




 这篇博客主要探讨了自然语言处理(NLP)中Transformer模型和Attention机制的原理,包括详细的解释和源码解析,帮助读者深入理解BERT等先进NLP模型的基础。
这篇博客主要探讨了自然语言处理(NLP)中Transformer模型和Attention机制的原理,包括详细的解释和源码解析,帮助读者深入理解BERT等先进NLP模型的基础。
NLP相关:
nlp中的Attention注意力机制+Transformer详解 https://zhuanlan.zhihu.com/p/53682800
NLP中的Attention原理和源码解析 https://zhuanlan.zhihu.com/p/43493999
【NLP】Transformer模型原理详解 https://zhuanlan.zhihu.com/p/44121378 https://zhuanlan.zhihu.com/p/46652512
一文读懂BERT(原理篇)https://blog.youkuaiyun.com/jiaowoshouzi/article/details/89073944
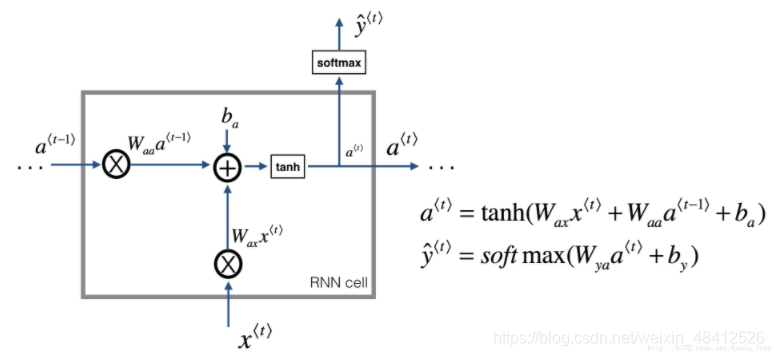
| 是什么 | 为什么需要RNN (RNN解决了什么问题) | 如何实现 | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RNN | RNN是神经网络中的一种,其网络结构是一个链条,链条中的每个节点存储着一个时间步的信息。 训练过程中,输入是一个序列(比如一句话),从左到右,每个时间步,RNN依次读取序列中的每个单词,通过隐藏层的激活函数将信息保存在当前节点中。然后把信息会传到下一个节点。基于这样前后单元相连接的链条结构,RNN实现了信息传递,最后一个单元保存了整个输入序列的信息,可以处理复杂的自然语言分类问题。
双向RNN:将两个相反方向的隐藏层连接到相同的output上,使得output可以能够同时取得过去和未来的信息 优势:能够支持模型使用序列的所有信息,支持在任意位置进行预测, 缺点:必须遍历序列所有信息后,才能够预测 | RNN 相对于传统神经网络的优势:
下列网络图中,只有Wax, Waa, Wya三种参数
a部分,通常选择用relu作为激活函数 y部分,如果是二分类问题,使用sigmoid作为激活函数,如果是多分类问题,可以使用softmax激活函数
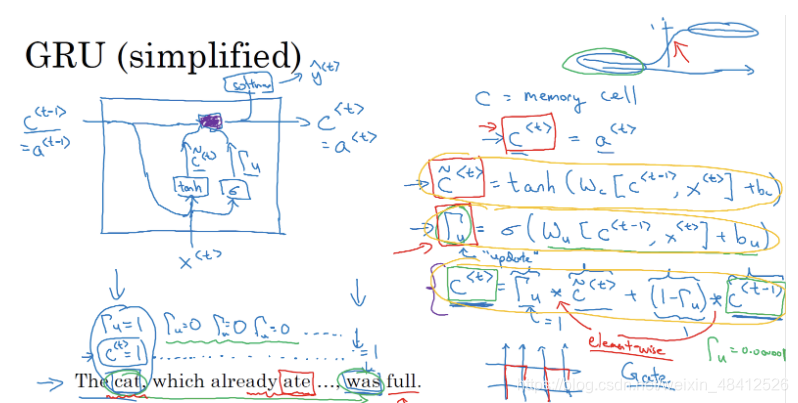
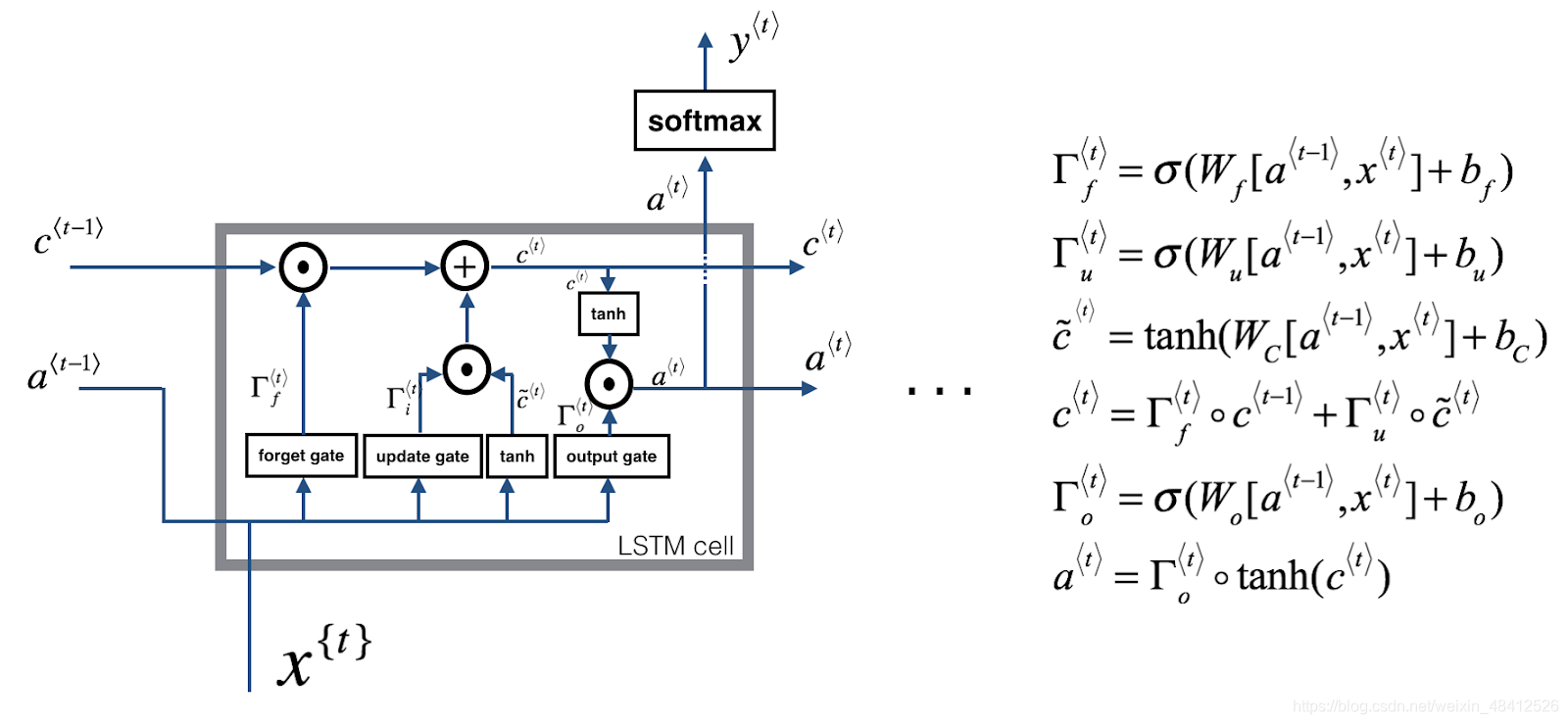
| 引入门的概念,有效处理梯度消失的问题 在RNN中,梯度消失意味这,前面的内容很难对后续内容产生影响,模型不能处理长度很长有很多单词的句子 比如: the cats, xxxxxxxxxxxxxx, was/were (此处如何选择was 还是were?) 门的概念的引入: GRU:在每个cell格子中,都加上一个更新门。cell 会保留过去的信息。更新门会决定这个cell的信息是否要更新。如果是,那么就会将过去的信息替换成新信息,然后传入下一个cell, 如果不更新,那么就会将旧信息传给下一个。 可以帮助捕获到长期的联系 LSTM:含有更新门,遗忘门,输出门。 每个cell 能够保留过去的信息,也能够保留任意时间戳的信息 三个门决定了要保留哪些信息,管理着进出cell的信息流 LSTM的优势就是能够捕获到长时间的联系,同时处理梯度消失的问题 | ||||||||||||||||||
| GRU | 将常规的RNN单元替换为GRU单元,GRU中引入了新的变量,记忆细胞,存储着过去的信息,提供了长期的记忆能力。
| 处理梯度消失的问题 | 在每个节点中,都引入”记忆细胞“的新变量,加上一个更新门。原始记忆细胞保留过去的信息。同时有个记忆细胞的候选值,保存着当前时间步上新的输入的信息。更新门会决定是否用候选值来更新当前记忆细胞的值。如果是,那么就会将过去的信息替换成新信息,然后传入下一个cell, 如果不更新,那么就会将旧信息传给下一个。
| ||||||||||||||||||
| LSTM |
LSTM:含有更新门,遗忘门,输出门。
每个cell 能够保留过去的信息,也能够保留任意时间戳的信息
三个门决定了要保留哪些信息,管理着进出cell的信息流
LSTM的优势就是能够捕获到长时间的联系,同时处理梯度消失的问题
| LSTM的优势就是能够捕获到长时间的联系,同时处理梯度消失的问题 可以同时保留过去信息和当前信息。通过遗忘门和更新门的大小来控制 对捕捉序列中更深层次的联系要比GRU更加有效。 | 背景:在读一篇文章,想要用LSTM来保留其语法结构。比如主语是单数还是复数等信息 之前的主语是单数,cell 中一直保留着“主语单数”的信息。 现在新遇到一个复数主语。
| ||||||||||||||||||
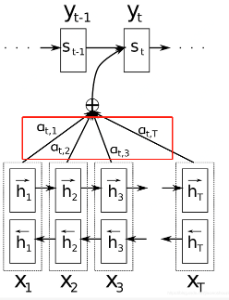
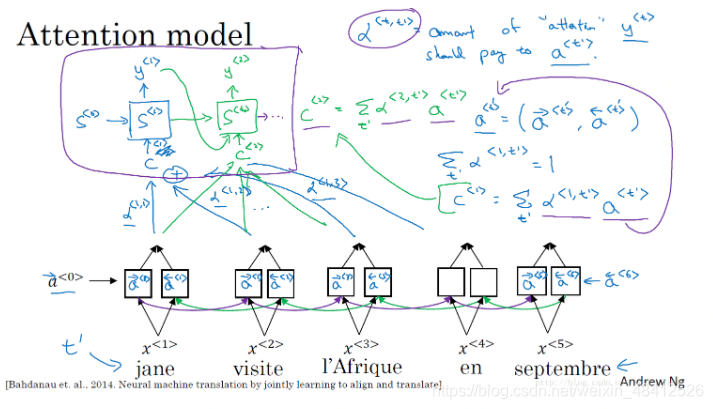
| 注意力机制 | 注意力模型会在输入的每个输入的信息块上计算注意力权重,不同的权重对每一步的输出结果有不同的注意力影响。
|
|
注意力机制:
| ||||||||||||||||||
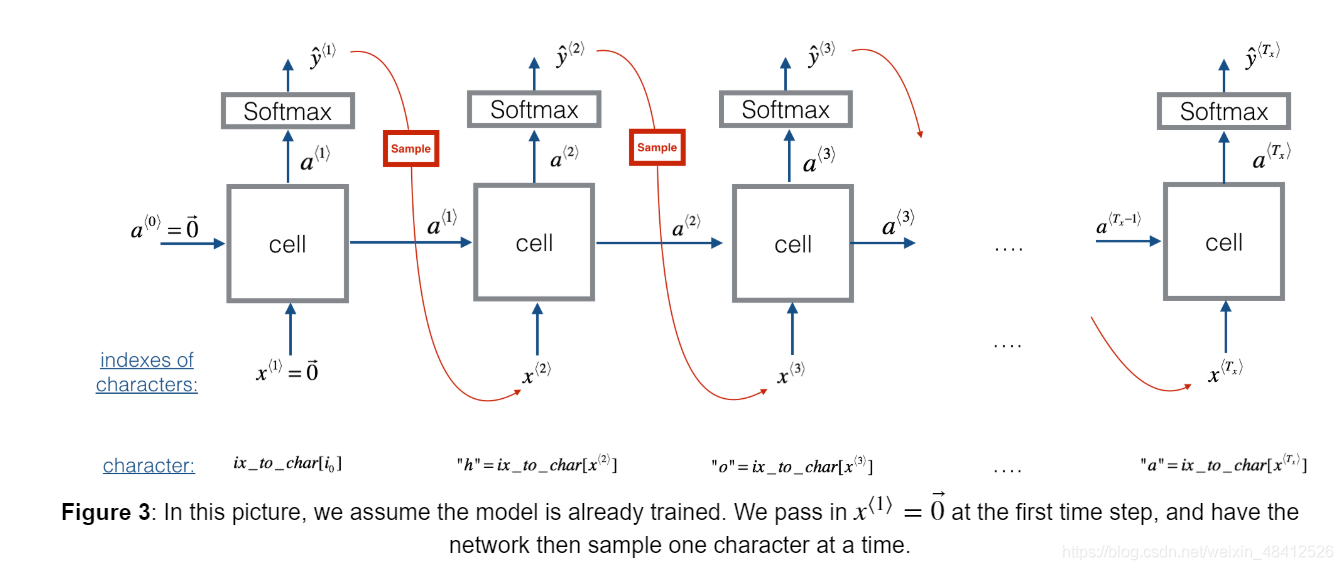
| Language Model 语言模型 | 词序列上的概率分布。对于一个长度为Ty的序列,它会给整个序列产生P(y<1>,y<2>... ,y<Ty>)}。 目标是用来区分那些读音很相近的单词和句子。 给定任意一个句子,语言模型能够估计它是特定一个句子的概率 | 语音转文本: The apple and pear salad was delicious. The apple and pair salad was delicious. 这两个句子的发音非常相似。但是语言模型会根据文本的合理性来选择第一个 | 用RNN来训练一个语言模型 训练数据:句子, 如: Cats average 15 hours of sleep a day. 将句子中的单词,逐个输入到RNN中,每一步都会给出一个预测值(所有单词中预测概率值最大的单词作为预测值)然后计算损失函数
| ||||||||||||||||||
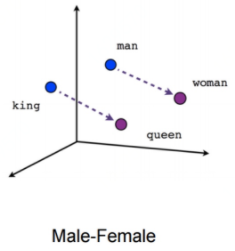
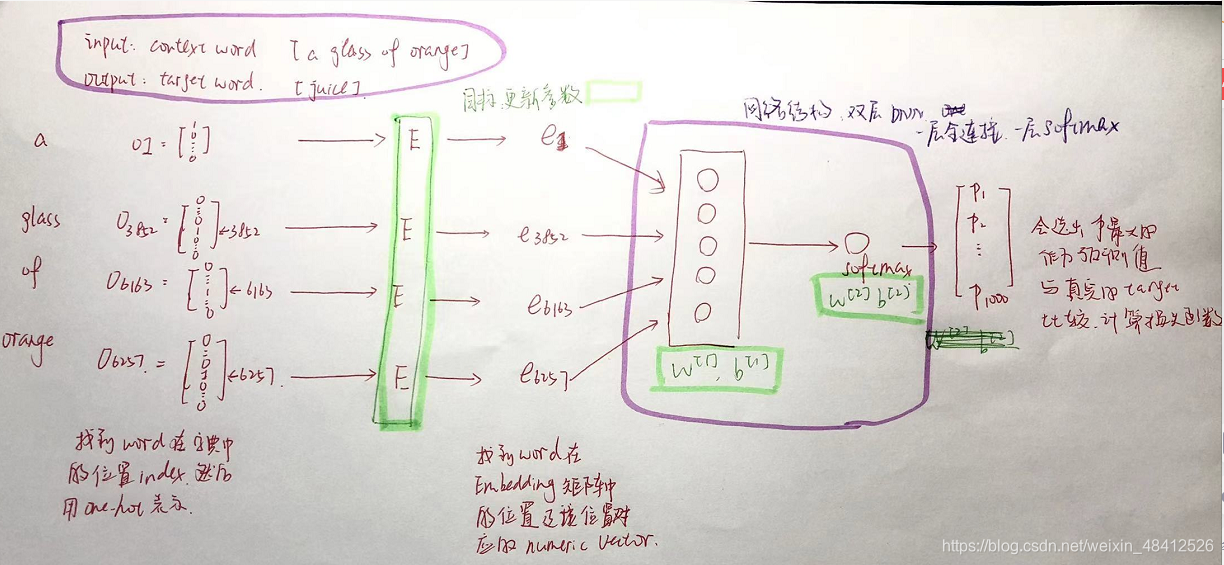
| Word Embedding | Word Embeddings 是一种词汇表征的方式,对不同单词进行了实现了特征化的表示。 优点:词与词之间的相似性很容易地表征出来,这样对于不同的单词,模型的泛化性能会好很多
| 将词进行特征表征。
| 词嵌入的学习方法
|


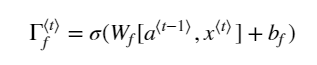
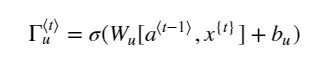
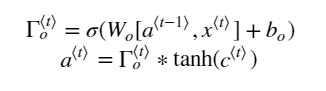

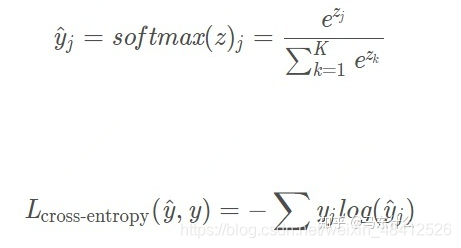


















 702
702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









