







 本文详细介绍了如何在5台主机上搭建Hadoop、Zookeeper和Kafka的高可用集群。从安装JDK开始,经过解压安装包、配置环境变量,到安装和配置Hadoop、Zookeeper,最后安装并启动Kafka。重点包括Hadoop的HDFS、MapReduce和YARN的配置,Zookeeper的集群设置,以及Kafka的服务器配置。整个过程需要确保各节点间的网络互通和配置同步。
本文详细介绍了如何在5台主机上搭建Hadoop、Zookeeper和Kafka的高可用集群。从安装JDK开始,经过解压安装包、配置环境变量,到安装和配置Hadoop、Zookeeper,最后安装并启动Kafka。重点包括Hadoop的HDFS、MapReduce和YARN的配置,Zookeeper的集群设置,以及Kafka的服务器配置。整个过程需要确保各节点间的网络互通和配置同步。
高可用集群搭建
1. 事先准备
我们需要5台虚拟机或者5台服务器,它们的网络需要互通,并且需要配置hosts和各主机间免密登录等操作,以及相应脚本文件,具体详情请查阅以下博客1-5节还有一些相应脚本编写的章节:
hadoop,zk,kafka简单集群搭建
准备好这些之后我们就可以开始了
2. 安装jdk
一、先解压安装包
cd /opt/install/
[root@jerry1 install]# ls
hadoop-2.6.0-cdh5.14.2.tar.gz kafka_2.11-2.0.0.tgz
jdk-8u111-linux-x64.tar.gz zookeeper-3.4.5-cdh5.14.2.tar.gz
[root@jerry1 install]# tar -zxf jdk-8u111-linux-x64.tar.gz -C /opt/bigdata/
[root@jerry1 install]# cd /opt/bigdata/
[root@jerry1 bigdata]# mv jdk1.8.0_111/ jdk180
二、将解压好的jdk传输给其他节点
xrsync jdk180
三、配置环境变量
1.创建配置文件
cd /etc/profile.d
touch env.sh
vi env.sh
2.加入jdk配置
export JAVA_HOME=/opt/bigdata/jdk180
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
3.给集群中所有其他主机传输一下env.sh配置文件
xrsync env.sh
4.给集群中所有主机source一下配置文件,使它生效,所有主机的jdk就都安装完成了。
3. 安装hadoop
一、解压hadoop
[root@jerry1 install]# tar -zxf hadoop-2.6.0-cdh5.14.2.tar.gz -C /opt/bigdata/
[root@jerry1 install]# mv /opt/bigdata/hadoop-2.6.0-cdh5.14.2/ /opt/bigdata/hadoop260
二、修改hadoop中所有配置文件中的jdk路径
进入hadoop的etc文件夹中hadoop文件夹中,对一下几个文件进行修改
vi hadoop-env.sh

vi mapred-env.sh

vi yarn-env.sh

三、配置hdfs配置文件
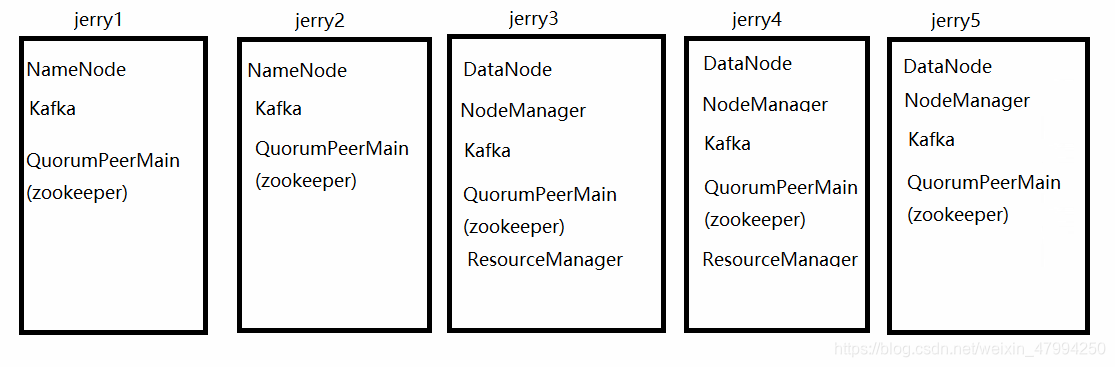
我们按照下图来进行配置
配置 core-site.xml ,配置了namenode所在节点,在configuration里面添加新内容。
vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/bigdata/hadoop260/hadoopdata</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>jerry1:2181,jerry2:2181,jerry3:2181,jerry4:2181,jerry5:2181</value>
</property>
</configurati 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









