







 本文介绍了Unix系统中的管道通信,包括管道的概念、使用方式、数据结构、创建与撤销,以及读写操作。此外,文章还深入探讨了Go语言中的channel,阐述了channel在goroutine间的通信机制,包括发送、接收、缓冲区管理和并发控制,展示了其与Unix管道通信的相似之处。
本文介绍了Unix系统中的管道通信,包括管道的概念、使用方式、数据结构、创建与撤销,以及读写操作。此外,文章还深入探讨了Go语言中的channel,阐述了channel在goroutine间的通信机制,包括发送、接收、缓冲区管理和并发控制,展示了其与Unix管道通信的相似之处。
管道通信
用户态的进程之间需要同步和交换数据,本质上是需要依靠内核来实现的。Unix系统提供了几种不同的进程间通信的方式来供程序员使用,这里只讨论管道通信。
管道通信适合在进程间实现生产者消费者的交互。有些进程向管道中写入数据,而另外的一些进程则需要从管道中读取数据。这是对管道通信的大致理解。
管道
管道是进程之间的一个单向数据流,即一个进程写入管道的所有数据都由内核定向到另一个进程,另一个进程就可以从管道中读取到数据。
在shell命令中可以使用“|”操作符来创建管道,使用下面的语句用shell来创建两个进程,并用一个管道来把这两个进程连接在一起。
ls | more
第一个进程ls的输出被重定向在管道中,第二个进程more从这个管道中读取输入。
管道使用
管道被看做是一种打开的文件,但是文件系统中没有他的映像。利用pipe()系统调用来创建一个新的管道,这个系统调用会返回一对文件描述符,然后利用fork()来把这两个描述符传递给它的子进程,来达到与子进程共享管道的目的。进程在read()系统调用中使用第一个文件描述符从管道中读取数据,同样也可以在write()系统调用中使用第二个文件描述符向管道中写入数据。
由于POSIX只定义了半双工的管道,虽然pipe()返回了两个描述符,每个进程在使用一个文件描述符之前仍然需要把另外一个文件描述符关闭,因为它采用的是单向的,一边输出到管道,另一边再从管道中读取。如果是双向的,就需要两次调用pipe()来实现,这里就是两个管道了。
Linux采取的方式是,每个管道的文件描述符仍然是单向,但在使用一个描述符之前不必把另外一个描述符关闭。这样虽然还是单向的,但是同时可以做全双工的事,进行双向传输。
数据结构
当索引节点inode指向管道
struct inode {
...
struct pipe_inode_info *i_pipe;
...
};
其中的i_pipe字段指向pipe_inode_info的结构体
#define PIPE_BUFFERS (16)
struct pipe_inode_info {
wait_queue_head_t wait;//管道/FIFO等待队列
unsigned int nrbufs, curbuf;//nrbufs包含待读数据的缓冲区数,curbuf包含待读数据的第一个缓冲区的索引
struct pipe_buffer bufs[PIPE_BUFFERS];//管道缓冲区描述符数据
struct page *tmp_page;//高速缓冲页框指针
unsigned int start;//当前管道缓冲区读的位置
unsigned int readers;//读进程的标志
unsigned int writers;//写进程的标志
unsigned int waiting_writers;//在等待队列中睡眠的写进程的个数
unsigned int r_counter;//与readers类似,当等待读取FIFO的进程时使用
unsigned int w_counter;//与readers类似,当等待写入FIFO的进程时使用
struct fasync_struct *fasync_readers;//用于通过信号进行的异步I/O通知
struct fasync_struct *fasync_writers;//用于通过信号进行的异步I/O通知
};
每个管道有自己的管道缓冲区pipe_buffer,他是一个单独的页。其中包含了已经写入管道等待读取的数据。
struct pipe_buffer {
struct page *page;//管道缓冲页框的描述符地址
unsigned int offset, len;//offset页框内有效数据的当前位置,len页框内有效数据的长度
struct pipe_buf_operations *ops;//管道缓冲区方法表的地址(缓冲区为空时为NULL)
};
ops指向缓冲区方法表pipe_buf_operations
struct pipe_buf_operations {
int can_merge;
void * (*map)(struct file *, struct pipe_inode_info *, struct pipe_buffer *);
//在访问缓冲区数据之前调用。只在管道缓冲区在高端内存时对管道缓冲区页框调用kmap()
void (*unmap)(struct pipe_inode_info *, struct pipe_buffer *);
//不在访问缓冲区数据时调用,对管道缓冲区页框调用kunmap()
void (*release)(struct pipe_inode_info *, struct pipe_buffer *);
//当释放管道缓冲区时调用。实现了一个单页内存高速缓存:释放的不是存放缓冲区的那个页框,而是由pipe_inode_info数据结构的tmp_page字段指向的高速缓存页框。存放缓冲区的页框变成了新的高速缓存页框。
};
16个缓冲区可以被看作一个整体环形缓冲区:写进程不断向这个大缓冲区追加数据,而读进程则不断移出数据,所有管道缓冲区中当前写入而等待读出的字节数就是所谓的管道大小。为提高效率,仍然要读的数据可以分散在几个未填充满的管道缓冲区内:事实上,在上一个管道缓冲区没有足够空间存放新数据时,每个写操作都可能会把数据拷贝到一个新的空管道缓冲区。因此,内核必须记录:
-
下一个待读字节所在的管道缓冲区、页框中的对应偏移量。该管道缓冲区的索引存放在pipe_inode_info数据结构的curbuf字段,而偏移量在相应pipe_buffer对象的offset字段。
-
第一个空管道缓冲区。它可以通过增加当前管道缓冲区的索引得到,并存放在pipe_inode_info数据结构的curbuf字段,而存放有效数据的管道缓冲区号存放在nrbufs字段。
为了避免对管道数据结构的竞争条件,内核使用包含在索引节点对象中的i_sen信号量。
管道创建
pipe()系统调用由sys_pipe()处理。
asmlinkage long sys_pipe(int __user *fildes)
{
int fd[2];
int error;
error = do_pipe(fd);
if (!error) {
if (copy_to_user(fildes, fd, 2*sizeof(int)))
error = -EFAULT;
}
return error;
}
sys_pipe调用do_pipe
int do_pipe(int *fd)
{
struct qstr this;
char name[32];
struct dentry *dentry;
struct inode * inode;
struct file *f1, *f2;//两个文件描述符,一个读一个写
int error;
int i,j;
error = -ENFILE;
f1 = get_empty_filp();
if (!f1)
goto no_files;
f2 = get_empty_filp();
if (!f2)
goto close_f1;
inode = get_pipe_inode();//为pipefs文件系统中的管道分配一个索引结点对象,并进行初始化。
if (!inode)
goto close_f12;
error = get_unused_fd();
if (error < 0)
goto close_f12_inode;
i = error;
error = get_unused_fd();
if (error < 0)
goto close_f12_inode_i;
j = error;
error = -ENOMEM;
sprintf(name, "[%lu]", inode->i_ino);
this.name = name;
this.len = strlen(name);
this.hash = inode->i_ino; /* will go */
dentry = d_alloc(pipe_mnt->mnt_sb->s_root, &this);//分配目录项对象
if (!dentry)
goto close_f12_inode_i_j;
dentry->d_op = &pipefs_dentry_operations;
d_add(dentry, inode);
//将两个文件对象和索引节点对象连接起来
f1->f_vfsmnt = f2->f_vfsmnt = mntget(mntget(pipe_mnt));
f1->f_dentry = f2->f_dentry = dget(dentry);
f1->f_mapping = f2->f_mapping = inode->i_mapping;
/* read file */
//为读管道分配一个文件对象和一个文件描述符
f1->f_pos = f2->f_pos = 0;
f1->f_flags = O_RDONLY;
f1->f_op = &read_pipe_fops;//read_pipe_fops表的地址
f1->f_mode = FMODE_READ;
f1->f_version = 0;
/* write file */
f2->f_flags = O_WRONLY;
f2->f_op = &write_pipe_fops;//write_pipe_fops的地址
f2->f_mode = FMODE_WRITE;
f2->f_version = 0;
fd_install(i, f1);
fd_install(j, f2);
fd[0] = i;
fd[1] = j;
return 0;
close_f12_inode_i_j:
put_unused_fd(j);
close_f12_inode_i:
put_unused_fd(i);
close_f12_inode:
free_pipe_info(inode);
iput(inode);
close_f12:
put_filp(f2);
close_f1:
put_filp(f1);
no_files:
return error;
}
管道撤销
release方法可以由pipe_read_release和pipe_write_release来实现,他们都调用pipe_release
static int
pipe_release(struct inode *inode, int decr, int decw)
{
down(PIPE_SEM(*inode));
PIPE_READERS(*inode) -= decr;
PIPE_WRITERS(*inode) -= decw;
if (!PIPE_READERS(*inode) && !PIPE_WRITERS(*inode)) {
free_pipe_info(inode);
} else {
wake_up_interruptible(PIPE_WAIT(*inode));
kill_fasync(PIPE_FASYNC_READERS(*inode), SIGIO, POLL_IN);
kill_fasync(PIPE_FASYNC_WRITERS(*inode), SIGIO, POLL_OUT);
}
up(PIPE_SEM(*inode));
return 0;
}
当管道缓冲区中待读的进程和待写的进程都为0时释放他们的管道描述符,也就是把他的readers和writers字段设置为0,释放他的高速缓冲页框和管道缓冲区页框。否则就会唤醒管道等待队列上的任意进程,让他们识别管道状态的变化。
管道读
内核会通过查找文件描述符相关的文件操作表找到相应read方法
struct file_operations read_pipe_fops = {
.llseek = no_llseek,
.read = pipe_read,
.readv = pipe_readv,
.write = bad_pipe_w,
.poll = pipe_poll,
.ioctl = pipe_ioctl,
.open = pipe_read_open,
.release = pipe_read_release,
.fasync = pipe_read_fasync,
};
read方法指向pipe_read
static ssize_tpipe_read(struct file *filp, char __user *buf, size_t count, loff_t *ppos){ struct iovec iov = {
.iov_base = buf,
.iov_len = count
};
return pipe_readv(filp, &iov, 1, ppos);
}
static ssize_tpipe_readv(struct file *filp, const struct iovec *_iov, unsigned long nr_segs, loff_t *ppos){
struct inode *inode = filp->f_dentry->d_inode;
struct pipe_inode_info *info;
int do_wakeup; ssize_t ret;
struct iovec *iov = (struct iovec *)_iov;
size_t total_len;
total_len = iov_length(iov, nr_segs); /* Null read succeeds. */
if (unlikely(total_len == 0))
return 0;
do_wakeup = 0;
ret = 0;
down(PIPE_SEM(*inode));//获取i_sem信号量
info = inode->i_pipe;
for (;;) { int bufs = info->nrbufs;
if (bufs) {//判断管道大小是否为0
int curbuf = info->curbuf;//获得当前缓冲区的索引
struct pipe_buffer *buf = info->bufs + curbuf;
struct pipe_buf_operations *ops = buf->ops;
void *addr;
size_t chars = buf->len;
int error;
if (chars > total_len)
chars = total_len;
addr = ops->map(filp, info, buf);//执行map方法
error = pipe_iov_copy_to_user(iov, addr + buf->offset, chars);
//从管道缓冲区拷贝请求的字节数到用户地址空间
ops->unmap(info, buf);//执行unmap方法
if (unlikely(error)) {
if (!ret) ret = -EFAULT;
break;
}
ret += chars;
buf->offset += chars;//更新offset
buf->len -= chars;//更新len
if (!buf->len) {//如果缓冲区为空了
buf->ops = NULL;
ops->release(info, buf);//释放页框
curbuf = (curbuf + 1) & (PIPE_BUFFERS-1);
info->curbuf = curbuf;
info->nrbufs = --bufs;//减少非空管道缓冲区的计数值
do_wakeup = 1;
}
total_len -= chars;
if (!total_len)
break; /* common path: read succeeded */
}
if (bufs) /* More to do? */
continue;
if (!PIPE_WRITERS(*inode))
break;
if (!PIPE_WAITING_WRITERS(*inode)) {
//至少有一个写进程在睡眠,且读操作阻塞
/* syscall merging: Usually we must not sleep * if O_NONBLOCK is set, or if we got some data. * But if a writer sleeps in kernel space, then * we can wait for that data without violating POSIX. */
if (ret)
break;
if (filp->f_flags & O_NONBLOCK) {
ret = -EAGAIN;
break;
}
}
if (signal_pending(current)) {
if (!ret) ret = -ERESTARTSYS;
break;
}
if (do_wakeup) {
//唤醒睡眠的所有进程
wake_up_interruptible_sync(PIPE_WAIT(*inode));
kill_fasync(PIPE_FASYNC_WRITERS(*inode), SIGIO,POLL_OUT); }
pipe_wait(inode);
}
up(PIPE_SEM(*inode));//释放i_sem信号量
/* Signal writers asynchronously that there is more room. */
if (do_wakeup) {
//唤醒所有在管道的等待队列中的所有睡眠的写进程
wake_up_interruptible(PIPE_WAIT(*inode));
kill_fasync(PIPE_FASYNC_WRITERS(*inode), SIGIO, POLL_OUT);
}
if (ret > 0)
file_accessed(filp);
return ret;//返回拷贝到用户地址空间的字节数}
管道写
与读类似
struct file_operations write_pipe_fops = {
.llseek = no_llseek,
.read = bad_pipe_r,
.write = pipe_write,
.writev = pipe_writev,
.poll = pipe_poll,
.ioctl = pipe_ioctl,
.open = pipe_write_open,
.release = pipe_write_release,
.fasync = pipe_write_fasync,
};
write指向pipe_write
pipe_write(struct file *filp, const char __user *buf, size_t count, loff_t *ppos){
struct iovec iov = {
.iov_base = (void __user *)buf,
.iov_len = count
};
return pipe_writev(filp, &iov, 1, ppos);
}
static ssize_tpipe_writev(struct file *filp, const struct iovec *_iov, unsigned long nr_segs, loff_t *ppos){
struct inode *inode = filp->f_dentry->d_inode;
struct pipe_inode_info *info;
ssize_t ret;
int do_wakeup;
struct iovec *iov = (struct iovec *)_iov;
size_t total_len;
total_len = iov_length(iov, nr_segs); /* Null write succeeds. */
if (unlikely(total_len == 0))
return 0;
do_wakeup = 0;
ret = 0;
down(PIPE_SEM(*inode));//获取i_sem信号量
info = inode->i_pipe;
if (!PIPE_READERS(*inode)) {
//检查管道读进程是否为0
send_sig(SIGPIPE, current, 0);
ret = -EPIPE;
goto out;
} /* We try to merge small writes */
if (info->nrbufs && total_len < PAGE_SIZE) {
int lastbuf = (info->curbuf + info->nrbufs - 1) & (PIPE_BUFFERS-1);
//当前待读第一个缓冲区索引+待读的缓冲区数-1正好是最后一个缓冲区的索引。
struct pipe_buffer *buf = info->bufs + lastbuf;
struct pipe_buf_operations *ops = buf->ops;
int offset = buf->offset + buf->len;
if (ops->can_merge && offset + total_len <= PAGE_SIZE) {
//如果空间足够写入,就进行拷贝
void *addr = ops->map(filp, info, buf);
int error = pipe_iov_copy_from_user(offset + addr, iov, total_len);//拷贝函数
ops->unmap(info, buf);
ret = error;
do_wakeup = 1;
if (error)
goto out;
buf->len += total_len;
ret = total_len;
goto out;
}
}
for (;;) {
int bufs;
if (!PIPE_READERS(*inode)) {
send_sig(SIGPIPE, current, 0);
if (!ret) ret = -EPIPE;
break;
}
bufs = info->nrbufs;
if (bufs < PIPE_BUFFERS) {
//待读缓冲区数小于16
ssize_t chars;
int newbuf = (info->curbuf + bufs) & (PIPE_BUFFERS-1);
struct pipe_buffer *buf = info->bufs + newbuf;
//空的管道缓冲区索引=待读缓冲区数+待读的第一个索引
struct page *page = info->tmp_page;
int error;
if (!page) {
//当高速缓冲页框指针为空,需要给他分配页框
page = alloc_page(GFP_HIGHUSER);
if (unlikely(!page)) {
ret = ret ? : -ENOMEM;
break;
}
info->tmp_page = page;
}
/* Always wakeup, even if the copy fails. Otherwise * we lock up (O_NONBLOCK-)readers that sleep due to * syscall merging. * FIXME! Is this really true? */
do_wakeup = 1;
chars = PAGE_SIZE;
if (chars > total_len)
chars = total_len;
error = pipe_iov_copy_from_user(kmap(page), iov, chars);
kunmap(page);
if (unlikely(error)) {
if (!ret) ret = -EFAULT;
break;
}
ret += chars; /* Insert it into the buffer array */
buf->page = page;//设置为页框描述符的地址
buf->ops = &anon_pipe_buf_ops;//设置为anon_pipe_buf_ops的地址
buf->offset = 0;
buf->len = chars;//写入的字节数
info->nrbufs = ++bufs;//待读管道缓冲区+1
info->tmp_page = NULL;
total_len -= chars;
if (!total_len)
break;
}
if (bufs < PIPE_BUFFERS)//请求的字节还没写完
continue;
if (filp->f_flags & O_NONBLOCK) {
if (!ret) ret = -EAGAIN;
break;
}
if (signal_pending(current)) {
if (!ret) ret = -ERESTARTSYS;
break;
}
if (do_wakeup) {
wake_up_interruptible_sync(PIPE_WAIT(*inode));
kill_fasync(PIPE_FASYNC_READERS(*inode), SIGIO, POLL_IN);
do_wakeup = 0;
}
PIPE_WAITING_WRITERS(*inode)++;
pipe_wait(inode);
PIPE_WAITING_WRITERS(*inode)--; }
out:
up(PIPE_SEM(*inode));//释放i_sem信号量
if (do_wakeup) {//唤醒所有等待的读进程
wake_up_interruptible(PIPE_WAIT(*inode));
kill_fasync(PIPE_FASYNC_READERS(*inode), SIGIO, POLL_IN); }
if (ret > 0)
inode_update_time(inode, 1); /* mtime and ctime */
return ret;//返回写入的字节数。
}
go中的channel
进程间通信有很多方法,上文中介绍的是管道通信只是其中的一种,这里我在学习go的时候也发现go中的“进程间通信”,这里其实通信的是协程goroutine。
Go语言中倡导使用channel作为goroutine之间同步和通信的手段。channel类型属于引用类型,且每个channel只能传递固定类型的数据,channel 声明如下所示:
var channeIName chan T
这行代码表示,我们通过chan关键字声明了一个新的channel,并且声明时指定channel内传输的数据类型T.
channel的发送与接收
channel作为一个队列,它会保证数据收发顺序总是遵循先入先出的原则进行:同时它也会保证同一时刻内有且仅有一个goroutine访问channel来发送和获取数据。
从channel发送数据需要使用“<-”符号,如下所示:
channel <- val
这行代码表示val将被发送到channel中,在channel被填满之后再向通道中发送将会阻塞当前goroutine。而从channel中读取数据也是使用符号“<-”,只不过待接收的数据和channel的位置互换了。
val := <- channel
这行代码表示从channel中读取一个值并赋值到val上,如果channel中没有数据,将会阻塞读取的goroutine直到有数据被放入channel。也可以在读取channel时立即返回。如下:
val, ok:= < -channel
这时需要检查ok是否为true,用于判断是否读取到了有效数据。
创建channel时我们需要借助make函数对channel进行初始化,形式如下:
ch := make(chan T, sizeOfChan)
在创建channel时需要指定channel传输的数据类型,可以选择指定channel的长度。 如果不指定,那么往channel中发送数据的goroutine 将会被阻塞,直到数据被读取;而指定了长度的channel将会携带sizeOfChan的缓冲区,在缓冲区未满时发送数据不会被阻塞。无论channel是否携带缓冲区,读取的goroutine都会被阻塞,直到channel中有数据可被读取。
实例:
创建一个channel 用于在两个goroutine 中发送数据,其中一个goroutine 从命令行读取输入发送到channel中:另一个goroutine循环性的从channel中读取数据并输出。
代码如下所示:
package mainimport ( "bufio" "fmt" "os")func printInput(ch chan string) { // 使用 for 循环从 channel 中读取数据 for val := range ch{ // 读取到结束符号 if val == "EOF"{ break } fmt.Printf("Input is %s\n", val) }}func main() { // 创建一个无缓冲的 channel ch := make(chan string) go printInput(ch) // 从命令行读取输入 scanner := bufio.NewScanner(os.Stdin) for scanner.Scan() { val := scanner.Text() ch <- val if val == "EOF"{ fmt.Println("End the game!") break } } // 程序最后关闭 ch defer close(ch)}
在命令行中输入字符串,输出如下:
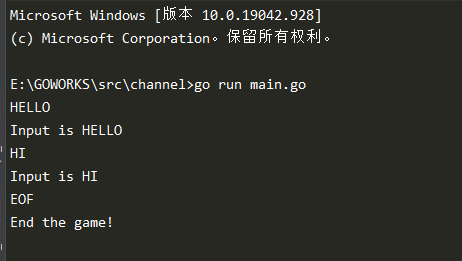
接下来演示一个带缓冲区的channel,要让一个channel带缓冲区,我们需要在一开始就指定channel的长度。goroutine在缓冲区未满时往channel发送数据将不会被阻塞。
代码如下:
package mainimport ( "fmt" "time")func consume(ch chan int) { // 线程休息 5s 再从 channel 读取数据 time.Sleep(time.Second * 5) <- ch}func main() { //创建一个长度为 2 的 channel ch := make(chan int, 2) go consume(ch) ch <- 0 ch <- 1 // 发送数据不被阻塞 fmt.Println("I am free!") ch <- 2 fmt.Println("I can not go there within 5s!") time.Sleep(time.Second)}
在5秒内输出的结果都是 I am free!,缓冲区满了之后继续往channel中发送数据的goroutine将会被阻塞,直到channel中的数据被读取,也就是5秒之后。

总结
可以看到go中的协程通信本质上和linux中的进程间通信里的管道通信很相似,都有缓冲区,都可以相互之间通信,数据的收发顺序都是先进先出。这里的协程通信在后面的一些服务设计中非常重要,进程间通信作为他们的根基,可以帮助我们很好的理解这部分知识。

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









