







继续接上一篇,从04_lw到05_riscvtests目录。对比一下两个目录下的文件如下:

其中主要的改动是Core.scala。这个改动不再是+1的小改动,而是从Load/Store共2个指令扩展为一整套RISC-V指令集(30多个指令)的实现,其中当然继续包括Load/Store指令,还包括了加减乘除算术运算、左移右移等位运算、条件判断跳转的控制,可以想见这三类指令的实现几乎就是一个完备的计算机了,不管多高级的语言编写的多复杂的程序,最后落地到计算机硬件上大体应该就是算术移位和条件跳转了。
这里不再详细比较04和05的Core.scala差异,而是列出05_riscvtests目录下的Core.scala文件进行分析:
package riscvtests
import chisel3._
import chisel3.util._
import common.Instructions._
import common.Consts._
class Core extends Module {
val io = IO(
new Bundle {
val imem = Flipped(new ImemPortIo())
val dmem = Flipped(new DmemPortIo())
val exit = Output(Bool())
val gp = Output(UInt(WORD_LEN.W))
}
)
val regfile = Mem(32, UInt(WORD_LEN.W))
val csr_regfile = Mem(4096, UInt(WORD_LEN.W))
//**********************************
// Instruction Fetch (IF) Stage
val pc_reg = RegInit(START_ADDR)
io.imem.addr := pc_reg
val inst = io.imem.inst
val pc_plus4 = pc_reg + 4.U(WORD_LEN.W)
val br_target = Wire(UInt(WORD_LEN.W))
val br_flg = Wire(Bool())
val jmp_flg = (inst === JAL || inst === JALR)
val alu_out = Wire(UInt(WORD_LEN.W))
val pc_next = MuxCase(pc_plus4, Seq(
br_flg -> br_target,
jmp_flg -> alu_out,
(inst === ECALL) -> csr_regfile(0x305) // go to trap_vector
))
pc_reg := pc_next
//**********************************
// Instruction Decode (ID) Stage
val rs1_addr = inst(19, 15)
val rs2_addr = inst(24, 20)
val wb_addr = inst(11, 7)
val rs1_data = Mux((rs1_addr =/= 0.U(WORD_LEN.U)), regfile(rs1_addr), 0.U(WORD_LEN.W))
val rs2_data = Mux((rs2_addr =/= 0.U(WORD_LEN.U)), regfile(rs2_addr), 0.U(WORD_LEN.W))
val imm_i = inst(31, 20)
val imm_i_sext = Cat(Fill(20, imm_i(11)), imm_i)
val imm_s = Cat(inst(31, 25), inst(11, 7))
val imm_s_sext = Cat(Fill(20, imm_s(11)), imm_s)
val imm_b = Cat(inst(31), inst(7), inst(30, 25), inst(11, 8))
val imm_b_sext = Cat(Fill(19, imm_b(11)), imm_b, 0.U(1.U))
val imm_j = Cat(inst(31), inst(19, 12), inst(20), inst(30, 21))
val imm_j_sext = Cat(Fill(11, imm_j(19)), imm_j, 0.U(1.U))
val imm_u = inst(31,12)
val imm_u_shifted = Cat(imm_u, Fill(12, 0.U))
val imm_z = inst(19,15)
val imm_z_uext = Cat(Fill(27, 0.U), imm_z)
val csignals = ListLookup(inst,
List(ALU_X , OP1_RS1, OP2_RS2, MEN_X, REN_X, WB_X , CSR_X),
Array(
LW -> List(ALU_ADD , OP1_RS1, OP2_IMI, MEN_X, REN_S, WB_MEM, CSR_X),
SW -> List(ALU_ADD , OP1_RS1, OP2_IMS, MEN_S, REN_X, WB_X , CSR_X),
ADD -> List(ALU_ADD , OP1_RS1, OP2_RS2, MEN_X, REN_S, WB_ALU, CSR_X),
ADDI -> List(ALU_ADD , OP1_RS1, OP2_IMI, MEN_X, REN_S, WB_ALU, CSR_X),
SUB -> List(ALU_SUB , OP1_RS1, OP2_RS2, MEN_X, REN_S, WB_ALU, CSR_X),
AND -> List(ALU_AND , OP1_RS1, OP2_RS2, MEN_X, REN_S, WB_ALU, CSR_X),
OR -> List(ALU_OR , OP1_RS1, OP2_RS2, MEN_X, REN_S, WB_ALU, CSR_X),
XOR -> List(ALU_XOR , OP1_RS1, OP2_RS2, MEN_X, REN_S, WB_ALU, CSR_X),
ANDI -> List(ALU_AND , OP1_RS1, OP2_IMI, MEN_X, REN_S, WB_ALU, CSR_X),
ORI -> List(ALU_OR , OP1_RS1, OP2_IMI, MEN_X, REN_S, WB_ALU, CSR_X),
XORI -> List(ALU_XOR , OP1_RS1, OP2_IMI, MEN_X, REN_S, WB_ALU, CSR_X),
SLL -> List(ALU_SLL , OP1_RS1, OP2_RS2, MEN_X, REN_S, WB_ALU, CSR_X),
SRL -> List(ALU_SRL , OP1_RS1, OP2_RS2, MEN_X, REN_S, WB_ALU, CSR_X),
SRA -> List(ALU_SRA , OP1_RS1, OP2_RS2, MEN_X, REN_S, WB_ALU, CSR_X),
SLLI -> List(ALU_SLL , OP1_RS1, OP2_IMI, MEN_X, REN_S, WB_ALU, CSR_X),
SRLI -> List(ALU_SRL , OP1_RS1, OP2_IMI, MEN_X, REN_S, WB_ALU, CSR_X),
SRAI -> List(ALU_SRA , OP1_RS1, OP2_IMI, MEN_X, REN_S, WB_ALU, CSR_X),
SLT -> List(ALU_SLT , OP1_RS1, OP2_RS2, MEN_X, REN_S, WB_ALU, CSR_X),
SLTU -> List(ALU_SLTU , OP1_RS1, OP2_RS2, MEN_X, REN_S, WB_ALU, CSR_X),
SLTI -> List(ALU_SLT , OP1_RS1, OP2_IMI, MEN_X, REN_S, WB_ALU, CSR_X),
SLTIU -> List(ALU_SLTU , OP1_RS1, OP2_IMI, MEN_X, REN_S, WB_ALU, CSR_X),
BEQ -> List(BR_BEQ , OP1_RS1, OP2_RS2, MEN_X, REN_X, WB_X , CSR_X),
BNE -> List(BR_BNE , OP1_RS1, OP2_RS2, MEN_X, REN_X, WB_X , CSR_X),
BGE -> List(BR_BGE , OP1_RS1, OP2_RS2, MEN_X, REN_X, WB_X , CSR_X),
BGEU -> List(BR_BGEU , OP1_RS1, OP2_RS2, MEN_X, REN_X, WB_X , CSR_X),
BLT -> List(BR_BLT , OP1_RS1, OP2_RS2, MEN_X, REN_X, WB_X , CSR_X),
BLTU -> List(BR_BLTU , OP1_RS1, OP2_RS2, MEN_X, REN_X, WB_X , CSR_X),
JAL -> List(ALU_ADD , OP1_PC , OP2_IMJ, MEN_X, REN_S, WB_PC , CSR_X),
JALR -> List(ALU_JALR , OP1_RS1, OP2_IMI, MEN_X, REN_S, WB_PC , CSR_X),
LUI -> List(ALU_ADD , OP1_X , OP2_IMU, MEN_X, REN_S, WB_ALU, CSR_X),
AUIPC -> List(ALU_ADD , OP1_PC , OP2_IMU, MEN_X, REN_S, WB_ALU, CSR_X),
CSRRW -> List(ALU_COPY1, OP1_RS1, OP2_X , MEN_X, REN_S, WB_CSR, CSR_W),
CSRRWI-> List(ALU_COPY1, OP1_IMZ, OP2_X , MEN_X, REN_S, WB_CSR, CSR_W),
CSRRS -> List(ALU_COPY1, OP1_RS1, OP2_X , MEN_X, REN_S, WB_CSR, CSR_S),
CSRRSI-> List(ALU_COPY1, OP1_IMZ, OP2_X , MEN_X, REN_S, WB_CSR, CSR_S),
CSRRC -> List(ALU_COPY1, OP1_RS1, OP2_X , MEN_X, REN_S, WB_CSR, CSR_C),
CSRRCI-> List(ALU_COPY1, OP1_IMZ, OP2_X , MEN_X, REN_S, WB_CSR, CSR_C),
ECALL -> List(ALU_X , OP1_X , OP2_X , MEN_X, REN_X, WB_X , CSR_E)
)
)
val exe_fun :: op1_sel :: op2_sel :: mem_wen :: rf_wen :: wb_sel :: csr_cmd :: Nil = csignals
val op1_data = MuxCase(0.U(WORD_LEN.W), Seq(
(op1_sel === OP1_RS1) -> rs1_data,
(op1_sel === OP1_PC) -> pc_reg,
(op1_sel === OP1_IMZ) -> imm_z_uext
))
val op2_data = MuxCase(0.U(WORD_LEN.W), Seq(
(op2_sel === OP2_RS2) -> rs2_data,
(op2_sel === OP2_IMI) -> imm_i_sext,
(op2_sel === OP2_IMS) -> imm_s_sext,
(op2_sel === OP2_IMJ) -> imm_j_sext,
(op2_sel === OP2_IMU) -> imm_u_shifted
))
//**********************************
// Execute (EX) Stage
alu_out := MuxCase(0.U(WORD_LEN.W), Seq(
(exe_fun === ALU_ADD) -> (op1_data + op2_data),
(exe_fun === ALU_SUB) -> (op1_data - op2_data),
(exe_fun === ALU_AND) -> (op1_data & op2_data),
(exe_fun === ALU_OR) -> (op1_data | op2_data),
(exe_fun === ALU_XOR) -> (op1_data ^ op2_data),
(exe_fun === ALU_SLL) -> (op1_data << op2_data(4, 0))(31, 0),
(exe_fun === ALU_SRL) -> (op1_data >> op2_data(4, 0)).asUInt,
(exe_fun === ALU_SRA) -> (op1_data.asSInt >> op2_data(4, 0)).asUInt,
(exe_fun === ALU_SLT) -> (op1_data.asSInt < op2_data.asSInt).asUInt,
(exe_fun === ALU_SLTU) -> (op1_data < op2_data).asUInt,
(exe_fun === ALU_JALR) -> ((op1_data + op2_data) & ~1.U(WORD_LEN.W)),
(exe_fun === ALU_COPY1) -> op1_data
))
// branch
br_target := pc_reg + imm_b_sext
br_flg := MuxCase(false.B, Seq(
(exe_fun === BR_BEQ) -> (op1_data === op2_data),
(exe_fun === BR_BNE) -> !(op1_data === op2_data),
(exe_fun === BR_BLT) -> (op1_data.asSInt < op2_data.asSInt),
(exe_fun === BR_BGE) -> !(op1_data.asSInt < op2_data.asSInt),
(exe_fun === BR_BLTU) -> (op1_data < op2_data),
(exe_fun === BR_BGEU) -> !(op1_data < op2_data)
))
//**********************************
// Memory Access Stage
io.dmem.addr := alu_out
io.dmem.wen := mem_wen
io.dmem.wdata := rs2_data
// CSR
val csr_addr = Mux(csr_cmd === CSR_E, 0x342.U(CSR_ADDR_LEN.W), inst(31,20))
val csr_rdata = csr_regfile(csr_addr)
val csr_wdata = MuxCase(0.U(WORD_LEN.W), Seq(
(csr_cmd === CSR_W) -> op1_data,
(csr_cmd === CSR_S) -> (csr_rdata | op1_data),
(csr_cmd === CSR_C) -> (csr_rdata & ~op1_data),
(csr_cmd === CSR_E) -> 11.U(WORD_LEN.W)
))
when(csr_cmd > 0.U){
csr_regfile(csr_addr) := csr_wdata
}
//**********************************
// Writeback (WB) Stage
val wb_data = MuxCase(alu_out, Seq(
(wb_sel === WB_MEM) -> io.dmem.rdata,
(wb_sel === WB_PC) -> pc_plus4,
(wb_sel === WB_CSR) -> csr_rdata
))
when(rf_wen === REN_S) {
regfile(wb_addr) := wb_data
}
//**********************************
// Debug
io.gp := regfile(3)
io.exit := (pc_reg === 0x44.U(WORD_LEN.W))
printf(p"io.pc : 0x${Hexadecimal(pc_reg)}\n")
printf(p"inst : 0x${Hexadecimal(inst)}\n")
printf(p"gp : ${regfile(3)}\n")
printf(p"rs1_addr : $rs1_addr\n")
printf(p"rs2_addr : $rs2_addr\n")
printf(p"wb_addr : $wb_addr\n")
printf(p"rs1_data : 0x${Hexadecimal(rs1_data)}\n")
printf(p"rs2_data : 0x${Hexadecimal(rs2_data)}\n")
printf(p"wb_data : 0x${Hexadecimal(wb_data)}\n")
printf(p"dmem.addr : ${io.dmem.addr}\n")
printf(p"dmem.rdata : ${io.dmem.rdata}\n")
printf("---------\n")
}
这里有一个最引人注目的函数调用是val csignals = ListLookup(inst, List(xxx), Array(xxx))!就是将此前取指(fetch)到的指令(inst),在RISC-V整套指令集(位于Array所定义的字典)中进行查找匹配,将匹配的结果保存在csignals变量中。如果没有匹配到字典中的任何一个,则使用ListLookup函数中的第二个参数List(xxx)作为返回结果。Array(xxx)作为一个字典,每一个元素是一个用key->value表达的字典,位于->左边的是key,位于->右边的是value,在本例子中value又是一个复合体,这个复合体和第二个参数List(xxx)格式完全一样,是一个含有7个字段的List。对于取指fetch到的指令inst进行字典查找的过程,就是使用inst和字典中的每一个key值进行匹配的过程。
这个ListLookup函数是chisel的一个API函数,可以在chisel-lang官网查阅API的说明如下,其中的第二个参数是字典查找没有匹配时返回的默认值。
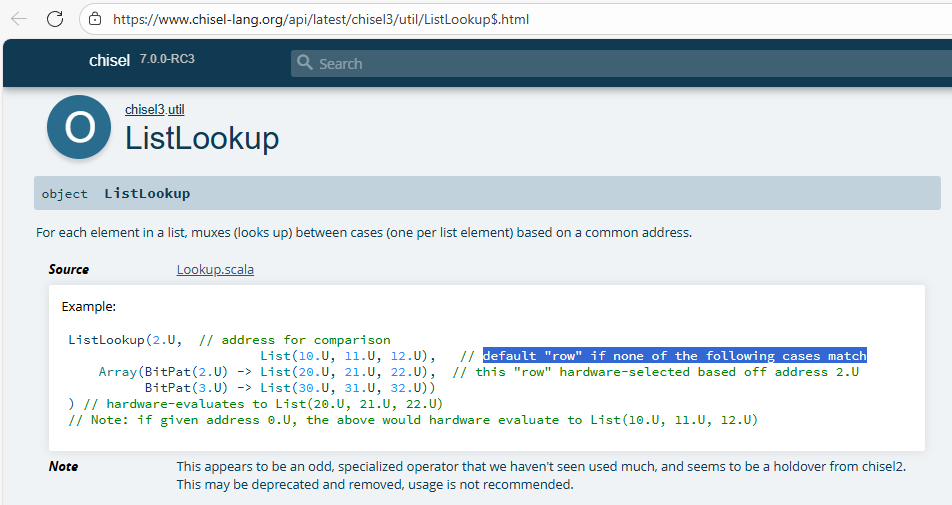
随后,使用val x :: y :: z :: w = csignals将csignals中的7个成员分别赋值给x, y, z等变量,其中的x实际为exe_func!
第二个引人注目的地方,是alu_out = MuxCase(0, Seq(xxx))这一个函数调用,对于算术运算(加减乘除)、逻辑运算(与或非)、移位运算(左移右移)都是在这里完成!显然这是实现“计算机”的“计算能力”的最直接的体现代码体现。这个MuxCase函数的第二个参数,又又又是一个字典,Seq和Array看起来都是字典!但是这个MuxCase函数没有像ListLookup函数中携带的第一个参数(inst)那样,字典的Key(也就是->的左侧)不是一个匹配inst的值、而是一个(xxx === XXX)的判断条件。MuxCase的第一个参数,表示的是没有匹配到Seq字典中的任何情况时作为函数的默认值返回给alu_out,这一点又和ListLookup函数的第二个参数相似!
这个MuxCase函数是chisel的一个API函数,可以在chisel-lang官网查阅API的说明如下,其中的第一个参数是字典查找没有匹配时返回的默认值。此前的系列文章中有用到Mux函数,本文上面的代码也有Mux函数的使用,可以对照Mux和MuxCase来更好地理解它们!
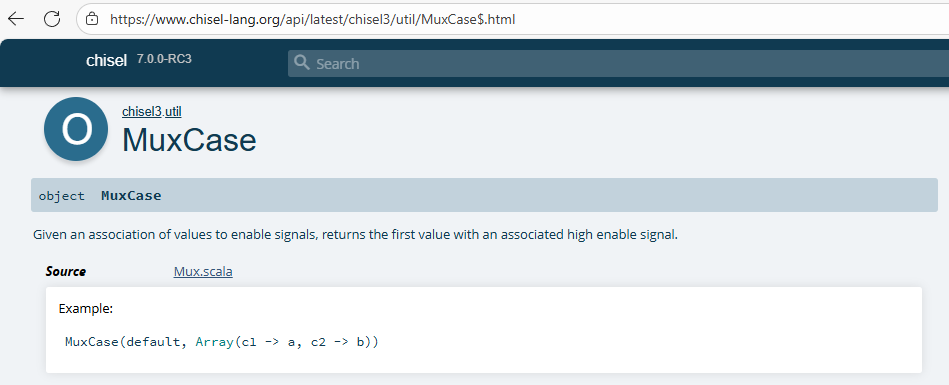
继续以alu_out这一变量为线索梳理代码,并结合常识来理解加法运算指令的结果如何写到内存中。之所以要结合常识来理解,是因为单纯的代码来看会很快陷入疑问中。看一下alu_out使用之处(总共5处):
32行:val alu_out = Wire(UInt(WORD_LEN.W))
36行:val pc_next = MuxCase(xxx, Seq(jmp_flg -> alu_out))
127行:alu_out = MuxCase(0, Seq(xxx))
157行:io.dmem.addr := alu_out
178行:val wb_data = MuxCase(alu_out, Seq(xxx))
这其中的第36行和第157行中,alu_out都是被当做内存地址(或内存地址的偏移量)来使用的!而我们常规理解的算术运算、逻辑运算和位运算中使用ALU的地方以及第127行的alu_out值的获得,都是内存地址的值而不是内存地址。这就是上面说的“陷入疑问”的问题了。
事实上,在本系列前面的文章还没有设计到ADD/ADDI等算术运算指令、只涉及Load/Store指令时,就使用了alu_out这样一个变量名表示内存地址的!
另外在本例子第127行的Array(xxx)的字典中,LW和SW指令与ADD和ADDI指令对应的操作码(也就是存放到exe_func变量中的值)一样,都是ALU_ADD,也就是说Load/Store指令的执行过程,也需要使用类似ALU的加法运算。这个加法运算不是使用ALU硬件单元,而是仅仅借用了ALU_ADD这样一个符号,以及127行处的加法代码,实现内存地址与内存地址偏移量的加法!
从常识上来说,ADD/ADDI/SUB/SUBI等算术运算、逻辑运算、移位运算的结果,最终是要通过Store写到数据内存中,这是通过两个指令(ADD和SW指令)实现的。在SW指令中,要获得Store的内存地址,需要使用加法将内存地址(位于寄存器组regfile中的某个寄存器的值,其中的寄存器是SW指令字中的5bit的wb_addr字段指定的) 加上位于SW指令字中的偏移量(12bit带符号的偏移量)。在SW指令中,还涉及到某个存储数据的寄存器(也就是算术运算的结果),这个应该就是第178行的赋值了!单纯的算术运算指令ADD/ADDI,在Store指令之前已经完成了!
假设我们运行的指令序列是ADD和SW,那么:
第一个ADD指令执行的时候,第127行->第157行->第178行依次执行,其中第127行计算的alu_out就是ADD指令的计算结果。第157行会将alu_out赋值给io.dmem.addr,但这个不会被使用。178行会将alu_out变量的值赋给wb_data(因为ADD执行下wb_sel变量的值等于WB_ALU)。第185行还会将这个wb_data存放到regfile(wb_addr)寄存器中,留给下一个指令SW使用!
第二个SW执行执行的时候,第127行->第157行->第178行依次执行,其中的第127行会计算内存地址的偏移(也就是wb_addr相关的地址计算),并保存到alu_out中。第157行会将alu_out赋值给io.dmem.addr。第159行会将rs2_data赋给io.dmem.wdata(这个rs2_data就是上一步ADD指令中的wb_data,靠编译器将代码编译为指令的时候对应上)。第158行对io.dmem.wen赋值MEM_S(Array字典中的SW这一行的MEM_S列)。到此SW其实已经就执行完了,io.dmem的三个信号wen, addr, wdata都准备好了,后端的Memory模块会在时钟驱动下将信号上的wdata写到信号addr所指定的内存中!
至此,通过代码并结合{一个ADD指令+一个SW指令}的梳理,大体上理解了整个Core.scala的运行过程。这个ADD指令换为其他算术指令、逻辑运算指令、移位运算指令,也是完全一样的。梳理一下所涉及的指令:
红色框内的LW/SW是Load/Store指令,是RISC系列CPU与CISC系列CPU(x86等)的关键区别。
绿色框内的是条件跳转(BRanch)指令。
位于红色框和绿色框之间的,是运算指令,包括算术运算(加减乘除)、逻辑运算(与或非异或)、移位运算(左移右移)。一般来说这些运算的操作数都在寄存器上,但有一部分以是直接操作数,也就是指令字中的部分bit作为运算操作的操作数!这些指令都带有一个I字符,比如ADDI或者ORI。这些计算类指令的其他字段都是完全一样的,仅这个OP2_IMI稍微特殊一些,用蓝色标识出来,对应的op2_data的构造会区分。
位于绿色框之后的,是JAL/JALR等指令,以及CSRxxx的系列执行,以及ECALL的执行。这其中又以CSR系列指令最值得关注!因为CSR(控制和状态寄存器)是CPU指令集的一个关键概念,用于多个指令连贯执行时候的状态记录,类似上面举例子的{ADD指令 + SW指令}的组合,没有用到CSR指令,但需要编译器在编译高级语言程序 到 底层的RISC-V CPU的时候,分配和使用regfile中的某一个寄存器并在ADD指令和SW指令中对应上!这个CSR要留待后面分析,这里先备忘一下,TBD。
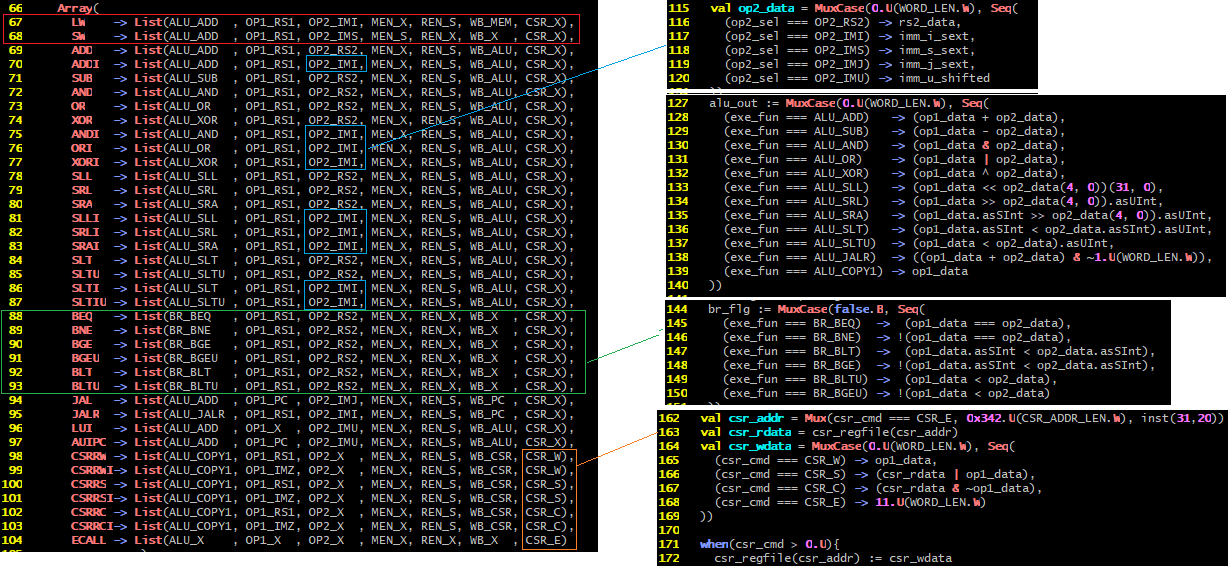
至此,已经看到了RISC-V的一整套指令集共38条指令(第67-104行),以及加减乘除运算的实际执行过程!这个实际计算过程的完整闭环,还需要Load/Store这两个指令将计算结果从寄存器写到内存中!这中间涉及到先序步骤ADD等运算结果保存到寄存器中,以及后序步骤SW将寄存器中的运算结果“搬运”到内存中,这两者的衔接,需要编译器的支持,包括从寄存器组regfile中分配哪个寄存器给先序后序的指令使用。更复杂的情况,大概就会涉及到CSR系列指令的使用!
另外,从05和04的Top.scala对比来看,05的Top模块增加了了一个io.gp = Core.io.gp,在上面Core.scare代码中的io.gp := regfile(3)明确了这个模块的输出信号,实际上就是把regfile(3)这个寄存器值赋值到输出信号上。这个是一个Global Pointer(全局指针),主要用途是快速访问程序中的全局变量和静态数据。但在目前的这个代码里暂时还没有使用。
最后总结一下:本文介绍的是一整套RISC-V的指令集的CPU芯片开发Demo代码,这一整套RISC-V指令集有38条指令,包括Load/Store、运算指令(算术-逻辑-移位)、条件跳转(BRanch)等常见的,还包括一个CSR的概念及配套的CSR系列指令。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











