







伙伴算法
伙伴算法的引入?
当程序在运行的时候需要更多的内存空间来存储数据,操作系统会根据请求给程序动态分配内存空间,分配的过程中可能会导致内存碎片,而且内核在频繁的请求和释放不同大小的一组连续页框的过程中肯定会导致在已经分配的块内分散许多小块的空闲页框,那么内存空间将会浪费,所以需要尽量避免产生内存碎片,所以引入伙伴算法对内存进行管理。
准备阶段-页、页表、页框块
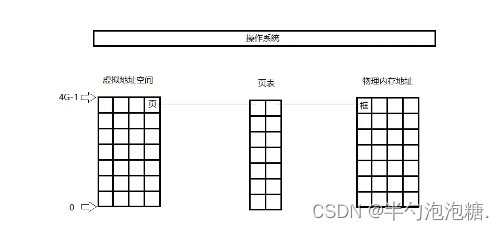
cpu在访问进程的时候均会访问内存,但是我们都知道cpu并不会直接访问物理内存,而是通过访问虚拟地址空间间接访问物理内存地址,如下图所示通过维护页表,就完成了页与框的映射关系,页面大小为4k。
页:将虚拟地址空间划分成若干个大小相等的片
框:将物理地址空间划分成若干个与页大小相等的存储块
页表:每一项存储一个页一个框的映射
原理
在操作系统分配内存的过程中,一个内存块被分成两个大小相等的内存块,我们称这两个大小相等的内存就处于伙伴关系,而且要求拆分出来的两个块的大小相同且物理地址是连续的。
算法思想:
buddy伙伴算法适用于大块连续物理内存分配以及释放,每个内存块由多个页面组成,核心就是将可用的物理内存拆分成大小为2的整数次幂的页面。
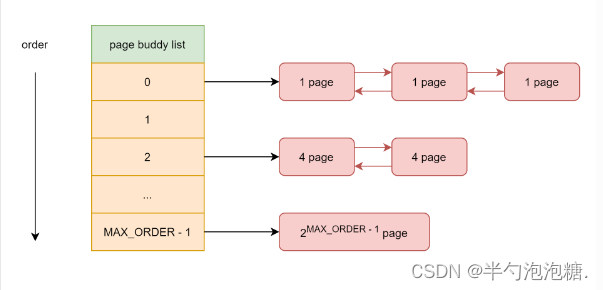
伙伴算法通常用free_area数据结构表示,free_list是一个链表即当前分配所对应的页框块链表,nr_free就是当前链表中空闲页框数量,举例说明,free_area[2]中nr_free值为3,就是3个大小为4的页框块,总的空闲页就是3*4=12。
#define MAX_ORDER 11
struct free_area {//链表
struct list_head free_list[MIGRATE_TYPES];//页属性
unsigned long nr_free;//空闲页框块数目
};
struct zone{
struct free_area freearea[MAX_ORDER];
};
#define MAX_ORDER 11 //即上文中提到的11个块链表
举例来说明伙伴算法原理
-
假设我们要申请一块16k大小的内存空间,224k=16k,所以系统会找到下标为2的位置,也就是第2个块链表,那么分配的块大小为4k,并修改链表
-
倘若下标为2的位置找不到,那么可以依次向后顺序查找更大的内存块,直到找到一个可以满足请求的内存块
-
当用完内存归还的时候,需要检查其伙伴块是否处于空闲状态,空闲的话那么就进行合并,否则就直接归入块链表
我们知道在64位操作系统中,内存划分成DMA,MDA32,Normal区,查看各个区域相关信息
cat /proc/Buddyinfo
每一行代表当前内存区以2的n次幂进行计算得到的可使用的空闲页数量,最大可取到2的10次方,就是1、2、4、8、16、32、64、128、256、512、1024,以页大小单位为4k进行计算。

x86下的物理地址空间布局:
内核将页划分成不同的区,主要使用了四种区。
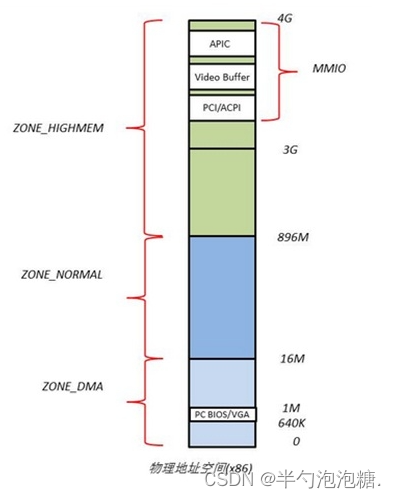
Node:NUMA环境下的节点号,当前只有一个节点0
zone:一个节点下的区域
DMA:该区域的物理页面专门供I/O设备的DMA使用,可以直接使用物理地址访问内存
DMA32:与DMA执行操作一样,区别是DMA32区域的页面只能被32位设备访问
HIGHMEM:高端内存,该区域的页不能永久地映射到内核地址空间
Normal:包含能正常映射到的页
举例说明:
比如说zone DMA的第3列,空闲页面就是1X2的3次方=8,可用内存就是1x2的3次方xPAGE_SIZ(4k)
源码分析–6.2版本
伙伴算法将物理内存块拆分成多个页面,只要系统有满足需求且充足的空闲页面,那么就会在free_area数组中查找满足需求的页块。
__get_free_pages() -->(/mm/page_alloc.c)
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order)
{
struct page *page;
page = alloc_pages(gfp_mask & ~__GFP_HIGHMEM, order);//获取页面,其中 __GFP_HIGHMEM 被清除,表示不获取高端内存区的页面。order 参数表示要获取的连续页面的数量。
if (!page)//失败
return 0;
return (unsigned long) page_address(page);//返回页面起始地址
}
获取物理页面的核心流程由alloc_pages()函数来完成
alloc_pages() -->(/mm/mempolicy.c)
//定义一个函数alloc_pages,它接受两个参数:gfp(页面分配标志)和order(要分配的连续页面的数量,存在形式为2的order次幂个物理页面,就是页块在free_area数组中的索引)。函数返回一个指向struct page的指针
struct page *alloc_pages(gfp_t gfp, unsigned order)
{
struct mempolicy *pol = &default_policy;//初始化为系统的默认内存策略
struct page *page;//保存分配到的页面的地址。
// 检查当前是否在中断上下文中,以及是否为特定节点分配页面
// 如果不在中断中并且没有为特定节点请求页面,则获取当前任务的内存策
if (!in_interrupt() && !(gfp & __GFP_THISNODE))
pol = get_task_policy(current);//获取当前任务的内存策略
/*
* No reference counting needed for current->mempolicy
* nor system default_policy
*/
//判断内存策略的模式是否为交叉分配
if (pol->mode == MPOL_INTERLEAVE)
page = alloc_page_interleave(gfp, order, interleave_nodes(pol));//是多首选节点模式,根据指定的多首选节点策略分配页
else if (pol->mode == MPOL_PREFERRED_MANY)//如果是优先分配多个节点
page = alloc_pages_preferred_many(gfp, order,
policy_node(gfp, pol, numa_node_id()), pol);
else//均不是,使用__alloc_pages方法,传入相关的节点和nodemask信息
page = __alloc_pages(gfp, order,
policy_node(gfp, pol, numa_node_id()),
policy_nodemask(gfp, pol));
return page;//返回分配到的页面的地址
}
总结:该函数主要是根据当前的内存策略来分配一定数量的连续物理页面,并返回分配到的页面的地址,当内存策略不是多首选节点模式以及交叉匹配则调用__alloc_pages完成页面分配。
__alloc_pages() -->(/mm/page_alloc.c)
struct page *__alloc_pages(gfp_t gfp, unsigned int order, int preferred_nid,
nodemask_t *nodemask)
// gfp页面分配标志,order要分配的连续页面的数量,preferred_nid首选节点 ID,nodemask节点掩码指针
{
struct page *page;//保存分配到的页面的地址
unsigned int alloc_flags = ALLOC_WMARK_LOW;//分配标志设置为ALLOC_WMARK_LOW
gfp_t alloc_gfp; /* The gfp_t that was actually used for allocation */
//保存实际用于分配的 gfp 标志
struct alloc_context ac = { };//初始化保存分配上下文
/*
* There are several places where we assume that the order value is sane
* so bail out early if the request is out of bound.
*/
//检查order是否超过了系统允许的最大值
if (WARN_ON_ONCE_GFP(order > MAX_ORDER, gfp))
return NULL;
gfp &= gfp_allowed_mask;
// 使用gfp_allowed_mask掩码来清除不允许的gfp标志
/*
* Apply scoped allocation constraints. This is mainly about GFP_NOFS
* resp. GFP_NOIO which has to be inherited for all allocation requests
* from a particular context which has been marked by
* memalloc_no{fs,io}_{save,restore}. And PF_MEMALLOC_PIN which ensures
* movable zones are not used during allocation.
*/
gfp = current_gfp_context(gfp);//获取当前任务的gfp上下文,主要考虑到GFP_NOFS、GFP_NOIO等标志的继承
alloc_gfp = gfp;
if (!prepare_alloc_pages(gfp, order, preferred_nid, nodemask, &ac,
&alloc_gfp, &alloc_flags))//页面分配的准备工作,设置页面分配标志、分配的连续页面数量等
return NULL;
/*
* Forbid the first pass from falling back to types that fragment
* memory until all local zones are considered.
*/
//合并,将不碎片化的标志加入到 alloc_flags 中,根据给定区域和 GFP 标志确定是否应该设置不碎片化的标志。
alloc_flags |= alloc_flags_nofragment(ac.preferred_zoneref->zone, gfp);
/* First allocation attempt */
//从空闲列表中获取页面
page = get_page_from_freelist(alloc_gfp, order, alloc_flags, &ac);
if (likely(page))//成功
goto out;
//失败
alloc_gfp = gfp;//重置 GFP 标志
ac.spread_dirty_pages = false;//不再尝试分散分配脏页面
/*
* Restore the original nodemask if it was potentially replaced with
* &cpuset_current_mems_allowed to optimize the fast-path attempt.
*/
ac.nodemask = nodemask;//设置分配上下文的节点掩码
page = __alloc_pages_slowpath(alloc_gfp, order, &ac);//分配页面
out:
// 如果启用了内存控制组的内核内存计费,并且分配成功,则尝试对页面进行计
if (memcg_kmem_online() && (gfp & __GFP_ACCOUNT) && page &&
unlikely(__memcg_kmem_charge_page(page, gfp, order) != 0)) {
__free_pages(page, order);//释放分配的页面
page = NULL;
}
trace_mm_page_alloc(page, order, alloc_gfp, ac.migratetype);//追踪页面分配的情况
kmsan_alloc_page(page, order, alloc_gfp);//进行内核内存清理
return page;//返回页面指针
}
可以发现核心的分配函数是在get_page_from_freelist()完成
get_page_from_freelist() -->(/mm/page_alloc.c)
static struct page *
get_page_from_freelist(gfp_t gfp_mask, unsigned int order, int alloc_flags,
const struct alloc_context *ac)
{
struct zoneref *z;
struct zone *zone;
struct pglist_data *last_pgdat = NULL;
bool last_pgdat_dirty_ok = false;//用于标记是否允许在最后一个节点(node)上分配脏页
bool no_fallback; //标记是否禁止回退分配
retry:
no_fallback = alloc_flags & ALLOC_NOFRAGMENT;//判断alloc_flags是否包含ALLOC_NOFRAGMENT标志位,如果包含则禁止回退分配
z = ac->preferred_zoneref;//获取首选的内存区域信息
for_next_zone_zonelist_nodemask(zone, z, ac->highest_zoneidx,
ac->nodemask) {//开始循环遍历zonelist中的每个内存管理区域(zone),遍历到最高内存管理区域(ac->highest_zoneidx)
struct page *page;//页面的信息
unsigned long mark;//页面状态
//启用了cpuest位置, 用户设置了 ALLOC_CPUSET 标志位 ,检查 cpuset
if (cpusets_enabled() &&
(alloc_flags & ALLOC_CPUSET) &&
!__cpuset_zone_allowed(zone, gfp_mask))
continue;
if (ac->spread_dirty_pages) {//需要分散分配脏页
if (last_pgdat != zone->zone_pgdat) {// 如果当前内存管理区域的节点与上一个节点不同
//更新last_pgdat为当前节点的信息,并检查当前节点是否可以分配脏页
last_pgdat = zone->zone_pgdat;
last_pgdat_dirty_ok = node_dirty_ok(zone->zone_pgdat);
}
//不允许分配脏页
if (!last_pgdat_dirty_ok)
continue;
}
//如果禁止回退分配且在线节点数大于1且当前内存管理区域不是首选的内存管理区域
if (no_fallback && nr_online_nodes > 1 &&
zone != ac->preferred_zoneref->zone) {
int local_nid;
/*
* If moving to a remote node, retry but allow
* fragmenting fallbacks. Locality is more important
* than fragmentation avoidance.
*/
local_nid = zone_to_nid(ac->preferred_zoneref->zone);//获取首选内存管理区域的节点ID
if (zone_to_nid(zone) != local_nid) {
alloc_flags &= ~ALLOC_NOFRAGMENT;//清除alloc_flags中的ALLOC_NOFRAGMENT标志位,允许回退分配
goto retry;
}
}
mark = wmark_pages(zone, alloc_flags & ALLOC_WMARK_MASK);//计算页面的水位线
if (!zone_watermark_fast(zone, order, mark,
ac->highest_zoneidx, alloc_flags,
gfp_mask)) {//不满足快速水位线
int ret;
#ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT
if (static_branch_unlikely(&deferred_pages)) {
if (_deferred_grow_zone(zone, order))
goto try_this_zone;
}
#endif
/* Checked here to keep the fast path fast */
BUILD_BUG_ON(ALLOC_NO_WATERMARKS < NR_WMARK);
if (alloc_flags & ALLOC_NO_WATERMARKS)
goto try_this_zone;
if (!node_reclaim_enabled() ||
!zone_allows_reclaim(ac->preferred_zoneref->zone, zone))//节点回收未启用,或者当前 zone 不允许回收
continue;
ret = node_reclaim(zone->zone_pgdat, gfp_mask, order);//回收节点内存
//回收情况
switch (ret) {
case NODE_RECLAIM_NOSCAN:
/* did not scan */
continue;
case NODE_RECLAIM_FULL:
/* scanned but unreclaimable */
continue;
default://其他情况
/* did we reclaim enough */
if (zone_watermark_ok(zone, order, mark,
ac->highest_zoneidx, alloc_flags))
goto try_this_zone;
continue;
}
}
//核心代码从首选的内存区域中获取页面,如果获取成功,则准备新的页面并可能为未来保留页块。如果没有获取到页面,则会检查是否定义了CONFIG_DEFERRED_STRUCT_PAGE_INIT,如果定义了并且该区域有延迟初始化的页面,会再试一次获取页面。
try_this_zone:
page = rmqueue(ac->preferred_zoneref->zone, zone, order,
gfp_mask, alloc_flags, ac->migratetype);//首选的内存区域中队列中获取一页
if (page) {//成功
prep_new_page(page, order, gfp_mask, alloc_flags);//准备新的一页
if (unlikely(order && (alloc_flags & ALLOC_HARDER)))//如果这是一个高阶原子分配,则检查是否应该为将来保留页面块
reserve_highatomic_pageblock(page, zone, order);
return page;//返回获取到的页面
} else {
#ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT
/* Try again if zone has deferred pages */
if (static_branch_unlikely(&deferred_pages)) {//有延迟初始化的页面,再试一次
if (_deferred_grow_zone(zone, order))//在区域中延迟初始化页面
goto try_this_zone;//成功
}
#endif
}
}
/*
* It's possible on a UMA machine to get through all zones that are
* fragmented. If avoiding fragmentation, reset and try again.
*/
if (no_fallback) {//如果已经尝试了所有区域而没有找到可用的页面,则清除标志位并重新分配内存
alloc_flags &= ~ALLOC_NOFRAGMENT;
goto retry;
}
return NULL;
}
get_page_from_freelist()是计入伙伴算法的前置函数,它通过传递进来的分配标志和分配阶,寻找适合的区(zone),如果找到了满足条件的区,则进行伙伴算法,进行分配,可以通过核心代码看到伙伴算法的入口函数为rmqueue()。
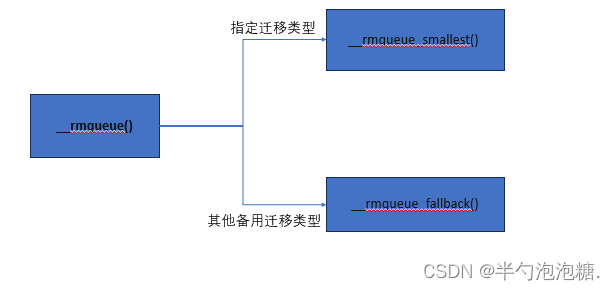
__rmqueue -->(/mm/page_alloc.c)
static __always_inline struct page *
__rmqueue(struct zone *zone, unsigned int order, int migratetype,
unsigned int alloc_flags)
{
struct page *page;
//CMA连续内存分配器被启用
if (IS_ENABLED(CONFIG_CMA)) {
如果分配标志包含ALLOC_CMA,并且区域的NR_FREE_CMA_PAGES(CMA空闲页面数量)大于NR_FREE_PAGES(总空闲页面数量)的一半
if (alloc_flags & ALLOC_CMA &&
zone_page_state(zone, NR_FREE_CMA_PAGES) >
zone_page_state(zone, NR_FREE_PAGES) / 2) {//尝试从CMA中获取页面
page = __rmqueue_cma_fallback(zone, order);//成功获取页面
if (page)
return page;
}
}
retry:
page = __rmqueue_smallest(zone, order, migratetype);//获取阶数以及迁移类型的最小页面
if (unlikely(!page)) {//未能获取到
if (alloc_flags & ALLOC_CMA)// // 如果分配标志包含ALLOC_CMA,则再次尝试从CMA中获取页面
page = __rmqueue_cma_fallback(zone, order);
/// 如果仍然未能获取到页面,并且__rmqueue_fallback函数返回true(表示可以尝试其他方法获取页面),
if (!page && __rmqueue_fallback(zone, order, migratetype,
alloc_flags))
goto retry;
}
return page;
}
总结:zone:伙伴算法将从该内存管理区中分配页框,order:分配阶,migratetype:迁移类型
__rmqueue_smalles() -->(/mm/page_alloc.c)
*/
static __always_inline
struct page *__rmqueue_smallest(struct zone *zone, unsigned int order,
int migratetype)
{
unsigned int current_order;//记录当前阶数
struct free_area *area;
struct page *page;
//循环遍历所有可能的阶数,直到找到合适的页面或达到最大阶数
for (current_order = order; current_order < MAX_ORDER; ++current_order) {
area = &(zone->free_area[current_order]);//获取当前阶数对应的free_area
page = get_page_from_free_area(area, migratetype);//从free_area中获取一个页面
if (!page)//失败
continue;
del_page_from_free_list(page, zone, current_order);//从空闲列表中删除获取的页面 ,删除则说明当前页框块已经不属于伙伴块链表了
expand(zone, page, order, current_order, migratetype);//扩展页面到所需的阶数
set_pcppage_migratetype(page, migratetype);//设置页面的迁移类型
trace_mm_page_alloc_zone_locked(page, order, migratetype,
pcp_allowed_order(order) &&
migratetype < MIGRATE_PCPTYPES);//跟踪页面分配事件
return page;//返回获取到的页面
}
return NULL;
}
总结:从当前的order链表中根据迁移类型去查找空闲的页框,链表不为空则可以分配order对应的页框块,一直顺序查找下去,一旦选定当前遍历的分配阶上分配页框块,那么就获取页框,并将此页框从块链表上del掉,并扩展页面所需阶数。
del_page_from_free_list() -->(/mm/page_alloc.c)
static inline void del_page_from_free_list(struct page *page, struct zone *zone,
unsigned int order)
{
/* clear reported state and update reported page count *///如果页面已被报告为已使用即内存泄漏
if (page_reported(page))
__ClearPageReported(page);//则清除该报告状态
list_del(&page->buddy_list);//从buddy列表中删除页面
__ClearPageBuddy(page);//清除页面的buddy标记
set_page_private(page, 0);//清除任何与页面关联数据
zone->free_area[order].nr_free--;// 更新指定阶数的空闲页面数量,将其减少1,表示已分配或使用了一个页面
}
总结:从空闲列表中删除指定的页面,并更新相关的状态和计数。
expand() -->(/mm/page_alloc.c)
static inline void expand(struct zone *zone, struct page *page,
int low, int high, int migratetype)
{
unsigned long size = 1 << high;//计算指定阶数high对应的页面大小,即2的high次方
while (high > low) {//计算指定阶数high对应的页面大小,即2的high次方
high--;//阶数减1
size >>= 1;//页面大小减半
VM_BUG_ON_PAGE(bad_range(zone, &page[size]), &page[size]);// 检查页面的范围是否合适
if (set_page_guard(zone, &page[size], high, migratetype))
continue;
add_to_free_list(&page[size], zone, high, migratetype);//将页面添加到空闲列表中
set_buddy_order(&page[size], high);//设置页面的buddy阶数
}
}
总结:引入此函数条件是所申请order小于当前选中的current_order,用该函数是扩展页面所需的阶数,如果遍历没有在当前的order中找到空闲块,那么在更大的阶找到。
举例说明:
(1)接着开篇举的例子,我们需要在order为2的阶上进行分配,但是此时prder为2的free_area上的free_list没有空闲块了
(2)依次顺序查找order为3、4的块链表,如果3页没有空闲块,4有空闲块,那么order为4的块链表上有2^4=16个页
(3)如果此时只申请了4个,那么多余的12个page就要分配在order为2、3的块链表上面
(4)size = 1 << high,此时high=4,计算得到size=16,high–即3
(5)继续执行size=8,那么8个页框add到order为3的块链表上
(6)继续执行size=4,那么4个页框add到order为2的块链表上
实践未完~~

















 2808
2808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









