







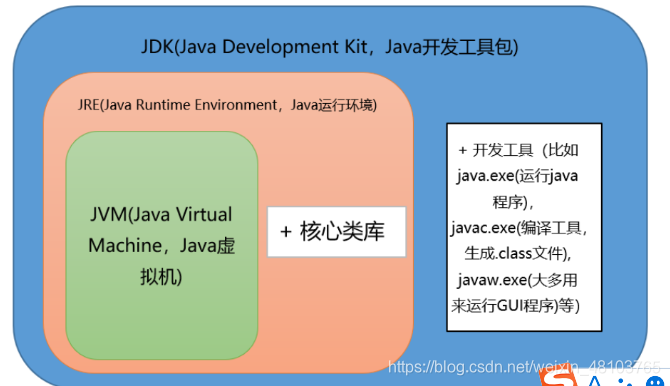
JVM的位置
JVM也是一个软件,运行在操作系统之上
java文件的运行过程:
.java文件---->.class文件---->jvm
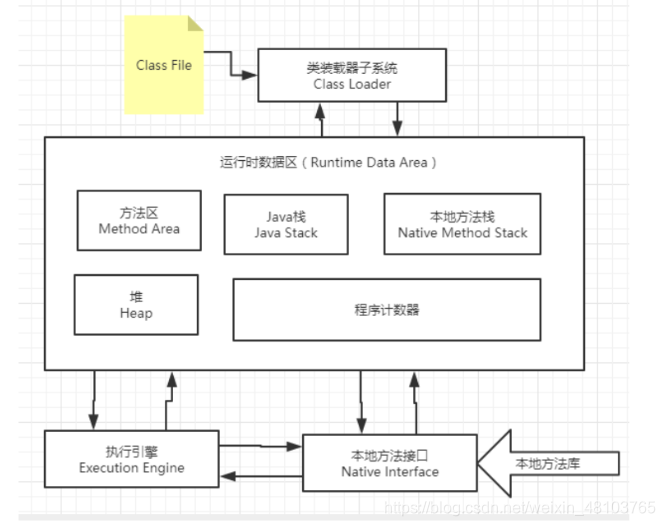
JVM体系结构
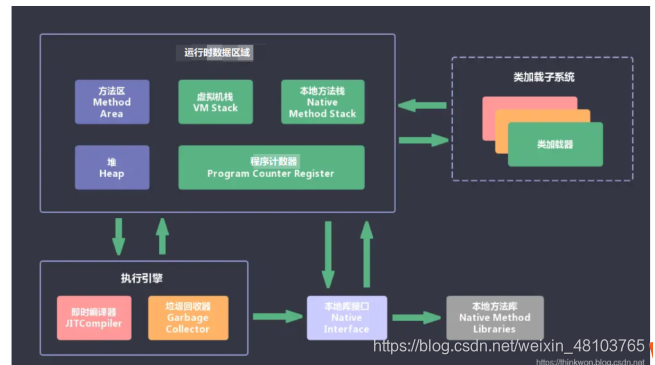
垃圾回收在方法区和堆中
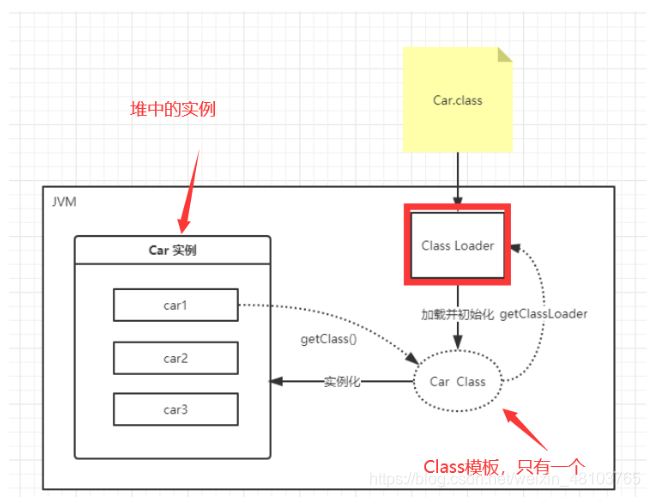
类加载器
作用:加载.class文件
类加载器的种类(等级从高到低)
jvm自带的加载器:
1.启动类(根)加载器(Bootstrap ClassLoader)用来加载java核心类库,无法被java程序直接引用。
2.扩展类加载器(extensions class loader):它用来加载 Java 的扩展库。Java 虚拟机的实现会提供一
个扩展库目录。该类加载器在此目录里面查找并加载 Java 类。
3.应用程序(系统类)加载器:你写的类一般都是它加载的。
ps:rt.jar
用户自定义的类加载器:
继承java.lang.ClassLoader
双亲委派机制
一个类先从app累加器,由等级从低到高,然后推到上一层,直到bootstrap根加载器
如果在高的加载器中找到类,则直接加载,否则再往下推,直到app加载器
Native关键字
凡是带了native关键字的,说明java的范围达不到了,需要调用底层c语言的库
凡是带了native的方法,调用时会进入本地方法栈(Native Method Stack),调用本地方法接口调用本地方法库
JNI:java native interface,java本地接口(扩展java的使用,融合不同的语言为java所用,最初即是c,c++)
PC寄存器:
即程序计数器:Program Counter Register
每个线程都有一个程序计数器,是线程私有的,就是一个指针,指向方法区中的方法字节码,用来指向指令的地址
方法区:被所有线程共享,所有字段和方法字节码,以及一些特殊的方法,如构造函数,接口也在这里定义,简单来说,所有定义的方法的信息都保存在该区域,此区域 属于共享区间。
方法区存储:静态变量、常量、类信息(构造方法、接口定义)、运行时的常量池也在方法区。(static final Class 常量池)
栈
java虚拟机栈
方法先入栈,就是先执行,栈顶的方法就是正在执行的方法(main方法最先开始,最后结束)
栈存储:8大基本类型的数据,对象的引用,实例的方法
栈也叫栈内存,主管程序的运行,生命周期和线程同步。线程结束,栈内存也就释放,对于栈来说,不存在垃圾回收问题。
栈运行原理:栈帧;
栈+堆+方法区的交互关系
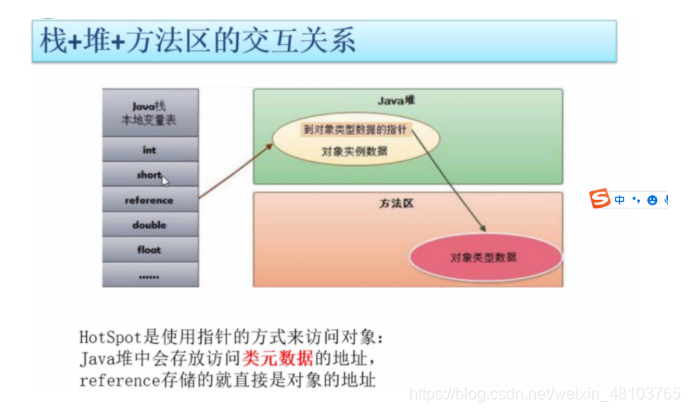
走近HotSpot
1.三种JVM
1.Sun 的 HotSpot
2.Bea 的 JRockit
3.IBM 的 J9VM
堆
Heap,一个JVM只有一个堆内存,堆的大小可以调节。
堆存储:(这里主要指不包括方法区的)对象的实例(成员变量,方法等),数组
堆内存细分:
- 新生区(伊甸园区) Young Generation Space Young/New
- 养老区 Tenure generation space Old/Tenure
- 永久区 Permanent Space Perm(jdk8后称为元空间)

GC垃圾回收主要是在 新生区和养老区,又分为 轻GC (新生区)和 重GC,如果内存不够,或者存在死循环,就会导致 java.lang.OutOfMemoryError: Java heap space
新生区是类诞生,成长,消亡的区域,一个类在这里产生,应用,最后被垃圾回收器收集,结束生命。新生区又分为两部分:伊甸区(Eden Space)和幸存者区(Survivor Space),所有的类都是在伊甸区被new出来的,幸存区有两个:0区 和 1区,当伊甸园的空间用完时,程序又需要创建对象,JVM的垃圾回收器将对伊甸园区进行垃圾回收(Minor GC)。将伊甸园中的剩余对象移动到幸存0区,若幸存0区也满了,再对该区进行垃圾回收,然后移动到1区,那如果1区也满了呢?(这里幸存0区和1区是一个互相交替的过程)再移动到养老区,若养老区也满了,那么这个时候将产生MajorGC(Full GC),进行养老区的内存清理,若养老区执行了Full GC后发现依然无法进行对象的保存,就会产生OOM异常
“OutOfMemoryError ”。
新生区,老年区,永久区
新生区
新生区是类诞生,成长,消亡的区域,一个类在这里产生,应用,最后被垃圾回收器收集,结束生命。新生区又分为两部分:伊甸区(Eden Space)和幸存者区(Survivor Space),所有的类都是在伊甸区被new出来的,幸存区有两个:0区 和 1区,当伊甸园的空间用完时,程序又需要创建对象,JVM的垃圾回收器将对伊甸园区进行垃圾回收(Minor GC)”轻GC"。将伊甸园中的剩余对象移动到幸存0区,若幸存0区也满了,再对该区进行垃圾回收,然后移动到1区,那如果1区也满了呢?(这里幸存0区和1区是一个互相交替的过程),产生MajorGC(Full GC)再移动到养老区,如果养老区,新生区都满了,则oom"out of memoryerror"
老年区
真理:有99%的的对象都是临时对象,很多在新生区就死亡
永久区
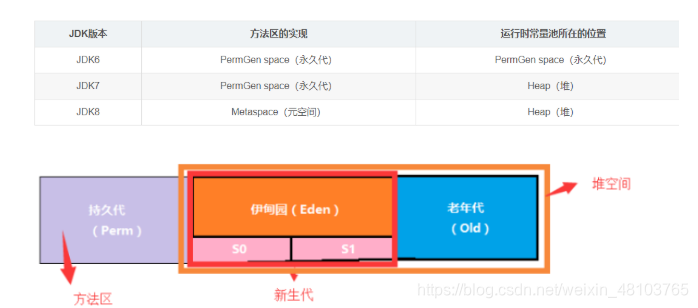
- jdk6之前:称为永久代,常量池在方法区,永久代是方法区的实现
- jdk7:永久代,但是慢慢退化了,常量池在堆中
- jdk8之后:无永久代,常量池在元空间
jvm内存查询:
public static void main(String[] args) {
//虚拟机试图使用的最大内存
long maxMemory = Runtime.getRuntime().maxMemory();//以字节为单位
System.out.println("最大内存为: "+maxMemory/1024/1024+"MB");
//返回JVM的总内存
long totalMemory = Runtime.getRuntime().totalMemory();
System.out.println("初始化占的内存为:"+ totalMemory/1024/1024+"MB");
//-Xmx 设置最大内存大小 1/4
//-Xms 设置初始分配大小 1/64
}
初始分配(Initial heap size )默认占cpu的1/64,最大内存(the maximum heap size)默认占用1/4

)]
上图设置jvm参数和输出GC信息
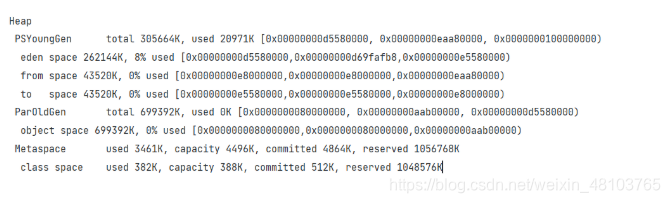
上图为GC信息输出
年轻代、老年代、元空间(可以看出老年代加上年轻代的内存),元空间逻辑上存在,实际上不存在(在本地内存)
使用Jprofiler分析oom原因
GC
垃圾回收只有在堆和方法区存在
记住GC口诀: 分代收集算法
次数频繁Young区,次数较少Old区,基本不动Perm(永久区)区
GC分两类:轻GC(普通的GC),重GC(全局GC)
普通GC:只针对新生代区域的GC
全局GC:针对老年代的GC,偶尔伴随对新生代的GC以及对永久代的GC
引用计数法
对象每引用一次给对象分配的计数器加1,对没有引用的对象(计数器为0)进行清除
缺点:
- 每次引用对象都要维护计数器,计数器本身也有消耗
- 较难处理循环引用
(jvm一般不用这个算法)
复制算法
主要是新生区使用
Survivoer的from和to区的区分:谁空谁是to
伊甸园的剩余的对象(GC后存活的)都会移动到幸存区(Survivor)。
复制算法即是:from区内存用完,(或者说to区有有一些从Eden来的对象)从from区拷贝存活的对象,放到to区,from和to在交换身份
-XX:MaxTenuringThreshold 任期时间=>设置对象在新生代中存活的次数
优点:
- 没有碎片内存
缺点:
- 浪费内存空间
最佳使用场景:新生区,对象存活度较低
标记清除
1.扫描对象,对活着的对象进行标记
2.扫描对象,对没有标记的对象进行清除
优点:
- 不需要额外的内存
缺点
- 两次扫描浪费时间
- 会产生内存碎片
标记清除压缩(标记整理)
1.扫描对象,对活着的对象进行标记
2.扫描对象,对没有标记的对象进行清除
3.将对象向一端移动,清除内存碎片
缺点:
多了移动的成本
总结
内存效率:复制算法>标记清除算法>标记压缩算法
内存整齐度:复制=标记压缩>标记清除
内存利用率:标记压缩=标记清除>复制算法
没有最好的算法,只有最合适的算法,jvm中根据分代选择算法----》分代收集算法
年轻代:存活率低,用复制算法
老年代:存活率高,区域大,标记清除+标记压缩(5次标记清除,1次压缩)
疑问:
什么时候进行GC?
参考:https://blog.youkuaiyun.com/pdf0824/article/details/77018879
堆与栈的区别:
1.物理地址:堆的物理地址分配不是连续的,因此性能较慢,栈的底层数据结构是栈,内存分配是连续的,性能较好
2.内存分别:堆是不连续的,内存分配在运行期决定,因此大小不固定,一般堆的大小远远大于栈;栈的内存分配是在编译期决定,大小是固定的。
3.存放的内容:
堆中存储的是对象的实例,实例变量(对象的内容),
栈中存储的是局部变量,局部的基本类型变量和对象的引用
各内存区域存储的内容:
方法区:Class模板(信息),static方法和变量,常量池
栈:对象引用,基本类型变量,局部变量
堆:对象的实例,实例对象
注:
实例变量(非static修饰的成员变量)和对象是关联在一起的
详细内容见博客:https://blog.youkuaiyun.com/u013241673/article/details/78574770

















 295
295

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









