







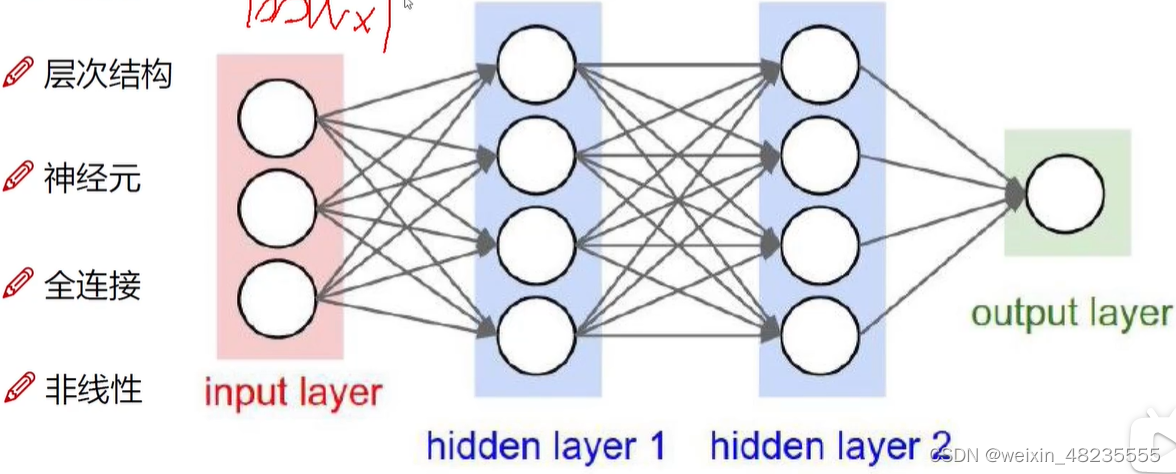
神经网络的整体架构
神经网络是一种模拟人脑的神经网络来处理信息的算法,主要用于机器学习和人工智能领域。它们由相互连接的节点(或称为“神经元”)组成,这些节点可以接收输入,进行计算,并产生输出。
基本架构
-
输入层(Input Layer):
- 输入层接收外部数据,并将数据传递给网络中的下一层。
- 不进行任何计算。
-
隐藏层(Hidden Layers):
- 一个或多个隐藏层执行复杂的计算。
- 每个隐藏层包含一定数量的神经元。
-
输出层(Output Layer):
- 输出层产生最终的结果或预测。
- 结构取决于特定任务(如分类、回归)。
神经元和激活函数
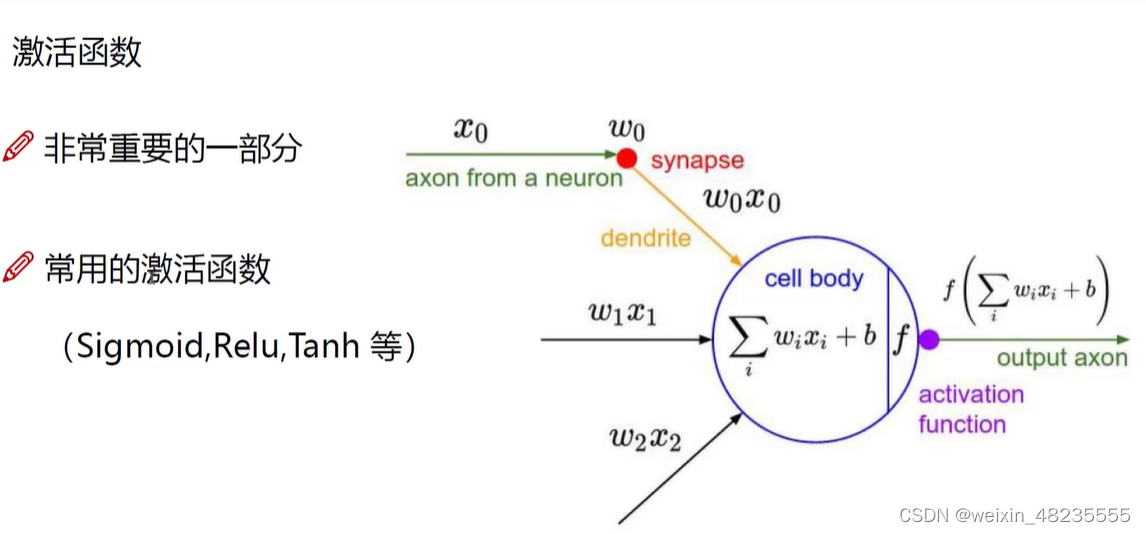
- 神经元是神经网络的基本单元,负责接收输入、计算和传递信号。
- 激活函数决定了神经元是否应该被激活,从而影响网络的输出。常见的激活函数包括 Sigmoid、ReLU、Tanh 等。
前向传播和反向传播
- 前向传播:数据从输入层开始,经过隐藏层,最后到达输出层。
- 反向传播:通过计算梯度并调整网络参数(如权重和偏置),以最小化预测和实际结果之间的差异。
网络训练
- 网络通过损失函数(如均方误差、交叉熵)来衡量预测的准确性。
- 使用优化算法(如梯度下降)来调整网络参数,以减少损失函数的值。
相关公式
- 神经元输出:
o
=
f
(
∑
i
=
1
n
w
i
x
i
+
b
)
o = f(\sum_{i=1}^{n} w_i x_i + b)
o=f(∑i=1nwixi+b)
- o o o 是输出
- f f f 是激活函数
- w i w_i wi 是权重
- x i x_i xi 是输入
-
b
b
b 是偏置

Python 示例代码
import numpy as np
import tensorflow as tf
# 创建简单的神经网络
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(10, activation='relu', input_shape=(input_size,)), # 隐藏层
tf.keras.layers.Dense(output_size, activation='softmax') # 输出层
])
# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, epochs=10)
K-近邻算法 (KNN)
K-近邻算法是一种基本且广泛使用的分类和回归算法。其基本原理是在特征空间中找到与测试点最近的 K 个训练点,并基于这些最近点的信息来预测测试点的标签。
基本步骤
-
选择 K 值:确定一个正整数 K,作为最近邻的数量。
-
计算距离:对于测试数据点,计算它与每个训练数据点之间的距离。
-
找到最近的 K 个邻居:从训练数据集中选出与测试点距离最近的 K 个点。
-
进行投票或平均:对于分类任务,根据这 K 个邻居的类别进行投票,类别出现次数最多的作为预测类别;对于回归任务,则计算这 K 个邻居的输出变量的平均值作为预测结果。
距离计算公式
最常用的距离度量是欧几里得距离,给定两点 x 1 x_1 x1 和 x 2 x_2 x2,其欧几里得距离公式为:
d ( x 1 , x 2 ) = ∑ i = 1 n ( x 1 i − x 2 i ) 2 d(x_1, x_2) = \sqrt{\sum_{i=1}^{n}(x_{1i} - x_{2i})^2} d(x1,x2)=i=1∑n(x1i−x2i)2
其中, n n n 是特征的数量, x 1 i x_{1i} x1i 和 x 2 i x_{2i} x2i 分别是两个点在第 i i i 个特征上的值。
Python 代码示例
以下是使用 Python 中的 scikit-learn 库进行 K-近邻分类的一个简单示例:
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 载入数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 创建 KNN 分类器实例
knn = KNeighborsClassifier(n_neighbors=3)
# 训练模型
knn.fit(X_train, y_train)
# 进行预测
predictions = knn.predict(X_test)
缺点:
- k近邻不知道图像中哪一部分是主体,哪一部分是背景,因为这个算法不会学习
- 不适合做图像分类
损失函数:
损失函数(Loss Function)是用于衡量模型预测值与真实值之间差异的函数,在机器学习中用于指导模型的优化。
-
均方误差(Mean Squared Error, MSE)
均方误差是回归问题中最常用的损失函数,计算预测值与真实值之差的平方的平均值。
公式:
MSE ( y , y ^ ) = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 \text{MSE}(y, \hat{y}) = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 MSE(y,y^)=n1i=1∑n(yi−y^i)2
其中, y i y_i yi 是真实值, y ^ i \hat{y}_i y^i 是预测值, n n n 是样本数。
-
绝对误差(Mean Absolute Error, MAE)
绝对误差是一种常用于回归问题的损失函数,用于衡量预测值与实际值之间的平均绝对差异。
公式:
M A E = 1 n ∑ i = 1 n ∣ y i − y i ^ ∣ MAE = \frac{1}{n} \sum_{i=1}^{n} |y_i - \hat{y_i}| MAE=n1i=1∑n∣yi−yi^∣
其中, y i y_i yi 是第 i i i 个观测值的真实值, y i ^ \hat{y_i} yi^ 是模型对第 i i i 个观测值的预测值, n n n 是样本总数。
高损失值表明模型的预测结果与真实结果差异较大,即模型的准确度低。
Softmax 分类器
Softmax 分类器是一种常用于多类别分类问题的方法。它是逻辑回归在多分类问题上的推广。
基本原理
在 softmax 分类器中,每个类别都有自己的一组权重,而分类的决策是基于计算出的概率最大的类别。Softmax 函数可以将一个含任意实数的 K 维向量“压缩”到另一个 K 维实向量中,使得每一个元素的范围都在 (0, 1) 之间,并且所有元素的和为 1。
Softmax 函数
对于一个输入向量 x ∈ R n x \in \mathbb{R}^n x∈Rn,softmax 函数定义为:
σ ( x ) j = e x j ∑ k = 1 K e x k for j = 1 , … , K \sigma(x)_j = \frac{e^{x_j}}{\sum_{k=1}^{K} e^{x_k}} \quad \text{for } j = 1, \ldots, K σ(x)j=∑k=1Kexkexjfor j=1,…,K
其中, x j x_j xj 是向量 x x x 的第 j j j 个分量, K K K 是类别的总数。
交叉熵损失函数
在训练 softmax 分类器时,通常使用交叉熵损失函数,它的公式为:
L = − ∑ i = 1 N ∑ k = 1 K y i k log ( y ^ i k ) L = -\sum_{i=1}^{N} \sum_{k=1}^{K} y_{ik} \log(\hat{y}_{ik}) L=−i=1∑Nk=1∑Kyiklog(y^ik)
其中, N N N 是样本的数量, y i k y_{ik} yik 是第 i i i 个样本属于第 k k k 类的真实概率(一般用 one-hot 编码), y ^ i k \hat{y}_{ik} y^ik 是模型预测第 i i i 个样本属于第 k k k 类的概率。
线性分类器的前向传播
线性分类器使用权重矩阵 W W W 和输入特征向量 x x x 来计算得分向量 f f f,该过程可表示为:
f = W x f = Wx f=Wx
这里, f f f 通常被称为 logits 或者分数(scores),它是一个向量,其中的每个元素对应于输入 x x x 被分类到某个类别的原始得分。
铰链损失(Hinge Loss)
为了训练分类器,需要定义一个损失函数,以衡量模型预测得分与真实标签之间的差异。对于每个训练样本的损失 L i L_i Li,铰链损失定义为:
L i = ∑ j ≠ y i max ( 0 , s j − s y i + 1 ) L_i = \sum_{j \neq y_i} \max(0, s_j - s_{y_i} + 1) Li=j=yi∑max(0,sj−syi+1)
这里:
- s s s 是模型输出的得分向量。
- s j s_j sj 是第 j j j 类的得分。
- s y i s_{y_i} syi 是正确类别 y i y_i yi 的得分。
- max ( 0 , ⋅ ) \max(0, \cdot) max(0,⋅) 函数确保损失是非负的,只有当正确类别的得分不高于其他类别的得分加上一个边际(通常设置为 1)时才会产生损失。
正则化项
除了损失函数,通常还会在目标函数中包含一个正则化项 R ( W ) R(W) R(W),以防止模型过拟合。这可以通过对权重矩阵 W W W 施加某种形式的惩罚来实现,常见的正则化项包括 L2 正则化。
总损失函数
模型的总损失 L L L 是每个样本损失 L i L_i Li 的平均值加上正则化项:
L = 1 N ∑ i = 1 N L i + λ R ( W ) L = \frac{1}{N} \sum_{i=1}^{N} L_i + \lambda R(W) L=N1i=1∑NLi+λR(W)
这里:
- N N N 是训练样本的总数。
- λ \lambda λ 是正则化强度的超参数。
分类器的训练过程就是通过梯度下降等优化算法来最小化总损失 L L L。
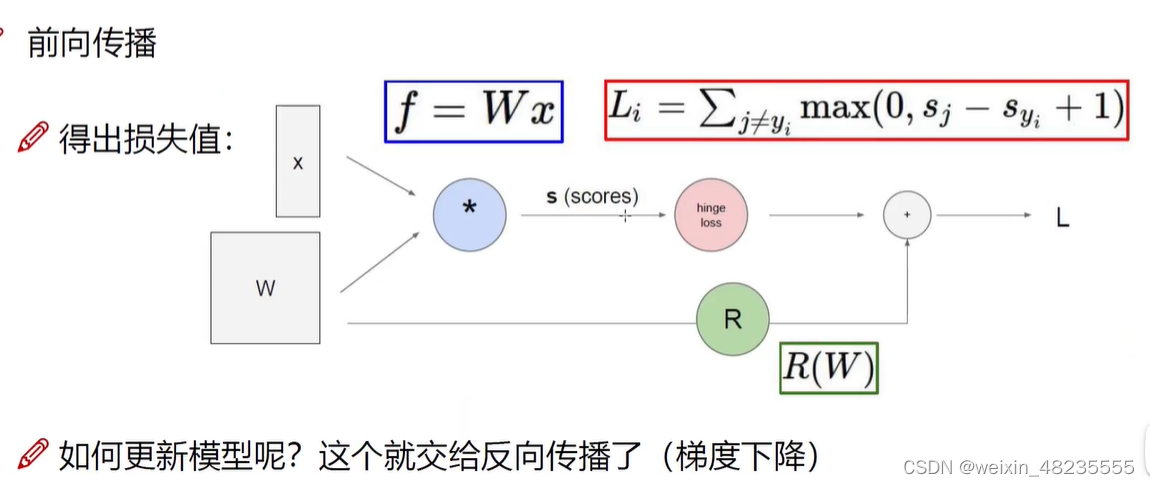
如何更新模型呢?这个就交给反向传播了 (梯度下降)
梯度下降 (Gradient Descent)
梯度下降是一种常用的优化算法,用于寻找函数的局部最小值。在机器学习中,梯度下降被广泛用于最小化损失函数,即寻找能够使损失函数最小的参数值。
基本原理
梯度下降的基本思想是:从一个随机的初始点开始,迭代地移动到函数值下降最快的方向,即负梯度方向。
数学描述
假设有一个可微的函数 f ( θ ) f(\theta) f(θ),其中 θ \theta θ 是参数向量。梯度下降的目标是找到 θ \theta θ 的值,使得 f ( θ ) f(\theta) f(θ) 最小。
-
梯度(Gradient):
函数 f ( θ ) f(\theta) f(θ) 在点 θ \theta θ 的梯度是该点函数值上升最快的方向。梯度的每个分量可以通过偏导数来计算:
∇ f ( θ ) = ( ∂ f ∂ θ 1 , ∂ f ∂ θ 2 , . . . , ∂ f ∂ θ n ) \nabla f(\theta) = \left( \frac{\partial f}{\partial \theta_1}, \frac{\partial f}{\partial \theta_2}, ..., \frac{\partial f}{\partial \theta_n} \right) ∇f(θ)=(∂θ1∂f,∂θ2∂f,...,∂θn∂f)
-
更新规则:
在每次迭代中,参数 θ \theta θ 按照梯度的反方向更新:
θ next = θ − α ∇ f ( θ ) \theta_{\text{next}} = \theta - \alpha \nabla f(\theta) θnext=θ−α∇f(θ)
其中, α \alpha α 是学习率,决定了在梯度方向上前进的步长。
算法步骤
- 选择初始参数 θ \theta θ 和学习率 α \alpha α。
- 计算当前参数下的梯度 ∇ f ( θ ) \nabla f(\theta) ∇f(θ)。
- 更新参数 θ = θ − α ∇ f ( θ ) \theta = \theta - \alpha \nabla f(\theta) θ=θ−α∇f(θ)。
- 重复步骤 2 和 3,直到达到收敛条件,比如梯度足够小或达到预定的迭代次数。
Python 代码示例
以下是使用 Python 实现的简单梯度下降算法示例:
def gradient_descent(f_grad, start, alpha, num_iters):
"""梯度下降算法的简单实现。
参数:
f_grad -- 目标函数的梯度函数
start -- 初始点
alpha -- 学习率
num_iters -- 迭代次数
"""
theta = start
for _ in range(num_iters):
grad = f_grad(theta)
theta = theta - alpha * grad
return theta
# 示例:求 f(x) = x^2 的最小值
def f_grad(x):
return 2 * x # f(x) = x^2 的导数
theta_start = 10 # 初始值
alpha = 0.1 # 学习率
num_iters = 100 # 迭代次数
theta_optimal = gradient_descent(f_grad, theta_start, alpha, num_iters)
print("Optimal theta:", theta_optimal)
激活函数:
它们引入非线性因素,使得神经网络能够学习和执行更复杂的任务。
1. Sigmoid 函数
Sigmoid 函数是一种将输入值压缩到 0 和 1 之间的激活函数。
-
公式:
σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1 + e^{-x}} σ(x)=1+e−x1
sigmoid容易梯度消失
2. ReLU 函数
ReLU(Rectified Linear Unit)函数是最常用的激活函数之一,主要用于隐藏层。
Relu是主流。
其数学表达式非常简单:f(x)=max(0,x)。这意味着如果输入是正数,则输出该数;如果是负数,则输出0。

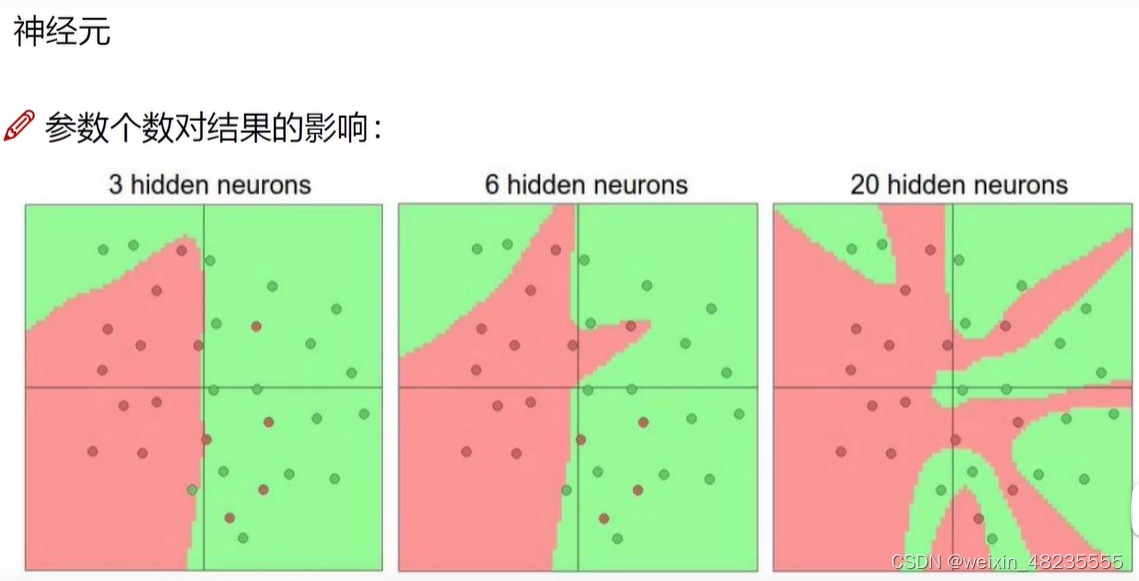
神经元个数对结果的影响:
神经元越多,过拟合越严重,运行时间越长
解决神经网络过拟合问题
正则化
- 目的:解决神经网络过拟合
- 增加一个神经元,相当于增加了一组数据
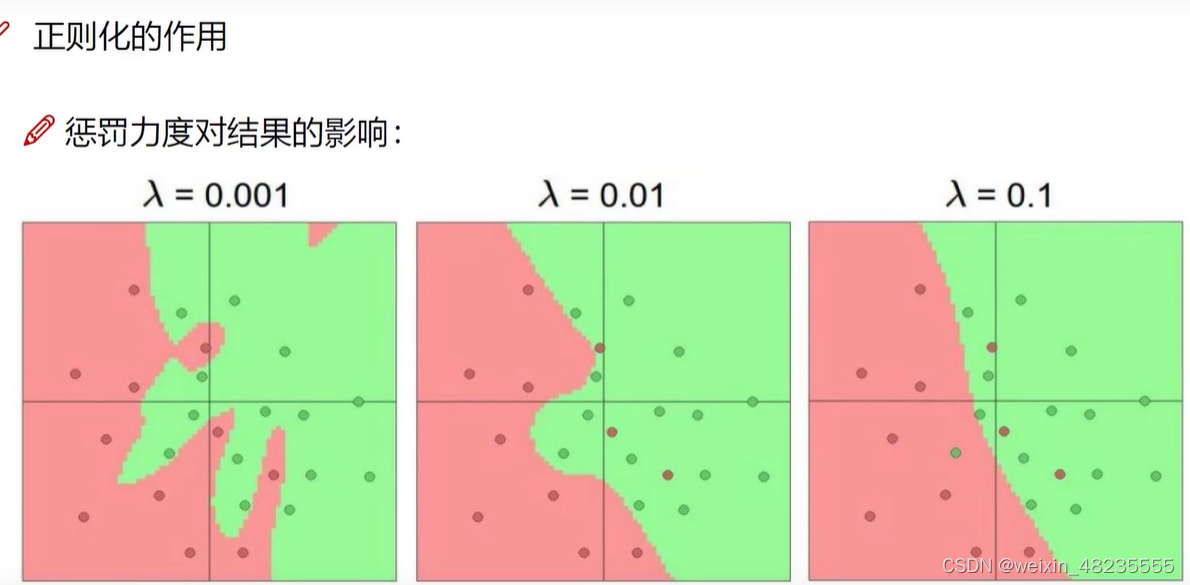
64,128,256,512最常见:
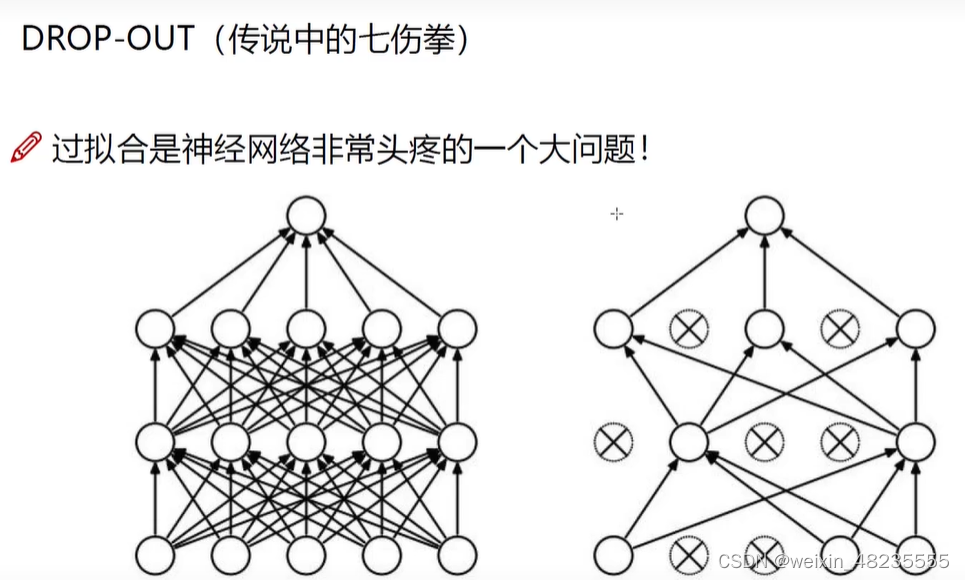
DROP-OUT
DROP-OUT也是解决过拟合的一个方法
- 在训练过程中随机丢弃(即设置为零)网络中的一部分神经元,这可以被视为一种极端的正则化形式。
- 每一层每一次都固定地选择固定比例的神经元进行“杀死”

















 1964
1964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









