







 本文介绍了一个基于唐宇迪opencv项目实战的OCR文本扫描过程,包括图片处理、轮廓检测、透视变换等步骤。首先,通过resize和Canny边缘检测进行预处理,接着应用高斯滤波去除噪点。然后,使用findContours找到轮廓并进行近似处理。透视变换部分,详细解释了cv2.getPerspectiveTransform和cv2.warpPerspective函数的使用。最后,通过pytesseract进行OCR文本识别。
本文介绍了一个基于唐宇迪opencv项目实战的OCR文本扫描过程,包括图片处理、轮廓检测、透视变换等步骤。首先,通过resize和Canny边缘检测进行预处理,接着应用高斯滤波去除噪点。然后,使用findContours找到轮廓并进行近似处理。透视变换部分,详细解释了cv2.getPerspectiveTransform和cv2.warpPerspective函数的使用。最后,通过pytesseract进行OCR文本识别。
OCR文本扫描 轮廓检测 透视变换
本项目和源代码来自唐宇迪opencv项目实战
OCR文本识别
什么是OCR,百度里的定义是:
OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程;即,针对印刷体字符,采用光学的方式将纸质文档中的文字转换成为黑白点阵的图像文件,并通过识别软件将图像中的文字转换成文本格式,供文字处理软件进一步编辑加工的技术。
输入一张图,然后扫描出其中文字


算法步骤
1、导入图片
image = cv2.imread('receipt.jpg')
2、图片与处理
resize 操作
resize函数的作用是按照原图像相同长宽比,当给定长(height)或者宽(width)时将原图resize成与原图像同比例的大小。
至于这一步为什么要进行resize操作,我分析
1 实验使用的图像多为手机拍摄的图片,图片大小至少为3500*4000,在imshow(),在屏幕显示并不能像是完整的图像,不利于观察。
该函数的返回值是resize后的图片;参数是原图像和指定的变换后的width或height值。
接着对图像进一步操作
Canny边缘检测步骤
1、canny边缘检测
使用高斯滤波器,以平滑图像,滤除噪声。计算图像中每个像素点的梯度强度和方向。应用非极大值(Non-Maximum Suppression)抑制,以消除边缘检测带来的杂散响应。应用双阈值(Double-Threshold)检测来确定真实的和潜在的边缘。通过抑制孤立的弱边缘最终完成边缘检测。
1、高斯滤波器:通过高斯分布去除噪点

2、计算Gx和Gy
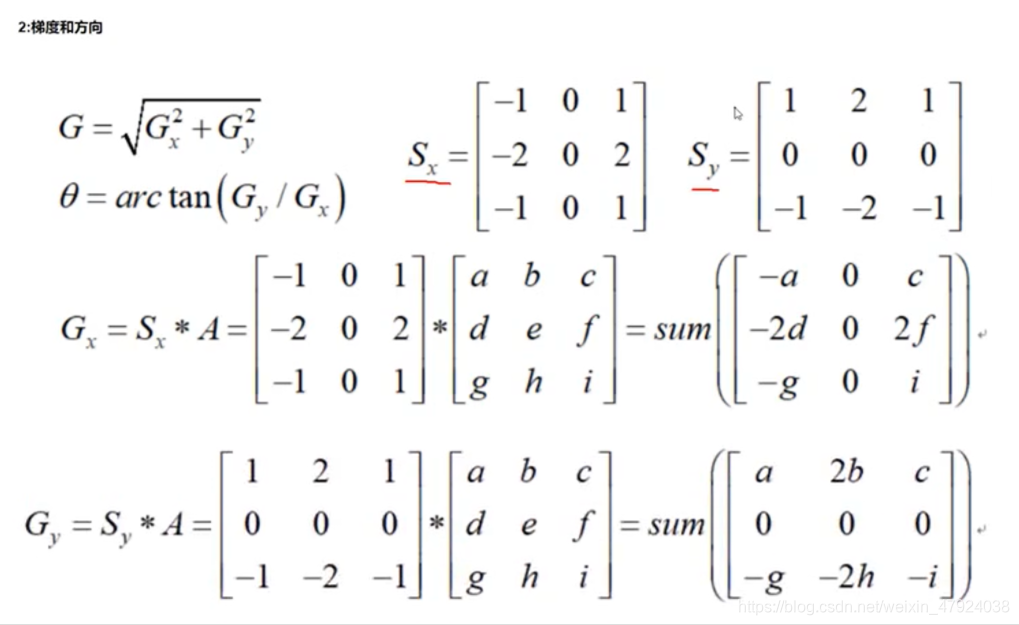
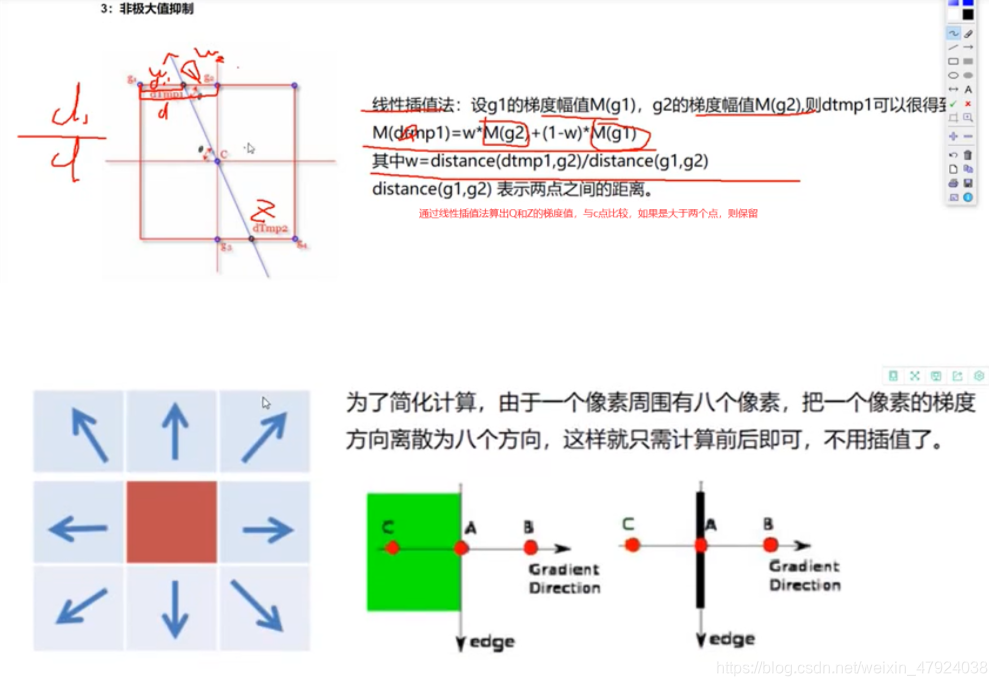
3、非极大值抑制
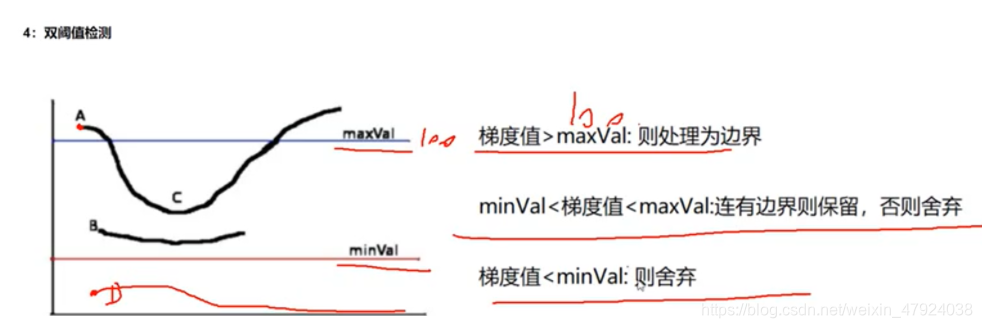
4、双阈值检测
import cv2 #opencv读取的格式是BGR
import numpy as np
import matplotlib.pyplot as plt#Matplotlib是RGB
def cv_show(name,img):
cv2.imshow(name,img)
#等待时间,毫秒级,0表示任意键终止
cv2.waitKey(0)#任意键终止
cv2.destroyAllWindows()
img=cv 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









