






 本文详细介绍如何在本地环境中配置和运行Apache Spark程序,包括设置必要的环境变量、参数配置、数据读取与处理流程,以及如何避免常见错误,适用于初学者进行Spark应用的测试与调试。
本文详细介绍如何在本地环境中配置和运行Apache Spark程序,包括设置必要的环境变量、参数配置、数据读取与处理流程,以及如何避免常见错误,适用于初学者进行Spark应用的测试与调试。
本地运行spark主要用于做测试和debug,在文件中抽取少量数据,用来测试
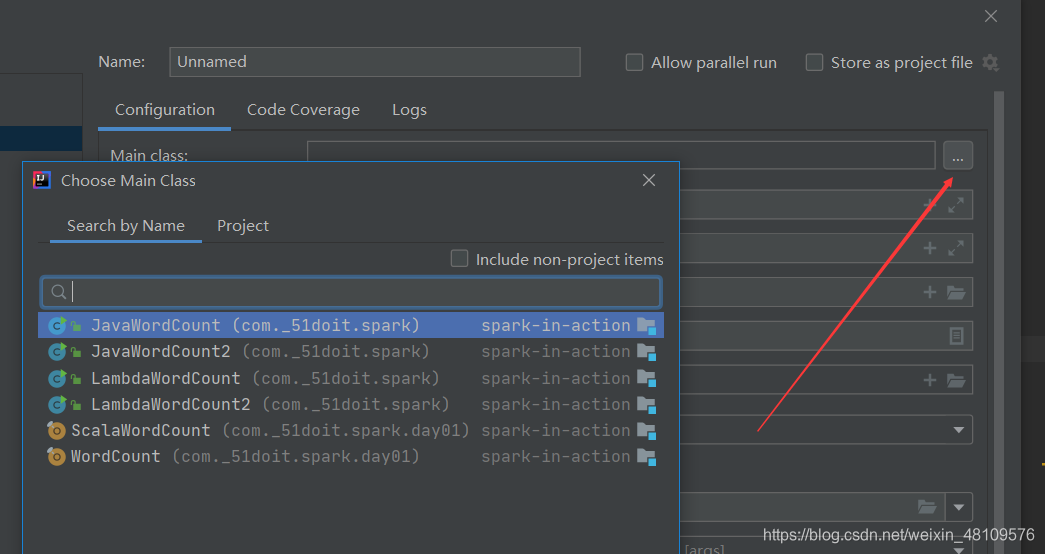
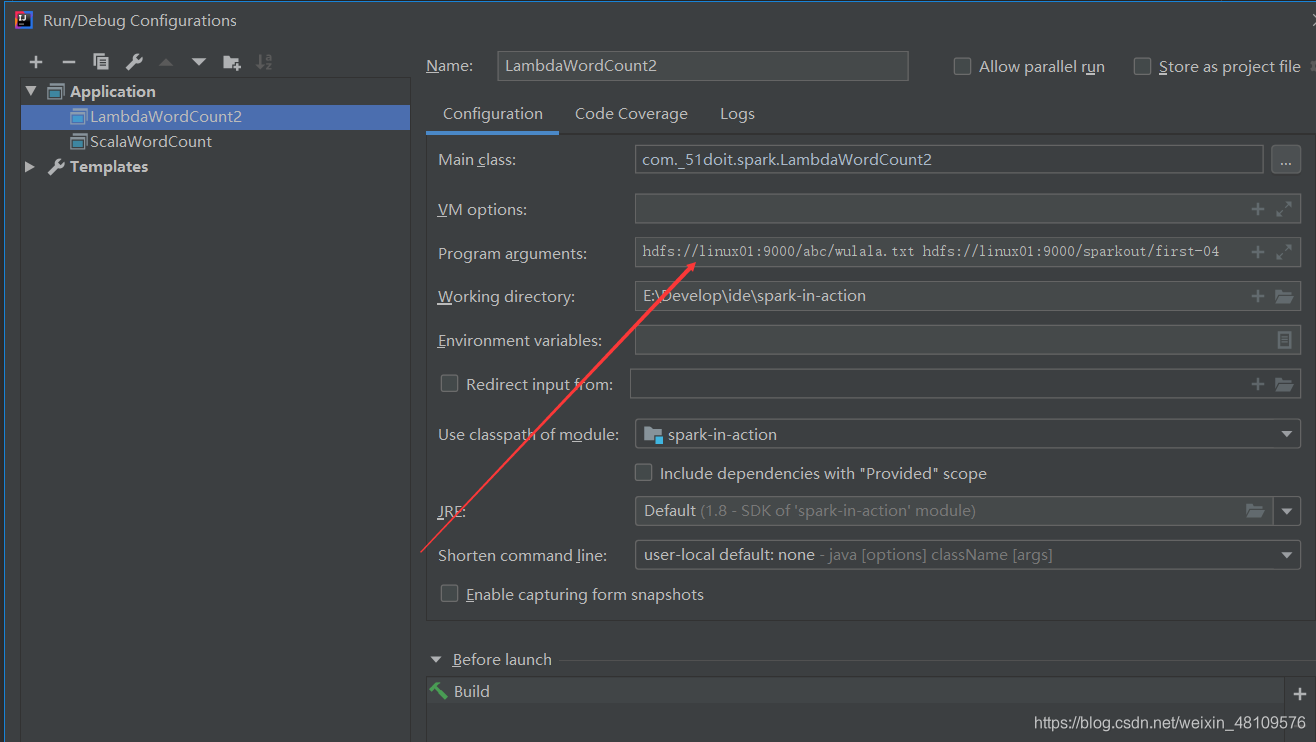
在hdfs上查找文件,输出文件需要的参数//System.setProperty("HADOOP_USER_NAME","root");在本地运行需要的参数//SparkConf conf = new SparkConf().setAppName("LambdaWordCount2").setMaster("local[*]");我将输入文件和输出文件用变量代替,所有我们选择运行的时候需要
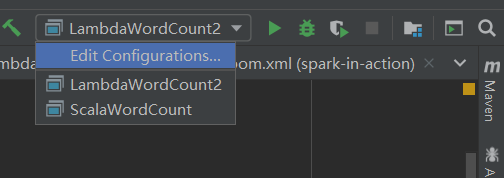
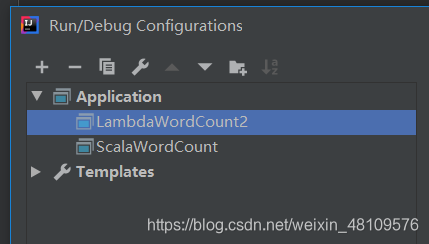
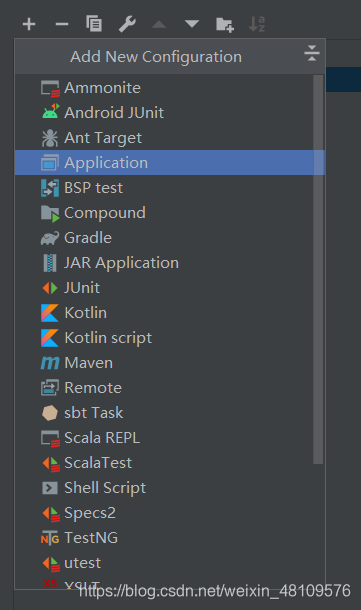
找到所在的类
上传到hdfs上运行
本地运行直接写,输入文件的path和输出的path
注意输出的目录不要存在否则报错.如果读取输出hdfs中一定要加System.setProperty("HADOOP_USER_NAME","root");
public class LambdaWordCount { public static void main(String[] args) { System.setProperty("HADOOP_USER_NAME","root"); //获取javaSpark的conf传入Jsc SparkConf conf = new SparkConf().setAppName("LambdaWordCount").setMaster("local[*]");; //将conf传入jsc中 JavaSparkContext jsc = new JavaSparkContext(conf); //获取RDD大集合 JavaRDD<String> javaRDD = jsc.textFile(args[0]); //使用flatMap方法拆分压平--因为java中flatMap方法返回的是iterator迭代器,所以需要将数组转成集合,在.迭代器,让返回值也是迭代器 JavaRDD<String> words = javaRDD.flatMap(lines -> Arrays.asList(lines.split(" ")).iterator()); //使用map方法聚合+1,形成元组,但java没有元组,所以需要调取Tuple2.apply方法转成元组形式,不能调map方法,这样就没有ReduceByKe了 JavaPairRDD<String, Integer> wordAndOne = words.mapToPair(w -> Tuple2.apply(w, 1)); //使用ReduceByKey,输入x+y逻辑,将相同key的values聚合 JavaPairRDD<String, Integer> reduceWord = wordAndOne.reduceByKey((x, y) -> (x + y)); //排序,java中排序只有SortByKey,所以需要调mapToPair方法将 key和values翻转,这样values在前,key在后 JavaPairRDD<Integer, String> swapWords = reduceWord.mapToPair(Tuple2::swap); //按照调换的value进行排序,false是倒叙 JavaPairRDD<Integer, String> sortByWord = swapWords.sortByKey(false); //使用mapToPair再次调换value和key JavaPairRDD<String, Integer> gogogo = sortByWord.mapToPair(Tuple2::swap); //Transformation 结束 //Action算子,会触发任务执行 //将数据保存到HDFS gogogo.saveAsTextFile(args[1]); jsc.stop(); } }


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









