









🌈个人首页: 神马都会亿点点的毛毛张
Shell编程基础
1.概述
1.1 什么是shell
- 核心定义:Shell是一个命令行解释器,作为用户与操作系统内核(Kernel)的桥梁,接收用户或应用程序的命令,翻译并调用内核执行。

- 功能特性:
- 命令语言:支持直接输入命令操作文件、进程等系统资源。
- 脚本编程语言:可编写脚本自动化任务,支持变量、循环、条件判断等编程特性。
- 应用程序接口:提供交互式界面,允许用户通过命令行访问系统服务。
- 实现语言:Shell本身用C语言编写,是Linux/Unix系统的核心组件之一。
1.2 什么是Shell脚本
- 定义:由Shell命令组成的文本文件,扩展名为
.sh,通过解释器逐行执行,实现自动化任务。 - 与Shell的区别:
- Shell:指命令行交互环境或解释器程序(如
bash)。 - Shell脚本:指用Shell语法编写的脚本文件。
- Shell:指命令行交互环境或解释器程序(如
1.3 Shell环境
- Shell 编程跟 java、php 编程一样,只要有一个能编写代码的文本编辑器和一个能解释执行的脚本解释器就可以了。
1.3.1 常见Shell解释器
| 解释器 | 描述 |
|---|---|
| sh | Bourne Shell,Unix标准Shell,功能简单。 |
| bash | Bourne Again Shell,Linux默认Shell,兼容sh并扩展功能(推荐使用)。 |
| zsh | 功能强大的交互式Shell,支持插件和主题(如Oh My Zsh)。 |
| fish | 友好的智能Shell,自带语法高亮和自动补全。 |
1.3.2 查看系统支持的Shell解释器
- 查看所有可用Shell解释器
user@host:~$ cat /etc/shells
/bin/sh # 基础 Bourne Shell
/bin/bash # Linux 默认 Shell(增强版 sh)
/sbin/nologin # 禁止登录的系统账户专用 Shell
/bin/dash # Debian 系默认脚本解释器(轻量快速)
/bin/tcsh # 兼容 C Shell 的扩展版本
/bin/csh # C Shell(语法类 C)
-
bash与sh的关系-
物理关系:在大多数 Linux 发行版(如 CentOS、Ubuntu)中,
sh是bash的符号链接(soft link),指向/bin/bash。ls -l /bin/sh # 输出示例:lrwxrwxrwx 1 root root 4 Mar 5 2020 /bin/sh -> bash -
行为差异:
- 当通过
sh执行脚本时,bash会切换至 POSIX 兼容模式,禁用部分扩展功能(如数组)。 - 直接使用
bash或#!/bin/bash时,启用全部 Bash 特性。
- 当通过
-
-
查看当前用户的默认Shell
echo $SHELL # 输出示例:/bin/bash(CentOS/RedHat 默认) -
临时切换Shell解释器:
bash # 进入 bash 环境 exit # 退出回到原 Shell dash # 切换至 dash(Debian 系) exit # 退出
1.3.3 指定脚本解释器
Shebang 的作用与语法
-
核心功能:脚本文件首行通过
#!(称为 Shebang 或 Hashbang)指定该脚本的解释器路径,系统根据此路径调用对应程序执行脚本内容。 -
基本语法
#!解释器绝对路径 -
两种常见指定方式
| 方式 | 示例 | 特点说明 |
|---|---|---|
| 直接指定解释器路径 | #!/bin/bash | 明确指向系统中的 bash 程序,路径固定但缺乏灵活性。 |
| 通过环境变量查找 | #!/usr/bin/env bash | 从 PATH 环境变量中动态查找 bash,兼容性更强,推荐使用! |
-
两种方式的对比与选择建议
-
#!/usr/bin/env bash的优势:- 路径灵活性:避免因不同系统中解释器路径不同(如 macOS 与 Linux 的差异)导致的兼容性问题。
- 版本控制:优先使用
PATH中的新版程序。例如,若用户将新安装的bash 5.0路径添加到PATH,脚本会自动选择新版而非系统默认的旧版。 - 跨平台友好:统一脚本在多种 Unix/Linux 环境下的执行行为。
-
#!/bin/bash的局限性:硬编码路径可能导致的问题:- 系统未安装
/bin/bash时脚本无法运行(如某些精简版 Linux)。 - 无法自动使用用户自定义安装的新版本
bash。
- 系统未安装
-
💡 强烈建议
除非明确需要兼容旧版 Shell,否则脚本应优先使用#!/usr/bin/env bash声明解释器。
1.4 Shell的两种模式
1.4.1 交互模式(Interactive)
-
特征:用户逐行输入命令,立即执行并反馈结果。
-
提示符:通常为
用户名@主机名:~$,等待用户输入。 -
示例:
user@host:~$ ls -l # 执行后立即显示目录内容
1.4.2 非交互模式(Non-Interactive)
-
特征:执行脚本文件或管道命令,无需用户交互。
-
执行方式
user@host:~$ bash script.sh # 显式指定解释器 user@host:~$ ./script.sh # 需脚本有可执行权限(+x) user@host:~$ source script.sh # 在当前Shell执行,影响环境变量 -
关键区别:
-
source或.执行脚本时,不创建子Shell,变量和函数直接影响当前Shell环境。 -
其他方式会创建子Shell,执行完毕后环境变化不保留。
-
2. Shell脚本基础语法
2.1 基本语法规则
2.1.1 注释
-
单行注释:以
#开头。 -
多行注释:使用
:<<EOF ... EOF包裹。# 这是单行注释 :<<EOF 这是多行注释 可跨越多行 EOF
2.1.2 输出命令
-
echo:输出字符串user@host:~$ echo "Hello World" # 普通输出 user@host:~$ echo -e "Line1\nLine2" # -e 启用转义(如换行符) user@host:~$ echo -n "No newline" # -n 不换行 -
printf:格式化输出user@host:~$ printf "%-10s %-8s %-4.2f\n" "Alice" "女" 98.1234 # 输出:Alice 女 98.12-
格式符:
-
%s字符串,%d整数,%f浮点数。 -
-左对齐,数字指定宽度(如%10s),.2保留两位小数。
-
-
2.2 脚本编写与执行
2.2.1 创建第一个脚本
-
编写脚本
helloworld.sh:#!/usr/bin/env bash echo "Hello World" -
赋予执行权限:
chmod +x helloworld.sh # 添加可执行权限 -
执行脚本:
./helloworld.sh # 相对路径执行 /full/path/helloworld.sh # 绝对路径执行 bash helloworld.sh # 显式指定解释器(无需权限)
2.2.2 脚本执行方式对比
| 执行方式 | 是否需要+x权限 | 是否创建子Shell | 环境变量影响范围 |
|---|---|---|---|
bash script.sh | 否 | 是 | 仅子Shell |
./script.sh | 是 | 是 | 仅子Shell |
source script.sh | 否 | 否 | 当前Shell |
. script.sh | 否 | 否 | 当前Shell |
注意事项:
- 权限问题:
./script.sh需先执行chmod +x script.sh。 - 环境变量:若脚本中导出变量(
export VAR=value),只有source或.执行时变量对当前Shell可见。
2.3 案例实操:变量作用域验证
-
脚本内容(
test_env.sh):#!/usr/bin/env bash A=10 export B=20 echo "脚本中:A=$A, B=$B" -
不同执行方式结果对比:
# 方式1:bash test_env.sh bash test_env.sh # 输出:脚本中:A=10, B=20 echo "A=$A, B=$B" # 输出:A= , B= # 方式2:source test_env.sh source test_env.sh # 输出:脚本中:A=10, B=20 echo "A=$A, B=$B" # 输出:A=10, B=20 -
结论:
-
子Shell执行(
bash或./)后变量不保留。 -
source执行后变量保留在当前Shell。
-
2.4 调试技巧
-
语法检查:
bash -n script.sh # 检查语法错误,不执行 -
跟踪执行:
bash -x script.sh # 打印每条命令及其参数
3.变量
-
在脚本中,其值可以发生改变的量被称为变量
-
Shell编程中变量主要分为三类
-
系统预定义变量
-
自定义变量
-
特殊变量
-
3.1 系统预定义变量
3.1.1 常用的系统变量
-
常见的系统变量
-
PATH:定义了系统查找可执行文件的路径。 -
HOME:当前用户的主目录。 -
USER:当前登录的用户名。 -
LANG:定义了系统的语言环境。 -
SHELL:当前使用的 Shell 类型。 -
BASH_VERSION:当前 Bash 的版本号。 -
PWD:当前工作目录。 -
RANDOM:生成一个 0 到 32767 之间的随机数。
-
-
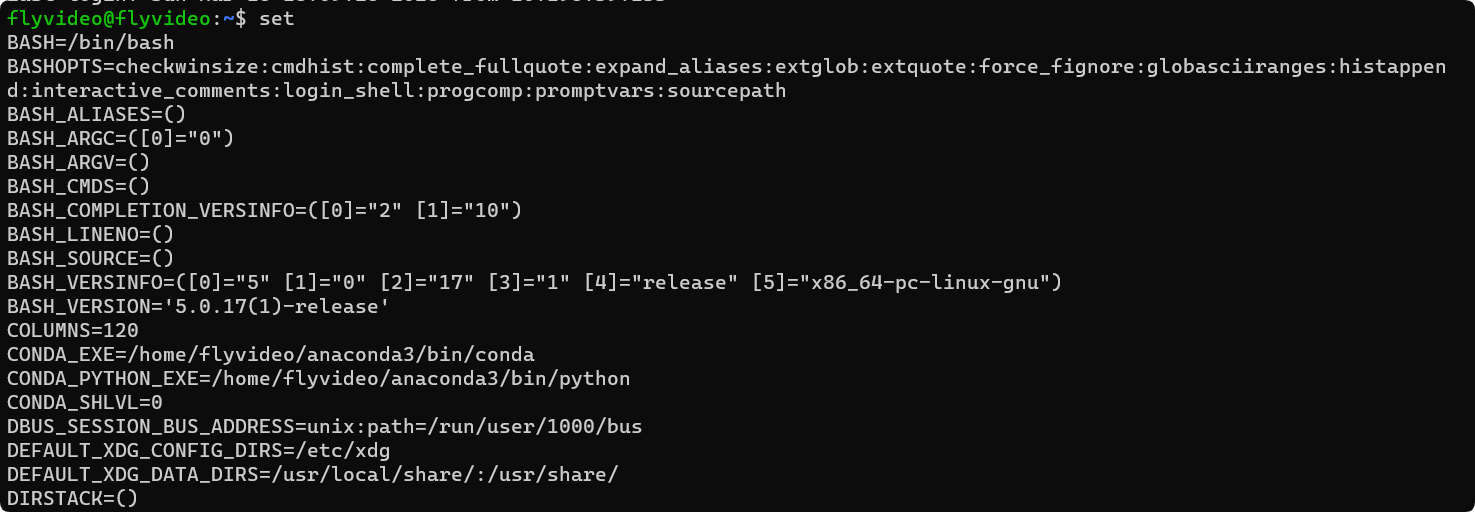
查看系统变量的值:
$变量名

- 可以通过
set命令查看当前系统中的所有变量的值
3.2 自定义变量
3.2.1 基本语法
-
基本语法
- 定义局部变量:变量名=变量值,注意=号前后不能有空格。例如:
name="John Doe" - 声明静态变量/只读变量:readonly 变量名。例如:
readonly name
- 定义局部变量:变量名=变量值,注意=号前后不能有空格。例如:
-
变量定义与命名规则
- 变量名称可以由字母、数字和下划线组成,但是不能以数字开头,环境变量名建议大写。
- 等号两侧不能有空格。
- 在bash中,变量默认类型都是字符串类型,无法直接进行数值运算。如需进行数值运算,需使用特定的语法或命令。
- 变量的值如果有空格,需要使用双引号或单引号括起来。例如:
name="John Doe"或name='John Doe' - 变量名不能使用 bash 里的关键字(可用 help 命令查看保留关键字)。
-
可把变量提升为全局环境变量,可供其他Shell程序使用:
export 变量名
3.2.2 案例实操
-
定义变量A:
[user@host ~]$ A=5 [user@host ~]$ echo $A 5 -
给变量A重新赋值:
[user@host ~]$ A=8 [user@host ~]$ echo $A 8 -
声明静态的变量B=2
[user@host ~]$ readonly B=2 [user@host ~]$ echo $B 2 [user@host ~]$ B=9 -bash: B: readonly variable -
在bash中,变量默认类型都是字符串类型,无法直接进行数值运算:
[user@host ~]$ C=1+2 [user@host ~]$ echo $C 1+2 -
变量的值如果有空格,需要使用双引号或单引号括起来:
[user@host ~]$ D=I love banzhang -bash: world: command not found [user@host ~]$ D="I love banzhang" [user@host ~]$ echo $D I love banzhang
3.3 特殊变量
3.3.1 $n
-
功能描述:n为数字,
$0代表该脚本名称,$1-$9代表第一到第九个参数,十以上的参数,十以上的参数需要用大括号包含,如${10} -
案例实操:
[user@host ~]$ touch parameter.sh [user@host ~]$ vim parameter.sh #!/bin/bash echo '==========$n==========' echo $0 echo $1 echo $2 [user@host ~]$ chmod 777 parameter.sh [user@host ~]$ ./parameter.sh cls xz ==========$n========== ./parameter.sh cls xz
3.3.2 $#
-
功能描述:获取所有输入参数个数,常用于循环。
-
案例实操:
[user@host ~]$ vim parameter.sh #!/bin/bash echo '==========$n==========' echo $0 echo $1 echo $2 echo '==========$#==========' echo $# [user@host ~]$ chmod 777 parameter.sh [user@host ~]$ ./parameter.sh cls xz ==========$n========== ./parameter.sh cls xz ==========$#========== 2
3.3.3 $*与$@
-
基本语法:
-
$*功能描述:这个变量代表命令行中所有的参数,$*把所有的参数看成一个整体 -
$@功能描述:这个变量也代表命令行中所有的参数,不过$@把每个参数区分对待
-
-
案例实操:
[user@host ~]$ vim parameter.sh #!/bin/bash echo '==========$n==========' echo $0 echo $1 echo $2 echo '==========$#==========' echo $# echo '==========$*==========' echo $* echo '==========$@==========' echo $@ [user@host ~]$ ./parameter.sh a b c d e f g ==========$n========== ./parameter.sh a b ==========$#========== 7 ==========$*========== a b c d e f g ==========$@========== a b c d e f g
3.3.4 $?
-
功能描述:最后一次执行的命令的返回状态。如果这个变量的值为0,证明上一个命令正确执行;如果这个变量的值为非0(具体是哪个数,由命令自己来决定),则证明上一个命令执行不正确了。
-
案例实操:判断helloworld.sh脚本是否正确执行
[user@host ~]$ $ ./helloworld.sh hello world [user@host ~]$ $ echo $? 0
3.3.5 $$
-
功能描述:表示当前Shell进程的进程ID(PID)。常用于生成临时文件或唯一标识符。
-
案例实操:输出当前Shell进程的PID,并利用PID创建临时文件:
[user@host ~]$ echo "当前进程PID: $$" 当前进程PID: 1234 # 假设当前Shell的PID为1234 # 使用PID生成唯一临时文件 [user@host ~]$ temp_file="/tmp/data_$$.log" [user@host ~]$ echo "临时文件路径: $temp_file" 临时文件路径: /tmp/data_1234.log
3.3.6 $!
-
功能描述:表示最后一个在后台运行的进程的PID。用于追踪后台任务的状态。
-
案例实操:启动一个后台进程(如
sleep),并检查其PID:[user@host ~]$ sleep 60 & [1] 5678 # 后台进程PID为5678 [user@host ~]$ echo "后台进程PID: $!" 后台进程PID: 5678 # 等待后台进程完成并检查状态 [user@host ~]$ wait $! [user@host ~]$ echo "后台进程退出状态: $?" 后台进程退出状态: 0 # 成功退出
3.3.7 $_
-
功能描述:表示上一个命令的最后一个参数,或当前Shell环境中的最后执行命令的最后一个参数。
- 注意:行为可能因Shell版本或上下文略有不同。
-
案例实操:
-
交互式Shell中:
[user@host ~]$ ls /home/user/documents/file.txt [user@host ~]$ echo $_ # 输出上一个命令的最后一个参数 /home/user/documents/file.txt -
脚本中
#!/bin/bash echo "Hello World" # 最后一个参数是 "World" echo "上一个命令的最后一个参数: $_" # 输出: 上一个命令的最后一个参数: World
-
3.4 访问变量
-
访问变量的语法形式为:
${var}和$var。 -
注意:变量名外面的花括号是可选的,加不加都行,加花括号是为了帮助解释器识别变量的边界,所以推荐加花括号。
-
案例实操:
word="hello" echo ${word} # Output: hello
3.5 删除变量/撤销变量
-
使用 unset 命令可以删除变量,变量被删除后不能再次使用
-
基本语法:
unset 变量名 -
注意事项:unset 命令不能删除只读变量。
-
案例实操:
[user@host ~]$ dword="hello" # 声明变量 [user@host ~]$ echo ${dword} # 输出变量值 # Output: hello [user@host ~]$ unset dword # 删除变量 [user@host ~]$ echo ${dword} # Output: (空)
3.6 字符串
3.6.1 单引号和双引号
shell 字符串可以用单引号 '',也可以用双引号 “”,也可以不用引号。
- 单引号的特点
- 单引号里不识别变量
- 单引号里不能出现单独的单引号(使用转义符也不行),但可成对出现,作为字符串拼接使用。
- 双引号的特点
- 双引号里识别变量
- 双引号里可以出现转义字符
综上,推荐使用双引号。
3.6.2 拼接字符串
# 使用单引号拼接
[user@host ~]$ name1='white'
[user@host ~]$ str1='hello, '${name1}''
[user@host ~]$ str2='hello, ${name1}'
[user@host ~]$ echo ${str1}_${str2}
# Output:
# hello, white_hello, ${name1}
# 使用双引号拼接
[user@host ~]$ name2="black"
[user@host ~]$ str3="hello, "${name2}""
[user@host ~]$ str4="hello, ${name2}"
[user@host ~]$ echo ${str3}_${str4}
# Output:
# hello, black_hello, black
3.6.3 获取字符串长度
[user@host ~]$ text="12345"
[user@host ~]$ echo ${#text}
# Output:
# 5
3.6.4 截取子字符串
[user@host ~]$ text="12345"
[user@host ~]$ echo ${text:2:2} # 从第 3 个字符开始,截取 2 个字符
# Output:
# 34
3.6.5 查找子字符串
[user@host ~]$ vim str-demo5.sh # 查找 `ll` 子字符在 `hello` 字符串中的起始位置。
#!/usr/bin/env bash
text="hello"
echo `expr index "${text}" ll`
[user@host ~]$
[user@host ~]$ ./str-demo5.sh
# Output:
# 3
3.7 数组
-
bash 只支持一维数组。
-
数组下标从 0 开始,下标可以是整数或算术表达式,其值应大于或等于 0。
3.7.1 创建数组
# 创建数组的不同方式
[user@host ~]$ nums=([2]=2 [0]=0 [1]=1)
[user@host ~]$ colors=(red yellow "dark blue")
3.7.2 访问数组元素
- 访问数组的单个元素:
[user@host ~]$ echo ${nums[1]}
# Output: 1
- 访问数组的所有元素:
[user@host ~]$ echo ${colors[*]}
# Output: red yellow dark blue
[user@host ~]$ echo ${colors[@]}
# Output: red yellow dark blue
上面两行有很重要(也很微妙)的区别:
为了将数组中每个元素单独一行输出,我们用 printf 命令:
[user@host ~]$ printf "+ %s\n" ${colors[*]}
# Output:
# + red
# + yellow
# + dark
# + blue
为什么dark和blue各占了一行?尝试用引号包起来:
[user@host ~]$ printf "+ %s\n" "${colors[*]}"
# Output:
# + red yellow dark blue
现在所有的元素都在一行输出 —— 这不是我们想要的!让我们试试${colors[@]}
[user@host ~]$ printf "+ %s\n" "${colors[@]}"
# Output:
# + red
# + yellow
# + dark blue
在引号内,${colors[@]}将数组中的每个元素扩展为一个单独的参数;数组元素中的空格得以保留。
- 访问数组的部分元素:
[user@host ~]$ echo ${nums[@]:0:2}
# Output:
# 0 1
在上面的例子中,${array[@]} 扩展为整个数组,:0:2取出了数组中从 0 开始,长度为 2 的元素。
3.7.3 访问数组长度
[user@host ~]$ echo ${#nums[*]}
# Output:
# 3
3.7.4 向数组中添加元素
向数组中添加元素也非常简单:
[user@host ~]$ colors=(white "${colors[@]}" green black)
[user@host ~]$ echo ${colors[@]}
# Output:
# white red yellow dark blue green black
上面的例子中,${colors[@]} 扩展为整个数组,并被置换到复合赋值语句中,接着,对数组colors的赋值覆盖了它原来的值。
3.7.5 从数组中删除元素
用unset命令来从数组中删除一个元素:
[user@host ~]$ unset nums[0]
[user@host ~]$ echo ${nums[@]}
# Output:
# 1 2
4.运算符
4.1 算术运算符
4.1.1 算是运算符类型
- Shell编程支持多种常见的算术运算符,如下表所示:
| 运算符 | 说明 | 示例 | 输出结果 |
|---|---|---|---|
+ | 加法 | $((5 + 3)) | 8 |
- | 减法 | $((10 - 4)) | 6 |
* | 乘法 | $((2 * 6)) | 12 |
/ | 整数除法 | $((10 / 3)) | 3 |
% | 取模(余数) | $((10 % 3)) | 1 |
= | 赋值 | x=$y | 将把变量 y 的值赋给 x。 |
** | 幂运算(仅限 Bash) | $((2 ** 3)) | 8 |
() | 改变优先级 | $(( (5+3)*2 )) | 16 |
4.1.2 算术运算符语法
-
方式1语法:
$(( 表达式 ))推荐-
特点:
- 直接内嵌在 Shell 中,无需外部命令
- 支持运算符优先级和括号控制运算顺序
- 变量名可省略
$符号(如$((a + b))或$(( $a + $b ))均可)
-
示例:
[user@host ~]$ sum=$((3 + 5 * 2)) # 3+10=13 [user@host ~]$ echo $sum # 输出 13 13 [user@host ~]$ x=10; y=3 [user@host ~]$ mod=$((x % y)) # 10%3=1 [user@host ~]$ echo $mod # 输出 1 1
-
-
方式1语法::
$[ 表达式 ]已过时,不推荐-
特点:
- 功能与
$(( ))类似,但属于旧式语法 - 部分 Shell 环境可能不再支持(如现代 Bash)
- 功能与
-
示例:
[user@host ~]$ result=$[8 / 2 + 1] # 4+1=5 [user@host ~]$ echo $result # 输出 5
-
-
方式3语法:
expr 表达式-
特点:
- 通过外部命令
expr执行运算 - 严格依赖空格分隔操作数和运算符
- 需转义特殊符号(如
*需写为\*)
- 通过外部命令
-
示例:
[user@host ~]$ result=$(expr 2 \* 3) # 2*3=6(注意转义 *) [user@host ~]$ echo $result # 输出 6 6 # 错误写法:expr 5+2(无空格) → 输出字符串 "5+2" # 正确写法:expr 5 + 2 → 输出 7
-
4.1.3 注意事项
-
$(( ))和$[ ]中运算符无需空格:$((5+3))合法 -
expr必须严格分隔:expr 5+3错误 → 需写为expr 5 + 3 -
expr的*、()等需转义:expr 2 \* \( 3 + 1 \)→ 输出 8 -
Shell 默认不支持浮点数运算,除法结果会取整:
[user@host ~]$ echo $((10 / 3)) # 输出 3,非 3.333 -
浮点运算需借助工具(如
bc):[user@host ~]$ echo "scale=2; 10/3" | bc # 输出 3.33 -
在
$(( ))中可直接使用变量名(无需$):[user@host ~]$ a=5; b=3 [user@host ~]$ echo $((a + b)) # 输出 8(等同于 $(( $a + $b )))
4.1.4 案例实操
-
计算(2+3)* 4的值:
[user@host ~]$ S=$[(2+3)*4] [user@host ~]$ echo $S -
计算两数之和:add.sh
[user@host ~]$ vim add.sh #!bin/bash sum=$[$1 + $2] echo sum=$sum [user@host ~]$ chmod +x add.sh [user@host ~]$ ./add.sh 25 89 114
4.2 条件判断运算符
4.2.1 基本语法
-
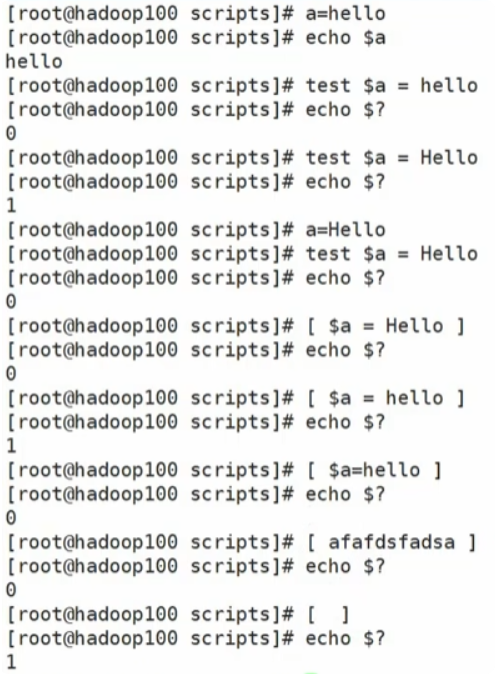
方式1:
test condiction -
方式2:
[ condiction ] -
注意:条件非空即为true,[ atguigu ]返回true,[ ] 返回false。
-
案例演示:
4.2.2 关系运算符
关系运算符只支持数字,不支持字符串,除非字符串的值是数字。
下表列出了常用的关系运算符,假定变量 x 为 10,变量 y 为 20:
| 运算符 | 说明 | 举例 |
|---|---|---|
-eq | 检测两个数是否相等,相等返回 true。 | [ $a -eq $b ]返回 false。 |
-ne | 检测两个数是否相等,不相等返回 true。 | [ $a -ne $b ] 返回 true。 |
-gt | 检测左边的数是否大于右边的,如果是,则返回 true。 | [ $a -gt $b ] 返回 false。 |
-lt | 检测左边的数是否小于右边的,如果是,则返回 true。 | [ $a -lt $b ] 返回 true。 |
-ge | 检测左边的数是否大于等于右边的,如果是,则返回 true。 | [ $a -ge $b ] 返回 false。 |
-le | 检测左边的数是否小于等于右边的,如果是,则返回 true。 | [ $a -le $b ]返回 true。 |
- 案例实操:
[user@host ~]$ x=10; y=20
[user@host ~]$ vim operator-demo.sh
#!bin/bash
echo "x=${x}, y=${y}"
if [[ ${x} -eq ${y} ]]; then
echo "${x} -eq ${y} : x 等于 y"
else
echo "${x} -eq ${y}: x 不等于 y"
fi
if [[ ${x} -ne ${y} ]]; then
echo "${x} -ne ${y}: x 不等于 y"
else
echo "${x} -ne ${y}: x 等于 y"
fi
if [[ ${x} -gt ${y} ]]; then
echo "${x} -gt ${y}: x 大于 y"
else
echo "${x} -gt ${y}: x 不大于 y"
fi
if [[ ${x} -lt ${y} ]]; then
echo "${x} -lt ${y}: x 小于 y"
else
echo "${x} -lt ${y}: x 不小于 y"
fi
if [[ ${x} -ge ${y} ]]; then
echo "${x} -ge ${y}: x 大于或等于 y"
else
echo "${x} -ge ${y}: x 小于 y"
fi
if [[ ${x} -le ${y} ]]; then
echo "${x} -le ${y}: x 小于或等于 y"
else
echo "${x} -le ${y}: x 大于 y"
fi
[user@host ~]$ chmod +x operator-demo.sh
[user@host ~]$ ./operator-demo2.sh # 执行脚本
# x=10, y=20
# 10 -eq 20: x 不等于 y
# 10 -ne 20: x 不等于 y
# 10 -gt 20: x 不大于 y
# 10 -lt 20: x 小于 y
# 10 -ge 20: x 小于 y
# 10 -le 20: x 小于或等于 y
4.2.3 布尔运算符
下表列出了常用的布尔运算符,假定变量 x 为 10,变量 y 为 20:
| 运算符 | 说明 | 举例 |
|---|---|---|
! | 非运算,表达式为 true 则返回 false,否则返回 true。 | [ ! false ] 返回 true。 |
-o | 或运算,有一个表达式为 true 则返回 true。 | [ $a -lt 20 -o $b -gt 100 ] 返回 true。 |
-a | 与运算,两个表达式都为 true 才返回 true。 | [ $a -lt 20 -a $b -gt 100 ] 返回 false。 |
- 案例演示:
[user@host ~]$ x=10; y=20
[user@host ~]$ vim operator-demo.sh
#!bin/bash
echo "x=${x}, y=${y}"
if [[ ${x} != ${y} ]]; then
echo "${x} != ${y} : x 不等于 y"
else
echo "${x} != ${y}: x 等于 y"
fi
if [[ ${x} -lt 100 && ${y} -gt 15 ]]; then
echo "${x} 小于 100 且 ${y} 大于 15 : 返回 true"
else
echo "${x} 小于 100 且 ${y} 大于 15 : 返回 false"
fi
if [[ ${x} -lt 100 || ${y} -gt 100 ]]; then
echo "${x} 小于 100 或 ${y} 大于 100 : 返回 true"
else
echo "${x} 小于 100 或 ${y} 大于 100 : 返回 false"
fi
if [[ ${x} -lt 5 || ${y} -gt 100 ]]; then
echo "${x} 小于 5 或 ${y} 大于 100 : 返回 true"
else
echo "${x} 小于 5 或 ${y} 大于 100 : 返回 false"
fi
[user@host ~]$ chmod +x operator-demo.sh
[user@host ~]$ ./operator-demo2.sh # 执行脚本
# x=10, y=20
# 10 != 20 : x 不等于 y
# 10 小于 100 且 20 大于 15 : 返回 true
# 10 小于 100 或 20 大于 100 : 返回 true
# 10 小于 5 或 20 大于 100 : 返回 false
4.2.4 逻辑运算符
以下介绍 Shell 的逻辑运算符,假定变量 x 为 10,变量 y 为 20:
| 运算符 | 说明 | 举例 |
|---|---|---|
&& | 逻辑与 | [[ ${x} -lt 100 && ${y} -gt 100 ]] 返回 false |
| ` | ` |
- 案例演示:
[user@host ~]$ x=10; y=20
[user@host ~]$ vim operator-demo.sh
#!bin/bash
echo "x=${x}, y=${y}"
if [[ ${x} -lt 100 && ${y} -gt 100 ]]
then
echo "${x} -lt 100 && ${y} -gt 100 返回 true"
else
echo "${x} -lt 100 && ${y} -gt 100 返回 false"
fi
if [[ ${x} -lt 100 || ${y} -gt 100 ]]
then
echo "${x} -lt 100 || ${y} -gt 100 返回 true"
else
echo "${x} -lt 100 || ${y} -gt 100 返回 false"
fi
[user@host ~]$ chmod +x operator-demo.sh
[user@host ~]$ ./operator-demo2.sh # 执行脚本
# x=10, y=20
# 10 -lt 100 && 20 -gt 100 返回 false
# 10 -lt 100 || 20 -gt 100 返回 true
4.2.5 字符串运算符
下表列出了常用的字符串运算符,假定变量 a 为 “abc”,变量 b 为 “efg”:
| 运算符 | 说明 | 举例 |
|---|---|---|
= | 检测两个字符串是否相等,相等返回 true。 | [ $a = $b ] 返回 false。 |
!= | 检测两个字符串是否相等,不相等返回 true。 | [ $a != $b ] 返回 true。 |
-z | 检测字符串长度是否为 0,为 0 返回 true。 | [ -z $a ] 返回 false。 |
-n | 检测字符串长度是否为 0,不为 0 返回 true。 | [ -n $a ] 返回 true。 |
str | 检测字符串是否为空,不为空返回 true。 | [ $a ] 返回 true。 |
- 案例演示:
x="abc"
y="xyz"
echo "x=${x}, y=${y}"
if [[ ${x} = ${y} ]]; then
echo "${x} = ${y} : x 等于 y"
else
echo "${x} = ${y}: x 不等于 y"
fi
if [[ ${x} != ${y} ]]; then
echo "${x} != ${y} : x 不等于 y"
else
echo "${x} != ${y}: x 等于 y"
fi
if [[ -z ${x} ]]; then
echo "-z ${x} : 字符串长度为 0"
else
echo "-z ${x} : 字符串长度不为 0"
fi
if [[ -n "${x}" ]]; then
echo "-n ${x} : 字符串长度不为 0"
else
echo "-n ${x} : 字符串长度为 0"
fi
if [[ ${x} ]]; then
echo "${x} : 字符串不为空"
else
echo "${x} : 字符串为空"
fi
# Execute: ./operator-demo5.sh
# Output:
# x=abc, y=xyz
# abc = xyz: x 不等于 y
# abc != xyz : x 不等于 y
# -z abc : 字符串长度不为 0
# -n abc : 字符串长度不为 0
# abc : 字符串不为空
6.6. 文件测试运算符
文件测试运算符用于检测 Unix 文件的各种属性。
属性检测描述如下:
| 操作符 | 说明 | 举例 |
|---|---|---|
| -b file | 检测文件是否是块设备文件,如果是,则返回 true。 | [ -b $file ] 返回 false。 |
| -c file | 检测文件是否是字符设备文件,如果是,则返回 true。 | [ -c $file ] 返回 false。 |
| -d file | 检测文件是否是目录,如果是,则返回 true。 | [ -d $file ] 返回 false。 |
| -f file | 检测文件是否是普通文件(既不是目录,也不是设备文件),如果是,则返回 true。 | [ -f $file ] 返回 true。 |
| -g file | 检测文件是否设置了 SGID 位,如果是,则返回 true。 | [ -g $file ] 返回 false。 |
| -k file | 检测文件是否设置了粘着位(Sticky Bit),如果是,则返回 true。 | [ -k $file ]返回 false。 |
| -p file | 检测文件是否是有名管道,如果是,则返回 true。 | [ -p $file ] 返回 false。 |
| -u file | 检测文件是否设置了 SUID 位,如果是,则返回 true。 | [ -u $file ] 返回 false。 |
| -r file | 检测文件是否可读,如果是,则返回 true。 | [ -r $file ] 返回 true。 |
| -w file | 检测文件是否可写,如果是,则返回 true。 | [ -w $file ] 返回 true。 |
| -x file | 检测文件是否可执行,如果是,则返回 true。 | [ -x $file ] 返回 true。 |
| -s file | 检测文件是否为空(文件大小是否大于 0),不为空返回 true。 | [ -s $file ] 返回 true。 |
| -e file | 检测文件(包括目录)是否存在,如果是,则返回 true。 | [ -e $file ] 返回 true。 |
- 案例演示:
file="/etc/hosts"
if [[ -r ${file} ]]; then
echo "${file} 文件可读"
else
echo "${file} 文件不可读"
fi
if [[ -w ${file} ]]; then
echo "${file} 文件可写"
else
echo "${file} 文件不可写"
fi
if [[ -x ${file} ]]; then
echo "${file} 文件可执行"
else
echo "${file} 文件不可执行"
fi
if [[ -f ${file} ]]; then
echo "${file} 文件为普通文件"
else
echo "${file} 文件为特殊文件"
fi
if [[ -d ${file} ]]; then
echo "${file} 文件是个目录"
else
echo "${file} 文件不是个目录"
fi
if [[ -s ${file} ]]; then
echo "${file} 文件不为空"
else
echo "${file} 文件为空"
fi
if [[ -e ${file} ]]; then
echo "${file} 文件存在"
else
echo "${file} 文件不存在"
fi
# Execute: ./operator-demo6.sh
# Output:(根据文件的实际情况,输出结果可能不同)
# /etc/hosts 文件可读
# /etc/hosts 文件可写
# /etc/hosts 文件不可执行
# /etc/hosts 文件为普通文件
# /etc/hosts 文件不是个目录
# /etc/hosts 文件不为空
# /etc/hosts 文件存在
5.流程控制(重点)
- 跟其它程序设计语言一样,Bash 中的条件语句让我们可以决定一个操作是否被执行。结果取决于一个包在
[[ ]]里的表达式。由[[ ]](sh中是[ ])包起来的表达式被称作 检测命令 或 基元。这些表达式帮助我们检测一个条件的结果。共有两个不同的条件表达式:if和case。
5.1 if条件语句
5.1.1 单分支判断
-
语法:
if [ 条件判断式 ];then 程序 fi # 或者 if [ 条件判断式 ] then 程序 fi -
案例演示:
# 写成一行 if [[ 1 -eq 1 ]]; then echo "1 -eq 1 result is: true"; fi # Output: 1 -eq 1 result is: true # 写成多行 if [[ "abc" -eq "abc" ]] then echo ""abc" -eq "abc" result is: true" fi # Output: abc -eq abc result is: true
5.1.2 多分支判断
-
语法:
# 方式1: if [ 条件判断式 ] then 程序 else 程序 fi # 方式2: if [ 条件判断式 ] then 程序 elif [ 条件判断式 ] then 程序 else 程序 fi -
案例演示:
if [[ 2 -ne 1 ]]; then echo "true" else echo "false" fi # Output: true x=10 y=20 if [[ ${x} > ${y} ]]; then echo "${x} > ${y}" elif [[ ${x} < ${y} ]]; then echo "${x} < ${y}" else echo "${x} = ${y}" fi # Output: 10 < 20
5.1.3 注意事项:
- [ 条件判断式 ],中括号和条件判断式之间必须有空格
if后要有空格
5.2 case条件语句
-
基本语法:
case $变量名 in "值1") 如果变量的值等于值1,则执行程序1 ;; "值2") 如果变量的值等于值2,则执行程序2 ;; …省略其他分支… *) 如果变量的值都不是以上的值,则执行此程序 ;; esac -
注意事项:
- case行尾必须为单词“in”,每一个模式匹配必须以右括号“)”结束。
- 双分号“;;”表示命令序列结束,相当于java中的break。
- 最后的“*)”表示默认模式,相当于java中的default。
-
案例演示:
case ${oper} in "+") val=`expr ${x} + ${y}` echo "${x} + ${y} = ${val}" ;; "-") val=`expr ${x} - ${y}` echo "${x} - ${y} = ${val}" ;; "*") val=`expr ${x} \* ${y}` echo "${x} * ${y} = ${val}" ;; "/") val=`expr ${x} / ${y}` echo "${x} / ${y} = ${val}" ;; *) echo "Unknown oper!" ;; esac
5.3 for循环
5.3.1 基本语法1
-
语法格式:
for (( 初始值;循环控制条件;变量变化 )) do 程序 done -
案例实操1:从1加到100
[user@host ~]$ touch for1.sh [user@host ~]$ vim for1.sh #!/bin/bash sum=0 for ((i=0;i<=100;i++)) do sum=$[$sum+$i] done echo $sum [user@host ~]$ chmod 777 for1.sh [user@host ~]$ ./for1.sh 5050
5.3.1 基本语法2
-
语法格式:
for 变量 in 值1 值2 值3… do 程序 done -
案例实操1:打印所有输入参数
[user@host ~]$ touch for2.sh [user@host ~]$ vim for2.sh #!/bin/bash #打印数字 for i in cls mly wls do echo "ban zhang love $i" done [user@host ~]$ chmod 777 for2.sh [user@host ~]$ ./for2.sh ban zhang love cls ban zhang love mly ban zhang love wls -
案例实操2:比较
$*和$@区别-
$*和$@都表示传递给函数或脚本的所有参数,不被双引号“”包含时,都以$1 $2 ... $n的形式输出所有参数。[user@host ~]$ touch for3.sh [user@host ~]$ vim for3.sh #!/bin/bash echo '=============$*=============' for i in $* do echo "ban zhang love $i" done echo '=============$@=============' for j in $@ do echo "ban zhang love $j" done [user@host ~]$ chmod 777 for3.sh [user@host ~]$ ./for3.sh cls mly wls =============$*============= banzhang love cls banzhang love mly banzhang love wls =============$@============= banzhang love cls banzhang love mly banzhang love wls -
当它们被双引号“”包含时,
$*会将所有的参数作为一个整体,以$1 $2 …$n的形式输出所有参数;$@会将各个参数分开,以$1 $2 … $n的形式输出所有参数。[user@host ~]$ vim for4.sh #!/bin/bash echo '=============$*=============' for i in "$*" #$*中的所有参数看成是一个整体,所以这个for循环只会循环一次 do echo "ban zhang love $i" done echo '=============$@=============' for j in "$@" #$@中的每个参数都看成是独立的,所以“$@”中有几个参数,就会循环几次 do echo "ban zhang love $j" done [user@host ~]$ chmod 777 for4.sh [user@host ~]$ ./for4.sh cls mly wls =============$*============= banzhang love cls mly wls =============$@============= banzhang love cls banzhang love mly banzhang love wls
-
6.4 while循环
-
语法格式:
while [ 条件判断式 ] do 程序 done -
案例演示:从1加到100
[user@host ~]$ touch while.sh [user@host ~]$ vim while.sh #!/bin/bash sum=0 i=1 while [ $i -le 100 ] do sum=$[$sum+$i] i=$[$i+1] done echo $sum [user@host ~]$ chmod 777 while.sh [user@host ~]$ ./while.sh 5050
6.5 until循环
-
until循环跟while循环正好相反。它跟while一样也需要检测一个测试条件,但不同的是,只要该条件为 假 就一直执行循环:[user@host ~]$ touch until.sh [user@host ~]$ vim until.sh #!/bin/bash x=0 until [[ ${x} -ge 5 ]]; do echo ${x} x=`expr ${x} + 1` done [user@host ~]$ chmod 777 until.sh [user@host ~]$ ./until.sh 0 1 2 3 4
6.6 select循环
-
select循环帮助我们组织一个用户菜单。它的语法几乎跟for循环一致:select answer in elem1 elem2 ... elemN do ### 语句 done -
说明:
select会打印elem1..elemN以及它们的序列号到屏幕上,之后会提示用户输入。通常看到的是$?(PS3变量)。用户的选择结果会被保存到answer中。如果answer是一个在1..N之间的数字,那么语句会被执行,紧接着会进行下一次迭代 —— 如果不想这样的话我们可以使用break语句。 -
案例演示:
[user@host ~]$ vim select.sh #!/usr/bin/env bash PS3="Choose the package manager: " select ITEM in bower npm gem pip do echo -n "Enter the package name: " && read PACKAGE case ${ITEM} in bower) bower install ${PACKAGE} ;; npm) npm install ${PACKAGE} ;; gem) gem install ${PACKAGE} ;; pip) pip install ${PACKAGE} ;; esac break # 避免无限循环 done [user@host ~]$ vim select.sh 1) bower 2) npm 3) gem 4) pip Choose the package manager: 2 Enter the package name: gitbook-cli
PS3是 Bash 中用于设置select语句提示符的变量。这里将其设置为"Choose the package manager: ",作为用户选择包管理器时的提示信息。
6.7 break 和 continue
-
如果想提前结束一个循环或跳过某次循环执行,可以使用 shell 的
break和continue语句来实现。它们可以在任何循环中使用。break语句用来提前结束当前循环。continue语句用来跳过某次迭代。
-
案例演示1:
# 查找 10 以内第一个能整除 2 和 3 的正整数 i=1 while [[ ${i} -lt 10 ]]; do if [[ $((i % 3)) -eq 0 ]] && [[ $((i % 2)) -eq 0 ]]; then echo ${i} break; fi i=`expr ${i} + 1` done # Output: 6 -
案例演示2:
# 打印10以内的奇数 for (( i = 0; i < 10; i ++ )); do if [[ $((i % 2)) -eq 0 ]]; then continue; fi echo ${i} done # Output: # 1 # 3 # 5 # 7 # 9
7.read读取控制台输入
-
基本语法:
read (选项) (参数) -
选项:
- -p:指定读取值时的提示符;
- -t:指定读取值时等待的时间(秒)。
-
参数
- 变量:指定读取值的变量名
-
案例实操:提示7秒内,读取控制台输入的名称
[user@host ~]$ touch read.sh [user@host ~]$ vim read.sh #!/bin/bash read -t 7 -p "Enter your name in 7 seconds :" NAME echo $NAME [user@host ~]$ ./read.sh Enter your name in 7 seconds : atguigu atguigu
8.函数
8.1 系统函数
8.1.1 basename
-
功能描述:basename命令会删掉所有的前缀包括最后一个(‘/’)字符,然后将字符串显示出来。
-
基本语法:
basename [string / pathname] [suffix] -
选项:
- suffix为后缀,如果suffix被指定了,basename会将pathname或string中的suffix去掉。
-
案例实操:截取该/home/atguigu/banzhang.txt路径的文件名称
[user@host ~]$ basename /home/atguigu/banzhang.txt banzhang.txt [user@host ~]$ basename /home/atguigu/banzhang.txt .txt banzhang
8.1.2 dirname
-
功能描述:从给定的包含绝对路径的文件名中去除文件名(非目录的部分),然后返回剩下的路径(目录的部分)
-
基本语法:
dirname 文件绝对路径 -
案例实操:获取banzhang.txt文件的路径
[atguigu@hadoop101 ~]$ dirname /home/atguigu/banzhang.txt /home/atguigu
8.2 自定义函数
8.2.1 基本语法
-
语法格式:
[ function ] functionname [()] { action; [return int;] } -
注意事项:
- 函数定义时,
function关键字可有可无,同时其它部分被[]包裹的内容都可以被省略 - 调用函数前必须先声明。Shell 脚本按行执行,不会像编译型语言那样预先编译,因此函数需在使用前定义完毕,建议将所有函数置于脚本开头。调用时只需使用函数名。
- 函数的返回值通过系统变量
$?获取。可使用return明确返回值,若无return,则以函数内最后一条命令的执行结果作为返回值。return后的值为整数(0-255),且只能是整数(0-255),用以表示函数的返回值。- 若无
return,Shell 默认取函数内最后一条命令的执行结果作为返回值。
- 函数定义时,
8.2.2 案例实操
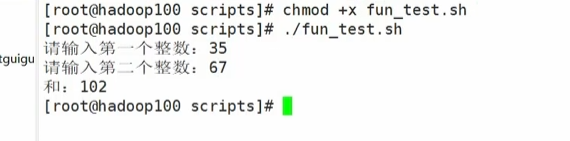
计算两个输入参数的和
[user@host ~]$ touch fun.sh
[user@host ~]$ vim fun.sh
#!/bin/bash
function sum(){
s=0
s=$[$1+$2]
echo "$s"
}
read -p "Please input the number1: " n1;
read -p "Please input the number2: " n2;
sum $n1 $n2;
[user@host ~]$ chmod 777 fun.sh
[user@host ~]$ ./fun.sh
Please input the number1: 2
Please input the number2: 5
7
8.3 综合案例:归档文件
-
案例需求:实现一个每天对指定目录归档备份的脚本,输入一个目录名称(末尾不带/),将目录下所有文件按天归档保存,并将归档日期附加在归档文件名上,放在
/root/archive下 -
脚本实现:
#!/bin/bash # -------------------------- # 功能:目录归档备份脚本 # 用法:./archive_backup.sh [目录路径] # 示例:./archive_backup.sh /opt/data # -------------------------- # 1. 检查参数个数 if [ $# -ne 1 ]; then echo "错误:参数个数不正确!请输入一个目录路径(末尾不带/)。" exit 1 fi # 2. 检查目录是否存在 if [ ! -d "$1" ]; then echo "错误:目录 '$1' 不存在!" exit 1 fi # 3. 提取目录名和父路径 DIR_NAME=$(basename "$1") # 目录名称(如 data) DIR_PATH=$(cd "$(dirname "$1")" && pwd) # 目录绝对路径(如 /opt) # 4. 创建归档存储目录(若不存在) ARCHIVE_DIR="/root/archive" mkdir -p "$ARCHIVE_DIR" || { echo "无法创建归档目录 $ARCHIVE_DIR"; exit 1; } # 5. 生成日期戳(格式:年月日) DATE=$(date +%Y%m%d) # 示例输出 20231225 # 6. 定义归档文件名和路径 ARCHIVE_FILE="archive_${DIR_NAME}_${DATE}.tar.gz" DEST_PATH="${ARCHIVE_DIR}/${ARCHIVE_FILE}" # 7. 执行归档压缩命令 echo "正在归档目录:$1 → $DEST_PATH" tar -czf "$DEST_PATH" -C "$DIR_PATH" "$DIR_NAME" # 8. 检查命令执行结果 if [ $? -eq 0 ]; then echo "归档成功!文件大小:$(du -h "$DEST_PATH" | cut -f1)" else echo "归档失败!请检查错误日志。" exit 1 fi
9.正则表达式与 grep 命令
9.1 grep 命令简介
-
grep(Global Regular Expression Print)是 Linux 中强大的文本搜索工具,通过正则表达式匹配文本内容。 -
基本语法:
grep [选项] '模式' 文件 -
常用选项:
-
-n:显示匹配行的行号 -
-i:忽略大小写 -
-v:反向匹配(显示不包含模式的行) -
-E:启用扩展正则表达式(等同于egrep)
-
9.2 基础正则表达式
9.2.1 特殊字符及功能
| 符号 | 功能 | 示例 | 说明 |
|---|---|---|---|
^ | 匹配行首 | grep '^a' file | 匹配以 a 开头的行 |
$ | 匹配行尾 | grep 't$' file | 匹配以 t 结尾的行 |
. | 匹配任意单个字符 | grep 'r..t' file | 匹配如 root、rabt 的行 |
* | 匹配前一个字符 0 次或多次 | grep 'ro*t' file | 匹配 rt、rot、root 等 |
[] | 匹配字符集合中的任意一个字符 | grep '[aeiou]' file | 匹配包含任意元音字母的行 |
[^] | 匹配不在字符集合中的任意一个字符 | grep '[^0-9]' file | 匹配包含非数字字符的行 |
\ | 转义特殊字符 | grep 'a\$b' file | 匹配包含 a$b 的行 |
9.2.2 字符集合范围
| 表达式 | 匹配范围 |
|---|---|
[0-9] | 任意数字字符 |
[a-z] | 任意小写字母 |
[A-Z] | 任意大写字母 |
[a-zA-Z] | 任意字母(不区分大小写) |
[^a-z] | 非小写字母的任意字符 |
9.2.3 重复匹配
| 表达式 | 功能 |
|---|---|
\{n\} | 前一个字符连续出现 n 次 |
\{n,\} | 前一个字符至少出现 n 次 |
\{n,m\} | 前一个字符出现 n 到 m 次 |
示例:
grep 'o\{2\}' file # 匹配包含 `oo` 的行
grep 'go\{2,3\}d' file # 匹配 `good` 或 `goood`
9.3 扩展正则表达式
- 使用
grep -E或egrep启用扩展正则表达式。
9.3.1 扩展特殊字符
| 符号 | 功能 | 示例 | 说明 |
|---|---|---|---|
+ | 匹配前一个字符 1 次或多次 | egrep 'go+d' file | 匹配 god、good、goood |
? | 匹配前一个字符 0 次或 1 次 | egrep 'go?d' file | 匹配 gd 或 god |
| ` | ` | 逻辑“或”匹配多个模式 | `egrep 'gd |
() | 分组匹配 | `egrep 'g(la | oo)d’ file` |
{} | 指定重复次数(无需转义) | egrep 'o{2}' file | 匹配连续两个 o |
9.3.2 复杂示例
# 匹配连续出现的 "xyz" 至少一次,并以 "C" 结尾
echo 'AxyzxyzxyzxyzC' | egrep 'A(xyz)+C'
# 匹配 "gd" 或 "good",并显示行号
egrep -n 'gd|good' file.txt
9.4 正则表达式 vs 通配符
| 场景 | 正则表达式 | 通配符(如 ls 命令) |
|---|---|---|
| 匹配逻辑 | 用于文本内容匹配(如 grep) | 用于文件名匹配(如 ls) |
| 符号差异 | . 表示任意字符 | * 表示任意多个字符 |
| 示例 | `ls | grep ‘^a.*’` |
示例对比:
# 使用正则表达式匹配文件名以 a 开头的文件
ls | grep '^a.*'
# 使用通配符直接列出以 a 开头的文件
ls -l a*
9.5 综合案例
-
查找
/etc目录下的符号链接文件:ls -l /etc | grep '^l' # 输出示例: # lrwxrwxrwx. 1 root root 20 Jan 1 00:00 grub.conf -> ../boot/grub2/grub.cfg -
过滤空白行和注释行:
# 基础正则表达式(需两次过滤) grep -v '^$' file | grep -v '^#' # 扩展正则表达式(一次过滤) egrep -v '^$|^#' file
9.6 注意事项
- 转义字符:
- 在基础正则表达式中,
{ }、+、|等符号需用\转义(如\+)。 - 在扩展正则表达式中,无需转义。
- 在基础正则表达式中,
- 字符集顺序:
[a-z]表示小写字母范围,但受语言环境(LC_ALL)影响,可能包含非常见字母(如é)。 - 性能优化:
- 精确匹配时,避免过度使用
.*(如^abc.*可简化为^abc)。 - 复杂正则表达式可拆分为多个
grep管道操作。
- 精确匹配时,避免过度使用

🌈欢迎和毛毛张一起探讨和交流!
联系方式点击下方个人名片


















 808
808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











