




 本文档介绍了如何在Google Colab上利用Disco Diffusion模型,通过输入文本来生成对应的图片。首先,需要在Colab上保存模型的副本并连接到Google云端硬盘。然后,在模型设置中输入文本提示,调整n_batches参数以生成单张图片。运行后,模型会开始渲染图片,大约5分钟后完成。最后,可以在Google云端硬盘的指定文件夹中查看和下载生成的图像。
本文档介绍了如何在Google Colab上利用Disco Diffusion模型,通过输入文本来生成对应的图片。首先,需要在Colab上保存模型的副本并连接到Google云端硬盘。然后,在模型设置中输入文本提示,调整n_batches参数以生成单张图片。运行后,模型会开始渲染图片,大约5分钟后完成。最后,可以在Google云端硬盘的指定文件夹中查看和下载生成的图像。
目的:在谷歌的的colab上基于disco diffusion模型实现输入文本输出相应图片的功能
1、disco diffusion托管在谷歌的colab上,登录对应网址如下:
https://colab.research.google.com/github/alembics/disco-diffusion/blob/main/Disco_Diffusion.ipynb
2、保存副本文件
进入页面后,要先在云端硬盘中保存一份副本,在副本上进行接下来的操作。
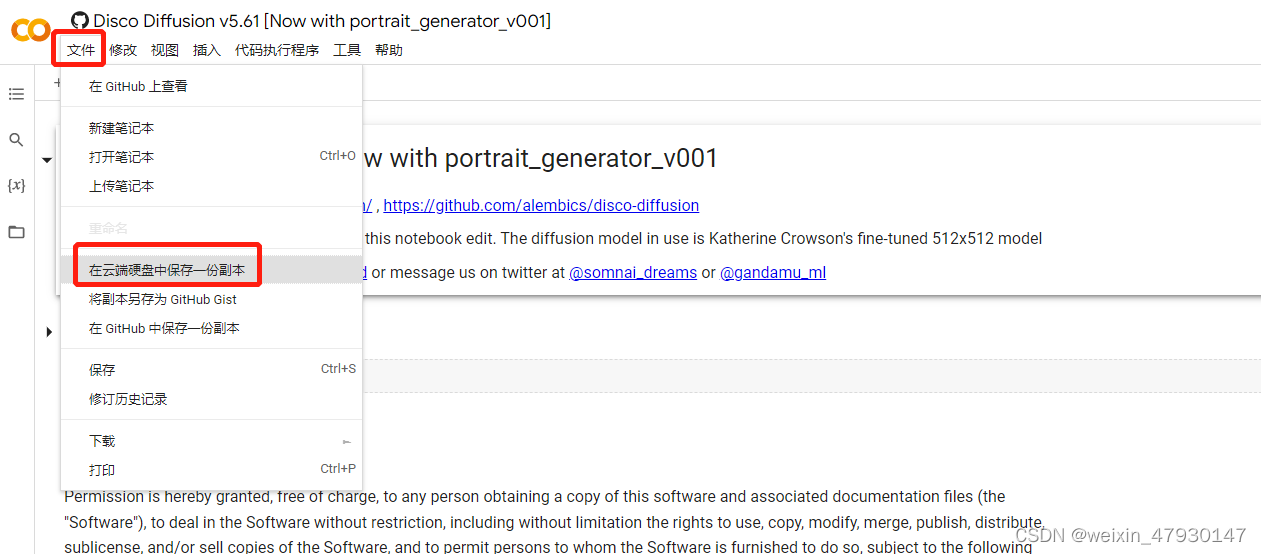
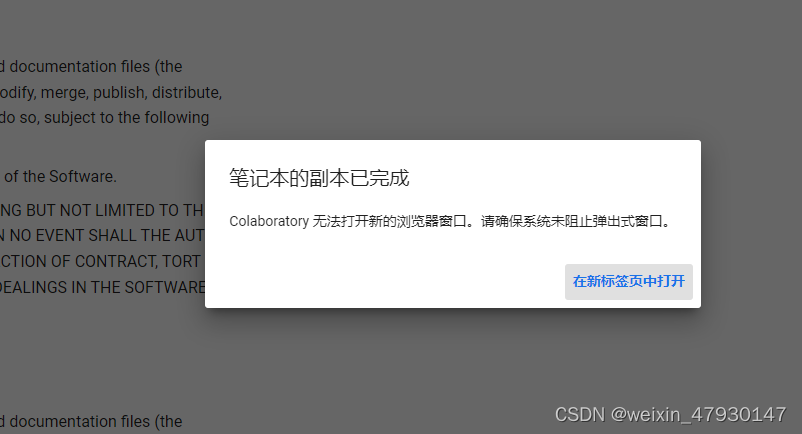
点击“在新标签页中打开”后进入副本页面
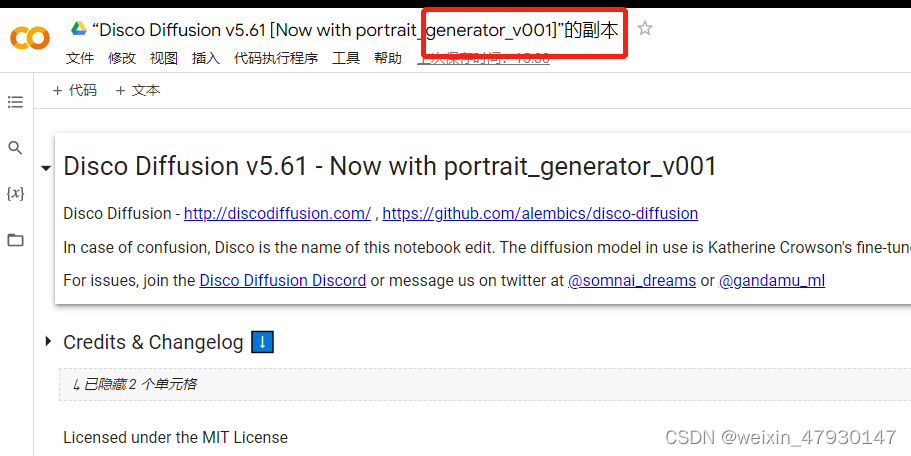
点击确定:

点击“连接到google云端硬盘”
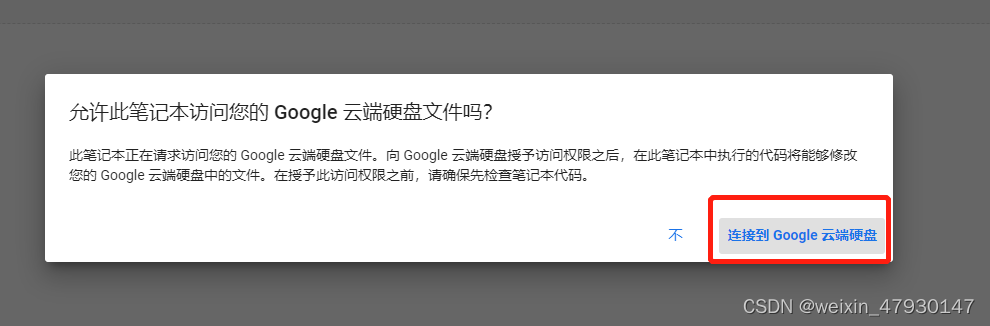
使用谷歌账户登录谷歌云盘
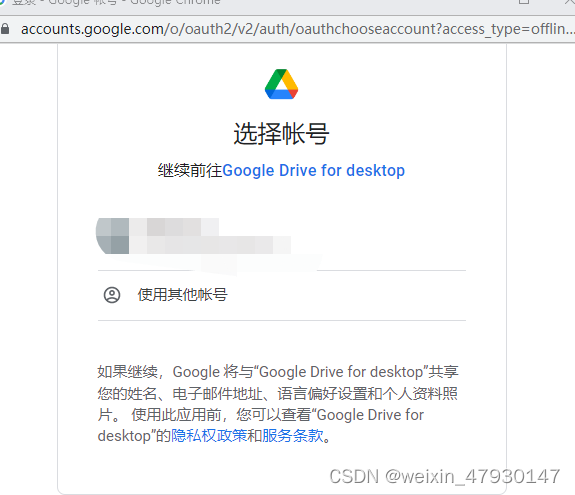
3、输入文本,输出图片
在第三部分的setting中,找到prompt模块,其中text_prompts 中输入文本,
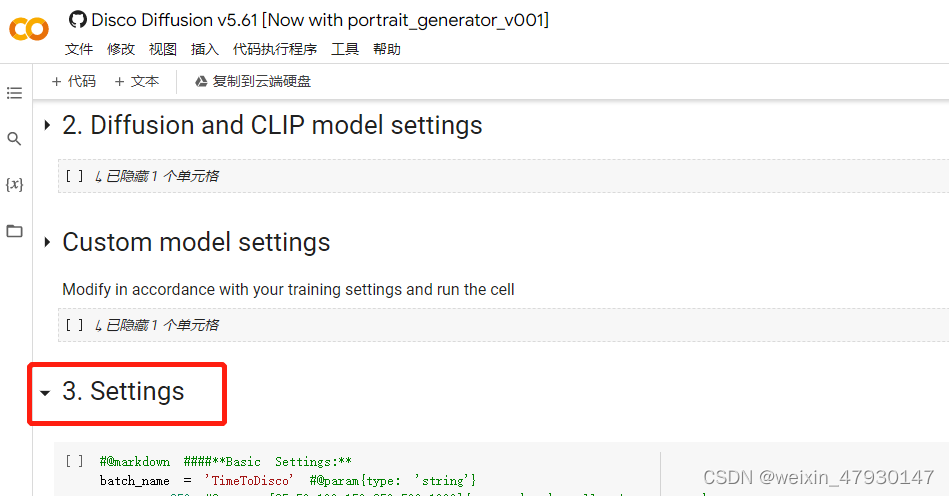

将第四部分中的n_batches设置为1,这样生成的图片就只有一张,
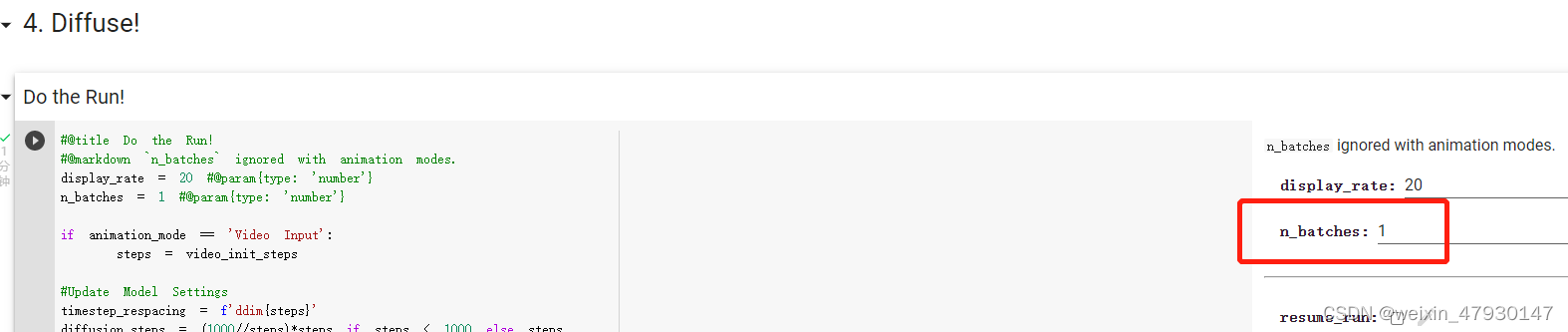
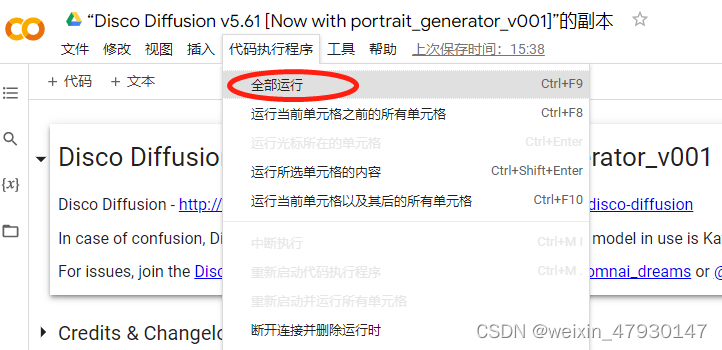
点击全部运行,开始作图
在diffusion模块中 可以看到图片渲染的进度
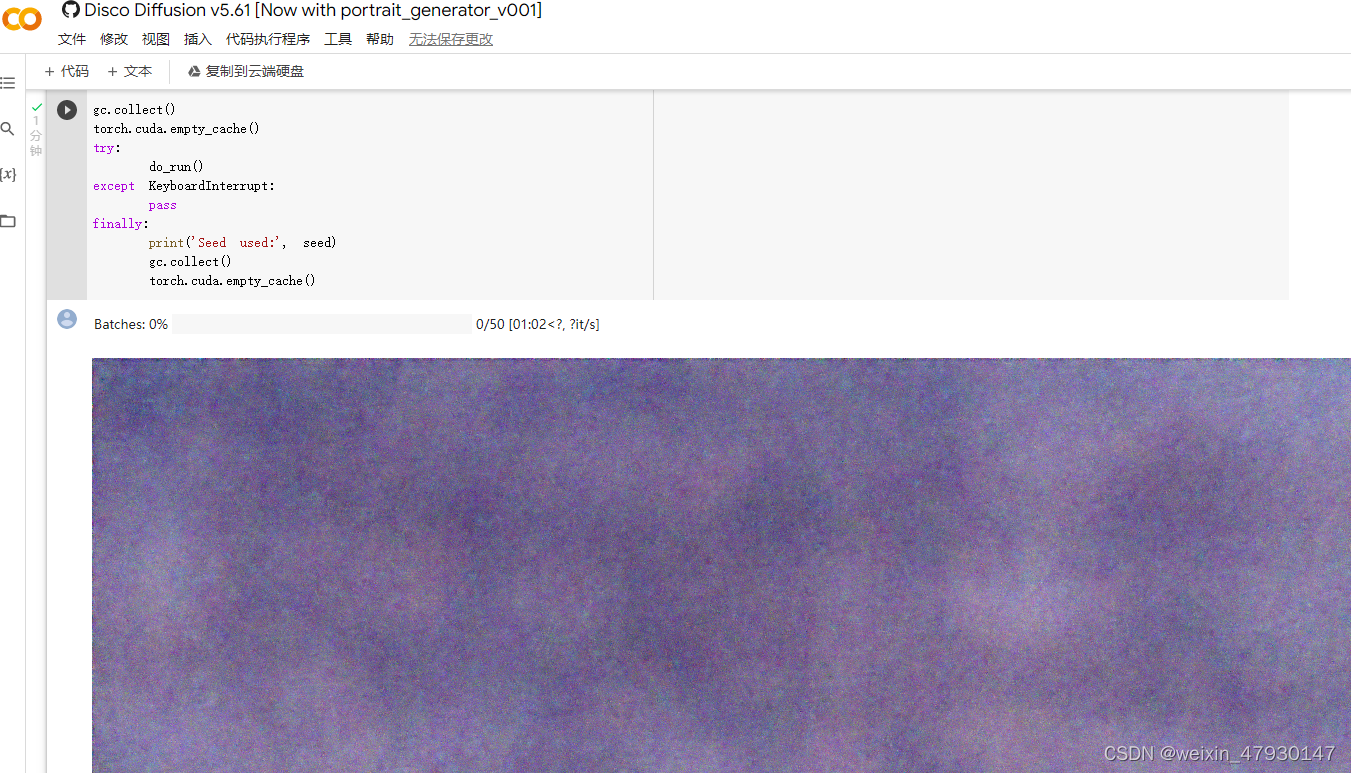
渲染五分钟后:
4、常用参数
disco diffusion模型中还有诸多参数可以设置,作者整理了主要参数的含义及取值范围,如下表
| 序号 | 分类 | 字段 | 描述 | 取值 |
| 1 | 提示 | text_prompts | 对你希望机器生成的内容进行描述 | |
| 2 | image_prompts | 可以设置一些参考图片,以对其内容的更多描述(可选) |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









