




前言
从实战场景出发

1. 基本知识
pd.pivot_table 是 Pandas 中一个强大的数据透视表工具,用于重新排列和汇总数据表,通过聚合函数对数据进行分组统计,生成一个新的数据框,非常适合处理结构化数据分析
基本知识以表格形式进行呈现:
| 项目 | 内容 |
|---|---|
| 作用 | 将长格式数据重新排列为宽格式数据,并进行聚合统计 |
| 函数签名 | pd.pivot_table(data, values=None, index=None, columns=None, aggfunc=‘mean’, fill_value=None) |
| 常用参数 | – |
| data | 必需,待处理的数据框 |
| values | 可选,需要聚合的列,默认为所有数值列 |
| index | 必需,透视表的行索引 |
| columns | 必需,透视表的列索引 |
| aggfunc | 可选,聚合函数,默认为 mean,也可选 sum、count 等 |
| fill_value | 可选,替代缺失值的填充值 |
应用场景
| 场景 | 描述 |
|---|---|
| 数据汇总与统计 | 按行和列分类后对特定值进行统计(如求和、平均值等) |
| 数据透视与转置 | 将长格式表转换为宽格式表,更直观地显示分组结果 |
| 缺失值填充 | 使用 fill_value 替代缺失值,便于后续数据分析 |
| 可视化前的数据准备 | 生成适合热图或其他图表的数据格式 |
优缺点
| 优点 | 缺点 |
|---|---|
| 支持多种聚合方式,灵活性高 | 大型数据框透视时性能较低,需优化数据规模 |
| 使用简单直观,参数明确 | 如果数据中有重复行,透视表可能难以识别原因并返回错误结果 |
| 支持 fill_value 填充缺失值 | 当 index 和 columns 层次复杂时,生成的表可能过于宽广,难以直接分析 |
2. Demo
场景:分析设备运行数据,统计每种类型设备的平均运行时间
假设原始数据为:
| EquipmentNo | EquipmentType | key value |
|---|---|---|
| A1 | Type1 | RunTime |
| A1 | Type1 | DownTime |
| A2 | Type1 | RunTime |
| A2 | Type1 | DownTime |
| B1 | Type2 | RunTime |
| B1 | Type2 | DownTime |
使用 pd.pivot_table 生成透视表
import pandas as pd
# 原始数据
data = {
"EquipmentNo": ["A1", "A1", "A2", "A2", "B1", "B1"],
"EquipmentType": ["Type1", "Type1", "Type1", "Type1", "Type2", "Type2"],
"key": ["RunTime", "DownTime", "RunTime", "DownTime", "RunTime", "DownTime"],
"value": [120, 10, 100, 20, 200, 30],
}
df = pd.DataFrame(data)
# 使用 pd.pivot_table 透视表
pivot_table = pd.pivot_table(
df,
index="EquipmentNo", # 行:设备编号
columns="key", # 列:统计维度
values="value", # 值:运行数据
aggfunc="mean", # 聚合方式:取平均值
fill_value=0 # 填充缺失值
).reset_index()
print(pivot_table)
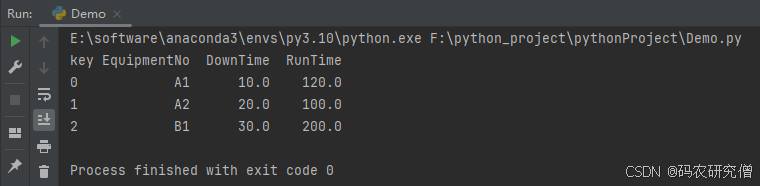
截图如下:



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











