






1.Ajax是什么?
Ajax(Asynchronous JavaScript and XML)是一种在无需重新加载整个网页的情况下,能够更新部分网页的技术。Ajax 通过在后台与服务器进行少量数据交换,使网页实现异步更新。这意味着可以在不影响网页当前显示内容的情况下,与服务器进行通信并更新部分网页内容。
Ajax 的工作流程通常如下:
- 用户触发一个事件(如点击按钮)。
- JavaScript 创建一个
XMLHttpRequest对象。 XMLHttpRequest对象向服务器发送请求。- 服务器处理请求并返回数据。
- JavaScript 接收服务器返回的数据,并使用 DOM 更新网页的部分内容。
2.分析请求
我们这里以微博为例,访问任一一博主,分析请求:
① 进入开发者工具,然后筛选请求,查看此次目标响应 xhr
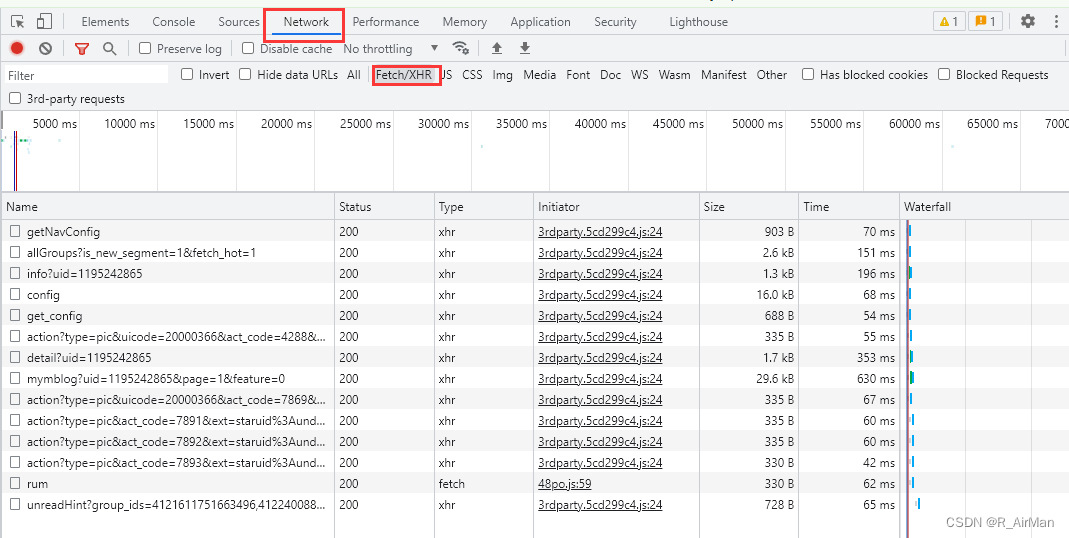
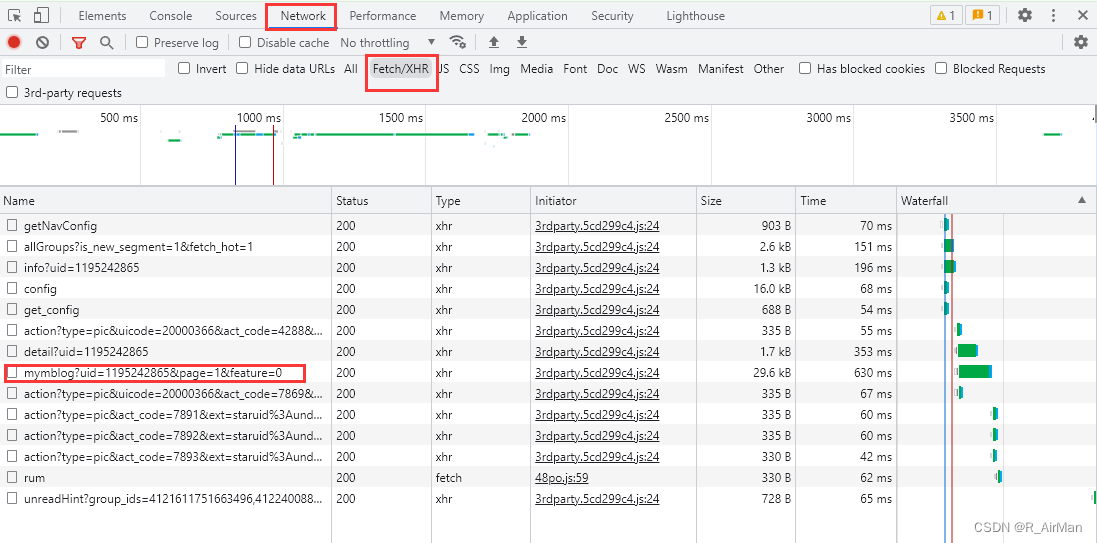
② 通过查看各个文件,我们发现Name为mymblog中包含了此次想要获取的数据(微博内容,点赞数,评论数等等)
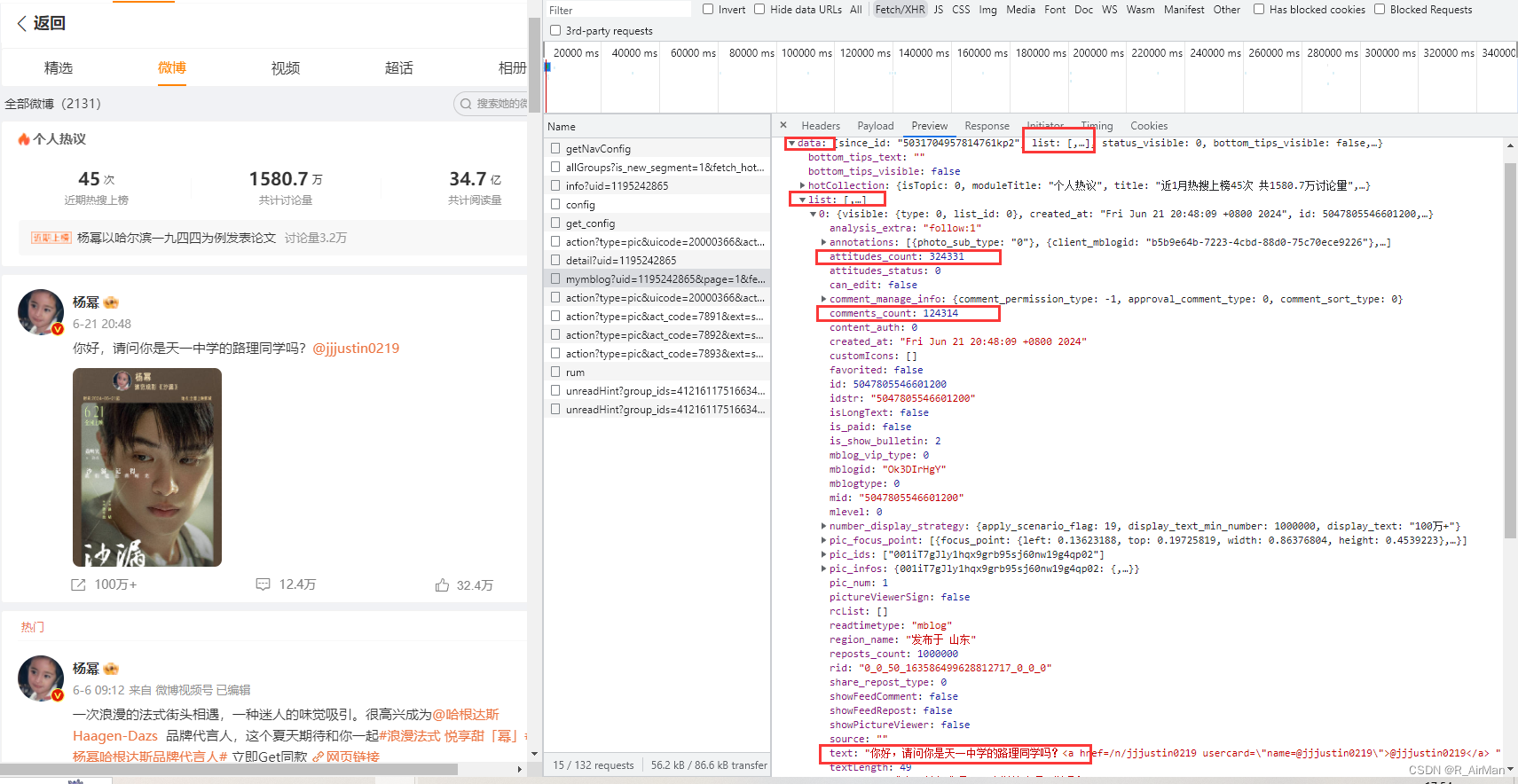
③ preview会将response的内容格式化,利于查看。可以发现,该xhr文件是一个data字典,里面包含了此次的目标内容。
3.分析响应
① 我们继续分析响应,发现返回内容是application/json, text/plain, */*,但是我们只需要筛选出来的xhr类型,也就是json文件内容。所以请求头我们需要设置Accept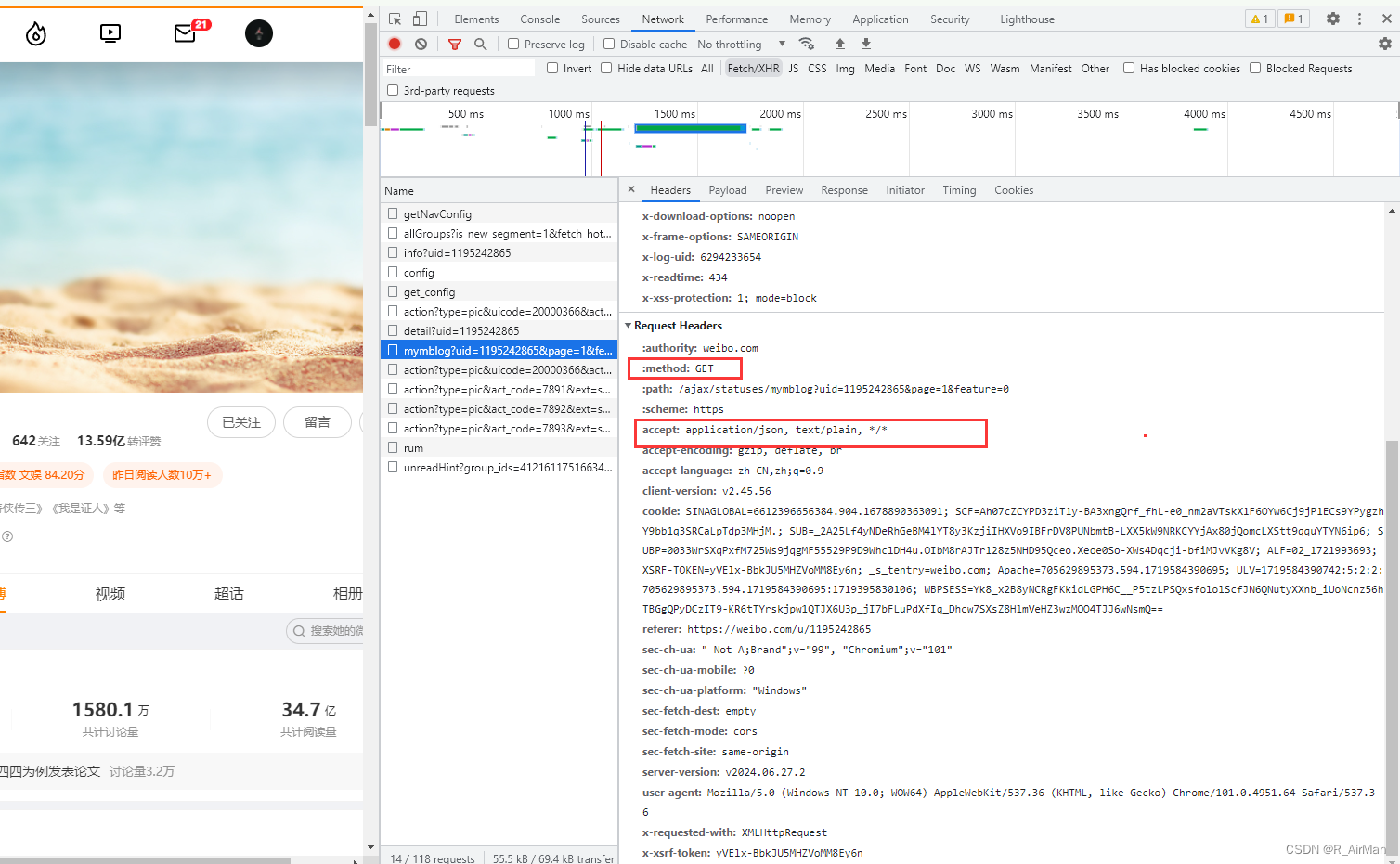
② 我们滑动页面向下(直至出现下拉加载页面),发现多了很多mymblog文件
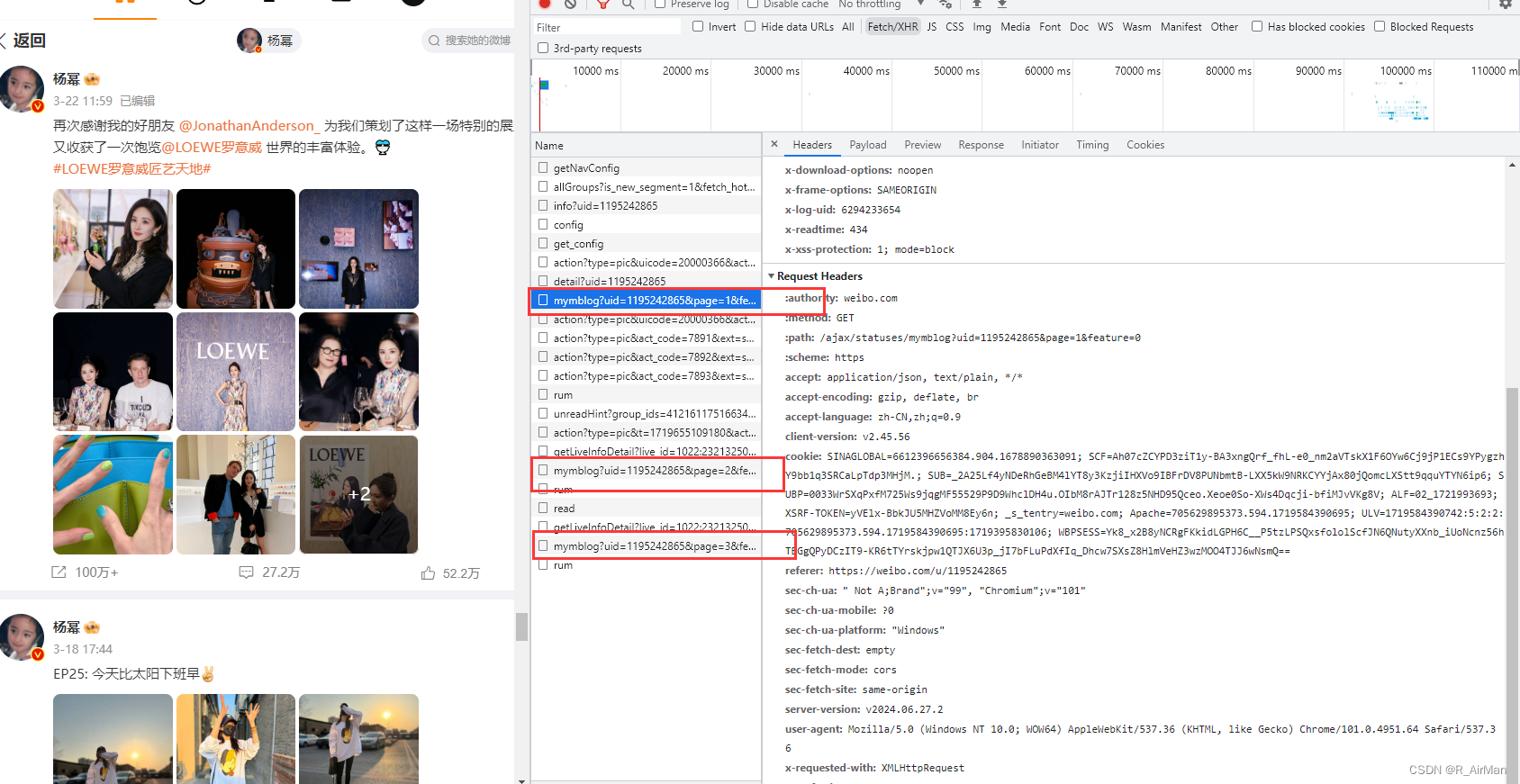
③ 进一步分析其url,发现url其实是由page来决定显示多少条微博的,每一list里面都存放了20条微博数据
![]()
![]()
![]()
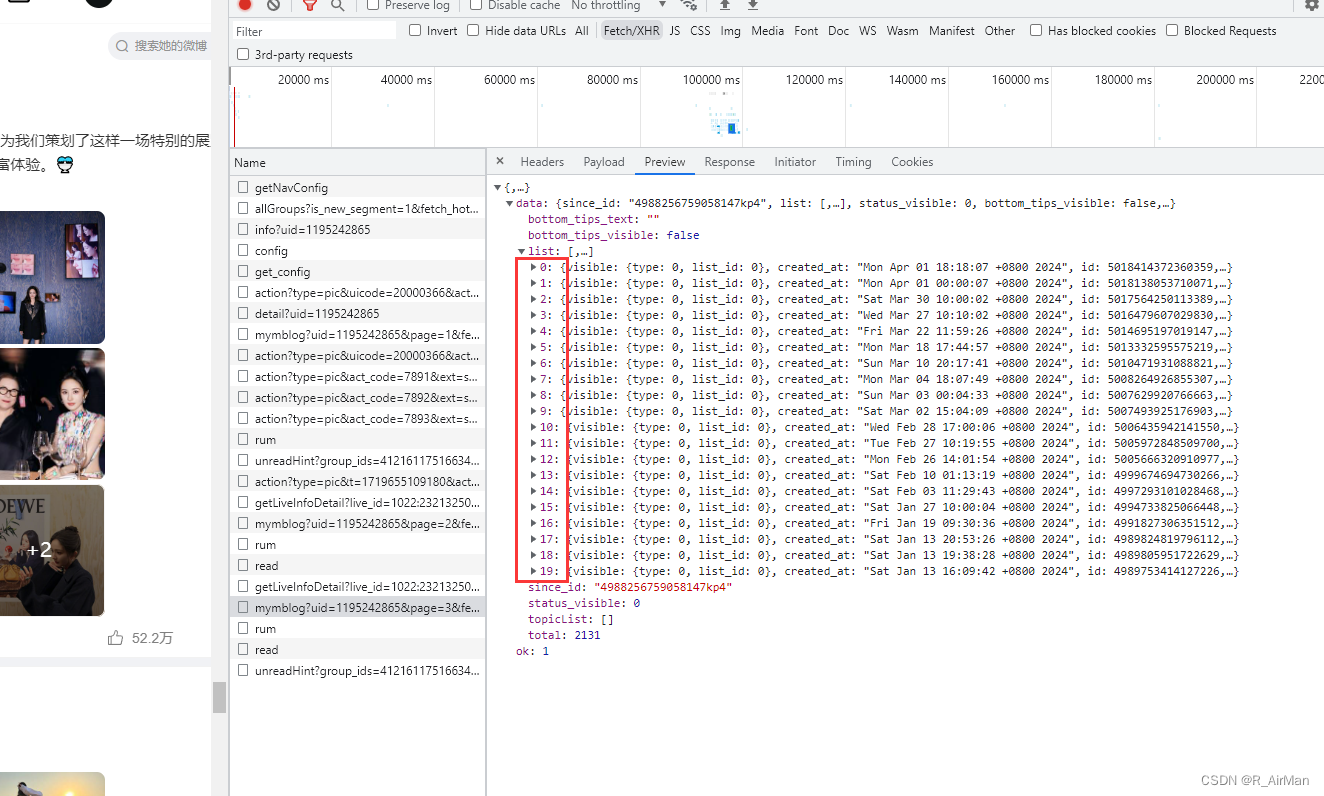
④ 最后整合思路:利用Request URL的规律构造最终url --> 采取get请求并且添加Accpet为json类型(因为我们想获取的数据就是一个json字典) --> 利用字典的方法提取数据即可 --> 保存数据至MySql数据库中
3.完整代码
import requests
import pymysql
import math
url = 'https://weibo.com/ajax/statuses/mymblog?uid=1195242865&page={page}&feature=0'
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36',
'Accept': 'application/json'
'cookie':'SINAGLOBAL=6612396656384.904.1678890363091; SCF=Ah07cZCYPD3ziT1y-BA3xngQrf_fhL-e0_nm2aVTskX1F6OYw6Cj9jP1ECs9YPygzhY9bb1q3SRCaLpTdp3MHjM.; XSRF-TOKEN=yVElx-BbkJU5MHZVoMM8Ey6n; _s_tentry=weibo.com; Apache=705629895373.594.1719584390695; ULV=1719584390742:5:2:2:705629895373.594.1719584390695:1719395830106; SUBP=0033WrSXqPxfM72wWs9jqgMF55529P9D9WhclDH4u.OIbM8rAJTr128z5JpVF02N1hB01h24e0B4; SUB=_2AkMRI1FjdcPxrAVTkfwXz2jkaYlH-jyi9jiVAn7uJhMyAxh87mglqSVutBF-XG7gIeZ3FvChi7-2MLihIH4BmdnP; WBPSESS=Dt2hbAUaXfkVprjyrAZT_Nwg9OgWrNgORcosnibGyT40gePTDd6KA1S2msZYoXC9RjJrTJpipifQgPfifnt4_BUJg23wrL88M1w5Oi_r2EaTxMfsz-J3aVRhXr7zj6o-KrXKbVzMap0OkqQhC7UhDg=='
}
db = pymysql.connect(host='localhost',user='root',password='123456',port=3306)
cursor = db.cursor()
cursor.execute('use spiders')
print('数据库连接成功!')
# 构造request url
def scrape_api(page):
Json_url = url.format(page=page)
print(f'现在开始爬取:{Json_url}')
return Json_url
# 从json字典中提取数据
def get_data(url):
response = requests.get(url=url, headers=headers)
data = []
if response.status_code == 200:
content = response.json()
text = content['data']['list']
for i in range(len(text)):
current_list = text[i]
one_data = {
'微博内容':current_list.get('text_raw'),
'评论数':current_list.get('comments_count'),
'点赞数':current_list.get('attitudes_count'),
'转发数':current_list['number_display_strategy'].get('display_text')
}
data.append(one_data)
else:
print("status不为200!")
return data
# 存放数据至MySql中
def save_data(data):
sql = "insert into weibo(content,comments_count,attitudes_count,display_text) values (%s, %s, %s, %s)"
for i in range(len(data)):
wait_insert_data = (
data[i].get('微博内容')[:1000],
data[i].get('评论数'),
data[i].get('点赞数'),
data[i].get('转发数'),
)
try:
cursor.execute(sql, wait_insert_data)
db.commit()
except Exception as e:
print(f'数据存储失败,原因是:{e}')
def main():
page_number = math.ceil( int(input('你需要爬取多少条微博:')) / 20 )
for i in range(1,page_number+1):
Json_url = scrape_api(i)
data = get_data(Json_url)
if data:
print(f'爬取完成{i * 20}条微博')
save_data(data)
else:
break
db.close()
if __name__ == '__main__':
main()

















 549
549

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









