数据集中混乱程度或不确定性的指标。在决策树构建过程中,选择分裂特征时,算法会尝试找到能使子节点基尼不纯度最小化的特征和分裂点。基尼不纯度的计算公式为:Gini(p)=∑i=1Kpi(1−pi),其中pi是第i类样本在节点中所占的比例,K是类别总数。
- 使用场景:在实际应用中,
'gini'是一种计算相对简单且高效的准则,对于大规模数据集通常表现良好。许多情况下,使用'gini'和'entropy'构建的决策树在性能上差异不大。但'gini'的计算速度更快,因为信息熵的计算涉及对数运算,相对复杂一些。例如,在电商用户行为分析中,预测用户是否购买商品,使用基尼不纯度作为分裂准则可以快速构建决策树模型,对用户行为进行分类。
splitter参数的其他选项'random':- 含义:当设置为
'random'时,决策树在选择分裂点时,不会考虑所有可能的特征和分裂点来找到最优解(像'best'那样),而是随机选择一部分特征和分裂点。具体来说,每次分裂时,算法会随机选择一个特征子集,然后在这个子集中寻找最佳分裂点。 - 使用场景:这种方式在数据集维度很高(特征很多)时非常有用,可以显著减少计算量。因为在高维数据中,遍历所有特征和分裂点来寻找最优解计算成本很高。通过随机选择特征子集,虽然可能找不到全局最优的分裂点,但可以在较短时间内构建一个性能尚可的决策树模型。例如,在图像识别任务中,图像数据可能有数千个特征,使用
'random'作为分裂策略可以加快决策树的训练速度,同时避免过拟合。
- 含义:当设置为
7、查看模型准确度
score = clf.score(x_test,y_test)
score
0.8612440191387568、画树
import graphviz as gh
from sklearn import tree
feature_name = ['仓级','性别','年龄']
dot_data = tree.export_graphviz(clf
,feature_names=feature_name
,class_names=["生存","死亡"]
,filled=True,rounded=True)
graph = gh.Source(dot_data)1. feature_names 与输入特征值的对应关系
-
名称顺序一致性:
feature_names是一个列表,其中的元素应与训练模型时使用的特征顺序严格一致。例如,如果训练决策树模型时,输入数据X的第一列是 “身高”,第二列是 “体重”,那么feature_names = ['身高', '体重'],这样在生成的决策树可视化图中,才能正确标注每个节点所依据的特征。 -
名称准确性:
feature_names中的名称应准确反映数据集中特征的含义。如果名称错误或不清晰,会导致对决策树可视化结果的误解。比如,若特征实际代表 “每月收入”,却写成了 “年收入”,就会误导对模型决策依据的理解。 -
特征数量匹配:
feature_names列表的长度必须与训练模型时输入特征的数量相等。如果特征数量不匹配,在调用tree.export_graphviz时会引发错误。例如,训练模型使用了 5 个特征,但feature_names只提供了 4 个名称,就会出现问题。
2. class_names 与目标值的对应关系
-
类别顺序一致性:
class_names列表中的类别名称应与目标值y中的类别标签顺序相对应。假设目标值y中,0 代表 “琴酒”,1 代表 “雪梨”,2 代表 “贝尔摩德”,那么class_names = ["琴酒", "雪梨", "贝尔摩德"]。这样在可视化的决策树中,叶节点的类别标注才会准确。 -
涵盖所有类别:
class_names必须包含目标值中的所有类别。如果目标值中有某个类别在class_names中未列出,那么在可视化结果中,该类别的相关信息可能无法正确显示。例如,目标值中除了 “琴酒”、“雪梨”、“贝尔摩德”,还有 “基安蒂”,但class_names未包含 “基安蒂”,就会导致可视化不完整。 -
数据类型兼容性:虽然
class_names通常是字符串列表,但目标值y中的类别标签可以是数值型(如 0, 1, 2)或其他可哈希类型。只要class_names中的名称与类别标签能正确对应即可。例如,即使目标值y中的类别标签是字符串形式的 “gin”、“sherry”、“vermouth”,class_names依然可以写成中文的 “琴酒”、“雪梨”、“贝尔摩德”,只要保证顺序和对应关系正确。
9、保存树到指定文件
graph.render('Titanic Survived', view = True)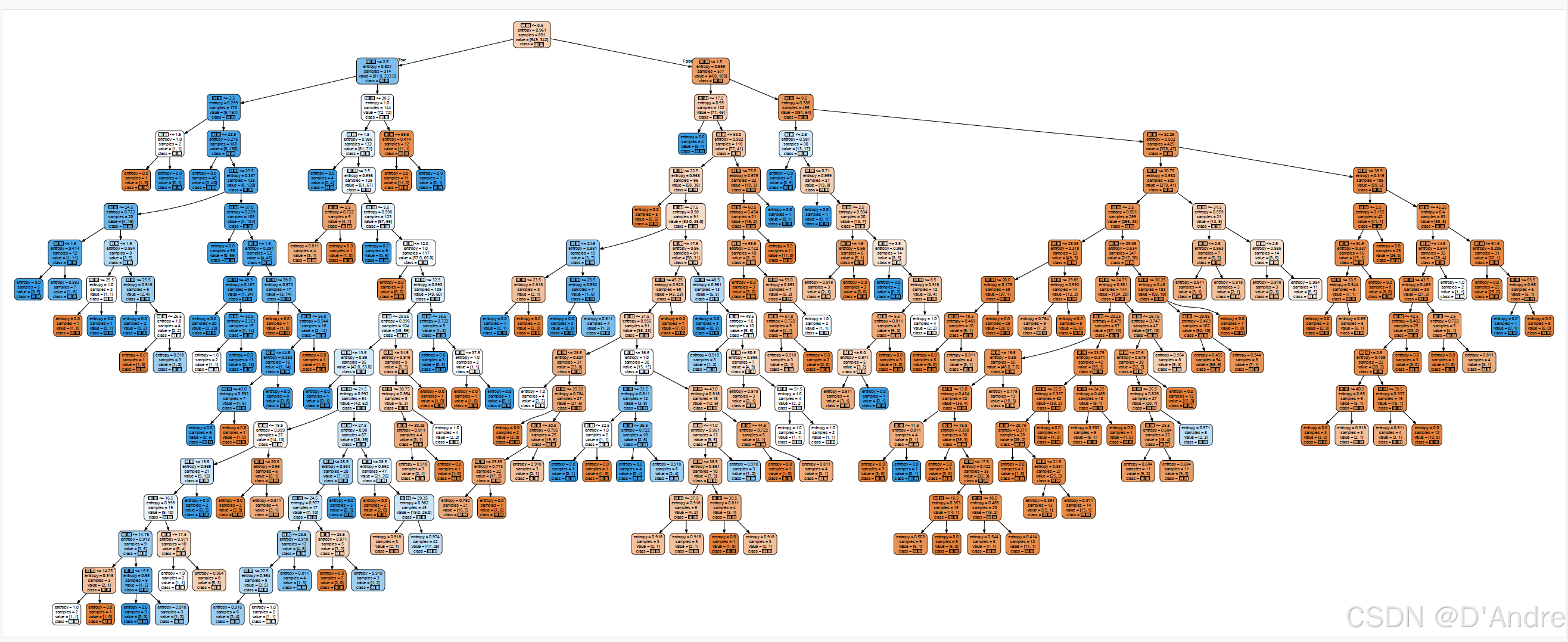
10、搞不懂
为什么特征和目标的中文无法显示?


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









