







【大模型基础_毛玉仁】2.1 大数据+大模型→新智能
2.大语言模型架构
大语言模型(LargeLanguageModel,LLM)。凭借着庞大的参数量和丰富的训练数据,大语言模型不仅展现出了强大的泛化能力,还催生了生成式人工智能(ArtificialIntelligenceGeneratedContent, AIGC)。
本章将深入探讨大语言模型的相关背景知识,并分别介绍Encoder-only、Encoder-Decoder 以及 Decoder-only 三种主流模型架构。简单介绍一些非Transformer架构的模型等等
2.1 大数据+大模型→新智能
截止2024年6月,国内外已见证超百种大语言模型的诞生。图2.1展示了一些具有重要影响力的模型。
图2.1: 大语言模型涌现能力的三个阶段。
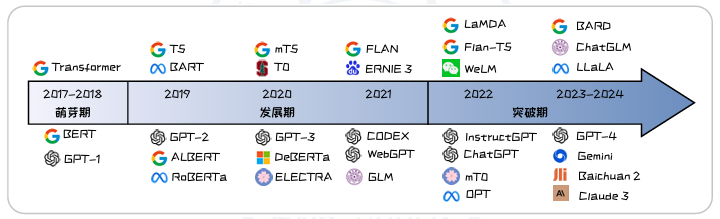
大语言模型的发展历程三个阶段:
-
萌芽期(2017至2018年):以Transformer架构的诞生和BERT、GPT-1模型的问世为标志,开启了预训练语言模型的新纪元。
-
发展期(2019至2022年):GPT-2、T5以及GPT-3等模型在参数规模以及能力上的大幅提升。
-
突破期(2022年起):ChatGPT2及GPT-4等模型的发布标志着大语言模型相关技术的显著进步。
本节将深入剖析大型语言模型的发展历程,特别是在能力增强和新能力涌现方面的进展。我们将从模型规模和数据规模的增长出发,探讨这些因素如何共同作用,促进了模型性能的飞跃和新功能的出现。
2.1.1 大数据+大模型→能力增强
数据规模的增长为模型提供了更丰富的信息。模型规模的不断扩大增加了模型的表达能力。
然而模型规模和数据规模的增长带来了更高的计算成本和存储需求,这要求我们在模型设计时必须在资源消耗和性能提升之间找到一个 恰当的平衡点。为应对这一挑战,大语言模型的扩展法则(Scaling Laws应运而生。
大语言模型的扩展法则(Scaling Laws) 是指通过量化模型性能与模型规模、数据规模和计算资源之间的关系,来预测和优化模型性能的法则。
本章节将深入介绍两种扩展法则:
-
OpenAI 提出的Kaplan-McCandlish扩展法则
-
DeepMind 提出的Chinchilla扩展法则。
1)Kaplan-McCandlish 扩展法则
2020 年,OpenAI 团队首次探究 了神经网络的性能与数据规模D以及模型规模N之间的函数关系。
根据实验结果拟合出了两个基本公式:
L ( N ) = ( N N c ) α N , α N ∼ − 0.076 , N c ∼ 8.8 × 1 0 13 L(N) = \left(\frac{N}{N_c}\right)^{\alpha_N}, \quad \alpha_N \sim -0.076, \quad N_c \sim 8.8 \times 10^{13} L(N)=(NcN)αN,αN∼−0.076,Nc∼8.8×1013
L ( D ) = ( D D c ) α D , α D ∼ − 0.095 , D c ∼ 5.4 × 1 0 13 L(D) = \left(\frac{D}{D_c}\right)^{\alpha_D}, \quad \alpha_D \sim -0.095, \quad D_c \sim 5.4 \times 10^{13} L(D)=(DcD)αD,αD∼−0.095,Dc∼5.4×1013
L(N)表示在数据规模固定时,不同模型规模下的交叉熵损失函数,反映了模型规模对拟合数据能力的影响。
L(D)表示在模型规模固定时,不同数据规模下的交叉熵损失函数,揭示了数据量对模型学习的影响。
L的值衡量了模型拟合数据分布的准确性,值越小表明模型对数据分布的拟合越精确,其自身学习能力也就越强大。
实验结果和相关公式表明,模型的性能与模型以及数据规模这两个因素均高度正相关。
然而,在模型规模相同的情况下,模型的具体架构对其性能的影响相对较小。因此,扩大模型规模和丰富数据集成为了提升大型模型性能的两个关键策略。
此外,OpenAI发现,总计算量C与数据量D和模型规模N的乘积近似成正比,即C≈6ND。而且模型规模的增长速度应该略快于数据规模的增长速度。两者的最优配置比例应当为 N o p t ∝ C 0.73 , D o p t ∝ C 0.27 N_{opt} \propto C^{0.73}, \quad D_{opt} \propto C^{0.27} Nopt∝C0.73,Dopt∝C0.27。
因此,指出了在模型规模上的投入应当略高于数据规模上的投入。
2)Chinchilla 扩展法则
谷歌旗下DeepMind团队对“模型规模的增长速度应该略高于数据规模的增长速度”这一观点提出了不同的看法。
2022年,他们对更大范围的模型规模以及数据规模进行了深入的实验研究,并据此提出了Chinchilla扩展法则:
L ( N , D ) = E + A N α + B D β L(N, D) = E + \frac{A}{N^\alpha} + \frac{B}{D^\beta} L(N,D)=E+NαA+DβB
- E =1.69, A =406.4, B = 410.7, α = 0.34, β = 0.28
DeepMind 最终得出数据集规模D与模型规模N的计算预算的最优配置为 N o p t ∝ C 0.46 , D o p t ∝ C 0.54 N_{opt} \propto C^{0.46}, \quad D_{opt} \propto C^{0.54} Nopt∝C0.46,Dopt∝C0.54。这一结果表明,数据集量D与模型规模N几乎同等重要。
此外,Chinchilla 扩展法则进一步提出,理想的数据集大小应当是模型规模的 20 倍。
例如,对于一个7B(70亿参数)的模型,最理想的训练数据集大小应为 140B(1400 亿)个Token。
但先前很多模型的预训练数据量并不够。因此,DeepMind推出了数据规模20倍于模型规模的Chinchilla模型(700 亿参数,1.4万亿Token),最终在性能上取得了显著突破。
2.1.2 大数据+大模型→能力扩展
如图2.2所示,模型训练数据规模以及参数数量的不断提升,不仅带来了上述学习能力的稳步增强,还为大模型“解锁”了一系列新的能力,例如上下文学习能力、常识推理能力、数学运算能力、代码生成能力等。
值得注意的是,这些新能力并非通过在特定下游任务上通过训练获得,而是随着模型复杂度的提升凭空自然涌现。这些能力因此被称为大语言模型的涌现能力(EmergentAbilities)。
图2.2: 大语言模型能力随模型规模涌现,图片由GPT-4o生成。
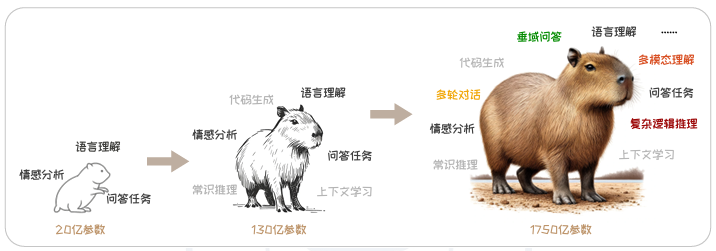
涌现能力往往具有突变性和不可预见性。类似于非线性系统中的“相变”,即系统在某个阈值点发生显著变化,这些能力也并没有一个平滑的、逐渐积累的过程,而是在模型达到一定规模和复杂度后,很突然地显现。
例如,在GPT系列的演变中,可以观察到一些较为典型的涌现能力。
-
上下文学习(In-ContextLearning):是指大语言模型在推理过程 中,能够利用输入文本的上下文信息来执行特定任务的能力。
-
常识推理(CommonsenseReasoning):赋予了大语言模型基于常识知识和逻辑进行理解和推断的能力。
-
代码生成(CodeGeneration):基于自然语言描述自动生成编程代码。
-
逻辑推理(LogicalReasoning):基于给定信息和规则进行合乎逻辑的推断和结论。这包括简单的条件推理、多步逻辑 推理、以及在复杂情境下保持逻辑一致性。
-
…
.
其他参考:【大模型基础_毛玉仁】系列文章
声明:资源可能存在第三方来源,若有侵权请联系删除!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









