









 本文介绍了一个利用Python爬取百度搜索结果中特定域名子域的脚本,并与AWVS API进行联动,实现自动化漏洞挖掘。通过设置搜索关键词和页数,脚本能生成包含目标URL的文件。代码中运用了XPATH解析网页,处理302重定向获取真实URL,并过滤掉非目标资产链接。最后,去除重复URL并保存到文件。这是一个适用于网络安全与自动化测试的实用技巧。
本文介绍了一个利用Python爬取百度搜索结果中特定域名子域的脚本,并与AWVS API进行联动,实现自动化漏洞挖掘。通过设置搜索关键词和页数,脚本能生成包含目标URL的文件。代码中运用了XPATH解析网页,处理302重定向获取真实URL,并过滤掉非目标资产链接。最后,去除重复URL并保存到文件。这是一个适用于网络安全与自动化测试的实用技巧。
谷歌语法在收集资产这方面挺有用的,于是手撸了爬取百度URL脚本,后续和AWVSapi脚本联动实现自动化挖洞
代码完整截图:
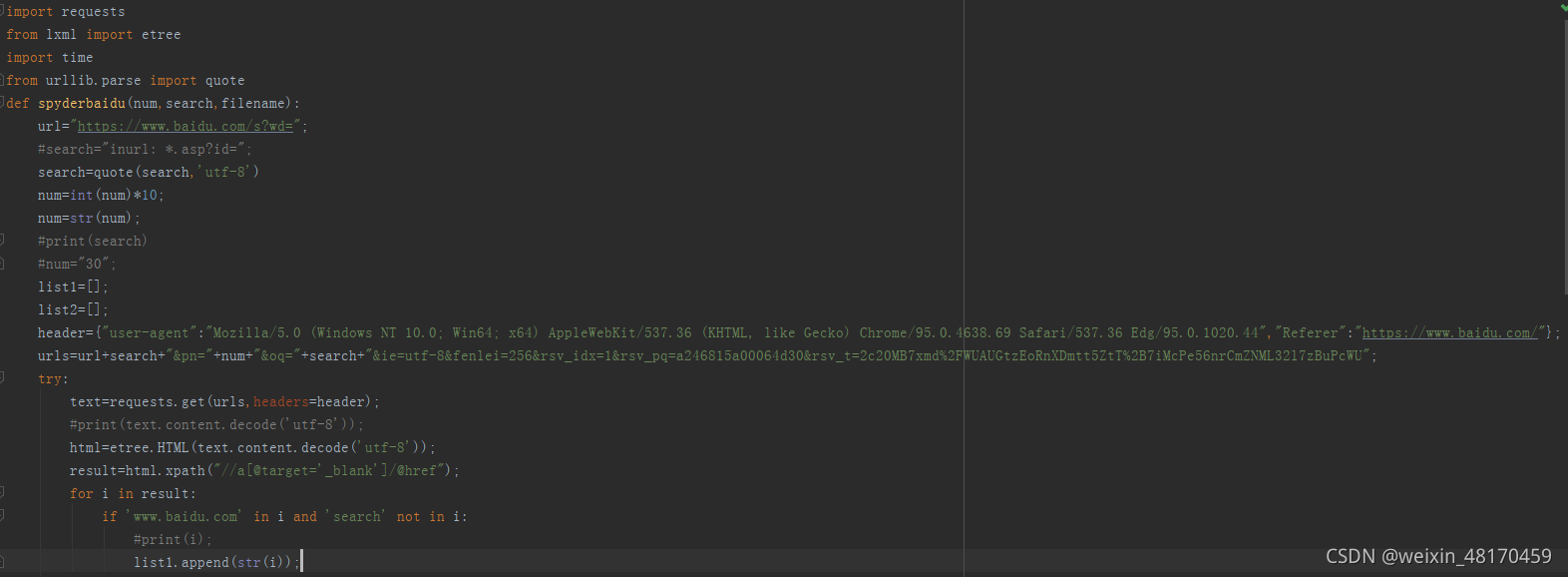
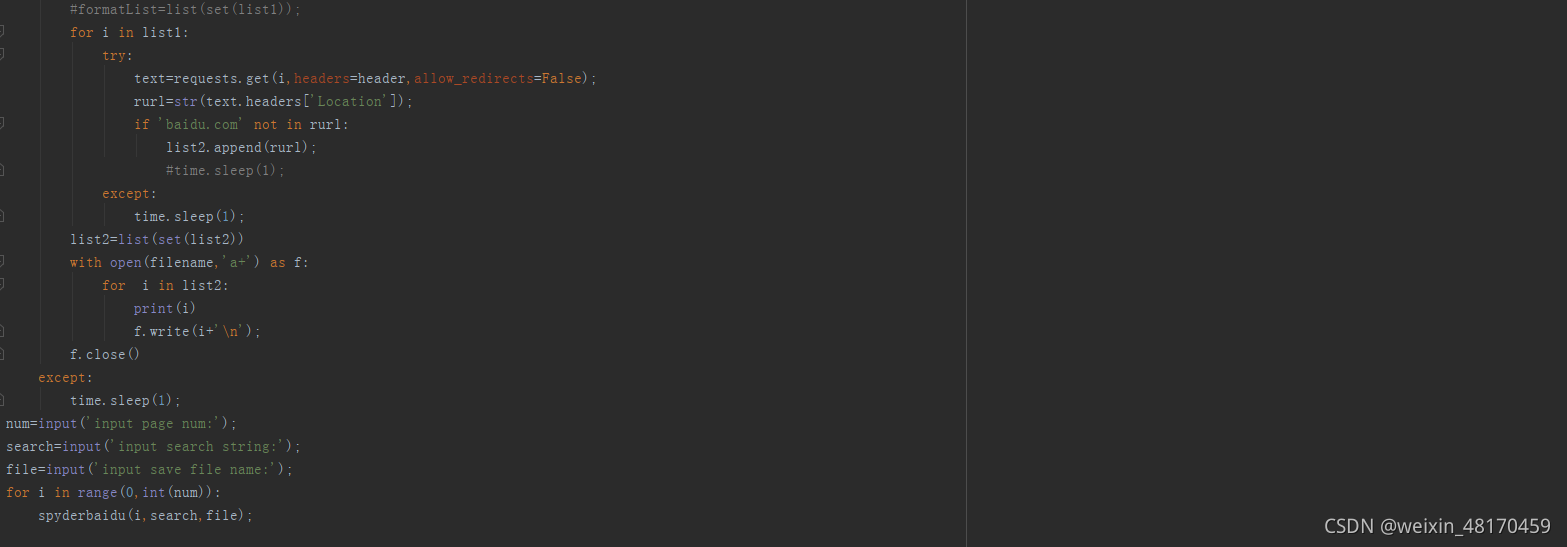 使用方法:
使用方法:

第一步输入爬取的页数,这里演示的是爬取5页
第二步输入百度搜索的字符串,这里爬取163.com的子域名
第三步输入保存文件名称,这里是www.txt
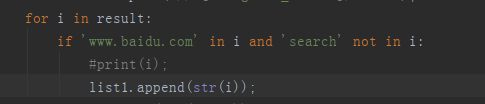
爬取的局部URL
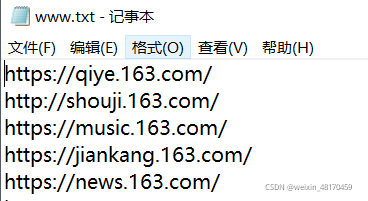
代码解析:
该代码采用的是单线程,如果想爬取速度快一点可以自行改为多线程
百度搜索有爬虫检测机制,所以要定制header
 search为要搜索的字符串,因为百度搜索的字符串经过了URL编码,所以我们也编码一下,num是页码,因为百度的第一页为0,第二页为10,第三页为20,所以num要乘以10
search为要搜索的字符串,因为百度搜索的字符串经过了URL编码,所以我们也编码一下,num是页码,因为百度的第一页为0,第二页为10,第三页为20,所以num要乘以10
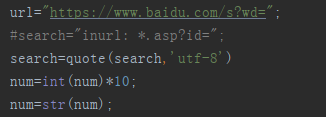
完整的百度搜索URL
 使用XPATH来解析爬取到的百度页面
使用XPATH来解析爬取到的百度页面
XPATH详解:https://www.runoob.com/xpath/xpath-syntax.html
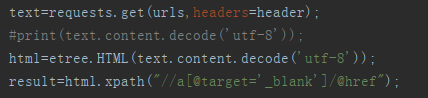
因为百度搜索的每个标题对应的html格式如下
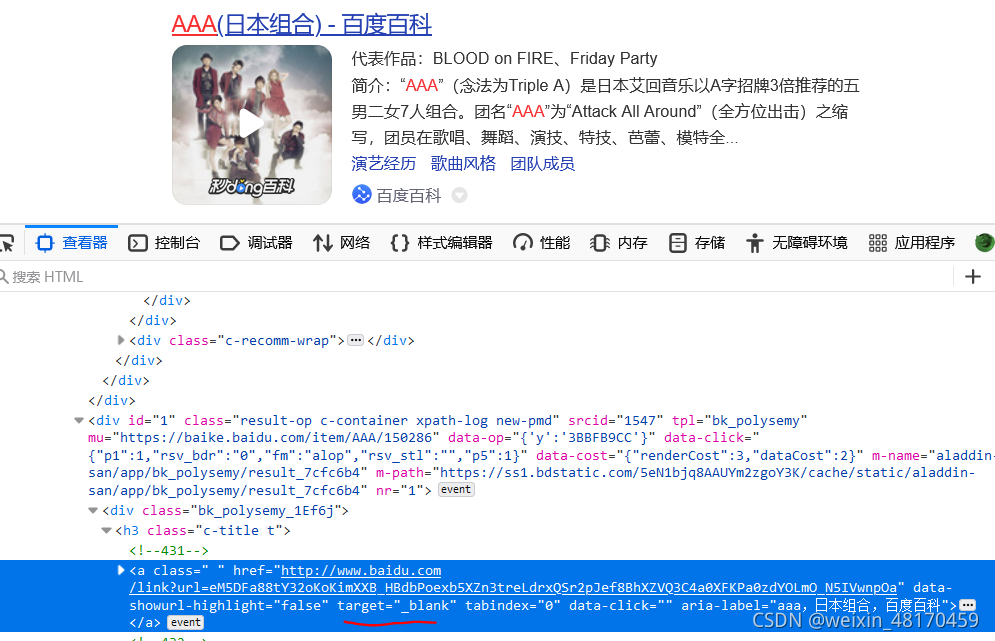 所以提取属性为target="_blank"的a标签的herf的值
所以提取属性为target="_blank"的a标签的herf的值
提取之后包含了一些脏URL,所以要去掉
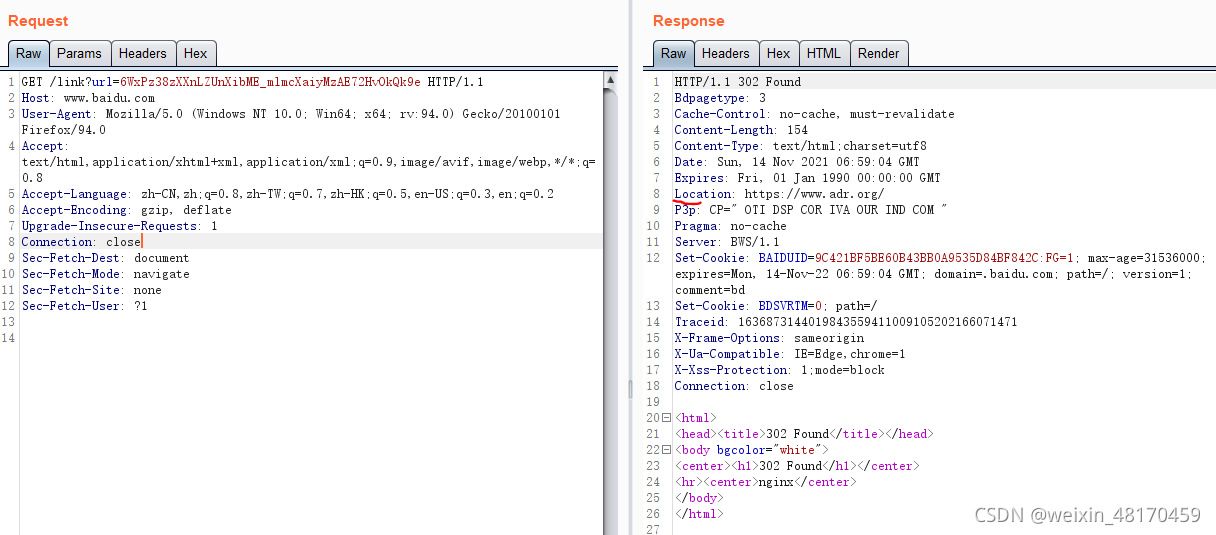
在对上面提取的URL进行请求后,发生了302跳转,Location位置为真实链接,所以我们提取Location位置的URL就行了
 当我们用request时要用try来捕捉异常,有时请求太频繁会出现异常,这时睡眠1秒再请求。
当我们用request时要用try来捕捉异常,有时请求太频繁会出现异常,这时睡眠1秒再请求。
这里我去掉了百度知道,百度百科等一些链接,但是就不能爬取百度资产了,如果你们想爬取百度资产,可以去掉或改为具体域名。
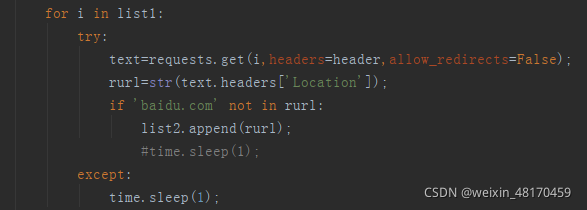
然后去掉重复URL

最后写到要保存的文件里面


















 1981
1981

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









