






目前这篇论文有些地方还看不太懂,我先标注出来,后续理解了再补上。
标题:Federated Learning with Only Positive Labels
来源:[2004.10342] Federated Learning with Only Positive Labels (arxiv.org)

目录
1.5 Federated learning of a classifification model
1、前言介绍
1.1 什么是正/负样本
数据样本,对于mnist数据集而言,样本就是一张手写数字识别图片。其中样本对应的标签为:0、1、2、3、4、5、6、7、8、9这十种类别。比如我们的设备中只有1的手写数字图片,我们期望识别的结果也为1,此时的正样本即为标签为1的手写数字图片,而其他的图片全部被称为负样本.
1.2什么是embedding
embedding直译为“嵌入式”,但在机器学习中其表达是一种映射关系(本人理解)表示将高维数据通过矩阵映射为低维数据。在本文中𝑔𝜃(𝑥):x→𝑅^𝑑将实例X映射到一个d维嵌入,而𝑊∈𝑅^𝐶×d使用这个嵌入来生成C类的评分函数f(x)。(其实就是利用矩阵乘法,W为一个C行d列的矩阵,𝑔𝜃(𝑥)为一个d行1列的矩阵,两者相乘为fx=W𝑔𝜃(𝑥))
嵌入法embedding是一种让算法自己决定使用哪些特征的方法,即特征选择和算法训练同时进行 先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据权值系数从大到小选择特征。这些权值系数往往代表了特征对于模型的某种贡献或某种重要性。
1.3对于单样本学习的理解
单样本学习的案例场景:学习一个分类模型,其中每个用户只能访问单个类。例如:包括人脸识别模型或说话人识别模型的分散训练,其中除了用户特定的人脸图像和语音样本外,用户的分类器还构成了不能与其他用户共享的敏感信息。
1.4传统损失函数的缺点
如果我们使用普通的联邦学习方法,我们本质上是最小化一个损失函数,该函数只鼓励实例和嵌入空间中的正类之间的小距离。因此,这种方法将导致一个简单的最优解,其中所有实例和类都崩溃到嵌入空间中的单个点。(红字为原文翻译,这儿不太理解什么叫奔溃到单个点?看到的大神可以解释一下*-*)本人理解为损失函数会将结果刻意的往正样本训练的预期结果走。也就是给出的样本手写图片为形形色色的1,训练的结果总是1.
1.5 Federated learning of a classifification model
在本篇论文第三部分中,介绍了联邦学习中的分类器。由𝑊∈𝑅^𝐶×d与𝑔𝜃(𝑥):x→𝑅^𝑑的乘积定义的评分函数f(x):
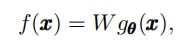
损失函数𝐥𝐨𝐬𝐬(𝐟(𝐱),𝐲)用于测量对于实例与标签对(𝒙,𝒚)上评分函数𝑓(𝑥)的质量,被定义为:
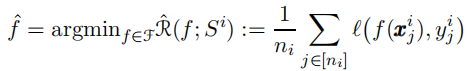
更新的参数为:θ、W模型参数
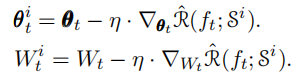
服务器端平均聚合θ与W:
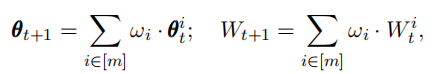
传统的损失函数会出现:
(1)嵌入向量𝑔𝜃(𝑥)𝑗𝑖与正样本类特征class embeddingW𝑗𝑖很相似,故需要不断的缩小距离。
(2)嵌入向量𝑔𝜃(𝑥)𝑗𝑖与正样本类特征class embeddingW𝑐差很多,不需要不断的拉大不同类之间的距离。
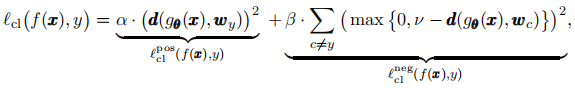
上式的损失函数优化分为正样本和负样本优化,但在本论文里,只有前面一项,即正样本优化。
2、FedAWS
继上,在没有负样本时的loss函数为:
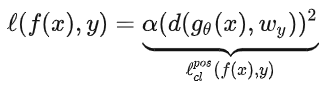


为了让不同的类别具有区分性,文中提出一种几何正则化,使得不同的类别W之间的距离不小于V:
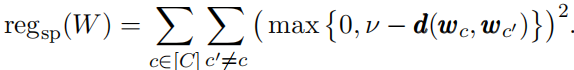
当C很大时(也称为极端多类分类设置),即使计算读程正则化器也会变得困难。为此reg_sp进行以下修改:
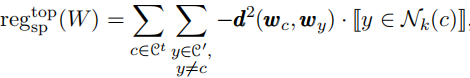
其中C' 是类的子集,Nk (c)表示在嵌入空间中最接近类c的k个类的集合。看作是上面式子中的读出正则化器的自适应逼近器。对于每个类c,我们自适应地将ν设置为Wc和它的第k+1最近的类嵌入之间的距离。我们只需要确保,在嵌入空间中,每个类都尽可能地远离它的封闭类。
算法步骤:

这儿需要注意的点:
服务器会将局部训练的Wc接收后拼接为一个Wt+1的矩阵,再将加入reg_sp正则化将W中包含的C类尽可能分开。
在服务器下发W^T时,不会吧矩阵W一股脑发给每个client。而是会把W每行发给对应的每个client。
3、结论
FedAWS其想法是在服务器端施加几何正则化,使所有类嵌入扩展。还注意到负采样技术对于使传统的极端多类分类工作至关重要。
本人理解:本文重点就是在正样本学习下如何处理缺乏负样本监督的问题,本文的做法是在服务器聚合过程中引入一个新的正则化项,将各类的距离拉远以抵御在单类学习中损失函数奔溃的一个点的“缺点”。

















 1229
1229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









