







HTTP基本原理简介
HTTP是超文本传输协议的缩写
1.用于从WWW服务器传输超文本到本地浏览器的传送协议,它可以使浏览器更加高效,使网络传输减少。
2.它不仅保证计算机正确快速地传输超文本文档,还确定传输文档中的哪一部分,以及哪部分内容首先显示(如文本先于图形)等。
3.HTTP是一个应用层协议,由请求和响应构成,是一个标准的客户端服务器模型
HTTP协议永远都是客户端发起请求,服务器回送响应
我们在浏览器中输入一个URL,回车之后便会在浏览器中观察到页面内容。实际上这个过程是浏览器向网站所在的服务器发送了一个请求,网站服务器收到这个请求后进行处理和解析,然后返回对应的响应,接着传回给浏览器.响应里包含了页面的源代码等内容,浏览器再对其进行解析,便将网页呈现了出来
请求方法
常见的请求方式
- GET请求:请求的参数会直接包含到URL中
- POST请求:数据通常以表单的i形式传输,而不会体现在URL中
GET和POST请求方法有如下区别:
- GET请求中的参数包含到URL中;而POST请求中的参数在请求体中,不会包含到URL中
- GET请求提交的数据最多只有1024字节,而POST方式没有限制
一般来说,登陆时,需要提交用户名和密码,其中包含了敏感信息,使用GET方式密码就会暴露在URL中,造成密码泄露,所以这里最好以POST方式发送
上传文件时,由于文件内容比较大,也会选用POST方式
请求头
Accept:请求报头域,用于指定客户端可接受哪些类型的信息。
Accept-Language:指定客户端可接受的语言类型
Accept-Encoding:指定客户端可接受的内容编码
Host:用于指定请求资源的主机IP和端口号,其内容为请求URL的原始服务器或网关的位置。从HTTP1.1版本开始,请求必须包含此内容
Cookie:这是网站为了辨别用户绘画跟踪而存储在用户本地的数据。它的主要功能是维持当前访问会话。例如:我们输入用户名和密码成功登录某个网站后,服务器会用会话保存登录状态信息,后面我们每次刷新或者请求该站点的其它页面时,会发现都是登录状态,这就是cookie的功劳。cookies里有信息标识了我们所对于的服务器会话,每次浏览器在请求该网站页面时,都会在请求头中加上cookies并将其发送给服务器,服务器通过cookies识别出是我们自己,并且查出当前状态时登录状态,所以返回结果就是登录之后才能看到的网页内容
Refer:此内容用来表示这个请求是从哪个页面发送过来的,服务器可以拿到这一信息并做相应的处理,如做来源统计,防盗链处理等
User-Agent:它是一个特殊的字符串头,可以使服务器识别客户使用的操作系统及版本,浏览器及版本等信息,在做爬虫时加上此信息,可以伪装成浏览器;如果不加很可能被识别出为爬虫
Content-type:也叫互联网媒体类型,它用来表示请求中的媒体类型信息
响应
响应,由服务器返回给客户端可以分为三部分:
- 响应状态码
- 响应头
- 响应体
响应状态码表示服务器的响应状态
如200代表服务器正常响应
404代表页面未找到
500代表服务器内部发生错误
在爬虫中,我们可以根据状态码来判断服务器响应的状态,如状态码为200,则证明成功返回数据,在进行进一步的处理
响应头包含了服务器对请求的应答信息:
Date:标识响应产生的时间
Last-Modified:指定资源的最后修改时间
Content-Encoing:指定响应内容的编码
Server:包含服务器的信息,比如名称,版本号等
Content-Type:文档类型,指定返回的数据类型是什么,如text/html代表返回HTML文档,application/x-javascript则代表JS文件,image/jpeg则代表返回图片
Set-Cookie:设置Cookie.响应中的set-cookie告诉浏览器需要将内容放在Cookies中,下次请求携带Cookies请求
响应体
响应的正文数据都在响应体中,比如请求网页时,它的响应体就是网页的HTML代码;
请求一张图片时,它的响应体就是图片的二进制数据
我们做爬虫请求网页后,要解析的内容就是响应体;
在浏览器开发者工具中点击Priview,就可以看到网页的源代码,也就是响应内容,他是解析的目标
在做爬虫时,我们主要通过响应体得到网页的源代码,json数据等然后从中提取相应的内容
Requests 模块
安装
pip install requests
get()方法
get()方法url参数必须
headers请求头信息,绝大多数情况下是需要使用的,一般user-agent
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36'
}
url = 'https://top.baidu.com/board'
params = {
'platform':'pc',
'sa':'pcindex_entry'
}
reponse = requests.get(url,params=params,headers=headers)
print(reponse.url)
post()方法
post()方法url参数和data或json参数必须
henders请求头信息,绝大多数情况下是需要使用的一般user-agent
响应
响应的属性:
response.status_code 响应的状态码
response.headers:响应头信息
response.encoding 编码格式信息
response.cookies cookies信息
response.url 响应的url信息
response.text 文本类型,通常是html文本
response.content bytes型也就是二级制数据,如图片/视频/音频等
requests模块中有内置JSON解码器,可以处理JSON数据 =》response.json()
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36'
}
url='https://gimg2.baidu.com/image_search/src=http%3A%2F%2Fimg.jj20.com%2Fup%2Fallimg%2F1114%2F113020142315%2F201130142315-1-1200.jpg&refer=http%3A%2F%2Fimg.jj20.com&app=2002&size=f9999,10000&q=a80&n=0&g=0n&fmt=auto?sec=1656293754&t=59a1bd4bfd0c7893fb7030af9522ef46'
reponse = requests.get(url,headers=headers)
print(reponse.content)
with open('pic.jpg','wb') as file:
file.write(reponse.content)
print('图片下载完成')
BS4模块
安装
pip install beautifulsoup4
简介
beautifulsoup4 是一个可以从HTML,XML文件中提取数据的库
安装解析器
pip install lxml
四大对象
Beautiful,Tag,NavigableString,Comment
- BeautifulSoup 对象,整个文档对象。
表示的是一个文档的全部内容.大部分的时候,可以把它当作全部Tag对象,它支持遍历文档书和搜索文档书中描述的大部分方法 - Tag对象,标签对象
与XML或HTML原生文档中的tag相同。
tag.name 标签名字
tag[‘class’] class属性 - NavigableString对象,字符串对象
tage.string - Comment 对象,注释对象
from bs4 import BeautifulSoup
soup = BeautifulSoup(open("index.html")) # 整个文档
tag = soup.p # 标签对象
tag.string # 字符串对象
import requests
from bs4 import BeautifulSoup
url = 'http://www.baidu.com'
response = requests.get(url)
response.encoding = 'utf-8'
html_doc = response.text
soup = BeautifulSoup(html_doc,'lxml')
print(soup.title.string)
搜索文档书
- find
- find_all
- select_one
- select
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36'
}
url = 'https://movie.douban.com/top250'
response = requests.get(url,headers=headers)
html_doc = response.text
soup = BeautifulSoup(html_doc,'lxml')
#查找单个标签 默认第一个
print(soup.find('em'))
#查找标签 全部
print(soup.find_all('em'))
print('~'*30)
# 获取单个标签 默认获取第一个
print(soup.find('span',{'class':'title'}))
print(soup.find(class_='title'))

import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36'
}
url = 'https://movie.douban.com/top250'
response = requests.get(url,headers=headers)
html_doc = response.text
soup = BeautifulSoup(html_doc,'lxml')
# 获取全部标签
title_elems = soup.find_all('span',{'class':'title'})
for title in title_elems:
print(title.string)
print(30*'-')
肖申克的救赎
------------------------------
/ The Shawshank Redemption
------------------------------
霸王别姬
------------------------------
阿甘正传
------------------------------
/ Forrest Gump
------------------------------
泰坦尼克号
------------------------------
/ Titanic
------------------------------
这个杀手不太冷
------------------------------
/ Léon
------------------------------
美丽人生
------------------------------
/ La vita è bella
------------------------------
千与千寻
------------------------------
/ 千と千尋の神隠し
------------------------------
辛德勒的名单
------------------------------
/ Schindler's List
------------------------------
盗梦空间
------------------------------
/ Inception
------------------------------
忠犬八公的故事
------------------------------
/ Hachi: A Dog's Tale
------------------------------
星际穿越
------------------------------
/ Interstellar
------------------------------
楚门的世界
------------------------------
/ The Truman Show
------------------------------
海上钢琴师
------------------------------
/ La leggenda del pianista sull'oceano
------------------------------
三傻大闹宝莱坞
------------------------------
/ 3 Idiots
------------------------------
机器人总动员
------------------------------
/ WALL·E
------------------------------
放牛班的春天
------------------------------
/ Les choristes
------------------------------
无间道
------------------------------
/ 無間道
------------------------------
疯狂动物城
------------------------------
/ Zootopia
------------------------------
大话西游之大圣娶亲
------------------------------
/ 西遊記大結局之仙履奇緣
------------------------------
熔炉
------------------------------
/ 도가니
------------------------------
控方证人
------------------------------
/ Witness for the Prosecution
------------------------------
教父
------------------------------
/ The Godfather
------------------------------
当幸福来敲门
------------------------------
/ The Pursuit of Happyness
------------------------------
触不可及
------------------------------
/ Intouchables
------------------------------
怦然心动
------------------------------
/ Flipped
------------------------------
Process finished with exit code 0
可以稍微做一下处理把英文名去掉
# 获取全部标签
title_elems = soup.find_all('span',{'class':'title'})
for title in title_elems:
if '/' in title.string:
continue
else:
print(title.string)
print(30*'-')
肖申克的救赎
------------------------------
霸王别姬
------------------------------
阿甘正传
------------------------------
泰坦尼克号
------------------------------
select_one
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36'
}
url = 'https://movie.douban.com/top250'
response = requests.get(url,headers=headers)
html_doc = response.text
soup = BeautifulSoup(html_doc,'lxml')
print(soup.select_one('.title').string)
肖申克的救赎
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36'
}
url = 'https://movie.douban.com/top250'
response = requests.get(url,headers=headers)
html_doc = response.text
soup = BeautifulSoup(html_doc,'lxml')
# class等于title
print(soup.select_one('.title').string)
# class等于hd 空格表示下一级 a标签下的第一个
print(soup.select_one('.hd a').text)
肖申克的救赎
肖申克的救赎
/ The Shawshank Redemption
/ 月黑高飞(港) / 刺激1995(台)
取出全部
title_elems = soup.select('.title')
for title in title_elems:
print(title.text)
print(30*'~')
title_elems = soup.select('.hd a')
for title in title_elems:
print(title.span.string)
print(30*'~')
肖申克的救赎
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
霸王别姬
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
阿甘正传
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
泰坦尼克号
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
这个杀手不太冷
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
获取电影链接
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36'
}
url = 'https://movie.douban.com/top250'
response = requests.get(url,headers=headers)
html_doc = response.text
soup = BeautifulSoup(html_doc,'lxml')
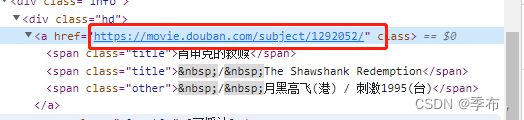
title_elems = soup.select('.hd a')
for title in title_elems:
print(title.get('href'))
print(title.span.string)
print(30*'~')
openpyxl
openpyxl创建排序sheet
from openpyxl import Workbook
#要操作的excel文件
wb = Workbook()
ws = wb.active
ws1 = wb.create_sheet('学生信息',0)
ws2 = wb.create_sheet('学生成绩',1)
wb.save(r"C:\Users\45563\Desktop\work1.xlsx")
openpyxl 读取excel数据
from openpyxl import Workbook
import openpyxl
# 加载excel文件
wb = openpyxl.load_workbook(r'C:\Users\45563\Desktop\work1.xlsx')
# 选择sheet表 ['学生信息', '学生成绩', 'Sheet']
print(wb.sheetnames)
# 获取具体的sheet表 获取其对象<Worksheet "学生信息">
ws = wb['学生信息']
print(ws)
# 定位读取某个cell
A1 = ws['A1'].value
print(A1)
# 读取多行或全部
for row in ws.rows:
data_list = [cell.value for cell in row]
print(data_list)
# 控制读取的范围 行迭代
for row in ws.iter_rows(min_row=2,min_col=1,max_row=max_row,max_col=max_column):
data_list = [cell.value for cell in row]
print(data_list)
# 控制读取的范围 列迭代
for column in ws.iter_cols(min_row=2,min_col=1,max_row=max_row,max_col=max_column):
data_list = [cell.value for cell in column]
print(data_list)
openpyxl 写入excel
from openpyxl import Workbook
import openpyxl
# 加载excel文件
wb = Workbook()
ws = wb.active
# 选择sheet表 ['学生信息', '学生成绩', 'Sheet']
print(wb.sheetnames)
# 获取具体的sheet表 获取其对象<Worksheet "学生信息">
# cell写入
# ws.cell(row=5,column=5).value = 'python'
#
# 具体定位
# ws['A1'] = 'A1'
# ws['B1'] = 'B1'
# ws['B3'] = 'B3'
# 追加写入
rows = (
('李四','男',12),
('王五','男',18),
('孙李','男',20)
)
for row in rows:
ws.append(row)
wb.save(r"C:\Users\45563\Desktop\work1.xlsx")



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











