







LeetCode 1738 题 “找出第 K 大的异或坐标值” 要求我们计算一个二维前缀异或和,然后找到第 K 大的值。
解体关键知识点:
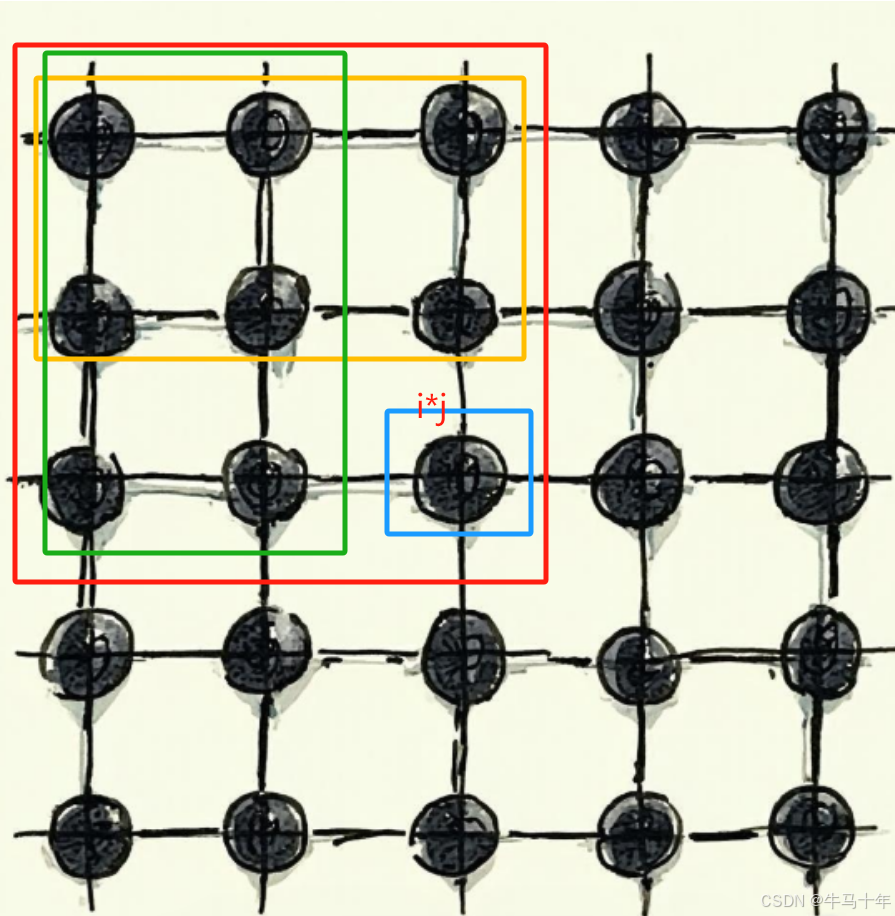
找到xor( i, j ) 和 matrix[i][j] , xor( i-1, j ) , xor( i, j-1 ) , xor( i-1, j-1 )的关系,有了这个关系就可以利用前面计算的值,不需要反复计算
设 xor(i,j) 表示从 (0,0) 到 (i,j) 的矩形区域的 前缀异或和,其计算方式如下:
xor( i, j ) = matrix[i][j] ⊕ xor( i-1, j ) ⊕ xor( i, j-1 ) ⊕ xor( i-1, j-1 ) (重复部分利用a异或a为0的属性减去,也就是绿色和黄色重叠区域)
题目描述:
给你一个二维矩阵 matrix,它的大小为 m x n,你需要计算 异或前缀和:
xor[i][j] = matrix[0][0] ⊕ ... ⊕ matrix[i][j](包含所有左上角的元素)
然后,找到这些 xor[i][j] 值中第 K 大的数。
暴力方式:
func kthLargestValue(matrix [][]int, k int) int {
all := []int{}
m, n := len(matrix), len(matrix[0])
for i := 0; i < m; i++ {
for j := 0; j < n; j++ {
all = append(all, cal(i, j, matrix))
}
}
sort.Ints(all)
return all[len(all)-k]
}
func cal(m, n int, matrix [][]int) int {
start := 0
for i := 0; i <= m; i++ {
for j := 0; j <= n; j++ {
start ^= matrix[i][j]
}
}
return start
}代码问题
-
cal(i, j, matrix)计算方式效率低-
cal(i, j, matrix)采用 直接枚举 (0,0) 到 (i,j) 所有元素 的方式计算异或和: - 对于一个
m x n的矩阵,每个cal(i, j, matrix)可能会进行O(mn)级别的计算,而总共计算m*n次,所以整体复杂度是 O(m²n²),这在 大矩阵时会超时。
-
-
可以用前缀异或优化
- 你是 重复计算已算过的部分,实际上可以 用前缀异或优化,避免重复计算。
- 计算
(i, j)的 XOR 值时,只需利用 前面已计算的值 - 这样计算 一次是 O(1),总复杂度是 O(mn),比你的
O(m²n²)高效得多
利用公式关系优化:复杂度:O(mn*log(mn)),适用于 小规模矩阵。
func kthLargestValue(matrix [][]int, k int) int {
m, n := len(matrix), len(matrix[0])
xorValues := make([]int, 0, m*n)
for i := 0; i < m; i++ {
for j := 0; j < n; j++ {
if i > 0 {
matrix[i][j] ^= matrix[i-1][j]
}
if j > 0 {
matrix[i][j] ^= matrix[i][j-1]
}
if i > 0 && j > 0 {
matrix[i][j] ^= matrix[i-1][j-1]
}
xorValues = append(xorValues, matrix[i][j])
}
}
sort.Sort(sort.Reverse(sort.IntSlice(xorValues)))
return xorValues[k-1]
}利用最小堆优化排序:
package main
import (
"container/heap"
"fmt"
)
// 小顶堆
type MinHeap []int
func (h MinHeap) Len() int { return len(h) }
func (h MinHeap) Less(i, j int) bool { return h[i] < h[j] } // 小顶堆
func (h MinHeap) Swap(i, j int) { h[i], h[j] = h[j], h[i] }
func (h *MinHeap) Push(x interface{}) { *h = append(*h, x.(int)) }
func (h *MinHeap) Pop() interface{} {
old := *h
n := len(old)
x := old[n-1]
*h = old[:n-1]
return x
}
func kthLargestValue(matrix [][]int, k int) int {
m, n := len(matrix), len(matrix[0])
h := &MinHeap{}
heap.Init(h)
xor := make([][]int, m)
for i := range xor {
xor[i] = make([]int, n)
}
for i := 0; i < m; i++ {
for j := 0; j < n; j++ {
xor[i][j] = matrix[i][j]
if i > 0 {
xor[i][j] ^= xor[i-1][j]
}
if j > 0 {
xor[i][j] ^= xor[i][j-1]
}
if i > 0 && j > 0 {
xor[i][j] ^= xor[i-1][j-1]
}
heap.Push(h, xor[i][j])
if h.Len() > k {
heap.Pop(h)
}
}
}
return heap.Pop(h).(int)
}
func main() {
matrix := [][]int{
{5, 2},
{1, 6},
}
k := 2
fmt.Println(kthLargestValue(matrix, k)) // 输出: 5
}
复杂度分析
- 计算前缀异或和:O(mn)
- 维护最小堆:
- 每次插入堆 O(logk)
- 最多插入 O(mn)
- 总复杂度:O(mnlogk)
整体复杂度为 O(mnlogk),适用于大数据集。
总结
- 堆方法:适用于 大规模数据,复杂度 O(mnlogk)
- 排序方法:适用于 小规模数据,复杂度 O(mnlog(mn))


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









