







前言
众所周知,在整个机器学习领域中,使用的最多的模型,无非就是上图的模型,今天就给大家揭秘这些模型的使用场景,并且每一个模型均有一个例子给大家详细展示了在机器学习中的作用。
- 线性回归模型的优点
1.1 简单易懂
线性回归模型是一种非常直观的算法,它的数学形式简单,易于理解和解释。模型的参数(系数)直接反映了每个特征对目标变量的影响程度。
1.2 计算效率高
线性回归模型的训练和预测速度非常快,尤其是在数据量较大时,计算复杂度较低,适合处理大规模数据集。
1.3 可解释性强
线性回归模型的系数可以明确地告诉我们每个特征对目标变量的贡献大小和方向(正相关或负相关),这对于业务分析和决策非常有帮助。
1.4 易于扩展
线性回归模型可以通过添加多项式特征、交互项等方式扩展为非线性模型,从而捕捉更复杂的数据关系。
1.5 理论基础扎实
线性回归是统计学中的经典方法,有坚实的数学理论基础,许多其他高级模型(如逻辑回归、广义线性模型)都是基于线性回归的扩展。
- 线性回归模型的缺点
2.1 对非线性关系拟合能力差
线性回归假设目标变量与特征之间存在线性关系。如果数据中的关系是非线性的,线性回归的表现会很差。
2.2 对异常值敏感
线性回归模型对异常值非常敏感,异常值会显著影响模型的拟合效果,导致预测不准确。
2.3 容易过拟合
当特征数量较多或特征之间存在多重共线性时,线性回归模型容易过拟合。虽然可以通过正则化(如Lasso、Ridge)缓解,但仍需谨慎处理。
2.4 假设条件严格
线性回归模型对数据有以下假设:
线性关系:目标变量与特征之间是线性关系。
独立性:特征之间相互独立(无多重共线性)。
同方差性:误差项的方差是常数。
正态分布:误差项服从正态分布。 如果这些假设不成立,模型的性能可能会下降。
2.5 无法处理分类问题
线性回归模型只能用于预测连续变量,不能直接用于分类问题(尽管可以通过逻辑回归等扩展方法解决)。
- 线性回归模型的适用场景
3.1 预测连续变量
线性回归模型适用于预测连续目标变量,例如:
房价预测(如波士顿房价、加州房价)。
销售额预测。
股票价格预测。
3.2 特征与目标变量之间存在线性关系
如果数据中的特征与目标变量之间存在明显的线性关系,线性回归模型是一个很好的选择。
3.3 需要强解释性的场景
在需要解释模型结果的场景中,线性回归模型非常有用。例如:
分析哪些因素对房价影响最大。
评估广告投入对销售额的影响。
3.4 数据量适中
线性回归模型适合处理中小规模的数据集。对于非常大的数据集,虽然线性回归仍然可以工作,但可能需要考虑更高效的算法(如随机梯度下降)。
3.5 基线模型
线性回归模型通常被用作基线模型,用于与其他复杂模型(如决策树、神经网络)进行性能对比。
- 线性回归模型的改进方法
4.1 多项式回归
通过添加多项式特征,将线性回归扩展为多项式回归,以捕捉非线性关系。
4.2 正则化
使用Lasso回归(L1正则化)或Ridge回归(L2正则化)来防止过拟合,并处理多重共线性问题。
4.3 特征工程
通过特征选择、特征变换(如对数变换、标准化)等方法,提升模型的性能。
4.4 鲁棒回归
对于存在异常值的数据,可以使用鲁棒回归方法(如RANSAC)来减少异常值的影响。
- 总结
优点
简单易懂,计算效率高。
可解释性强,适合需要解释模型结果的场景。
理论基础扎实,易于扩展。
缺点
对非线性关系拟合能力差。
对异常值敏感。
假设条件严格,容易过拟合。
无法直接处理分类问题。
适用场景
预测连续变量。
特征与目标变量之间存在线性关系。
需要强解释性的场景。
数据量适中,适合作为基线模型。
代码片段
# 我们使用scikit-learn中的fetch_california_housing函数加载加州房价数据集
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# 加载加州房价数据集
california = fetch_california_housing()
X = pd.DataFrame(california.data, columns=california.feature_names)
y = pd.Series(california.target, name='MedHouseVal')
# 查看数据集的基本信息
print(X.info())
print(X.describe())
# 查看目标变量的分布
print(y.describe())
# 检查缺失值
print(X.isnull().sum())

# 设置支持中文的字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows 系统可以使用 SimHei
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 假设 X 和 y 是你的数据
# 例如:X 是特征数据框,y 是目标值
# 这里以加州房价数据集为例
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing()
X = pd.DataFrame(housing.data, columns=housing.feature_names)
y = housing.target
# 将 inf 值替换为 NaN(避免 use_inf_as_na 警告)
X.replace([np.inf, -np.inf], np.nan, inplace=True)
# 直方图和箱线图查看目标变量和特征的分布:
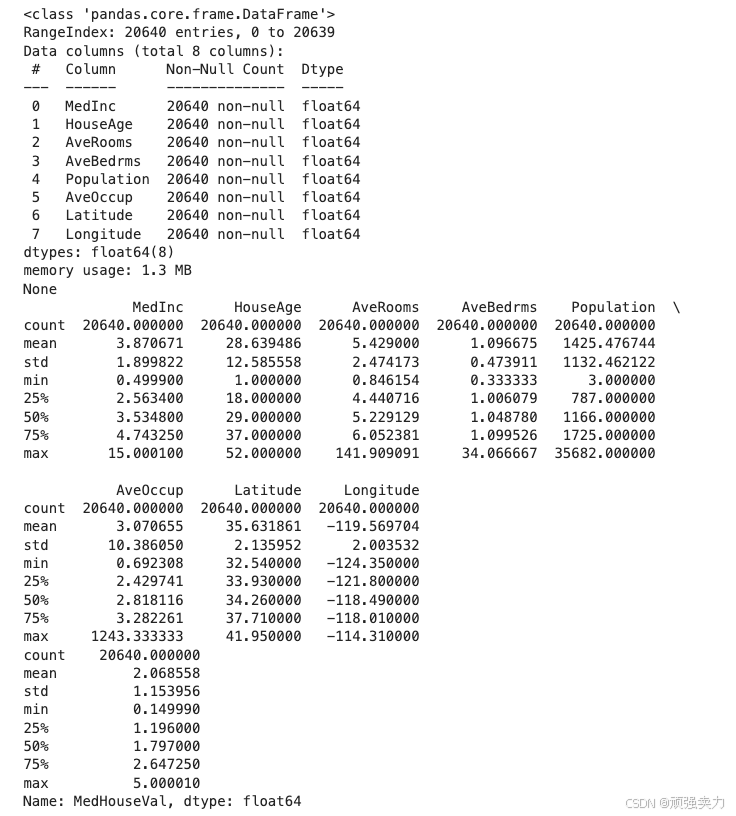
# 目标变量分布
plt.figure(figsize=(8, 6))
sns.histplot(y, bins=30, kde=True, color='blue')
plt.title('Distribution of MedHouseVal (房价中位数)')
plt.xlabel('MedHouseVal')
plt.ylabel('Frequency')
plt.show()
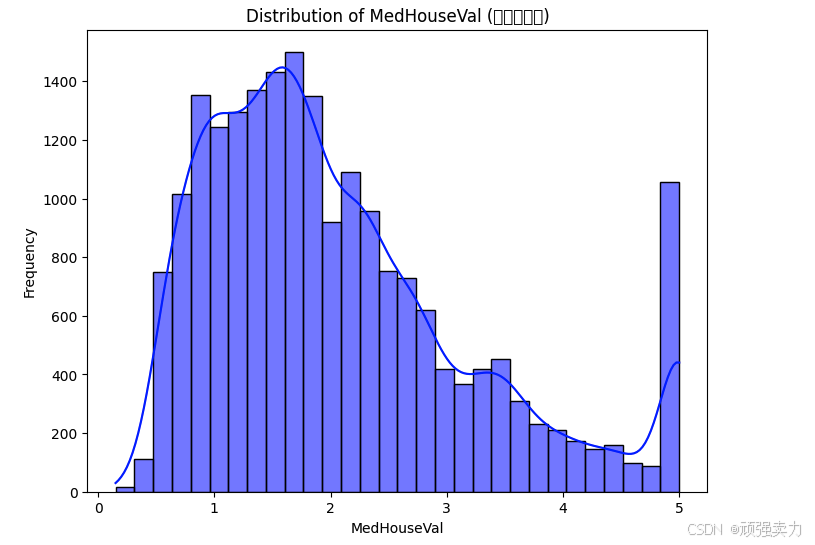
# 特征变量分布(以MedInc为例)
plt.figure(figsize=(8, 6))
sns.histplot(X['MedInc'], bins=30, kde=True, color='green')
plt.title('Distribution of MedInc (收入中位数)')
plt.xlabel('MedInc')
plt.ylabel('Frequency')
plt.show()
1.use_inf_as_na 的警告: 这是 seaborn 库的一个未来警告,提示 use_inf_as_na 选项将在未来版本中被移除。 解决方法是将 inf(无穷大)值转换为 NaN,然后再进行操作。
2.字体缺失的警告: 这是因为当前使用的字体不支持中文字符(如“房价中位数”等)。 解决方法是指定支持中文的字体,例如 SimHei 或 Arial Unicode MS。
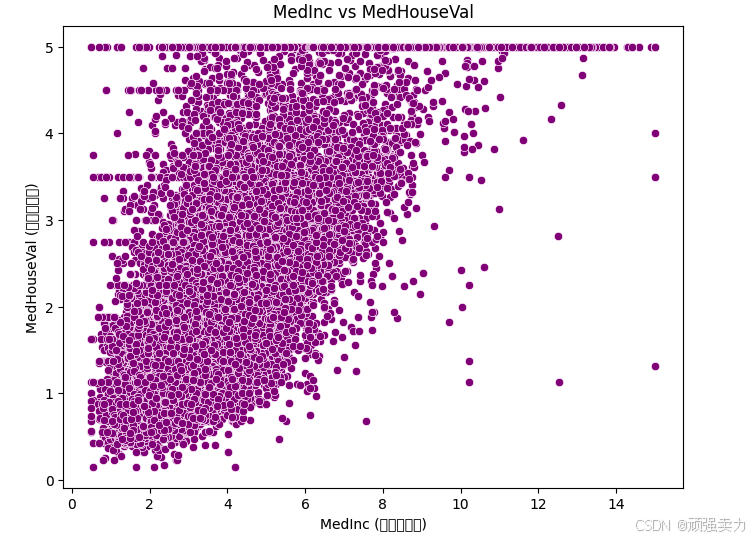
# 散点图和热力图分析特征与目标变量之间的关系
# 散点图:以MedInc(收入中位数)和MedHouseVal(房价中位数)为例
plt.figure(figsize=(8, 6))
sns.scatterplot(x=X['MedInc'], y=y, color='purple')
plt.title('MedInc vs MedHouseVal')
plt.xlabel('MedInc (收入中位数)')
plt.ylabel('MedHouseVal (房价中位数)')
plt.show()
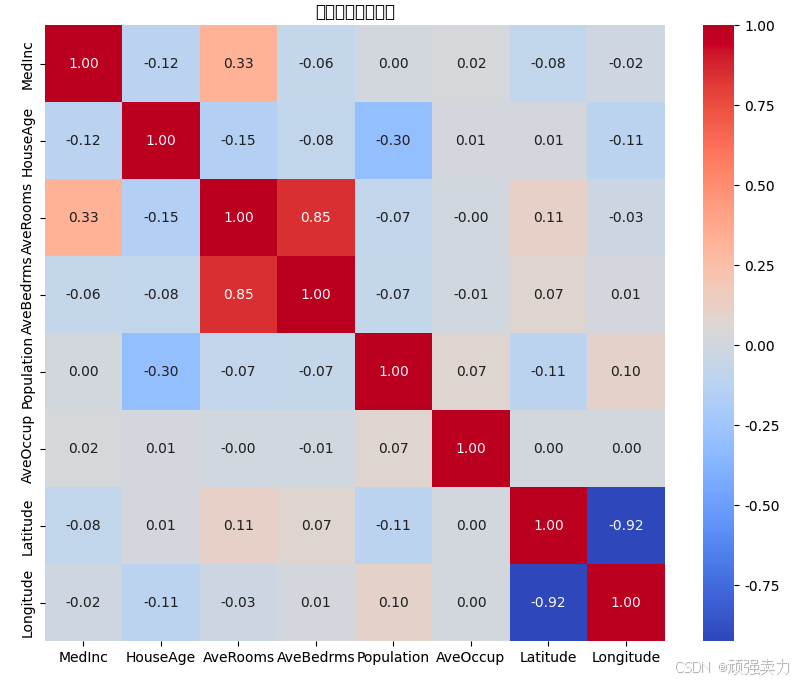
# 热力图:查看特征之间的相关性
plt.figure(figsize=(10, 8))
corr_matrix = X.corr()
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', fmt='.2f')
plt.title('特征相关性热力图')
plt.show()
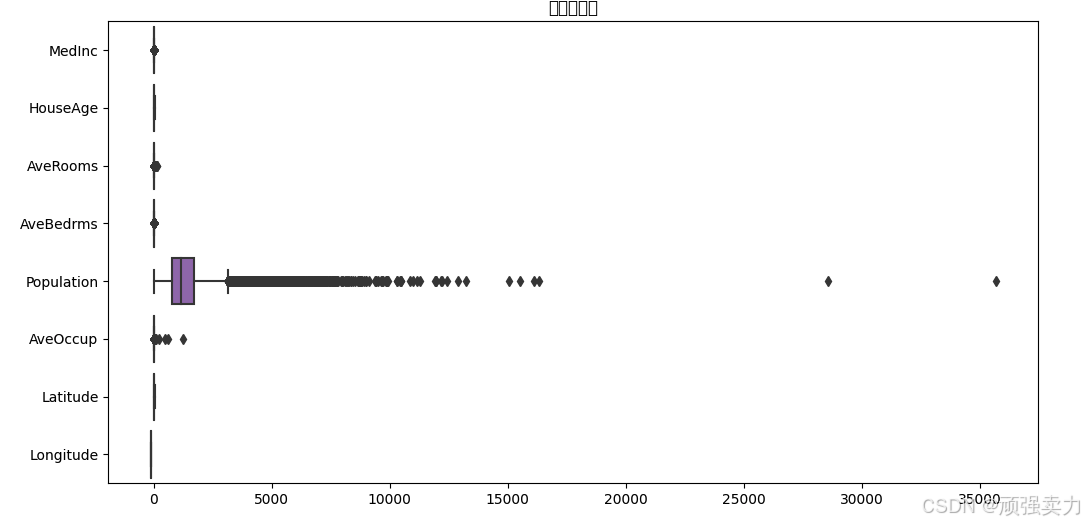
# 箱线图检查数据中是否存在异常值
plt.figure(figsize=(12, 6))
sns.boxplot(data=X, orient='h')
plt.title('特征箱线图')
plt.show()
# 如果特征的量纲差异较大,可以对数据进行标准化处理
from sklearn.preprocessing import StandardScaler
# 标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
X_scaled_df = pd.DataFrame(X_scaled, columns=california.feature_names)
# 查看标准化后的数据
print(X_scaled_df.head())
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# 创建线性回归模型
model = LinearRegression()
# 训练模型
model.fit(X_train, y_train)
# 对测试集进行预测
y_pred = model.predict(X_test)
# 使用均方误差(MSE)和决定系数(R²)来评估模型的性能
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
print(f"R^2 Score: {r2}")
模型优化
选择对目标变量影响最大的特征,可以使用统计方法或基于模型的方法(如Lasso回归)来选择特征。 正则化
为了防止过拟合,可以使用正则化方法,如Lasso回归(L1正则化)或Ridge回归(L2正则化):
from sklearn.linear_model import Lasso, Ridge
# Lasso回归
lasso = Lasso(alpha=0.1)
lasso.fit(X_train, y_train)
y_pred_lasso = lasso.predict(X_test)
# Ridge回归
ridge = Ridge(alpha=0.1)
ridge.fit(X_train, y_train)
y_pred_ridge = ridge.predict(X_test)
# 使用交叉验证来评估模型的稳定性和泛化能力
from sklearn.model_selection import cross_val_score
scores = cross_val_score(model, X_scaled, y, cv=5, scoring='r2')
print(f"Cross-Validation R^2 Scores: {scores}")
print(f"Mean Cross-Validation R^2 Score: {np.mean(scores)}")
通过上述步骤,我们可以得到一个线性回归模型,并对其进行评估和优化。最终,我们可以根据模型的性能指标(如MSE和R²)来判断模型的好坏,并根据需要进行进一步的调整和优化。
我已经为大家准备好了机器学习常见模型详解的ipynb,想要获取更多资源,请关注V❤️公主号【海水三千】,回复【算法详解】即可获取完整文件!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











