







 面对10万个服务向Eureka注册中心的高并发请求,通过构建Eureka集群并控制规模,结合服务元信息网关和缓存数据库,将大量并发转化为单一请求,降低对Eureka的压力,实现高效的服务发现。缓存数据设置短效期,确保数据实时同步。
面对10万个服务向Eureka注册中心的高并发请求,通过构建Eureka集群并控制规模,结合服务元信息网关和缓存数据库,将大量并发转化为单一请求,降低对Eureka的压力,实现高效的服务发现。缓存数据设置短效期,确保数据实时同步。
在一个超大型的系统中,有100K个Client,也就是10万个服务,这么多个服务定时向Eureka注册中心请求发现服务时,应该怎样处理?
首先,我们可以让多个Eureka相互注册构成集群,多个服务向集群内的不同Eureka定时请求发现服务,不同的Eureka之间会相互同步服务地址数据。
Eureka的部署方式如下图所示:
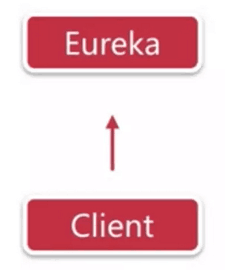
一、 Eureka单点
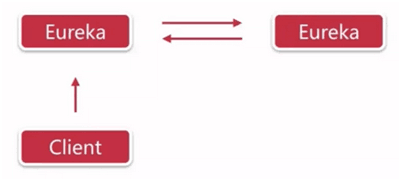
二、 两台Eureka相互注册
三、 三台Eureka相互注册
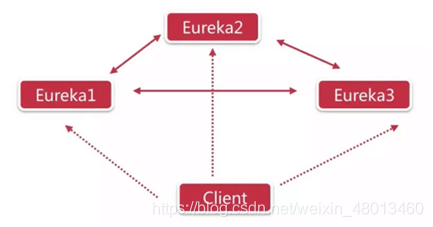
通过上面的图示我们可以发现,随着集群内Eureka数量的增多,Eureka之间相互同步数据将占用更多的资源,所以控制集群的规模对于实现高并发服务发现来说非常重要。
我们可以在Client和Eureka集群之间加一个缓存处理系统,该系统由两部分组成,一是服务元信息网关,二是高性能的缓存数据库。
当很多个服务高并发地请求服务发现时,并不直接访问Eureka,虽然Eureka可以配置为集群,能够处理很高的并发,但我们有一个前提,就是在控制Eureka集群规模的情况下处理极高并发,让100K
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









