







 本文深入探讨了JDK并发编程中的一些关键概念,包括AQS(AbstractQueuedSynchronizer)的内部机制,如acquireQueued、park、unpark、condition的使用,以及线程中断的处理。文章详细分析了线程如何在同步队列中等待、被唤醒以及中断状态的管理,同时讲解了condition的await和signal方法的工作流程,展示了线程间的通信和同步控制。
本文深入探讨了JDK并发编程中的一些关键概念,包括AQS(AbstractQueuedSynchronizer)的内部机制,如acquireQueued、park、unpark、condition的使用,以及线程中断的处理。文章详细分析了线程如何在同步队列中等待、被唤醒以及中断状态的管理,同时讲解了condition的await和signal方法的工作流程,展示了线程间的通信和同步控制。
写在前面,用于自己每日复习的小计。
jdk并发源码笔记 不错
JUC框架 源码解析系列文章目录 JDK8
aqs thread等源码解析
(ReetrantLock)、公平锁、非公平锁及Condition的源码级分析(基于AQS、独占锁)(JDK不同版本对比)
java 内存模型解释
aqs 的思考
threadlocal万字解析
threadlocal 不错
尚硅谷并发笔记
synchronized
0 多线程精确控制
1.线程打断的问题
1.1interrupt()方法
Thread t=new Thread(()->{
//业务代码
......
// sleep();
}).start();
t.interrupt();
线程使用interrupt()方法打断时,
1.打断现在正常执行的 sleep(),join(),wait() 方法时,会抛出 InterruptedException异常,并设置打断标记为false(也就是清除打断标记)
2.打断正常运行的线程。
3.打断park()方法的线程,会设置打断标记为true
注意,interrupt()打断park线程后,打断标准为true,那么再次调用park()方法失效。
1.2 isInterrupted()和interrupted() 区别
首先,isInterrupted 是实例方法,interrupted 是静态方法,它们的用处都是查看当前打断的状态,但是 isInterrupted 方法查看线程的时候,不会将打断标记清空,也就是置为 false,interrupted 查看线程打断状态后,会将打断标志置为 false,也就是清空打断标记,简单来说,interrupt() 方法类似于 setter 设置中断值,isInterrupted() 类似于 getter 获取中断值,interrupted() 类似于 getter + setter 先获取中断值,然后清除标志。
用代码测试如下:
/**
* 测试 isInterrupted 与 interrupted
*/
@Slf4j(topic = "c.Code_14_Test")
public class Code_14_Test {
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
log.info("park");
LockSupport.park();
log.info("unpark");
// log.info("打断标记为:{}", Thread.currentThread().isInterrupted());
log.info("打断标记为:{}", Thread.interrupted());
// 使用 Thread.currentThread().isInterrupted()
//查看打断标记为 true, LockSupport.park() 失效
/**
* 执行结果:
* 11:54:17 [t1] c.Code_14_Test - park
* 11:54:18 [t1] c.Code_14_Test - unpark
* 11:54:18 [t1] c.Code_14_Test - 打断标记为:true
* 11:54:18 [t1] c.Code_14_Test - unpark
*/
// 使用 Thread.interrupted() 查看打断标记为 true,
// 然后清空打断标记为 false, LockSupport.park() 不失效
/**
* 执行结果:
* 11:58:12 [t1] c.Code_14_Test - park
* 11:58:13 [t1] c.Code_14_Test - unpark
* 11:58:13 [t1] c.Code_14_Test - 打断标记为:true
*/
LockSupport.park();
log.info("unpark");
}, "t1");
t1.start();
Thread.sleep(1000); // 主线程休眠 1 秒
t1.interrupt();
}
}
上述问题使用interrupt()打断park(),会设置打断标记为true,再次park()会失效。
需要清楚打断标记 可以使用
2. aqs 队列
系列一、aqs源码
aqs await() signal 源码
aqs 面试必考AQS-await和signal的实现原理
aqs condition 源码
JUC框架 源码解析系列文章目录 JDK8 66
AQS之CHL同步队列分析
aqs node分析以及其他源码
阿昌AQS
一文让你彻底搞懂AQS(通俗易懂的AQS)
2.1 aqs acquireQueued()上锁或者获得锁
唤醒park有两种方法 :
1.持有锁的线程释放锁,幻想下一个节点线程。
2.其他线程 使用interrupt()方法,打断同步队列里面的线程。
所以 只有前一个节点是头节点,才能进行尝试加锁。被中断的线程就算唤醒了也获取不到锁。
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {//死循环
//p为傀儡节点
final Node p = node.predecessor();//获得该node的前置节点
/**
* 如果前置节点是head,表示之前的节点就是正在运行的线程,表示是第一个排队的
*
(一般讲队列中第一个是正在处理的,可以想象买票的过程,第一个人是正在买票(处理中),
第二个才是真正排队的人);
那么再去tryAcquire尝试获取锁,如果获取成功,说明此时前置线程已经运行结束,
则将head设置为当前节点返回
*
*
**/
// 因为线程A释放锁,线程B再次进入这
//此时傀儡节点为头节点,
//且再次执行tryAcquire去强占资源,此时会返回true,并强占成功
if (p == head && tryAcquire(arg)) {
// //设置头节点为线程B
//设置线程B的Node中的线程为null
//线程B的Node的前节点为null
setHead(node);
//将傀儡节点的后节点设置为null
p.next = null;
// help GC,将前置节点移出队列,这样就没有指针指向它,可以被gc回收
failed = false;
//返回是否被中断,默认是没被中断也是false
return interrupted;
//返回false表示不能被打断,意思是没有被挂起,也就是获得到了锁
}
/**shouldParkAfterFailedAcquire将前置node设置为需要被挂起,
注意这里的waitStatus是针对当前节点来说的,
即是前置node的ws指的是下一个节点的状态**/
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())//挂起线程 park()
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
//如果失败取消尝试获取锁
//(从上面的代码看只有进入p == head && tryAcquire(arg)这个逻辑是才会触发,
//这个时候前置节点正好在当前节点入队的时候执行完,当前节点正好获得锁,
//具体的代码以后分析)
}
}
//看到因为是死循环,所以当执行到parkAndCheckInterrupt()时,
//当前线程被挂起,等到某一天被unpark继续执行,
//这个时候已经是对头的第二个节点了,
//那么就会进入if (p == head && tryAcquire(arg))逻辑获取到锁并结束循环
2.1.1 竞争 和非竞争获取锁
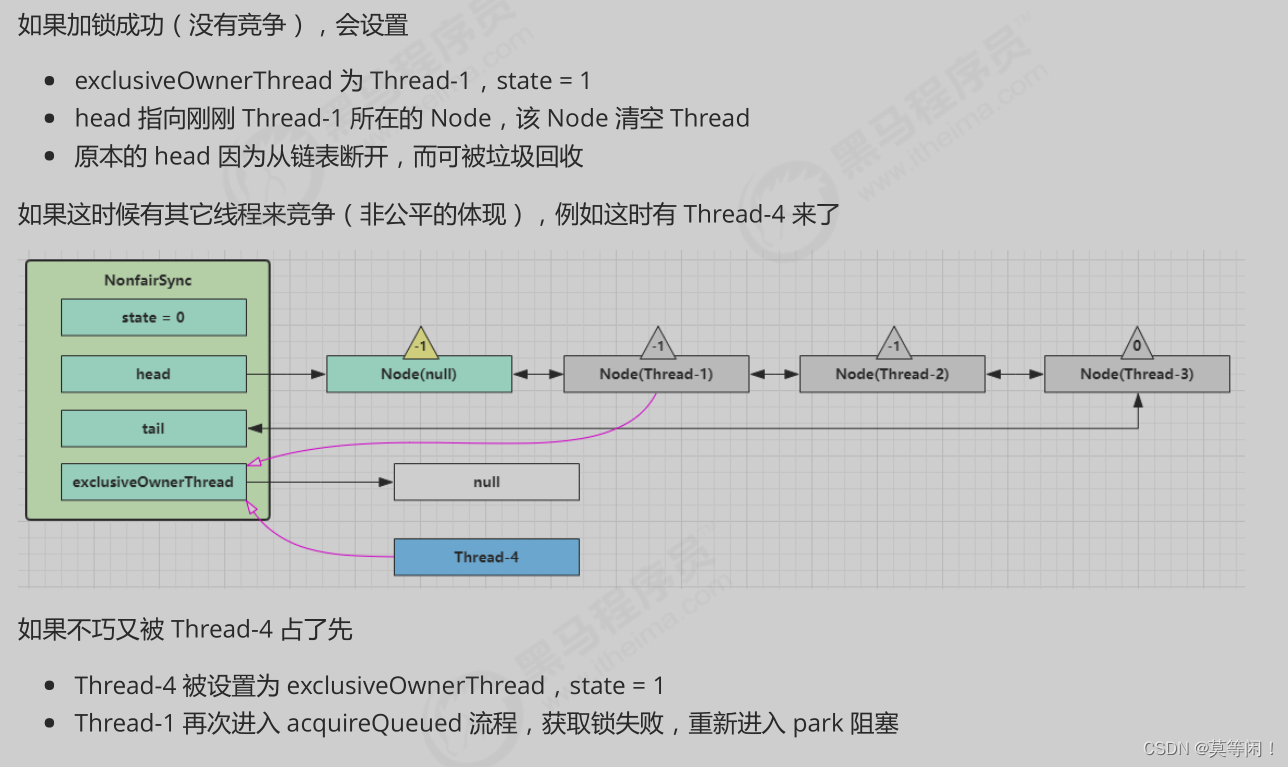
2.2 aqs park线程 waitstatus
已经有线程获得锁,B线程再去争抢锁,会在shouldParkAfterFailedAcquire()中修改B线程为Node 的前一个节点的 waitStatus为-1,说明前一节点都再等待,没有B线程什么事,
所以返回true调用parkAndCheckInterrupt()来阻塞park线程。
/*
// CANCELLED:由于超时或中断,此节点被取消。
节点一旦被取消了就不会再改变状态。特别是,取消节点的线程不会再阻塞。
CANCELLED = 1;
// SIGNAL:此节点后面的节点已(或即将)被阻止(通过park),因此当前节点在释放或取消时必须断开后面的节点
// 为了避免竞争,acquire方法时前面的节点必须是SIGNAL状态,然后重试原子acquire,然后在失败时阻塞。
//SIGNAL 等待触发状态,前节点可能是head或者前节点为取消状态CANCELLED
SIGNAL = -1;
//CONDITION 等待条件状态,在等待队列中
CONDITION=-2;
//PROPAGATE 状态需要向后传播
PROPAFATE=-3
*/
/
* @param pred 前继节点
* @param node 当前节点
/
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
int ws = pred.waitStatus;
if (ws == Node.SIGNAL)
/*
*
* 前继节点还在等待触发,还没当前节点的什么事儿,所以当前节点可以被park
*/
return true;
if (ws > 0) {
/*
// 当前节点的 ws > 0, 则为 Node.CANCELLED
说明前驱节点已经取消了等待锁(由于超时或者中断等原因)
// 既然前驱节点不等了, 那就继续往前找,
直到找到一个还在等待锁的节点
// 然后我们跨过这些不等待锁的节点,
直接排在等待锁的节点的后面 (是不是很开心!!!)
*/
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
/*
* 到这一步,waitstatus只有可能有2种状态,一个是0,
* 一个是PROPAGATE,无论是哪个都需要把当前节点的状态设置为SIGNAL
*/
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}
2.3 aqs unpark 释放锁关键
释放锁后,查看是否有头节点,并且waitstatus 不等于0,如果waitstatus等于0也不能唤醒。
1.同步队列头节点为null不需要唤醒
2.同步队列正在加入第一个节点,也就是创建了头节点,但是头节点没有置为-1
public final boolean release(int arg) {
//上面返回的free为true,进入下面逻辑
if (tryRelease(arg)) {
//拿到头节点的引用并赋给h变量,头节点是傀儡节点
//h为傀儡节点
Node h = head;
//头节点为傀儡节点不为null,
//且傀儡节点的waitState状态为-1,不等于0
if (h != null && h.waitStatus != 0)
//执行unparkSuccessor,唤醒阻塞的线程
unparkSuccessor(h);
return true;
}
return false;
}
private void unparkSuccessor(Node node) {
//拿到傀儡节点的waitStatus状态
//ws = -1
int ws = node.waitStatus;
//进入逻辑
if (ws < 0)
//CAS,设置傀儡节点的waitStatus为0
compareAndSetWaitStatus(node, ws, 0);
//拿到傀儡节点的后节点,也就是线程B节点
//s为线程B节点
// 找到需要 unpark 的节点, 但本节点从 AQS 队列中脱离, 是由唤醒节点完成的
Node s = node.next;
//此时s为线程B节点不为null,且线程B节点的waitStatus为0,不进入逻辑
if (s == null || s.waitStatus > 0) {
//不考虑已取消的节点,
//从 AQS 队列从后至前找到队列最前面需要 unpark 的节点
s = null;
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
//s为线程B节点不为null,进入逻辑
if (s != null)
//为线程B唤醒
LockSupport.unpark(s.thread);
}
2.4 condition
2.4.1 一开始就有出现 移除条件队列的node?
这是因为可能有些线程没有持有锁,调用了await方法,
回抛出异常,所以需要移除。
final int fullyRelease(Node node) {
boolean failed = true;
try {
int savedState = getState();
if (release(savedState)) {
failed = false;
return savedState;
} else {
throw new IllegalMonitorStateException();
}
} finally {
if (failed)
// 执行release()出异常,说明当前线程没有持有锁,
//调用release()方法抛出异常,将node的status改为cancelled
//所以一开始先移除node
node.waitStatus = Node.CANCELLED;
}
}
当发现当前线程不是持有锁的线程时,我们就会进入finally块,将当前Node的状态设为Node.CANCELLED,这也就是为什么上面的addConditionWaiter在添加新节点前每次都会检查尾节点是否已经被取消了。
2.4.2 dosignal() transferForSignal()改waitstatus 为0
等待队列出队->
transferForSignal()方法中 (将node转移到sync 队列中)
修改出等待队列的 节点 的 waitstatus 值为0
如果修改成功不反回,继续执行。
入队
如果p节点的waitStatus为CANCELLED(ws>0) 或 使用CAS将p节点的waitStatus修改成SIGNAL失败,则代表p节点无法来唤醒node节点,因此直接调用LockSupport.unpark方法唤醒node节点。
private void doSignal(Node first) {
do {
// 将firstWaiter指向条件队列队头的下一个节点
if ( (firstWaiter = first.nextWaiter) == null)
lastWaiter = null;
// 将条件队列原来的队头从条件队列中断开,
//则此时该节点成为一个孤立的节点
first.nextWaiter = null;
} while (!transferForSignal(first) && (first = firstWaiter) != null);//找到没有cancelled的一个节点 停止dowhile循环
}
这个方法也是一个do-while循环,目的是遍历整个条件队列,找到第一个没有被cancelled的节点,并将它添加到条件队列的末尾。如果条件队列里面已经没有节点了,则将条件队列清空(firstWaiter=lasterWaiter=null)。
在这里,我们用的依然用的是transferForSignal方法,但是用到了它的返回值,只要节点被成功添加到sync queue中,transferForSignal就返回true, 此时while循环的条件就不满足了,整个方法就结束了,即调用signal()方法,只会唤醒一个线程。
总结: 调用signal()方法会从当前条件队列中取出第一个没有被cancel的节点添加到sync队列的末尾。
2.4.3 await唤醒后的代码 无论如何都在同步队列
1.被signal 后,将条件队列的第一个等待节点加入同步队列。
2.没beisignal后,产生中断,也加入同步队列。
并且status状态都为0
public final void await() throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
Node node = addConditionWaiter();
int savedState = fullyRelease(node);
int interruptMode = 0;
while (!isOnSyncQueue(node)) {
LockSupport.park(this);
// 我们在这里被挂起了,被唤醒后,将从这里继续往下运行
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
}
// 执行到这里说明node 无论如何 都已经被加入到 同步队列中了
/**
这里值得注意的是,当我们被唤醒时,
其实并不知道是因为什么原因被唤醒,
有可能是因为其他线程调用了signal方法,也有可能是因为当前线程被中断了。
但是,无论是被中断唤醒还是被signal唤醒,
被唤醒的线程最后都将离开condition queue,
进入到sync queue中,这一点我们在下面分析源代码的时候详细说。
*/
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
if (node.nextWaiter != null)
unlinkCancelledWaiters();
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
}
2.4.4 线程await后,park唤醒的不同情况
***情况1(中断发生于signal之前)***我们就分析完了,这里我们简单总结一下:
线程因为中断,从挂起的地方被唤醒
随后,我们通过transferAfterCancelledWait确认了线程的waitStatus值为Node.CONDITION,说明并没有signal发生过
然后我们修改线程的waitStatus为0,并通过enq(node)方法将其添加到sync queue中
接下来线程将在sync queue中以阻塞的方式获取,如果获取不到锁,将会被再次挂起
线程在sync queue中获取到锁后,将调用unlinkCancelledWaiters方法将自己从条件队列中移除,该方法还会顺便移除其他取消等待的锁
最后我们通过reportInterruptAfterWait抛出了InterruptedException
情况2.1(被唤醒时,已经发生了中断,但此时线程已经被signal过了)
我们就分析完了,这里我们简单总结一下:
可以理解为线程A 调用signal方法,已经将Node 线程B waitstatus 修改为0了,还没有添加到同步队列中,此时线程C把B用中断唤醒。
1.线程从挂起的地方被唤醒,此时既发生过中断,又发生过signal
2.随后,我们通过transferAfterCancelledWait确认了线程的waitStatus值已经不为Node.CONDITION,说明signal发生于中断之前
3.然后,我们通过自旋的方式,等待signal方法执行完成,确保当前节点已经被成功添加到sync queue中
接下来线程将在sync queue中以阻塞的方式获取锁,如果获取不到,将会被再次挂起
最后我们通过reportInterruptAfterWait将当前线程再次中断,但是不会抛出InterruptedException
2.4.5 transferAfterCancelledWait
final boolean transferAfterCancelledWait(Node node) {
//若此时node节点的waitStatus为CONDITION状态,说明该节点未被唤醒
/**
再signal之前发生中断,或者达到await时间 就加入队列。
*/
if (compareAndSetWaitStatus(node, Node.CONDITION, 0)) {
//将该Node加入到sync queue中
enq(node);
//直接返回true
return true;
}
/**
再signal之后,也就是node 已经加入 同步队列时,发生中断。
*/
while (!isOnSyncQueue(node))
Thread.yield();
return false;
}
2.5 await()
await()总结
至此,我们总算把await()方法完整的分析完了,这里我们对整个方法做出总结:
1.进入await()时必须是已经持有了锁
2.离开await()时同样必须是已经持有了锁
3.调用await()会使得当前线程被封装成Node扔进条件队列,然后释放所持有的锁
4.释放锁后,当前线程将在condition queue中被挂起,等待signal或者中断
5.线程被唤醒后会将会离开condition queue进入sync queue中进行抢锁
6.若在线程抢到锁之前发生过中断,则根据中断发生在signal之前还是之后记录中断模式
7.线程在抢到锁后进行善后工作(离开condition queue, 处理中断异常)
8.线程已经持有了锁,从await()方法返回
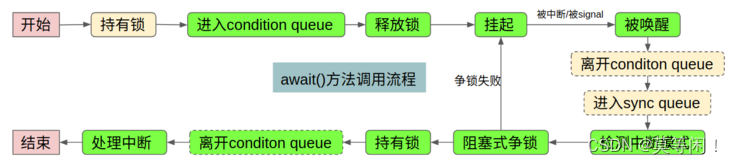
2.5.1 awaitNanos() 区别
awaitNanos(long nanosTimeout) 和await(long time, TimeUnit unit)
调用await(long time, TimeUnit unit)其实就等价于调用awaitNanos(unit.toNanos(time)) > 0
awaitNanos(long nanosTimeout)的返回值是剩余的超时时间,如果该值大于0,说明超时时间还没到,则说明该返回是由signal行为导致的,
public final boolean await(long time, TimeUnit unit) throws InterruptedException {
.........
while (!isOnSyncQueue(node)) {
if (nanosTimeout <= 0L) {*/
timedout = transferAfterCancelledWait(node);
/*break;
}
......
}
return !timedout;
}
而await(long time, TimeUnit unit)的返回值就是transferAfterCancelledWait(node)的值
如果调用该方法时(),node还没有被signal过则返回true,node已经被signal过了,则返回false。
因此当await(long time, TimeUnit unit)方法返回true,则说明在超时时间到之前就已经发生过signal了,
2.6 为什么aqs unpark()线程 需要从后往前遍历
pre的有效性
node.prev = t;//一
if (compareAndSetTail(t, node)) {//二
t.next = node;//三
return t;
}
注意,这里第三步是在第二步执行成功后才执行的,这就意味着,有可能即使我们已经完成了第二步,将新的节点设置成了尾节点,此时原来旧的尾节点的next值可能还是null(因为还没有来的及执行第三步),所以如果此时有线程恰巧从头节点开始向后遍历整个链表,则它是遍历不到新加进来的尾节点的,但是这显然是不合理的,因为现在的tail已经指向了新的尾节点。
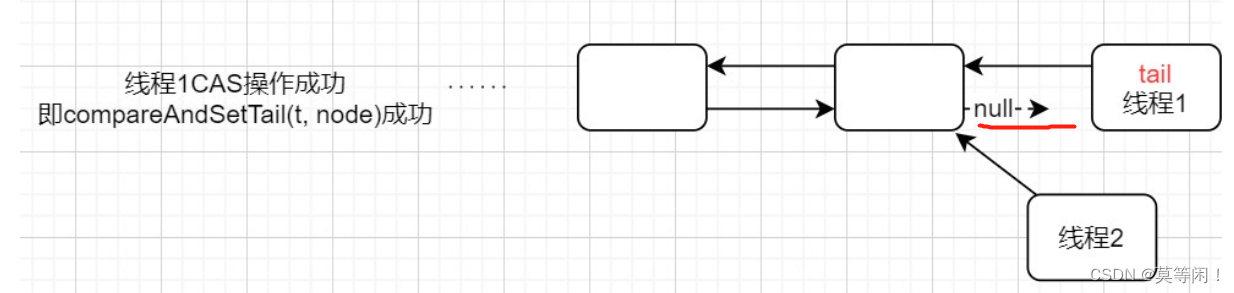
prev的有效性:从上图第二步可以看到,此时线程1的node已经是成功放到队尾了,但此时队列却处于一个中间状态,前一个node的next还没有指向队尾呢。此时,如果另一个线程如果通过next指针遍历队列,就会漏掉最后那个node;但如果另一个线程通过tail成员的prev指针遍历队列,就不会漏掉node了。
————————————————
prev的有效性也解释了AQS源码里遍历队列时,为什么常常使用tail成员和prev指针来遍历,比如你看unparkSuccessor。
2.7cancelAcquire 何时运行
1.在acquireQueued()中,tryAcquire()抛出异常。 对于AQS来说tryAcquire()是抽象方法,具体实现在子类;在AQS的acquireQueued()方法中调用子类实现的tryAcquire()有可能会抛出一次样;抛出异常后获取锁失败需要cancelAcquire;
2.线程抛出 InterruptedException 异常;
因为 在 acquireQueued()中 有finally 块
cancelAcquire(node);
表面当前节点被取消 进去这个方法
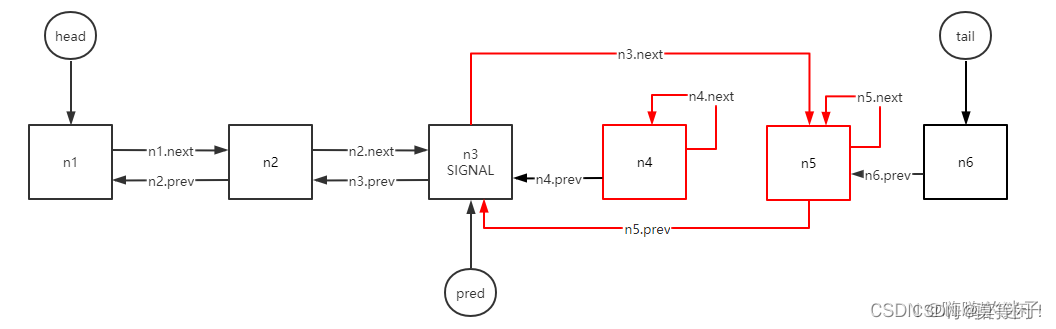
而且我们从上面两个图可以看出来,节点取消会保留一个从后往前的单向链接,这也解释了为什么搜索前置有效节点都是从后往前的。
还有一个问题没有解释,就是取消节点保持了一个向前的引用,可以看看之前的几个图,那么这些节点不会立刻被垃圾回收掉,怎么办,就让这些无效节点一直存在队列中么?
这个时候又得回忆回忆之前总结的知识了,答案在shouldParkAfterFailedAcquire中,这个方法中有一段逻辑:
int ws = pred.waitStatus;
if (ws > 0) {
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
用语言描述,就是会将当前节点的prev链到前面最近的非取消节点上。如下图所示,取消n4、n5节点后,如果n6被唤醒或者执行自旋,那么都会再次执行shouldParkAfterFailedAcquire方法,进而n6.prev会被更新,这个时候n4、n5彻底从链表上断开了,会被垃圾回收掉,所以"不是不报,时候未到"而已。
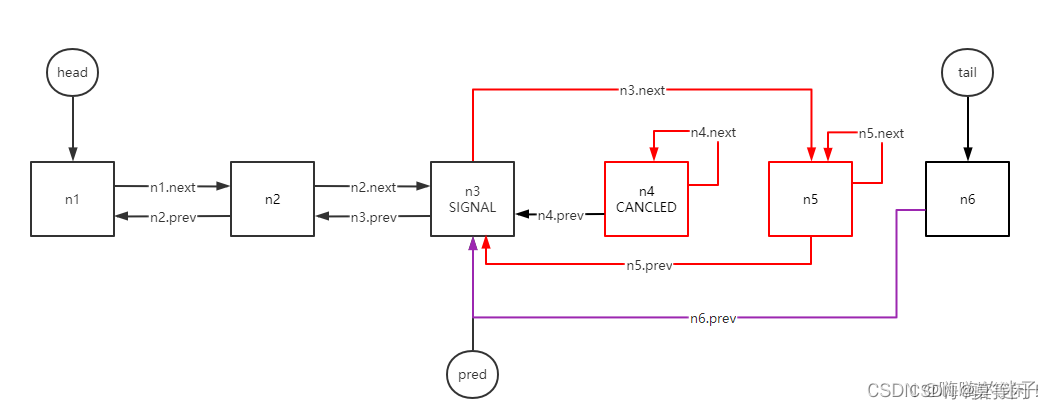
2.8 hasQueuedPredecessors()
public final boolean hasQueuedPredecessors() {
// The correctness of this depends on head being initialized
// before tail and on head.next being accurate if the current
// thread is first in queue.
Node t = tail; // Read fields in reverse initialization order
Node h = head;
Node s;
return h != t &&
((s = h.next) == null || s.thread != Thread.currentThread());
}
hasQueuedPredecessors返回true代表有别的线程在CHL队列中排了当前线程之前;返回false代表当前线程处于CHL队列的第一个线程。
1、分析h != t返回false的情况。此时hasQueuedPredecessors返回false。
当h和t都为null,返回false。此时说明队列为空,还从来没有Node入过队。
当h和t都指向同一个Node,也返回false。此时说明队列中只有一个dummy node,那说明没有线程在队列中。
2、队列中只有一个dummy节点
也就是 图下情况 head!=null tail==null
首先解释下,hasQueuedPredecessors在先后读取完tail和head后,如果这二者只有一个为null(另一个不为null),那么只可能出现“head不为null,tail为null”的情况:
从if (compareAndSetHead(new Node()))到tail = head;的间隙可知,除非一个线程恰好在tail = head;之前读取了tali域(Node t = tail; Node t = head;),那么才可能发生 此时 head不为null,tail为null的情况。
否则,其他情况下。head和tail要都为null,要么都不为null。

上面讲到的出现“head不为null,tail为null”的情况,此时head是空node,next成员肯定为null),那么说明有一个线程正在执行enq,且它正好执行到if (compareAndSetHead(new Node()))到tail = head;的间隙。但这个线程肯定不是当前线程(当前线程在执行tryAcquire阶段,另一个线程已经准备入队了),所以不用判断后面短路的s.thread != Thread.currentThread()了,因为当前线程连enq都没开始执行,但另一个线程都开始执行enq了,那不就是说明当前线程排在别人后面了,别的线程马上就要入队了。
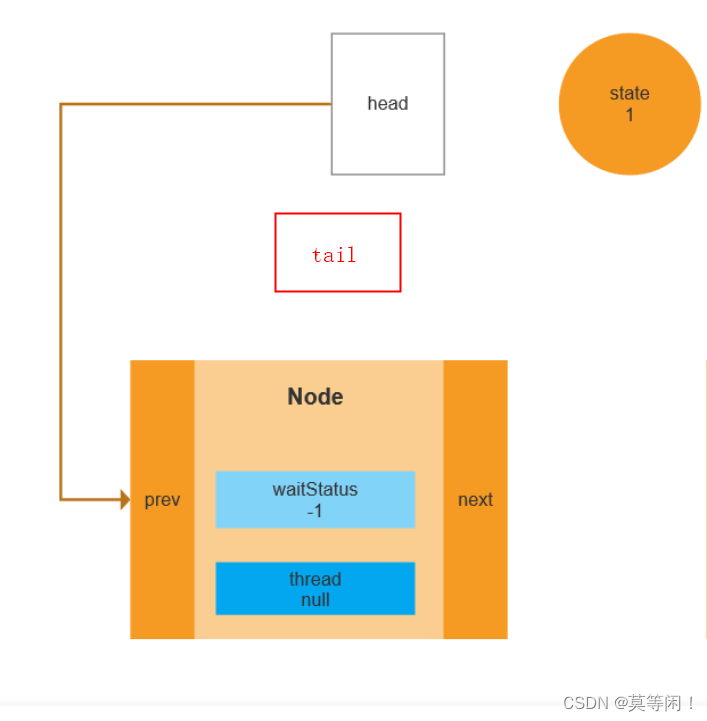
3、队列中有两个以上节点且来抢锁的不是队列中的第二个节点
也抢不到锁
3 threadlocal

3.1 expungeStaleEntry()函数
这里先简单说下expungeStaleEntry的作用:向后搜索连续段,如果遇到stale entry就清空(所以刚开始就会把i下标清空),如果遇到取模下标不等于实际下标的entry,为其再哈希,以使得它更靠近取模下标,甚至直接到取模下标上去。
- 循环从来向后搜索连续段,当遇到null entry时(是指循环开始前就为null的entry),停止。
- 每次循环中,遇到stale entry,清空它。
- 每次循环中,遇到取模下标不是其实际下标的entry,为其rehash,以使得它移动到更靠近取模下标的位置上去。
/** * 此方法从staleSlot索引开始,一直到循环开始前就为null的entry为止。 * 过程中,如果遇到entry的key为null,执行清空操作; * 如果遇到entry的key因冲突而本不应该在当前位置,也清空当前位置,再从新为其找新位置 * (可能找到离取模下标更近的位置)。 * * @param staleSlot 当前已知的stale entry的索引 * @return 在staleSlot之后的,第一个为null的entry的索引。 * (staleSlot索引和返回值索引之间的entry都会收到expunge检查). */ private int expungeStaleEntry(int staleSlot) { //当循环退出,tab[i]) == null return i; }我们先讲下探测式清理,也就是expungeStaleEntry方法,遍历散列数组,从开始位置向后探测清理过期数据,将过期数据的Entry设置为null,沿途中碰到未过期的数据则将此数据rehash后重新在table数组中定位,如果定位的位置已经有了数据,则会将未过期的数据放到最靠近此位置的Entry=null的桶中,使rehash后的Entry数据距离正确的桶的位置更近一些。操作逻辑如下:
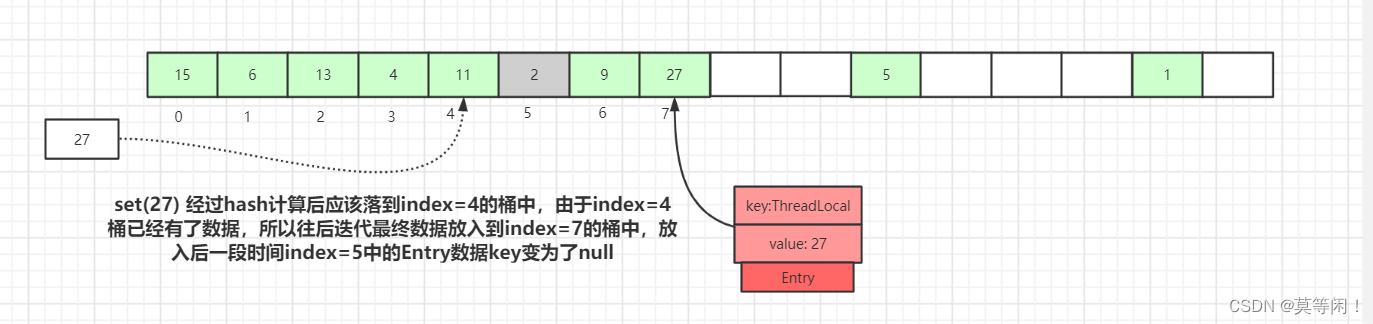
3.2 cleanSomeSlots()函数
cleanSomeSlots函数·
启发式地扫描并清空stale entry,其实启发是指扫描次数不一定是多少次。当别的函数调用到该函数时,参数n要么为个数,要么为容量。/** * 启发式地扫描stale entry,其实启发是指扫描次数。 * 扫描还是往后移动索引。 * * @param i 一个是有效entry的索引。所以扫描从i之后开始 * * @param n 用来控制扫描的次数。次数可为log2(n)次,但如果扫描到 * stale entry,那么不管已扫描次数,再扫描log2(容量)次。 * * @return 返回true如果扫描并清空到至少一个stale entry */ private boolean cleanSomeSlots(int i, int n) { boolean removed = false; Entry[] tab = table; int len = tab.length; do { i = nextIndex(i, len);//另i往后移动 Entry e = tab[i]; if (e != null && e.get() == null) {//检测到i位置的entry是一个stale entry n = len;//更新n为容量,接下来至少又得循环log2(容量)次 removed = true; i = expungeStaleEntry(i);//返回i之后第一个为null的entry的索引,使得i跳跃 } } while ( (n >>>= 1) != 0);//n无符号右移,只是用来控制循环次数 // return removed; }3.3 threadlocal 为什么key需要弱引用
但是有一种危险是,如果线程是线程池的,在线程执行完代码的时候并没有结束,只是归还给线程池,这个时候ThreadLocalMap和里面的元素是不会回收掉的。
探测式清理 会把key 为null,value 也设置为null
任何对ThreadLocalMap的get和remove操作都会触发对持有无效key的Entry的清理。
在ThreadLocalMap中的set/getEntry中 ,会对Key = NULL(即ThreadLocal = NULL)的进行判定,如果为NULL,将会把value也置为NULL。
这就意味着:使用完Thread Local,CurrentThread仍然运行的情况下,就算忘记remove(),弱引用也会比强引用多一层保障。3.4 特点
特点 内容 1.线程并发 在多线程并发场景下 2.传递数据 我们可以通过ThreadLocal在同一线程,不同组件中传递公共变量(保存每个线程的数据,在需要的地方可以直接获取, 避免参数直接传递带来的代码耦合问题) 3.线程隔离 每个线程的变量都是独立的, 不会互相影响.(核心)(各线程之间的数据相互隔离却又具备并发性,避免同步方式带来的性能损失) 3.5 内存泄漏原因
如果线程是线程池的线程,threadlocalMap 中的value 存在强引用,执行value 对象。
所有存在一个引用链
thread ref–>thread—》threadlocalmap---->entry—>value—>object对象。
线程不退出,这个引用链不会消失,导致内存泄漏。
这样value所强引用的Object对象迟迟得不到回收,就会导致内存泄漏。
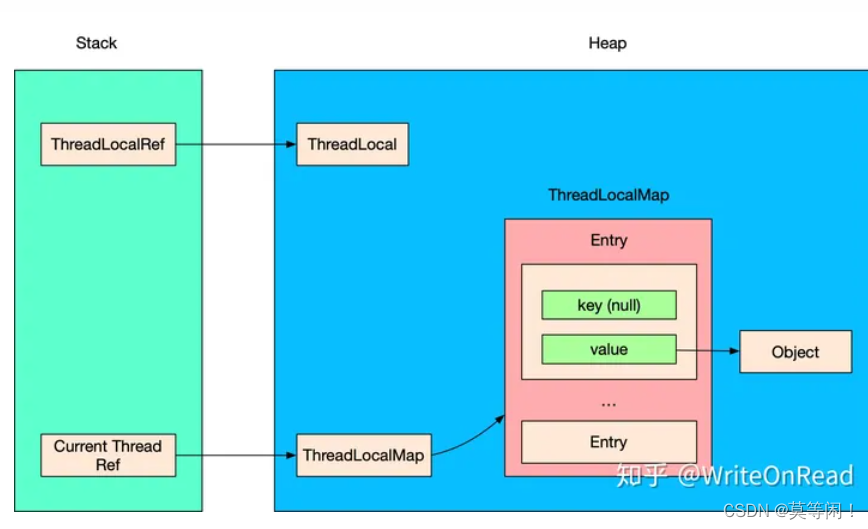
3.5.1 key 使用强引用
会导致 threadlocal 中的entry 内存泄漏。
3.5.2 key 使用弱引用
key 使用弱引用是为了降低程序中出现
内存泄漏的。jvm gc 时,key 的弱引用,key 为null,下一次调用 get()。set(),发现 key 为null,会把对于的value 值也置为null。调用set()方法时,采样清理、全量清理,扩容时还会继续检查。
调用get()方法,没有直接命中,向后环形查找时。
调用remove()时,除了清理当前Entry,还会向后继续清理。4.synchronized
4.1 对象组成
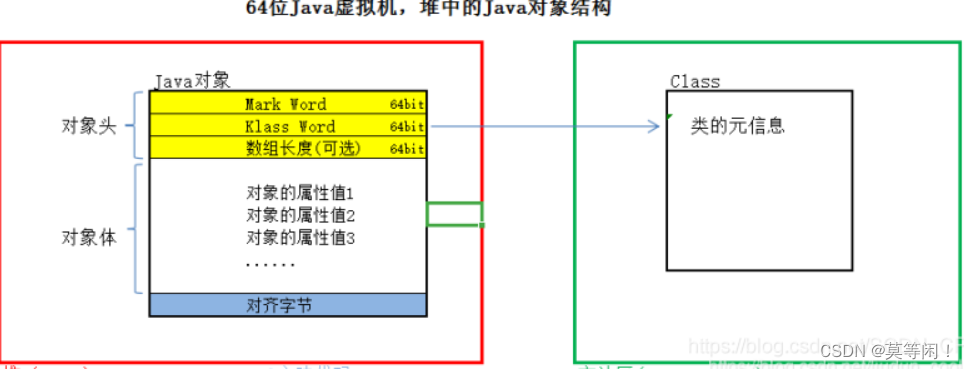
mark word
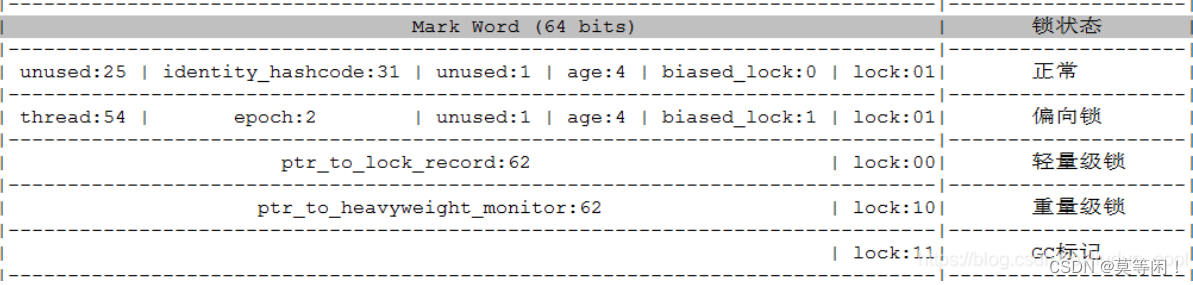
总结如下

图
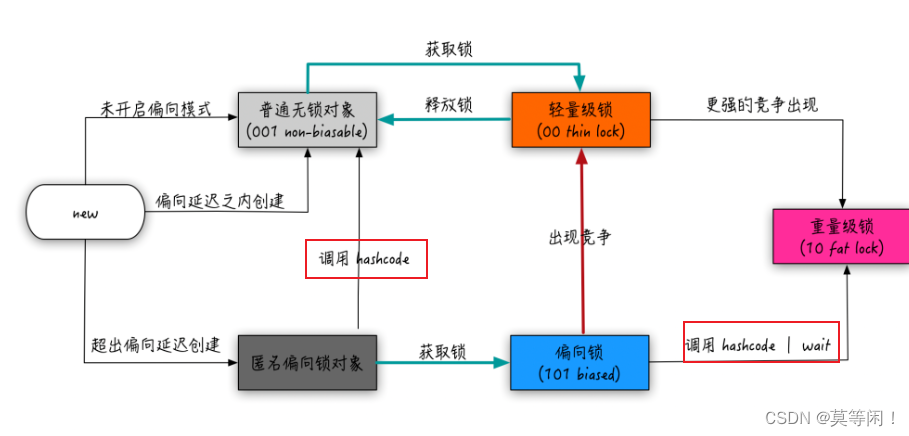
4.2 偏向锁
5.0 volatile 屏障
按照内存屏障的分类,我理解有两类。(1)一类是强制读取主内存,强制刷新主内存的内存屏障,叫做Load屏障和Store屏障
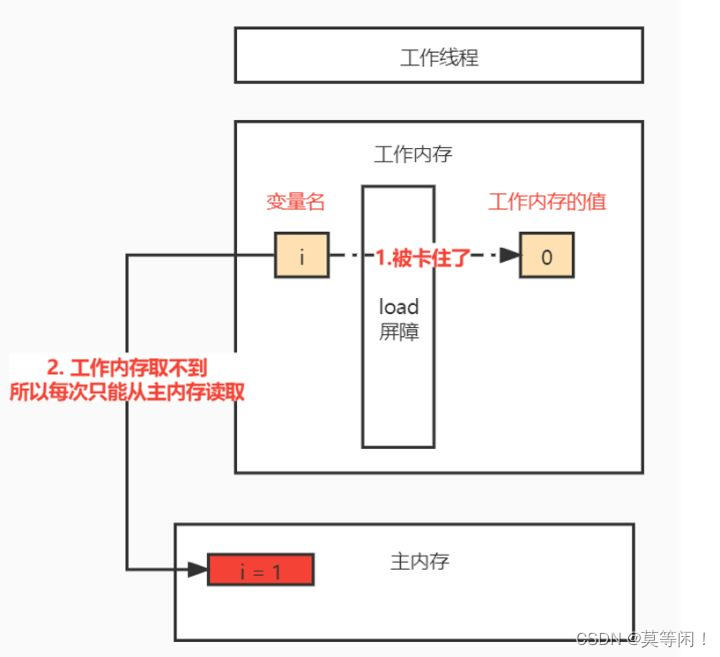
5.0.1强制读取/刷新主内存的屏障
Load屏障:执行读取数据的时候,强制每次都从主内存读取最新的值
Store屏障:每次执行修改数据的时候,强制刷新回主内存。load屏障
store屏障
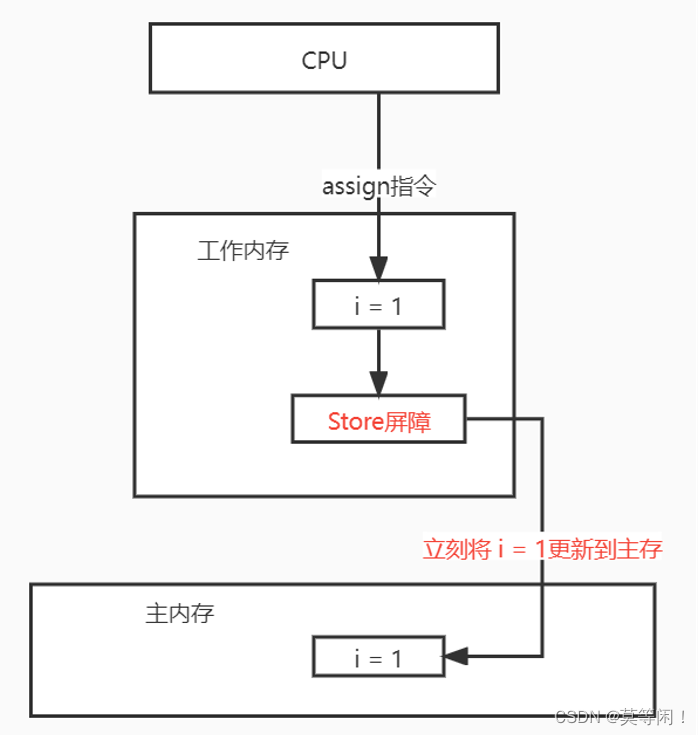
5.0.2 禁止指令重排序的屏障
(2)另外一类是禁止指令重排序的内存屏障,有四个分别叫做LoadLoad屏障、StoreStore屏障、LoadStore屏障、StoreLoad屏障
①. 写 在每个volatile写操作的前⾯插⼊⼀个StoreStore屏障 在每个volatile写操作的后⾯插⼊⼀个StoreLoad屏障
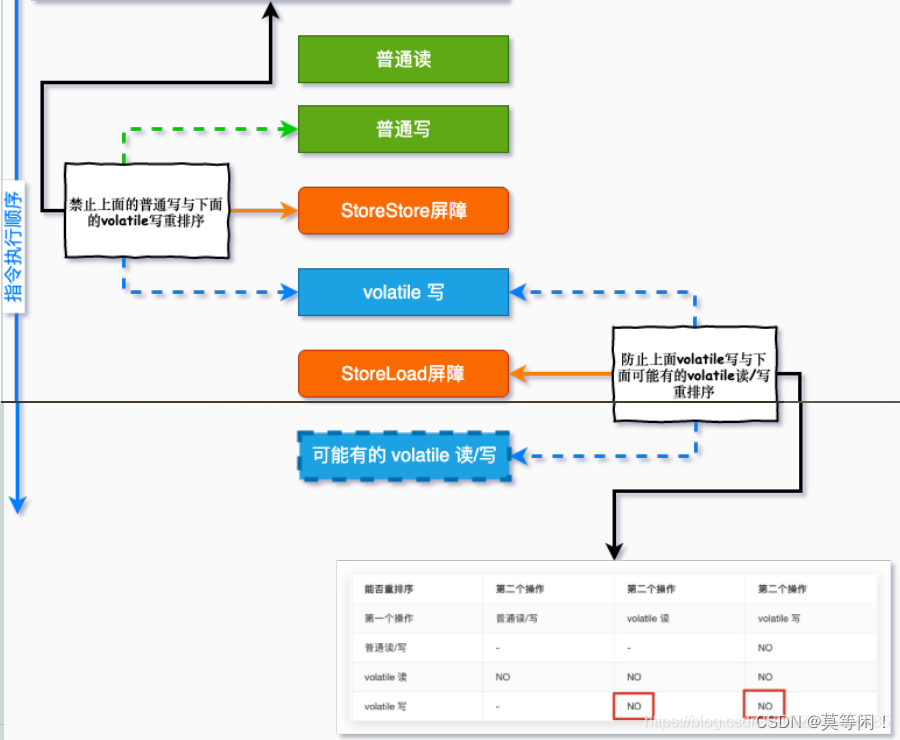
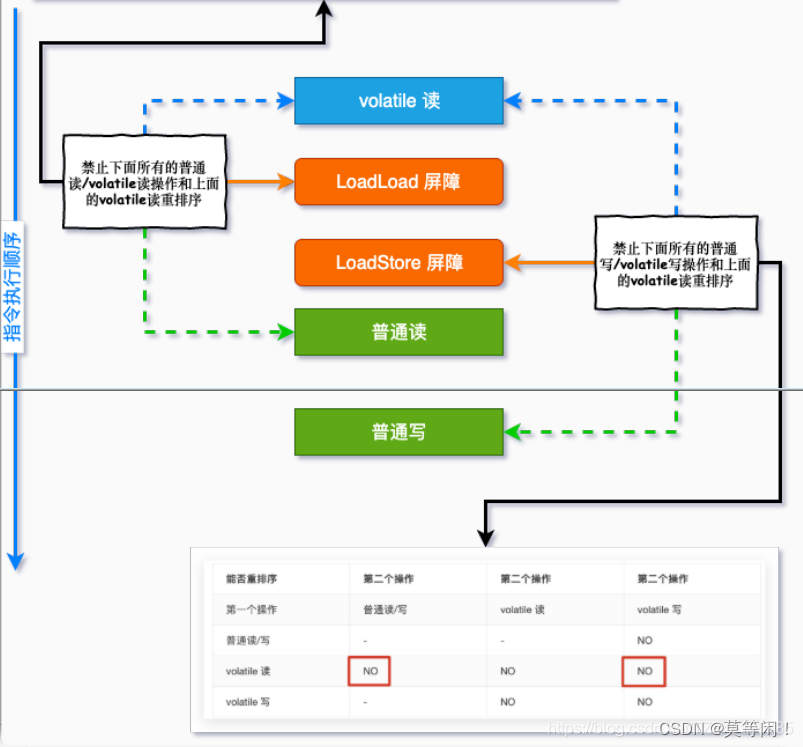
②. 读 在每个volatile读操作的后⾯插⼊⼀个LoadLoad屏障 在每个volatile读操作的后⾯插⼊⼀个LoadStore屏障
5.JMM
JMM的设计分为两部分,一部分是面向我们程序员提供的,也就是happens-before规则,它通俗易懂的向我们程序员阐述了一个强内存模型,我们只要理解 happens-before规则,就可以编写并发安全的程序了。
5.1 happens-before
但它其实表达的是,前一个操作的结果对后续操作是可见的。
5.1.1 程序顺序规则
一个线程中,按照程序顺序,前面的操作 Happens-Before 于后续的任意操作。这个还是非常好理解的,比如上面那三行代码,第一行的 "double pi = 3.14; " happens-before 于 “double r = 1.0;”,这就是规则1的内容,比较符合单线程里面的逻辑思维,很好理解。
double pi = 3.14; // A double r = 1.0; // B double area = pi * r * r; // C5.1.2 监视器锁规则
对一个锁的解锁,happens-before于随后对这个锁的加锁。
线程a线解锁 线程b才能加锁这个规则中说的锁,其实就是Java里的 synchronized。例如下面的代码,在进入同步块之前,会自动加锁,而在代码块执行完会自动释放锁,加锁以及释放锁都是编译器帮我们实现的。
synchronized (this) { //此处自动加锁 // x是共享变量,初始值=10 if (this.x < 12) { this.x = 12; } } //此处自动解锁所以结合锁规则,可以理解为:假设 x 的初始值是 10,线程 A 执行完代码块后 x 的值会变成 12(执行完自动释放锁),线程 B 进入代码块时,能够看到线程 A 对 x 的写操作,也就是线程 B 能够看到 x==12。这个也是符合我们直觉的,非常好理解。。
5.1.3 volatile变量规则
对一个volatile域的写,happens-before于任意后续对这个volatile域的读
前面的写对后面的读是可见的。
这个就有点费解了,对一个 volatile 变量的写操作相对于后续对这个 volatile 变量的读操作可见,这怎么看都是禁用缓存的意思啊,貌似和 1.5 版本以前的语义没有变化啊(前面讲的1.5版本前允许volatile变量和普通变量之间重排序)?如果单看这个规则,的确是这样,但是如果我们关联一下规则 4,你就能感受到变化了
5.1.4. 传递性
如果A happens-before B,且B happens-before C,那么A happens-before C。
我们将规则 4 的传递性应用到我们下面的例子中,会发生什么呢?class VolatileExample { int x = 0; volatile boolean v = false; public void writer() { x = 42; v = true; } public void reader() { if (v == true) { // 这里x会是多少呢? } } }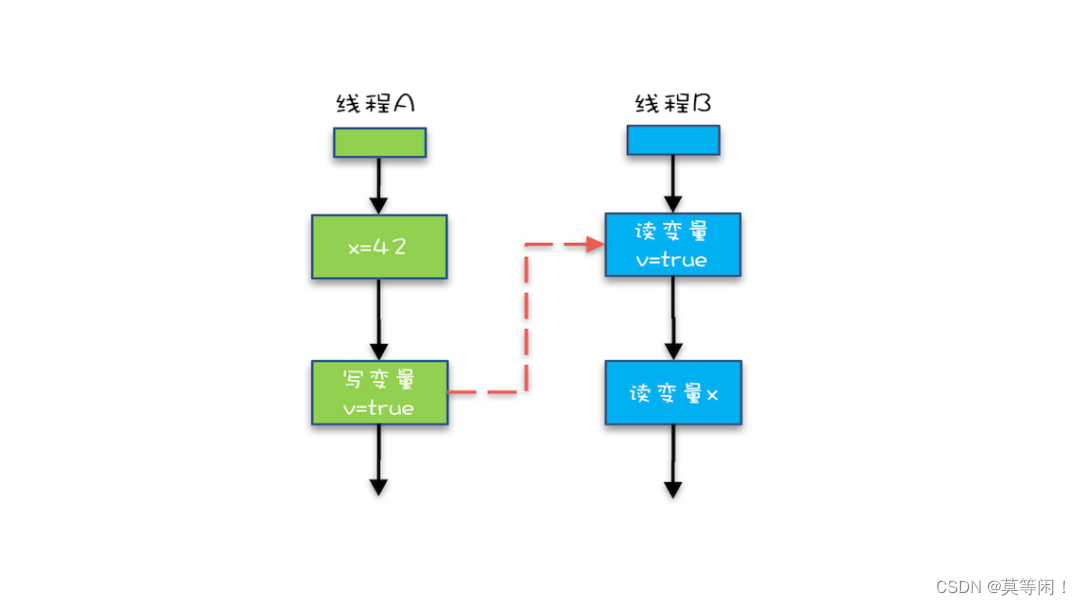
从图中,我们可以看到:1.“x=42” Happens-Before 写变量 “v=true” ,这是规则 1 的内容;
2.写变量“v=true” Happens-Before 读变量 “v=true”,这是规则 3 的内容 。
3.再根据这个传递性规则,我们得到结果:“x=42” Happens-Before 读变量“v=true”。这意味着什么呢?如果线程 B 读到了“v=true”,那么线程 A 设置的“x=42”对线程 B 是可见的。也就是说,线程 B 能看到 “x == 42” ,有没有一种恍然大悟的感觉?这就是 1.5 版本对 volatile 语义的增强,这个增强意义重大,1.5 版本的并发工具包(java.util.concurrent)就是靠 volatile 语义来搞定可见性的。
5.1.5. start()规则
这条是关于线程启动的。它是指主线程 A 启动子线程 B 后,子线程 B 能够看到主线程在启动子线程 B 前的操作。
线程 的start()方法 先行发生于此线程的每一个动作new Thread(()->{ //....doSomething }).start(); // xian start() 里面内容才能执行5.1.6. join()规则
如果线程A执行操作ThreadB.join()并成功返回,那么线程B中的任意操作happens-before于线程A从ThreadB.join()操作成功返回。
5.1.7 interrupt() 规则
也就是说 要先调用interrupt()方法,设置过标志位,我们才能检测到中断的发生
t1.interrupt(); //t1 线程内T Thread.interrupted();5.1.8 termination()
5.1.9 总节
在 Java 语言里面,Happens-Before 的语义本质上是一种可见性,A Happens-Before B 意味着 A 事件对 B 事件来说是可见的,无论 A 事件和 B 事件是否发生在同一个线程里。例如 A 事件发生在线程 1 上,B 事件发生在线程 2 上,Happens-Before 规则保证线程 2 上也能看到 A 事件的发生。

















 286
286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









