







目录
6.5 实践与应用
下面,我们将探讨搭建简单 RAG 系统的方法, 以及 RAG 的两类典型应用。
.
6.5.1 搭建简单 RAG 系统
为助力开发者们高效且便捷地构建 RAG 系统,当前已有诸多成熟开源框架可供选择,其中最具代表性的便是 LangChain与 LlamaIndex。
接下来,我们将首先简要概述这两个框架的特色及其核心功能,然后讲解如何利用 LangChain 来搭建一个简单的 RAG 系统。
.
1)LangChain 与 LlamaIndex
(1)LangChain
LangChain 主要包含六大模块:Model IO、Retrieval、Chains、Memory、 Agents 和 Callbacks。
-
Model IO 模块:包含各种大模型的接口以及 Prompt 设计组件。
-
Retrieval 模块:包含构建 RAG 系统所需的核心组件,包括文档加载、文本分割、向量构建、索引生成以及向量检索等,还提供非结构化数据库的接口。
-
Chains 模块:可以将各个模块链接在一起逐个执行。
-
Memory 模块:存储对话过程中的数据。
-
Agents 模块:利用大语言模型自动决定执行哪些操作。
-
Callbacks 模块:帮助开发者干预和监控各个阶段。
(2)LlamaIndex
与 LangChain 相比,LlamaIndex 更加专注于数据索引与检索的部分。这一特性使得开发者能够迅速构建高效的检索系统。
LlamaIndex 还支持对这些信息进行过滤、重新排序等精细化操作。值得一提的是,LlamaIndex 框架还能够与 LangChain 框架相结合,从而实现更加多样化的功能。
总体而言,LlamaIndex 侧重于索引与检索,在查询效率上的表现更为突出,非常适用于在大数据量的场景下构建更为高效的 RAG 系统。
.
2)基于 LangChain 搭建简单 RAG 系统
参考其官方文档:https://python.langchain.com/v0.2/docs/tutorials/rag/
演示如何快速搭建一套简单的 RAG 系统。
(1)安装与配置:
首先,安装 LangChain 框架及其依赖项。
# 安装LangChain框架及其依赖项
!pip install langchain langchain_community langchain_chroma
(2)数据准备与索引构建:
接下来,准备数据并构建索引。
LangChain 的 DocumentLoaders 中提供了种类丰富的文档加载器,例如,我们可以使用 WebBaseLoader 从网页中加载内容并将其解析为文本。
from langchain_community.document_loaders import WebBaseLoader
# 使用WebBaseLoader加载网页内容:
loader = WebBaseLoader("https://example.com/page")
docs = loader.load()
加载完成后,由于加载的文档可能过长,不适合模型的上下文窗口,需要将文档分割成合适的大小。
LangChain 提供了 TextSplitter 组件来实现文档分割。
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 使用TextSplitter将长文档分割成更小的块,其中chunk_size表示分割文档的长度,chunk_overlap表示分割文档间的重叠长度
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
接下来需对分割后的文本块进行索引化,以便后续进行检索。
可以调用 Chroma 向量存储模块和 OpenAIEmbeddings 模型来存储和编码文档。
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
# 使用向量存储(如Chroma)和嵌入模型来编码和存储分割后的文档
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
(3)RAG 系统构建:
构建好知识源后,接下来开始构建基础 RAG 系统。该系统包括检索器与生成器,具体工作流程如下:
-
对于用户输入的问题,检索器首先搜索与该问题相关的文档,
-
接着将检索到的文档与初始问题一起传递给生成器,即大语言模型,
-
最后将模型生成的答案返回给用户。
首先进行检索器构建,这里可基于 VectorStoreRetriever 构建一个 Retriever 对象,利用向量相似性进行检索。
# 创建检索器
retriever = vectorstore.as_retriever()
接下来是生成器部分的构建,这里可使用 ChatOpenAI 系统模型作为生成器。
这一步,需设置 OpenAI 的 API 密钥,并指定要使用的具体模型型号。例如,我们可以选择使用 gpt-3.5-turbo-0125 模型。
import os
os.environ["OPENAI_API_KEY"] = 'xxx'
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
随后是输入 Prompt 的设置,LangChain 的 Prompt Hub 中提供了多种预设的 Prompt 模板,适用于不同的任务和场景。这里我们选择一个适用于 RAG 任务的 Prompt。
from langchain import hub
# 设置提示模板
prompt = hub.pull("rlm/rag-prompt")
最后我们需要整合检索与生成,这里可以使用LangChain表达式语言(LangChain Execution Language,LCEL)来方便快捷地构建一个链,将检索到的文档、构建的输入 Prompt 以及模型的输出组合起来。
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
# 使用LCEL构建RAG链
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# 定义文档格式化函数
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# 使用RAG链回答问题
response = rag_chain.invoke("What is Task Decomposition?")
print(response)
通过以上步骤,我们可以方便快捷地使用 LangChain 迅速搭建一个基础 RAG 系统。LangChain 提供了一系列强大的工具和组件,使得构建和整合检索与生成过程变得简单而高效。
.
6.5.2 RAG 的典型应用
下面介绍 RAG 系统的两个典型应用案例:智能体(Agent)、垂域多模态模型增强。
.
1)智能体(Agent)
RAG 在 Agent 系统中扮演着重要角色。在 Agent 系统主动规划和调用各种工具的过程中,需要检索并整合多样化的信息资源,以更精确地满足用户的需求。 RAG 通过提供所需的信息支持,助力 Agent 在处理复杂问题时展现出更好的性能。
图 6.27: Agent 框架流程示意图
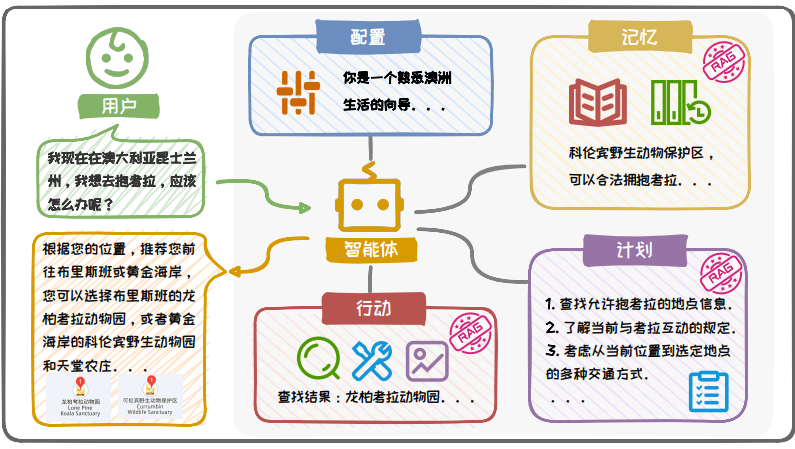
上图,展示了一个经典的 Agent 框架,该框架主要由四大部分组成:配置(Profile)、记忆(Memory)、计划(Planning)和行动(Action)。其中记忆模块、 计划模块与行动模块均融入了 RAG 技术,以提升整体性能。
-
配置模块:通过设定基本信息来定义 Agent 的角色,这些信息可以包括 Agent 的年龄、性别、职业等基本属性,以及反映其个性和社交关系的信息;
-
记忆模块:存储从环境中学习到的知识以及历史信息,支持记忆检索、记忆更新和记忆反思等操作,允许 Agent 不断获取、积累和利用知识。在这一模块中, RAG 通过检索相关信息来辅助记忆的读取和更新;
-
计划模块:赋予 Agent 将复杂任务分解为简单的子任务的能力,并根据记忆和行动反馈不断调整。RAG 在此模块中通过提供相关的信息,帮助 Agent 更合理有效地规划任务;
-
行动模块:负责将 Agent 的计划转化为具体的行动,包括网页检索、工具调用以及多模态输出等,能够对环境或 Agent 自身状态产生影响,或触发新的行动链。在这一模块中, RAG 通过检索相关信息来辅助 Agent 的决策和行动执行。
通过这种模块化且集成 RAG 技术的方法,Agent 能够更加高效和智能地响应用户需求,展现出更加卓越的性能。
.
2)多模态垂直领域应用
目前,已经出现了一些多模态垂直领域的 RAG 应用,例如 Ossowski 等人提出的医学领域多模态检索框架。下图展示了该框架的整个工作流程。
图 6.28: 多模态垂域 RAG 框架示意图
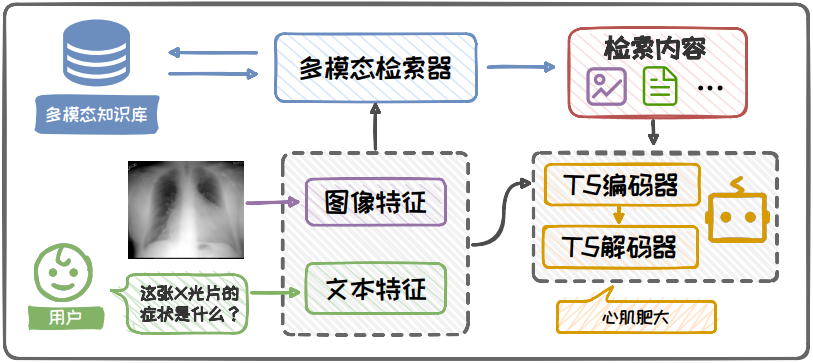
此处以给定一张 X 光照片,询问该照片所对应的可能症状这一任务为例进行说明。该框架:
-
首先提取图像与文本的特征表示,深入理解图像内容与问题语义,为检索模块提供丰富的特征向量。
-
随后,设计了一个多模态检索模块,利用这些特征向量在医学知识库中进行精准检索,从而获取与输入问题最为相关的信息。这些信息可能包括医学案例、症状描述、潜在病因及治疗方案等,它们以文本和图像的多种形式呈现。
-
最终,Prompt 构建模块将这些信息进行整合,辅助模型生成准确的回答。本例中,模型生成的答案是“心肌肥大”。
除了医疗领域,RAG 在其他垂直领域,如金融、生物学中也展现了其在处理专业信息上的强大能力,显著提升了专业人士的决策效率。
在各类任务中,除了图片信息,RAG 在音频、视频等其他多模态场景中也同样有着出色的表现。随着技术的进步和数据资源的丰富,我们期待未来 RAG 能够在更多垂直领域、更多数据模态中发挥关键作用。
.
其他参考:【大模型基础_毛玉仁】系列文章
声明:资源可能存在第三方来源,若有侵权请联系删除!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









