








目录
二、图片转文本(image-to-text/image-text-to-text)
一、引言
pipeline(管道)是huggingface transformers库中一种极简方式使用大模型推理的抽象,将所有大模型分为音频(Audio)、计算机视觉(Computer vision)、自然语言处理(NLP)、多模态(Multimodal)等4大类,28小类任务(tasks)。共计覆盖32万个模型

今天介绍多模态的第四篇:图片转文本(image-to-text/image-text-to-text),在huggingface库内可以使用pipeline两行代码部署的图片转文本(image-to-text)模型有700个,因为2024年图片多模态大模型的兴起,在图片文本转文本(image-text-to-text)任务中,模型有5000+。关于图片文本转文本(image-text-to-text),之前写了很多篇,可以参考我之前的两篇文章:
【机器学习】GLM-4V:图片识别多模态大模型(MLLs)初探
【机器学习】阿里Qwen-VL:基于FastAPI私有化部署你的第一个AI多模态大模型
今天主要对如何使用pipeline两行代码部署的图片转文本(image-to-text)模型进行讲解。
二、图片转文本(image-to-text/image-text-to-text)
2.1 概述
图片转文本(image-to-text/image-text-to-text)模型从给定图像输出文本。图像字幕或光学字符识别可视为图像转文本的最常见应用。
图片特征提取与文本生成在技术上主要有2个流派:
- ViT+GPT2:上一篇讲的是图片特征提取,主要讲到了Vision Transformer (ViT)方法,但ViT仅有encode结构,只能将图片转换为特征向量,无法进行文本生成,本篇进一步将ViT和GPT2融合,本质上是在ViT上新增一个decode结构,提供文本补全的功能。(Qwen-VL、GLM-4V)等均属于这个流派。
- CLIP+BLIP:同样的,另一个图片特征提取流派:对比学习CLIP也是仅有encode,无法进行文本生成,于是Salesforce团队研发了BLIP,在CLIP的基础上新增decode结构,具体论文见BLIP)。
为了保证技术连贯性,今天在上一篇ViT基础上,讲解ViT+GPT2。
2.2 nlpconnect/vit-gpt2
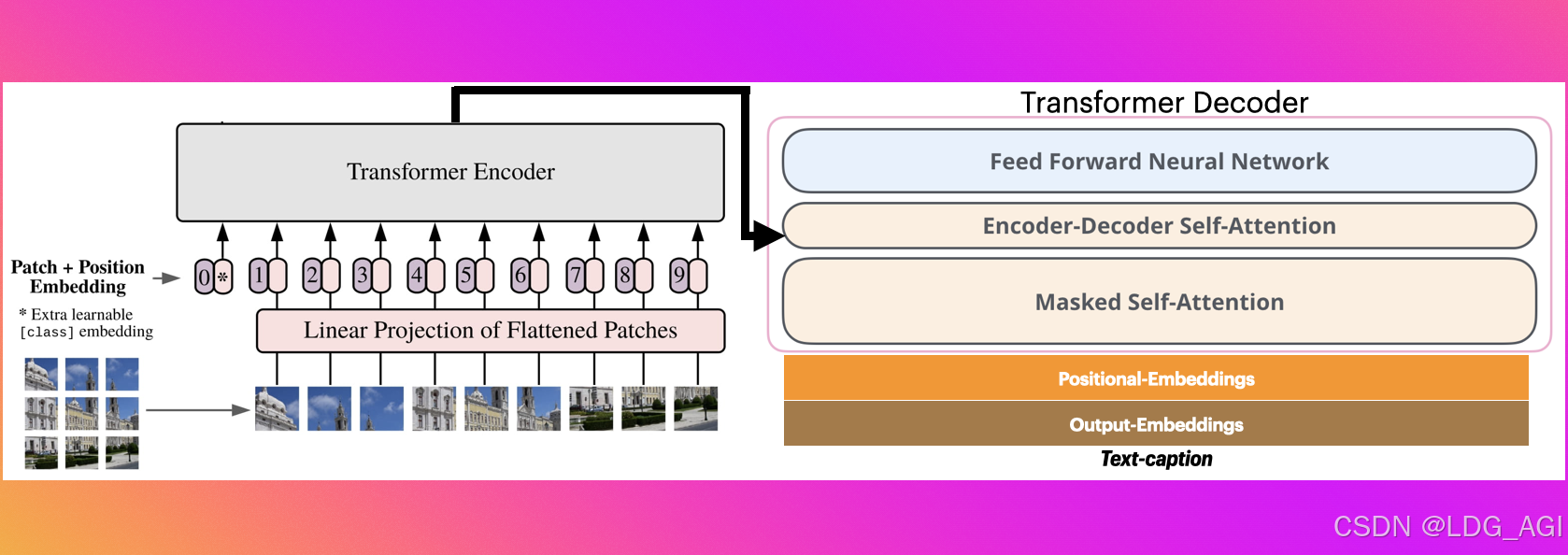
ViT部分:首先将图片切分成大小相等的块序列(分辨率为16*16),对每个图片块进行线性嵌入添加位置信息,通过喂入一个标准的transformer encoder结构进行特征交叉。
GPT部分:将文本token向量化后,经过embedding层、Masked Self-Attention层,在Encoder-Decoder Self-Attention层与ViT的Transformer Encoder输出相连接。
这样ViT与GPT可以进行联合学习,完成图片到文本的转换。
2.3 pipeline参数
2.3.1 pipeline对象实例化参数
- model(PreTrainedModel或TFPreTrainedModel)— 管道将使用其进行预测的模型。 对于 PyTorch,这需要从PreTrainedModel继承;对于 TensorFlow,这需要从
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3069
3069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









