






 本文详细探讨了Linux内存管理,包括用户空间与内核空间的区别、虚拟地址到物理地址的转换机制,以及四级页表映射在32位和64位系统中的应用。讲解了进程地址空间、mm_struct和内核空间布局,以及内存分配与地址映射的原理。
本文详细探讨了Linux内存管理,包括用户空间与内核空间的区别、虚拟地址到物理地址的转换机制,以及四级页表映射在32位和64位系统中的应用。讲解了进程地址空间、mm_struct和内核空间布局,以及内存分配与地址映射的原理。
linux内存管理(详解)
Linux内存管理-一口Linux
Linux用户空间与内核地址空间详解
Linux 内存相关问题汇总 与内存管理
一口气搞懂【Linux 内存管理】,就靠这 60 张图、59 个问题了
用户空间与内核空间
人间还是仙界?聊一聊linux系统的用户空间和内核空间
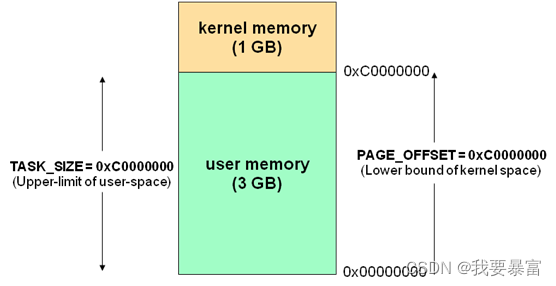
以32 位Linux系统为例,虚拟地址的大小是4GB (0x0000_0000 ~ 0xffff_ffff)。
Linux 用户空间和 内核空间的大小可以通过设置宏 PAGE_OFFSET 来配置,默认PAGE_OFFSET = 0xc000_0000。
当PAGE_OFFSET = 0xc000_0000 时用户空间为 0-3G,内核空间为3-4G。
Linux为什么要划分用户空间 和 内核空间?
① 处理器模式不同、权限不同
对于x86 体系的CPU,用户空间的代码运行在Ring3 模式,内核空间的代码运行在Ring0 模式;
对于 arm体系的CPU,用户空间的代码运行在usr 模式,内核空间的代码运行在svc 模式;
②安全考虑
内核空间主要用于内核,内核负责管理系统中的各种资源,CPU资源、内存资源和外设资源等等。
Linux是多用户、多进程的系统,用户进程访问这些资源是受限的,空间隔离可以保证系统内核的稳定性,即使一个用户进程奔溃,或是恶意的破坏也不会导致内核奔溃。
③软件设计思想
内核代码偏向于系统管理,用户空间代码偏向于业务逻辑实现,二者分工不同更利于管理。
应用进程地址空间
在Linux 中一个进程的空间大小就是4GB,0-3G 是用户空间,3-4G 是内核空间。
这3G 的虚拟空间就包含代码段、数据段、bss 段、堆栈等等。
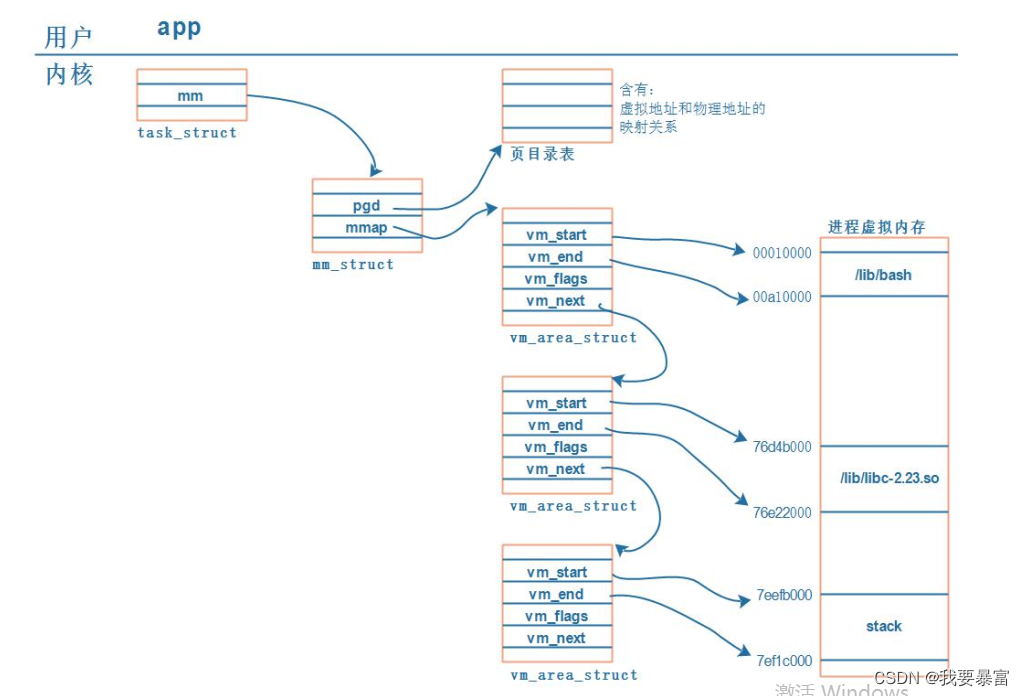
内核使用task_struct 来描述一个用户进程,每个进程都需要分配内存空间资源 用task_struct->mm_struct来描述一个进程的内存资源。
mm_struct->vm_area_struct 用来描述进程中各部分的虚拟地址空间(代码段、数据段等等);mm_struct->pgd 用来描述虚拟地址与物理地址之间的关系。
不同进程之间的内存资源是不可共享的,因为它们都有自己唯一的页表,mm_struct->pgd 表示一个进程的页目录表地址,通过页表就可以找到对应的内存物理地址。所以有时候发现不同进程使用相同的虚拟地址,依然能正常工作,这是因为它们页表中实际映射的物理地址不同。(因为如此不同进程之间通信要使用进程间通信)
其实并不是说一个进程真的拥有 4GB 的内存空间,内核对进程屏蔽了内存空间的管理,表面上给他画出4个G 的大饼,但是只有在进程真正访问一个内存地址的时候,内核才会将这个虚拟地址映射到实际存在的物理地址上。进程用到一点就给他分配一点,所以内核实际上是将物理内存东一块、西一块的分配给不同进程。
内核地址空间
linux内核1G虚拟地址空间的映射规则以及什么是高端内存?
内核中所有的线程,共享1GB 内核空间,因此内核中不同模块之间通信只需要全局变量即可。
用户进程也可以通过调用c库中的函数,执行系统调用产生0x80 号中断来陷入内核空间。
CPU 访问内存的过程
在程序中 CPU 使用的是虚拟地址,需要通过MMU 的转换得到物理地址,在总线上发出物理地址才能访问到内存。
MMU:地址映射单元,完成虚拟地址到物理地址转换的计算。
TLB:页表缓存,是一个高速ram。由于在地址换算过程中MMU 需要经常访问页表,那么如果把页表放在相对低速的内存中,那么转换效率将会变得低下。

页表映射
linux内核页表映射机制:线性地址如何转为物理地址?
二级页表映射:
以32位 系统为例虚拟地址的大小一共是4GB (0x0000_0000 ~ 0xffff_ffff)。
在程序中想要表达一个虚拟地址就是 用32位长度,比如0xffff_0011,要完成对内存上的数据的访问就要做到 虚拟地址–> 线性地址–> 物理地址的转换,物理地址才是真实存放数据的地址。
在Linux 内核中虚拟地址与线性地址的值是相等的。
下图是一个二级页表的结构图:
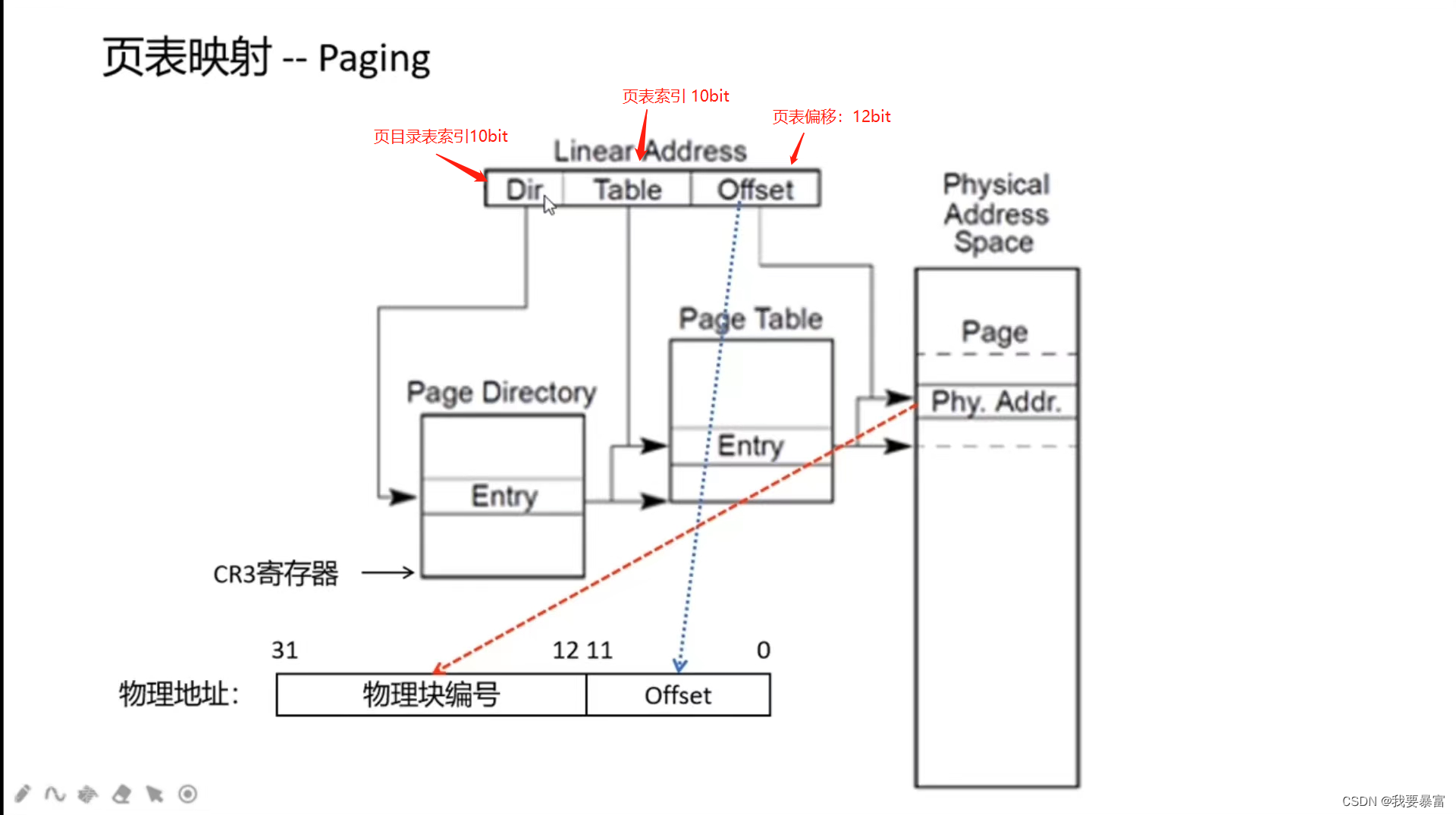
线性地址由页目录表索引、页表索引和页表偏移组成,一共32位。
Linux 将一个物理页大小设置为4KB,那么一个4GB 的物理内存就有 4GB / 4KB = 1024* 1024页;
页目录表(Page directory)用来存放页表地址,每一个地址条目的大小4 byte,一个页目录表一个共可以描述1024个页表;
页表(page Table)用来描述一个物理页的基地址,每一个条目需要大小为4 bype,一个页表可以描述1024个页地址;
(1024项页表 x 1024条页地址 x 4KB(页大小) = 4GB )如此刚好能描述4GB 的地址大小。
虚拟地址到物理地址的转换过程(页表映射):
① 从寄存器CR3 得到页目录表基地址。
② 取出线性地址高 10位 作为页目录表索引,通过索引找到页目录表中对应的页表项,得到页表基地址。
③ 取出线性地址中间 10位 作为页表索引,通过页表索引找到页表中描述的物理页项,得到页基地址。
④ 取出线性地址低 12位 作为物理页中的偏移地址,页地址 + 偏移地址 = 物理地址。
每一个进程都有自己唯一的页表,Linux 内核使用mm_struct->pgd 来描述一个进程的页目录表地址,在切换进程时只需要将pgd 存入寄存器CR3 即可完成进程页表的切换。
应用进程或内核线程在使用 malloc 等函数申请内存时,内核分配的是虚拟地址,并没有直接进行映射。当cpu 访问分配的地址空间时,假如没有映射物理地址,会陷入一个缺页异常,进行地址映射。
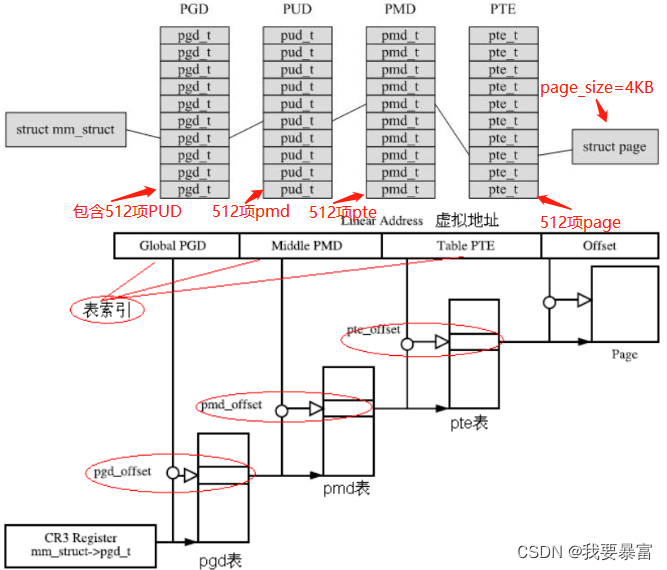
四级页表映射:
Linux 64位用户空间与内核空间布局:
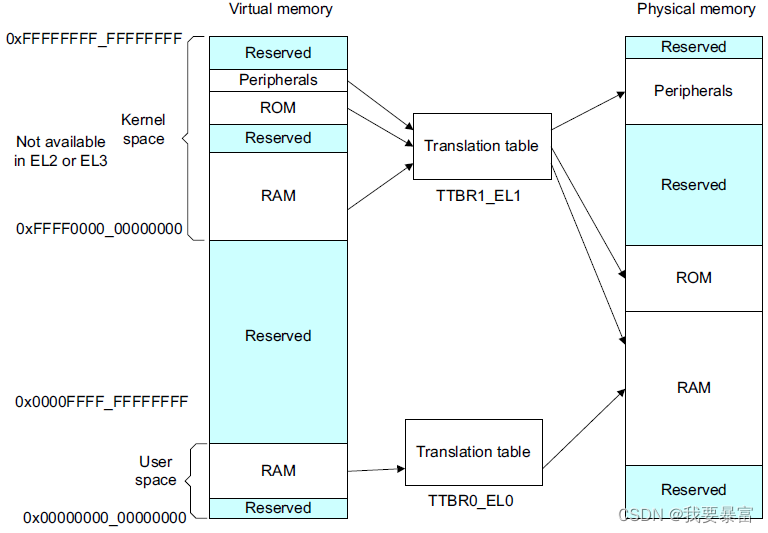
ARMv8 使用的是4级页表映射,4级页表映射参考
4级页表与2级页表的基本原理是一样的,只不过多了几层:全局页目录(pgd)、上级页目录(pud)、中间页目录(pmd)和页表(pte)。
页的大小还是相同的 4KB,但是多级页目录能描述的地址空间也就更广泛了。
一个pgd 一共能描述512项pud,一个pud 一功能描述512项pmd,一个pmd 一共能描述512项pte,一页大小4KB。
(512 x 512 x 512 x4KB = 256TB) 目前64位系统的寻址能力就是256TB。
使用参考链接中的测试代码可以查看ARMv8 的页表映射情况、和虚拟地址到物理地址的换算:
/*描述各级页表中的页表项*/
typedef struct { pteval_t pte; } pte_t;
typedef struct { pmdval_t pmd; } pmd_t;
typedef struct { pudval_t pud; } pud_t;
typedef struct { pgdval_t pgd; } pgd_t;
/* 将页表项类型转换成无符号类型 */
#define pte_val(x) ((x).pte)
#define pmd_val(x) ((x).pmd)
#define pud_val(x) ((x).pud)
#define pgd_val(x) ((x).pgd)
/* 将无符号类型转换成页表项类型 */
#define __pte(x) ((pte_t) { (x) } )
#define __pmd(x) ((pmd_t) { (x) } )
#define __pud(x) ((pud_t) { (x) } )
#define __pgd(x) ((pgd_t) { (x) } )
/* 获取页表项的索引值 */
#define pgd_index(addr) (((addr) >> PGDIR_SHIFT) & (PTRS_PER_PGD - 1))
#define pud_index(addr) (((addr) >> PUD_SHIFT) & (PTRS_PER_PUD - 1))
#define pmd_index(addr) (((addr) >> PMD_SHIFT) & (PTRS_PER_PMD - 1))
#define pte_index(addr) (((addr) >> PAGE_SHIFT) & (PTRS_PER_PTE - 1))
/* 获取页表中entry的偏移值 */
#define pgd_offset(mm, addr) (pgd_offset_raw((mm)->pgd, (addr)))
#define pgd_offset_k(addr) pgd_offset(&init_mm, addr)
#define pud_offset_phys(dir, addr) (pgd_page_paddr(*(dir)) + pud_index(addr) * sizeof(pud_t))
#define pud_offset(dir, addr) ((pud_t *)__va(pud_offset_phys((dir), (addr))))
#define pmd_offset_phys(dir, addr) (pud_page_paddr(*(dir)) + pmd_index(addr) * sizeof(pmd_t))
#define pmd_offset(dir, addr) ((pmd_t *)__va(pmd_offset_phys((dir), (addr))))
#define pte_offset_phys(dir,addr) (pmd_page_paddr(READ_ONCE(*(dir))) + pte_index(addr) * sizeof(pte_t))
#define pte_offset_kernel(dir,addr) ((pte_t *)__va(pte_offset_phys((dir), (addr))))
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/init.h>
#include <linux/sched.h>
#include <linux/pid.h>
#include <linux/mm.h>
#include <asm/pgtable.h>
#include <asm/page.h>
MODULE_DESCRIPTION("vitual address to physics address");
static int pid;
static unsigned long va;
module_param(pid,int,0644); //从命令行传递参数(变量,类型,权限)
module_param(va,ulong,0644); //va表示的是虚拟地址
static int find_pgd_init(void)
{
unsigned long pa = 0; //pa表示的物理地址
struct task_struct *pcb_tmp = NULL;
pgd_t *pgd_tmp = NULL;
pud_t *pud_tmp = NULL;
pmd_t *pmd_tmp = NULL;
pte_t *pte_tmp = NULL;
printk(KERN_INFO"PAGE_OFFSET = 0x%lx\n",PAGE_OFFSET); //页表中有多少个项
/*pud和pmd等等 在线性地址中占据多少位*/
printk(KERN_INFO"PGDIR_SHIFT = %d\n",PGDIR_SHIFT);
//注意:在32位系统中 PGD和PUD是相同的
printk(KERN_INFO"PUD_SHIFT = %d\n",PUD_SHIFT);
printk(KERN_INFO"PMD_SHIFT = %d\n",PMD_SHIFT);
printk(KERN_INFO"PAGE_SHIFT = %d\n",PAGE_SHIFT);
printk(KERN_INFO"PTRS_PER_PGD = %d\n",PTRS_PER_PGD); //每个PGD里面有多少个ptrs
printk(KERN_INFO"PTRS_PER_PUD = %d\n",PTRS_PER_PUD);
printk(KERN_INFO"PTRS_PER_PMD = %d\n",PTRS_PER_PMD); //PMD中有多少个项
printk(KERN_INFO"PTRS_PER_PTE = %d\n",PTRS_PER_PTE);
printk(KERN_INFO"PAGE_MASK = 0x%lx\n",PAGE_MASK); //页的掩码
struct pid *p = NULL;
p = find_vpid(pid); //通过进程的pid号数字找到struct pid的结构体
pcb_tmp = pid_task(p,PIDTYPE_PID); //通过pid的结构体找到进程的task struct
printk(KERN_INFO"pgd = 0x%p\n",pcb_tmp->mm->pgd);
// 判断给出的地址va是否合法(va<vm_end)
if(!find_vma(pcb_tmp->mm,va)){
printk(KERN_INFO"virt_addr 0x%lx not available.\n",va);
return 0;
}
pgd_tmp = pgd_offset(pcb_tmp->mm,va); //返回线性地址va,在页全局目录中对应表项的线性地址
printk(KERN_INFO"pgd_tmp = 0x%p\n",pgd_tmp);
//pgd_val获得pgd_tmp所指的页全局目录项
//pgd_val是将pgd_tmp中的值打印出来
printk(KERN_INFO"pgd_val(*pgd_tmp) = 0x%lx\n",pgd_val(*pgd_tmp));
if(pgd_none(*pgd_tmp)){ //判断pgd有没有映射
printk(KERN_INFO"Not mapped in pgd.\n");
return 0;
}
pud_tmp = pud_offset(pgd_tmp,va); //返回va对应的页上级目录项的线性地址
printk(KERN_INFO"pud_tmp = 0x%p\n",pud_tmp);
printk(KERN_INFO"pud_val(*pud_tmp) = 0x%lx\n",pud_val(*pud_tmp));
if(pud_none(*pud_tmp)){
printk(KERN_INFO"Not mapped in pud.\n");
return 0;
}
pmd_tmp = pmd_offset(pud_tmp,va); //返回va在页中间目录中对应表项的线性地址
printk(KERN_INFO"pmd_tmp = 0x%p\n",pmd_tmp);
printk(KERN_INFO"pmd_val(*pmd_tmp) = 0x%lx\n",pmd_val(*pmd_tmp));
if(pmd_none(*pmd_tmp)){
printk(KERN_INFO"Not mapped in pmd.\n");
return 0;
}
//在这里,把原来的pte_offset_map()改成了pte_offset_kernel
pte_tmp = pte_offset_kernel(pmd_tmp,va); //pte指的是 找到表
printk(KERN_INFO"pte_tmp = 0x%p\n",pte_tmp);
printk(KERN_INFO"pte_val(*pte_tmp) = 0x%lx\n",pte_val(*pte_tmp));
if(pte_none(*pte_tmp)){ //判断有没有映射
printk(KERN_INFO"Not mapped in pte.\n");
return 0;
}
if(!pte_present(*pte_tmp)){
printk(KERN_INFO"pte not in RAM.\n");
return 0;
}
pa = (pte_val(*pte_tmp) & PAGE_MASK) ;//物理地址的计算方法
printk(KERN_INFO"virt_addr 0x%lx in RAM Page is 0x%lx .\n",va,pa);
//printk(KERN_INFO"contect in 0x%lx is 0x%lx\n",pa,*(unsigned long *)((char *)pa + PAGE_OFFSET));
return 0;
}
static void __exit find_pgd_exit(void)
{
printk(KERN_INFO"Goodbye!\n");
}
module_init(find_pgd_init);
module_exit(find_pgd_exit);
MODULE_LICENSE("GPL");
下图是进程hello 中变量a 地址的虚拟地址->物理地址转换。

ARMv8 对pgd_t、pud_t、pmd_t、pte_t 等类型定义在:arch\arm64\include\asm\pgtable-types.h (不同架构定义不同)
Linux 内存管理机制
物理内存管理之 node、zone 和page
目前计算机系统有两种体系结构:一致性内存访问 UMA 和非一致性内存访问 NUMA。
一致性内存访问 UMA(Uniform Memory Access)也可以称为SMP(Symmetric Multi-Process)对称多处理器。意思是所有的处理器访问内存花费的时间是一样的。也可以理解整个内存只有一个node。
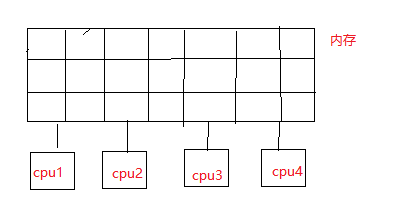
非一致性内存访问 NUMA(Non-Uniform Memory Access)意思是内存被划分为各个node,访问一个node花费的时间取决于CPU离这个node的距离。每一个cpu内部有一个本地的node,访问本地node时间比访问其他node的速度快。
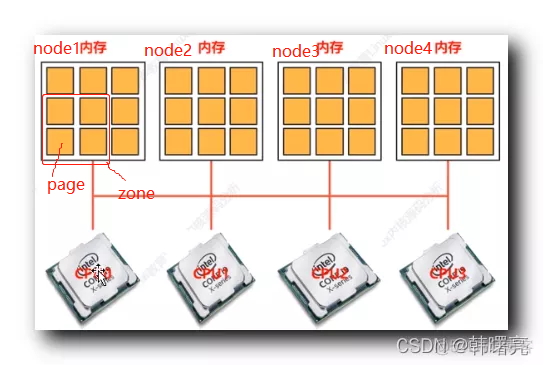
Linux 内核用 struct pglist_data描述一个node,用struct page 来描述一个物理内存的最小单位(一页,4KB) 。由于页的描述太小,node的描述太大,于是内核又将一个node中 相同目的的page 用一个struct zone 来描述。
内核源码中 struct pglist_data 定义在include/linux/mmzone.h
比较重要的成员如下:
node 是由多个zone 组成的。
//include/linux/mmzone.h
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES]; //保存着node 中所有的zone
......
unsigned long node_start_pfn; //该node 所描述的物理内存起始地址
unsigned long node_present_pages; /* total number of physical pages. 该node 包含物理页的总数*/
unsigned long node_spanned_pages; /* total size of physical page range, including holes. 所有物理页的大小的总和,包含空洞 */
} pg_data_t;
zone 由多个page 组成。
struct zone {
unsigned long zone_start_pfn; //zone 起始的物理页号
atomic_long_t managed_pages; //zone中 被伙伴系统所管理的page 数量
unsigned long spanned_pages; //一个zone 中page的数量
unsigned long present_pages; //存在的page ,等于spanned_pages - 空洞的page
}
page 是内存管理中,物理内存的最基本单位,即一页,大小为4KB。
//include/linux/mm_types.h
struct page {
unsigned long flags; /* Atomic flags, some possibly
* updated asynchronously */
//标志page 的flag,/proc/meminfo 中也是根据此flag 信息来分类
union {
struct { /* Page cache and anonymous pages */
/**
* @lru: Pageout list, eg. active_list protected by
* pgdat->lru_lock. Sometimes used as a generic list
* by the page owner.
*/
struct list_head lru;
//指向一个lru 链表,根据一个page 的使用活跃度来将page 挂入active 链表或inactive 链表,这决定了该page映设的物理内存是否可回收
/* See page-flags.h for PAGE_MAPPING_FLAGS */
struct address_space *mapping;
/*
mapping:用来指向inode 对应的address_space;
内核用address_space 来管理一个文件所有的缓存页。
在Linux系统中打开一个文件的时候,内核会将文件的数据读入到内存中,这些数据在内存上就是存在一个一个page 中。
最新版本的内核中已经不用address_space 来管理文件page。
*/
pgoff_t index; /* Our offset within mapping. */
/**
* @private: Mapping-private opaque data.
* Usually used for buffer_heads if PagePrivate.
* Used for swp_entry_t if PageSwapCache.
* Indicates order in the buddy system if PageBuddy.
*/
unsigned long private;
}
......
}


















 851
851

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









