







 本文深入解析了C语言中数组的内存分配与访问,包括不同类型数组的地址计算,以及结构体和联合体的内存组织。重点介绍了缓冲区溢出问题及其预防措施,如栈随机化、栈保护机制和代码区域限制。
本文深入解析了C语言中数组的内存分配与访问,包括不同类型数组的地址计算,以及结构体和联合体的内存组织。重点介绍了缓冲区溢出问题及其预防措施,如栈随机化、栈保护机制和代码区域限制。
一、数组的分配与访问
首先看几个数组的例子,数组A 是由8 个char 类型的元素组成,每个元素的大小是一个字节。假设数组A 的起始地址是Xa,那么数组元素A[i] 的地址就是Xa+i。
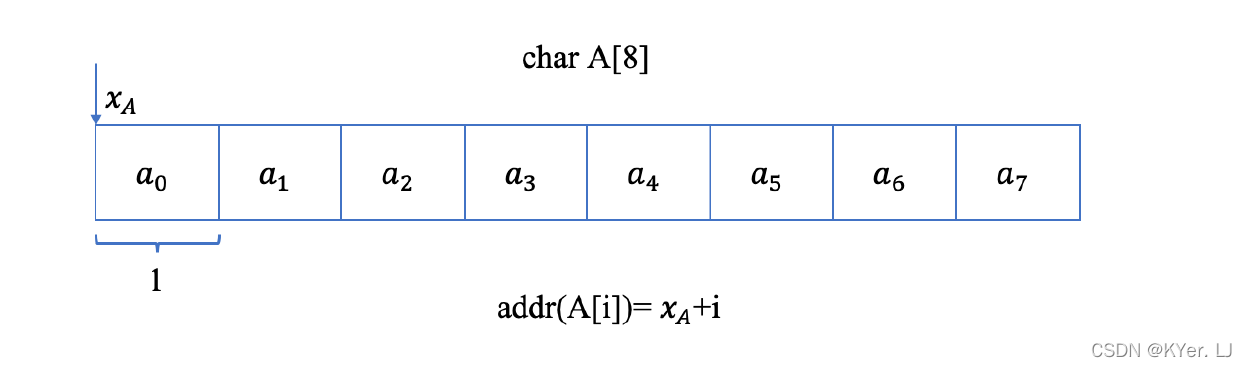
我们再来看一个int 类型的数组,数组B 是由4 个整数组成,每个元素占4 个字节,因此数组B 总的大小为16 个字节。假设数组B 的起始地址是Xb,那么数组元素B[i] 的地址就是Xb+4i。
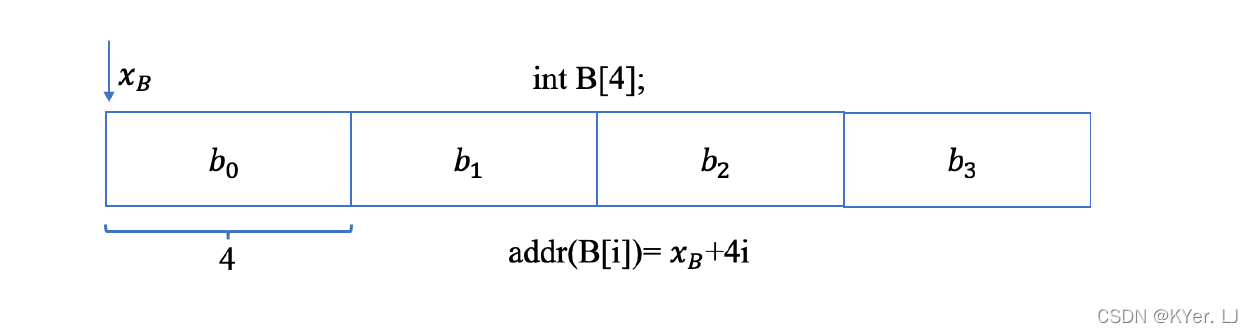
在C 语言中,允许对指针进行运算,例如,我们声明了一个指向char 类型的指针p,和一个指向int 类型的指针q。为了方便理解,我们还是把内存抽象成一个大的数组。假设指针p 和指针q 都指向0x100(内存地址)处。
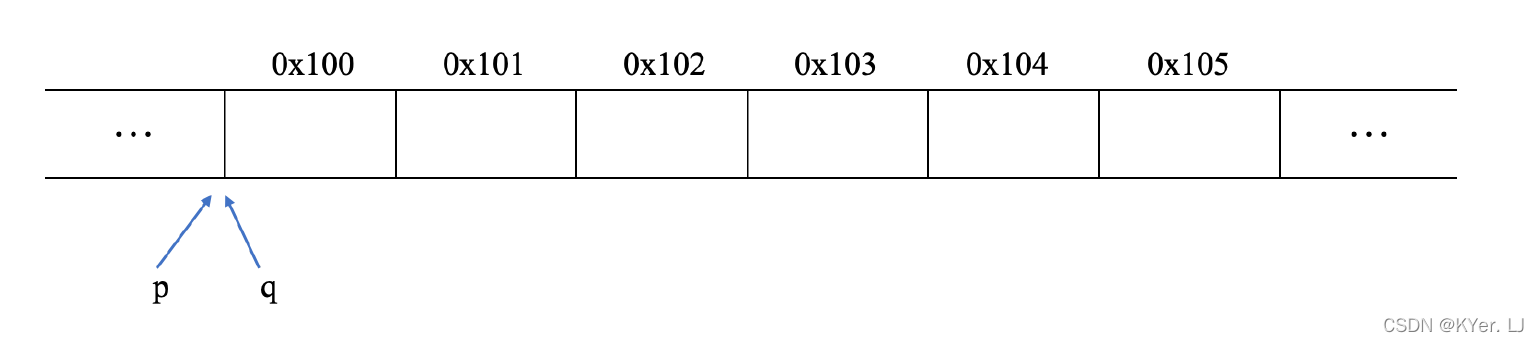
现在分别对指针p 和指针q 进行加一的操作,指针p 加1 指向0x101 处,而指针q加1 后指向0x104 处。
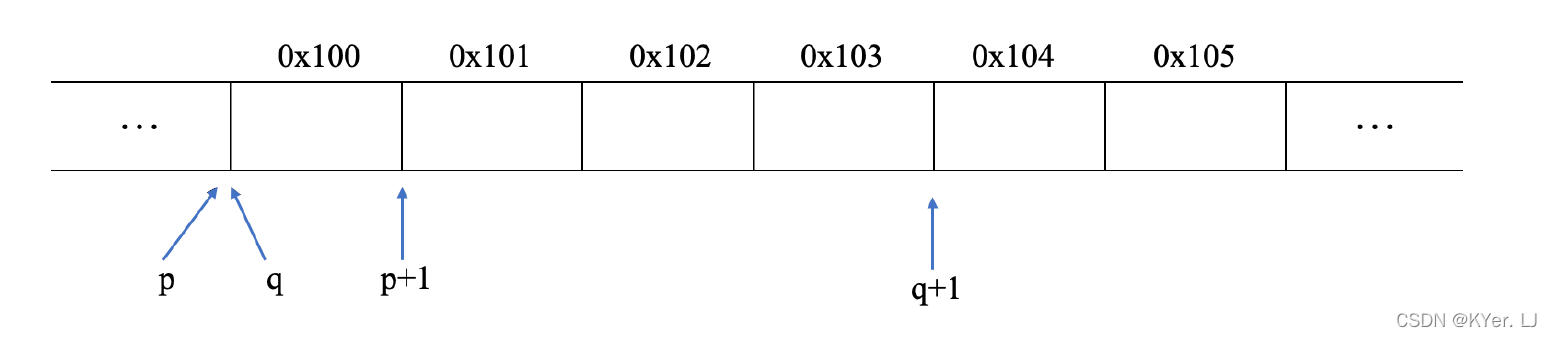
虽然都是对指针进行加一的运算,但是得到的结果却不同。这是因为对指针进行运算时,计算结果会根据该指针引用的数据类型进行相应的伸缩。
接下来,我们看一个例子,我们定义了一个数组E,假设这个数组存放在内存中,对于数组的每一个元素都有两个属性,一个属性是它存储的内容,另外一个属性是它的存储地址,说白了就是它是啥,放在哪儿。对于元素的存储地址,可以通过取地址运算符来获得,具体如图所示。
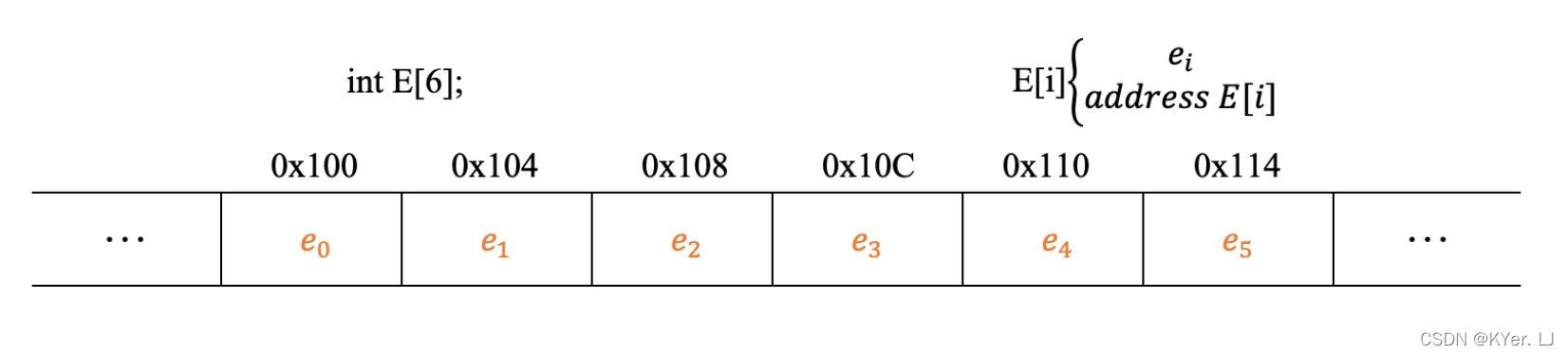
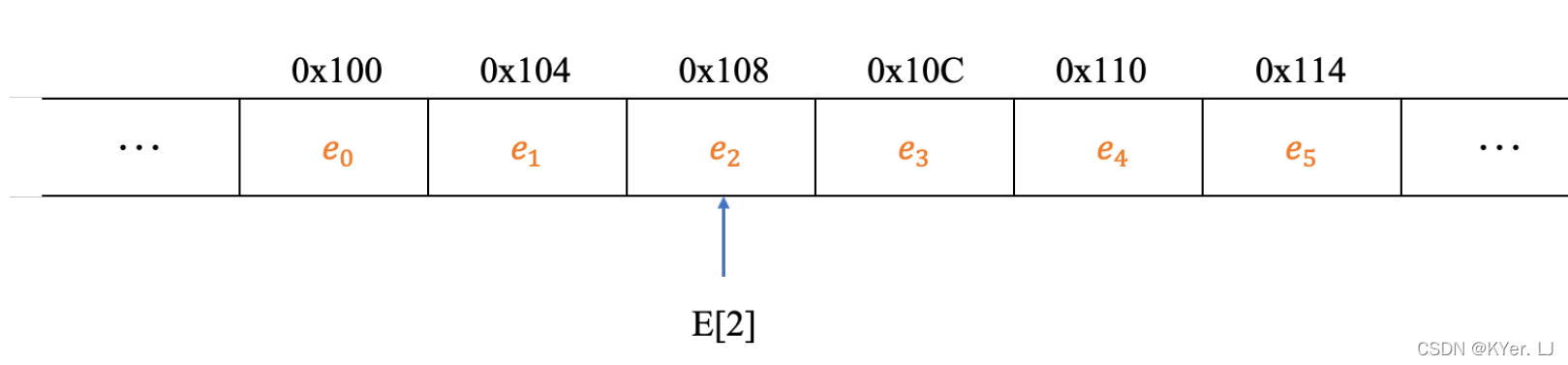
通常我们习惯使用数组引用的方式来访问数组中的元素,例如可以使用图中的表达式来访问数组中的元素。
除此之外,还有另外一种方式,具体如图所示,其中表达式E+2 表示数组第二个元素的存储地址,大写字母E 表示数组的起始地址(第0 个元素),此处加2 的操作与指针加2 的运算类似,也是与数据类型相关。
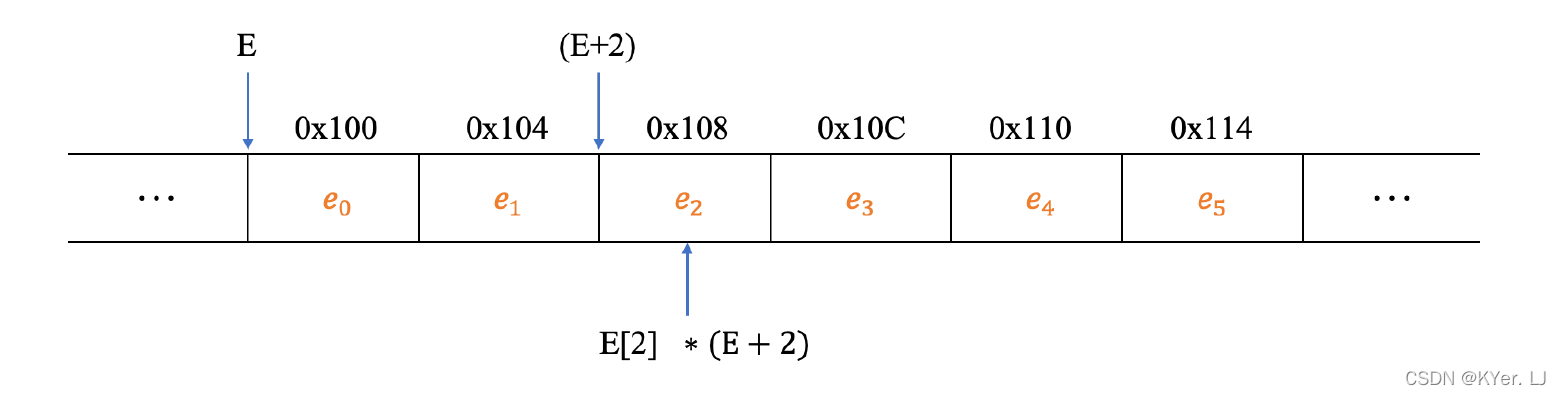
指针运算符* 可以理解成从该地址处取数据,指针是C 语言中最难理解的部分,我们理解了内存地址的概念之后,可以发现指针其实就是地址的抽象表述。
嵌套数组
嵌套数组也被称为二维数组,图中我们声明了一个数组A,数组A 可以被看成5 行3 列的二维数组,这种理解方式与矩阵的排列类似。在计算机系统中,我们通常把内存抽象为一个巨大的数组,对于二维数组在内存中是按照“行优先”的顺序进行存储的,基于这个规则,我们可以画出数组A 在内存中的存储情况。
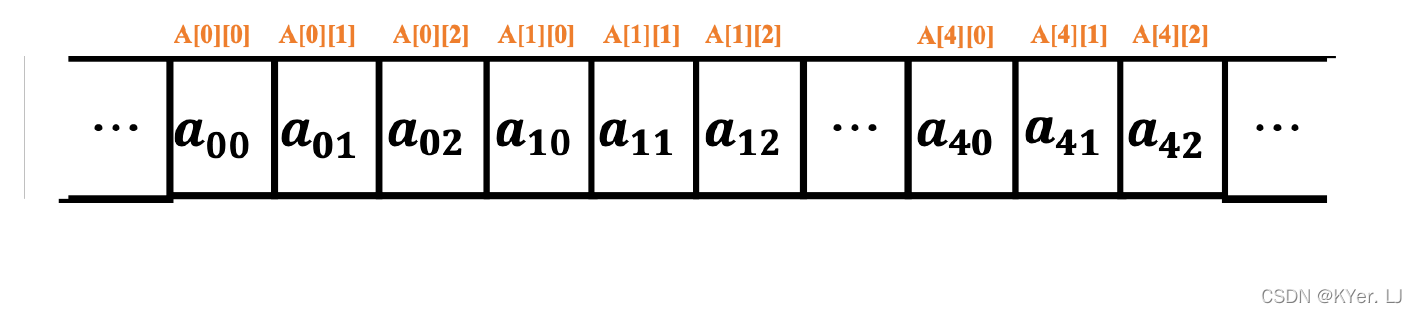
关于数组的理解,还有一种方式,就是可以把数组A 看成一个有5 个元素的数组,其中每个元素都是一个长度为3 的数组,这便是嵌套数组的理解方式。
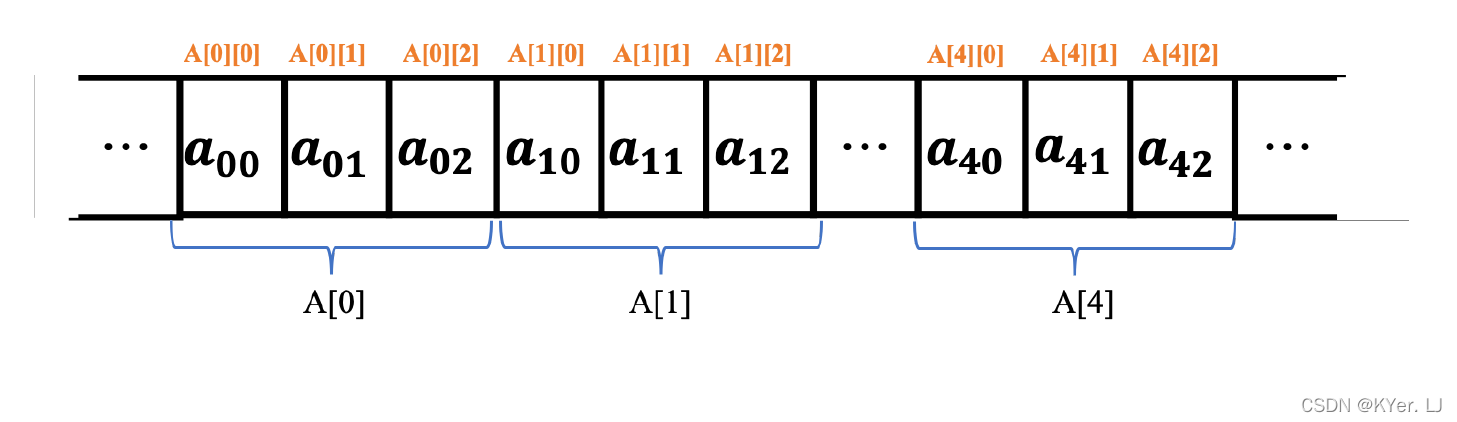
无论用何种方式来理解,数组元素在内存中的存储位置都是一样的。下面我们来看一下数组元素的地址是如何计算的,对于数组D 任意一个元素可以通过图中的计算公式来计算地址。
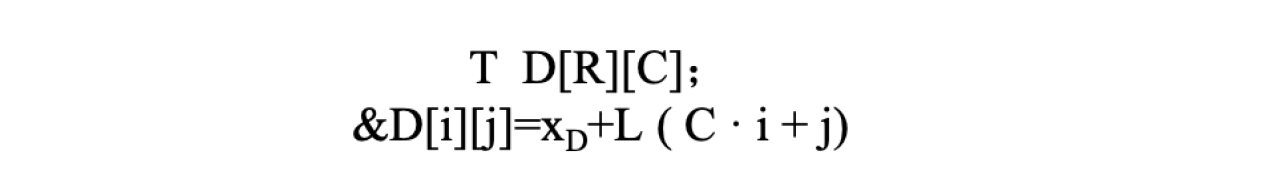
其中,XD 表示数组的起始地址;L 表示数据类型T 的大小,如果T 是int 类型,L就等于4,T 是char 类型,L 就等于1;在具体的示例中,C、i、j 都是常数。
根据图中的计算公式,对于5×3 的数组A,其任意元素的地址可以Xa+ 4*(3i+j))来计算。
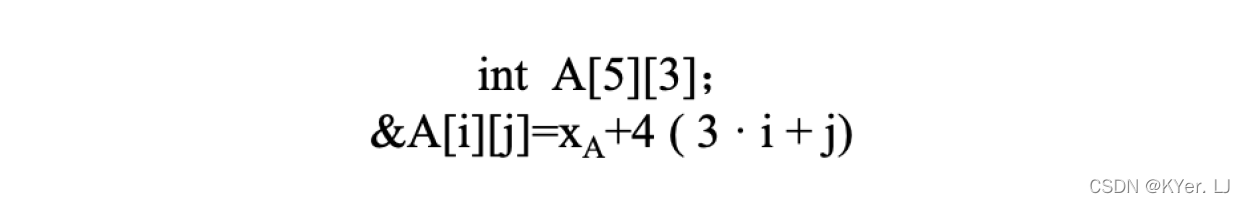
二、结构体与联合体
1 struct rec{
2 int i;
3 int j;
4 int a[2];
5 int *p;
6 }
这个结构体包含四个字段:两个int 类型的变量,个int 类型的数组和一个int 类型的指针。
我们可以画出各个字段相对于结构体起始地址处的字节偏移。

从这个图上可以看出数组a 的元素是嵌入到结构体中的。接下来,我们看一下如何访问结构体中的字段。
例如,我们声明一个结构体类型指针变量r,它指向结构体的起始地址。
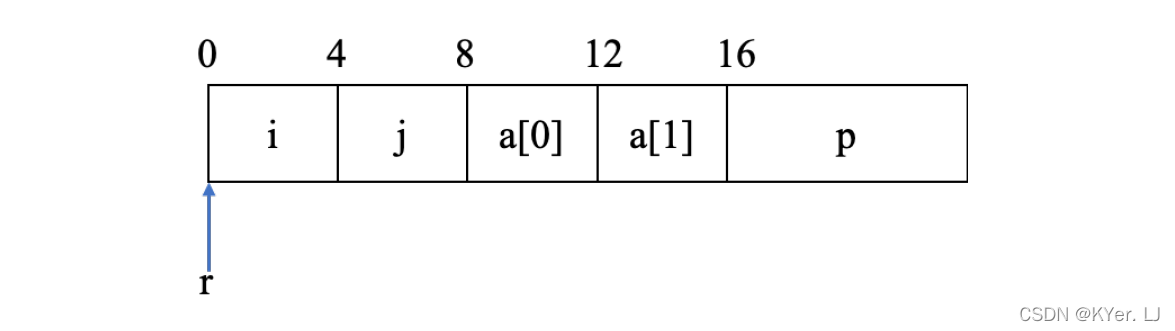
假设r 存放在寄存器rdi 中,可以使用下图的汇编指令将字段i 的值复制到字段j中。

• 首先读取字段i 的值,由于字段i 相对于结构体起始地址的偏移量为0,所以字段i 的地址就是r 的值,而字段j 的偏移量为4,因此需要将r 加上偏移量4。
• 其中结构体指针r 存放在寄存器rdi 中,数组元素的索引值i 存放在寄存器rsi中,最后地址的计算结果,存放在寄存器rax 中。
综上所述,无论是单个变量还是数组元素,都是通过起始地址加偏移量的方式来访问。
对于图中的结构体,它包含两个int 类型的变量和一个char 类型的变量。

根据前面的知识,我们会直观的认为该结构体占用9 个字节的存储空间,但是当使用sizeof 函数对该结构体的大小进行求值时,得到的结果却是12 个字节。原因是为了提高内存系统的性能,系统对于数据存储的合法地址做出了一些限制。
例如变量j 是int 类型,占4 个字节,它的起始地址必须是4 的倍数,因此,编译器会在变量c 和变量j 之间插入一个3 字节的间隙,这样变量j 相对于起始地址的偏移量就为8,整个结构体的大小就变成了12 个字节。
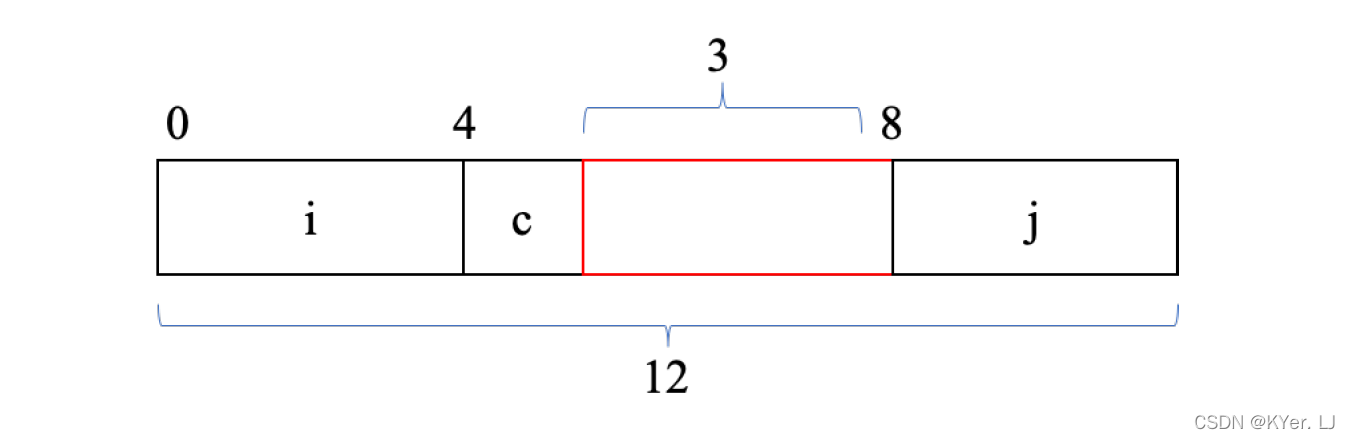
对于不同的数据类型,地址对齐的原则是任何K 字节的基本对象的地址必须是K的倍数。也就是说对于short 类型,起始地址必须是2 的倍数;对于占8 个字节的数据类型,起始地址必须是8 的倍数。

基于上表的规则,编译器可能需要在字段的地址空间分配时插入间隙,以此保证每个结构体的元素都满足对齐的要求。
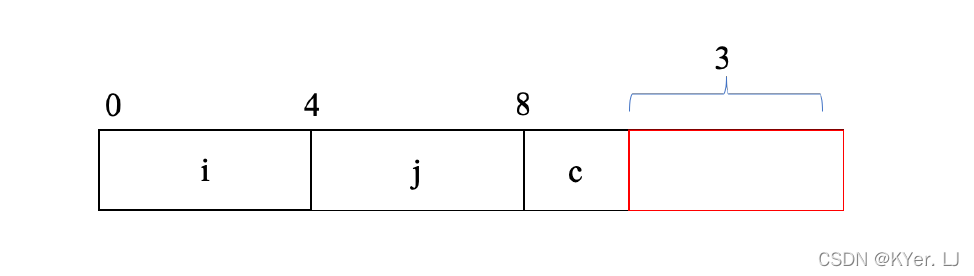
除此之外,结构体的末尾可能需要填充间隙,还是刚才的这个结构体,可以通过调整字段j 和字段c 的排列顺序,使得所有的字段都满足了数据对齐的要求。
但是当我们声明一个结构体数组时,分配9 个字节的存储空间,是无法满足所有数组元素的对齐要求,因此,编译器会在结构体的末端增加3 个字节的填充,这样一来,所有的对齐限制都满足了。
联合体
与结构体不同,联合体中的所有字段共享同一存储区域,因此联合体的大小取决于它最大字段的大小。
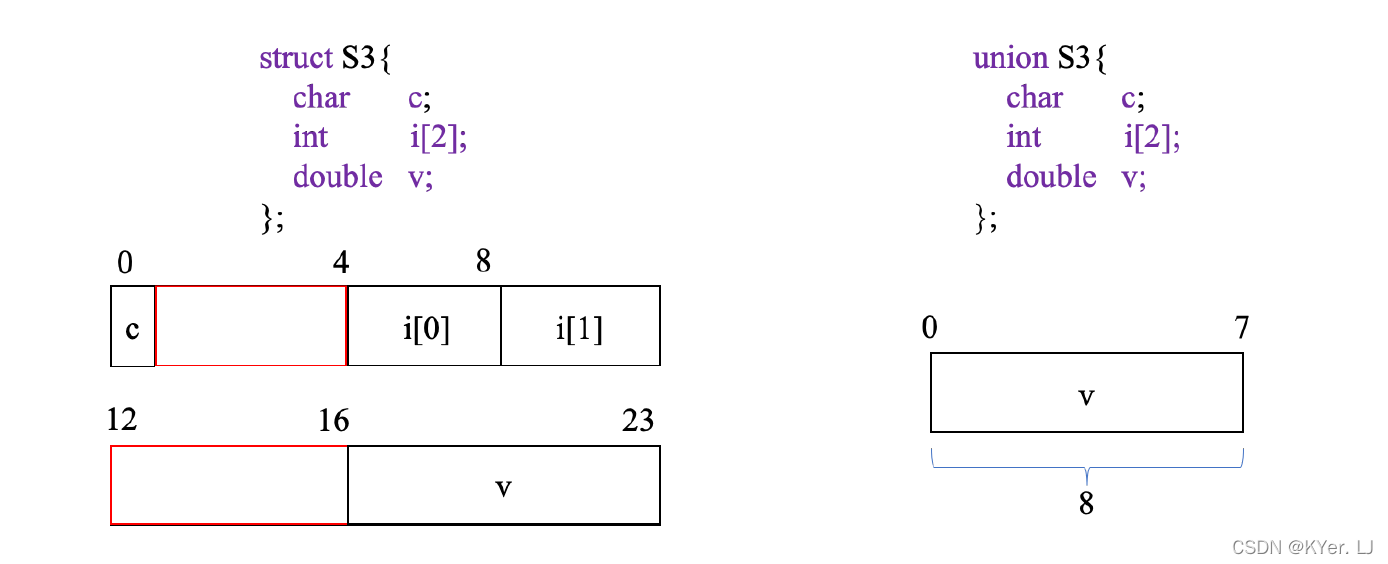
变量v 和数组i 的大小都是8 个字节,因此,这个联合体的占8 个字节的存储空间。
联合体的一种应用情况是:我们事先知道两个不同字段的使用是互斥的,那么我们可以将这两个字段声明为一个联合体。原理就是不会让不可能有数据的字段白白浪费内存。
例如,我们定义一个二叉树的数据结构,这个二叉树分为内部节点和叶子节点,其中每个内部节点不含数据,都有指向两个孩子节点的指针,每个叶子节点都有两个double 类型的数据值。
我们可以用结构体来定义该二叉树的节点。
1 struct node_s{
2 struct node_s *left;
3 struct node_s *right;
4 double data [2];
5 };
那么每个节点需要32 个字节,由于该二叉树的特殊性,我们事先知道该二叉树的任意一个节点不是内部节点就是叶子节点,因此,我们可以用联合体来定义节点.
1 union node_u{
2 struct{
3 union node_s *left;
4 union node_s *right;
5 }internal;
6 double data [2];
7 };
这样,每个节点只需要16 个字节的存储空间,相对于结构体的定义方式,可以节省一半的空间。不过,这种编码方式存在一个问题,就是没有办法来确定一个节点到底是叶子节点还是内部节点,通常的解决方法是引入一个枚举类型,然后创建一个
结构体,它包含一个标签和一个联合体
三、缓冲区溢出
我们通过一个代码示例看一下什么是缓冲区溢出。
1 void echo(){
2 char buf [8];
3 gets(buf);
4 puts(buf);
5 }
数据对齐
实际上当输入字符串的长度不超过23 时,不会发生严重的后果,超过以后,返回地址以及更多的状态信息会被破坏,那么返回指令会导致程序跳转到一个完全意想不到的地方。
历史上许多计算机病毒就是利用缓冲区溢出的方式对计算机系统进行攻击的,针对缓冲区溢出的攻击,现在编译器和操作系统实现了很多机制,来限制入侵者通过这种攻击方式来获得系统控制权。
例如栈随机化、栈破坏检测以及限制可执行代码区域等。
1、栈随机化
1 int main(){
2 long local;
3 printf(” l o c a l at %p\n”, &local);
4 return 0;
5 }
在过去,程序的栈地址非常容易预测,如果一个攻击者可以确定一个web 服务器所使用的栈空间,那就可以设计一个病毒程序来攻击多台机器,栈随机化的思想是栈的位置在程序每次运行时都有变化,上面这段代码只是简单的打印main 函数中局部变量local 的地址,每次运行打印结果都可能不同。
在64 位linux 系统上,地址的范围:0x7fff0001b698 0x7ffffffaa4a8。因此,采用了栈随机化的机制,即使许多机器都运行相同的代码,它们的栈地址也是不同的。
在linux 系统中,栈随机化已经成为标准行为,它属于地址空间布局随机化的一种,简称ASLR,采用ASLR,每次运行时程序的不同部分都会被加载到内存的不同区域,这类技术的应用增加了系统的安全性,降低了病毒的传播速度。
2、栈破坏检测
编译器会在产生的汇编代码中加入一种栈保护者的机制来检测缓冲区越界,就是在缓冲区与栈保存的状态值之间存储一个特殊值,这个特殊值被称作金丝雀值,之所以叫这个名字,是因为从前煤矿工人会根据金丝雀的叫声来判断煤矿中有毒气体的含量。

金丝雀值是每次程序运行时随机产生的,因此攻击者想要知道这个金丝雀值具体是什么并不容易,在函数返回之前,检测金丝雀值是否被修改来判断是否遭受攻击。
函数返回之前,我们通过指令xor 来检查金丝雀值是否被更改。如果金丝雀值被更改,那么程序就会调用一个错误处理例程,如果没有被更改,程序就正常执行。
3、限制可执行代码区域
最后一种机制是消除攻击者向系统中插入可执行代码的能力,其中一种方法是限制哪些内存区域能够存放可执行代码。
以前,x86 的处理器将可读和可执行的访问控制合并成一位标志,所以可读的内存页也都是可执行的,由于栈上的数据需要被读写,因此栈上的数据也是可执行的。
虽然实现了一些机制能够限制一些页可读且不可执行,但是这些机制通常会带来严重的性能损失,后来,处理器的内存保护引入了不可执行位,将读和可执行访问模式分开了。有了这个特性,栈可以被标记为可读和可写,但是不可执行。检查页是否可执行由硬件来完成,效率上没有损失。
以上这三种机制,都不需要程序员做任何额外的工作,都是通过编译器和操作系统来实现的,单独每一种机制都能降低漏洞的等级,组合起来使用会更加有效。
不幸的是,仍然有方法能够对计算机进行攻击。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









