







 本文详细介绍了Python中的类装饰器、迭代器和生成器的相关概念与用法,包括@classmethod与@staticmethod的差异、迭代器协议、生成器的实现方式、for循环的工作原理以及深拷贝与浅拷贝的区别。同时,文章讨论了装饰器的实现,特别是类装饰器的使用,以及cls和self的区别。
本文详细介绍了Python中的类装饰器、迭代器和生成器的相关概念与用法,包括@classmethod与@staticmethod的差异、迭代器协议、生成器的实现方式、for循环的工作原理以及深拷贝与浅拷贝的区别。同时,文章讨论了装饰器的实现,特别是类装饰器的使用,以及cls和self的区别。
文章目录
python中的@classmethood与@staticmethod
1.classmethood()
简单来说:@classmethood的作用就是“可以不需要实力化,直接通过类名.方法名()来调用”。
具体来说:@classmethood的作用实际是可以在class内实力化class,作用就是比如输入的数据需要清洗一遍再实力化,可以把清洗函数定义在class内部加上@classmethood装饰器已达到减少代码的目的,换句话说就是,可以用来为一个类创建一些预处理的实例。
2.staticmethod()
该方法不强制要求传递参数,实现实例化使用 C().f(),当然也可以不实例化调用该方法 C.f()
迭代器

什么是迭代器
如果你的某个对象可以用for循环去遍历出里面的所有的值,那么他就可以作为迭代器。当然你也可以使用collections库里面的Iterable,使用isinstance([],Iterable)判断该对象是否是迭代
from collections import Iterable# 输出true为可迭代,false为不可迭代对象
b = [1.2, 3, 3, 6, ]
print(isinstance(b, Iterable))
可迭代对象的本质
分析:对可迭代对象进行迭代使用的过程,每迭代一次(即在for…in…中每循环一次)都会返回对象中的下一条数据,一直向后读取数据直到迭代了所有数据后结束。那么,在这个过程中就应该有一个“人”去记录每次访问到了第几条数据,以便每次迭代都可以返回下一条数据。我们把这个能帮助我们进行数据迭代的“人”称为迭代器(Iterator)
类中如何实现迭代器
首先我们要理解迭代器,迭代器就是能够使用循环的方式,获取你对象中的所有值。例如再python中list、tuple、str类型都可以称为可迭代对象。可迭代对过程其实也很简单,我们用list举个栗子
# 创建一个对象
lists = list[1,2,3,4,5,6]
# 创建一个索引值
index = 0
# 遍历对象内的所有值,被称为迭代过程
while True:
print(list[index])
index += 1
那么如果在类中我们是否可以这样实现
from collections import Iterable
class TestIterable:
def __init__(self):
self.lists = [1, 2, 3, 4, 5, 6]
self.index = -1
def __iter__(self):
return self
def __next__(self):
self.index += 1
if self.index < len(self.lists):
return self.lists[self.index]
else:
raise
StopIterations = TestIterable()
print(isinstance(s, Iterable))
for i in s:
print(i)
现在开始解释为什么要这样实现:
首先在迭代器使用过程中,类的方法里面有默认的魔术方法 __iter__和__next__两种。
__iter__表示让对象变为可迭代对象,然后他的返回值要是一个迭代器,你自身拥有__iter__方法。所以他就是一个迭代器,我们只需要返回他自身即可。
__next__对象是对访问对象的值,每次迭代过程都会获取__next__的值。所以我们把需要迭代的值,用index去控制他的索引位置。那么我们就可以是这个类变为可迭代的对象。当然你也可以试过之后尝试,使用__next__返回其他的类,这样或有意想不到的结果。最后万物皆对象。
1、迭代器协议 有next方法 一直直到StopIteration终止 (只能往前走不能后退)
2.可迭代对象 遵行迭代器协议的对象就称之为可迭代对象 转换成可迭代对象:iter方法
# Python中字符串 列表 元组 字典 集合 文件都不是可迭代对象,但是可以转换成可迭代对象iter
l = [1, 2, 3]
iter_l = l.__iter__()
print(iter_l.__next__())
print(iter_l.__next__())
print(iter_l.__next__())
print(iter_l.__next__())
print(next(iter_l))
# iter()函数介绍:生成一个迭代器对象
#iter()函数用法:iter(iterable)
#next()函数介绍:返回迭代器中的数据
#next()函数用法:next(iterable)
iter_obj = iter([1,2,3])
next(iter_obj)
# test_list 实际上是一个列表,但是被迭代器迭代之后。并不是一次性将列表放入内存中,而是每次放一个元素进入内存,然后被读取。(这就是我们说的按需加载)
可迭代对象
类似于list、tuple、str 等类型的数据可以使用for… in… 的循环遍历语法可以从其中依次拿到数据并进行使用,我们把这个过程称为遍历,也称迭代。python中可迭代的对象有list(列表)、tuple(元组)、dirt(字典)、str(字符串)set(集合)等。
生成迭代器(也就是生成器generator)
除了刚刚我们使用的 iter() 函数之外 ,我们还有其他方法生成迭代器:
第一种:for循环生成方法 —> 我们可以在函数中使用 for 循环, 并对每一个 for 循环的成员使用 yield() 函数 [它的意思就是将每一个 for 循环成员放到一个迭代器对象中,不过只有被调用才会被放入。]
def test():
for i in range(10):
yield i
result = test()
print('for 循环,第一次 \'i\'的值为:', next(result))
print('for 循环,第二次 \'i\'的值为:', next(result))
print('for 循环,第三次 \'i\'的值为:', next(result))
print('for 循环,第四次 \'i\'的值为:', next(result))
# >>> 执行结果如下:
# >>> for 循环,第一次 'i'的值为: 0
# >>> for 循环,第二次 'i'的值为: 1
# >>> for 循环,第三次 'i'的值为: 2
# >>> for 循环,第四次 'i'的值为: 3
#注意:超过10次异常会抛 StopIteration 的异常。
第二种:for 循环一行生成迭代器对象
result = (i for i in [1, 2, 3]) # 将 for 循环在非函数中 赋值 给一个变量, 这也是生成一个迭代器变量的方法
print('for 循环,第一次 \'i\'的值为:', next(result)) # 使用 next 调用迭代器
print('for 循环,第二次 \'i\'的值为:', next(result))
print('for 循环,第三次 \'i\'的值为:', next(result))
# >>> for 循环,第一次 'i'的值为: 1
# >>> for 循环,第二次 'i'的值为: 2
# >>> for 循环,第三次 'i'的值为: 3
使用 for 循环生成的迭代器,可以不使用 next() 函数 也可以执行,(依然可以通过 for 循环
获取迭代器的数据)不仅如此,当我们调取完迭代器中的数据之后,程序不会抛出异常,相比较与 next() 函数要友好的多
def make_iter():
for i in range(5):
yield i
iter_obj = make_iter()
for i in iter_obj:
print(i)
print('----')
for i in iter_obj:
print(i)
# >>> 执行结果如下:
# >>> 0
# >>> 1
# >>> 2
# >>> 3
# >>> 4
# >>> ----
# >>> 从运行结果得出结论,当我们从内存中读取完迭代器所有的值后,内存就会被释放,不再循环输出。
Python中for循环强大的机制
for运行机制就是
1.iter 2.next 3.捕捉StopIteration(停止迭代)
为什么要有for循环
如果说字符串 列表 元组有序的while也可以实现,但是对于无序的类型呢?只有通过for循环当然有序同样能够进行操作
for循环列表字典等,并不是真正的for循环列表本身。而是for循环他们返回的一个迭代器对象
生成器(可迭代对象)
原文:https://blog.youkuaiyun.com/weixin_44706915/article/details/116702292
生成器仅仅保存了一套生成数值的算法,并且没有让这个算法现在就开始执行,而是我什么时候调它,它什么时候开始计算一个新的值,并给你返回
1.生成器本身是一种特殊的迭代器,也就是说生成器就是迭代器。
2.生成器会自动实现迭代器协议,也就是说只要我们yield后,自动就生成了next对象包括StopIteration等结构。
3.生成器使用yield语句返回一个值。yield语句挂起该生成器函数的状态,保留足够的信息。对生成器函数的第二次(或第n次)调用,跳转到函数上一次挂起的位置。生成器不仅“记住”了它的数据状态,生成还记住了程序执行的位置。
1.特征
1.自动实现迭代器协议 不再调用iter方法二是使用for循环
2.表现形式 函数式yield 生成器表达式(类似列表推导式),
def test():
yield 1
yield 2
yield 3
g = test()
print(g)
print(g.__next__())
print(g.__next__())
print(g.__next__())
2.三元表达式、列表解析
name = 'eric'
res = 'sb' if name == 'eric' else 'shuai'
print(res)
l = [i for i in range(10)]
print(l)
生成器和迭代器的区别
1.迭代器是访问容器的一种方式,也就是说容器已经出现。我们是从已有元素拓印出一份副本,只为我们此次迭代使用。而生成器则是,而生成器则是自己生成元素的。也就是前者是从有到有的复制,而后者则是从无到有的生成。
yield关键字
yield相当于return 控制函数的返回值
x = yield的另外一个特性 接收send传过来的值,赋值给x, .send() 和next()一样,都能让生成器继续往下走一步(下次遇到yield停),但send()能传一个值,这个值作为yield表达式整体的结果
yield 的作用就是把一个函数变成一个 generator,带有 yield 的函数不再是一个普通函数,Python 解释器会将其视为一个 generator,
装饰器
本质就是函数,为其它函数添加新的功能
把握两原则:不修改被修饰函数的源代码 不修改被修饰函数的调用方式
装饰器=高阶函数+函数嵌套+闭包
1、高阶函数:传入参数函数名: 为被修饰函数增加功能但是改变了调用方式
返回值函数名:不修改函数的调用的方式
把上边两个方式结合起来就实现装饰器了
import time
def foo():
time.sleep(1)
print('from foo')
def timer(func):
"""
传入参数函数名
:param func:
:return:
"""
start_time = time.time()
func()
stop_time = time.time()
print('函数的运行时间%s' %(stop_time-start_time))
timer(foo) # 违背函数调用方式
def timer(func):
"""
from foo
函数运行的时间1.0009970664978027
from foo 这样确实能够统计出foo运行的时间,调用方式也没改变 但是多执行一次foo函数
:param func:
:return:
"""
start_time = time.time()
func()
stop_time = time.time()
print('函数运行的时间%s' %(stop_time-start_time))
return func
foo = timer(foo)
foo()
2、函数嵌套
def father(name):
# print('from father %s' %name)
def son():
# print('我的爸爸是%s' %name)
def grandson():
print('我的爷爷是%s' %name)
grandson()
son()
father('Mr.Wei')
3. 闭包:作用域的一种表现
类的装饰器实现
上面咱们一起学习了怎么写装饰器函数,在python中,其实也可以同类来实现装饰器的功能,称之为类装饰器。类装饰器的实现是调用了类里面的__call__函数。类装饰器的写法比我们装饰器函数的写法更加简单。
当我们将类作为一个装饰器,工作流程:
通过__init__()方法初始化类
通过__call__()方法调用真正的装饰方法
import time
class BaiyuDecorator:
def __init__(self, func):
self.func = func
print("执行类的__init__方法")
def __call__(self, *args, **kwargs):
print('进入__call__函数')
t1 = time.time()
self.func(*args, **kwargs)
print("执行时间为:", time.time() - t1)
@BaiyuDecorator
def baiyu():
print("我是攻城狮白玉")
time.sleep(2)
def python_blog_list():
time.sleep(5)
print('''【Python】爬虫实战,零基础初试爬虫下载图片(附源码和分析过程)
https://blog.youkuaiyun.com/zhh763984017/article/details/119063252 ''')
print('''【Python】除了多线程和多进程,你还要会协程
https://blog.youkuaiyun.com/zhh763984017/article/details/118958668 ''')
print('''【Python】爬虫提速小技巧,多线程与多进程(附源码示例)
https://blog.youkuaiyun.com/zhh763984017/article/details/118773313 ''')
print('''【Python】爬虫解析利器Xpath,由浅入深快速掌握(附源码例子)
https://blog.youkuaiyun.com/zhh763984017/article/details/118634945 ''')
@BaiyuDecorator
def blog(name):
print('进入blog函数')
name()
print('我的博客是 https://blog.youkuaiyun.com/zhh763984017')
if __name__ == '__main__':
baiyu()
print('--------------')
blog(python_blog_list)
参数的类装饰器
当装饰器有参数的时候,init() 函数就不能传入func(func代表要装饰的函数)了,而func是在__call__函数调用的时候传入的
class BaiyuDecorator:
def __init__(self, arg1, arg2): # init()方法里面的参数都是装饰器的参数
print('执行类Decorator的__init__()方法')
self.arg1 = arg1
self.arg2 = arg2
def __call__(self, func): # 因为装饰器带了参数,所以接收传入函数变量的位置是这里
print('执行类Decorator的__call__()方法')
def baiyu_warp(*args): # 这里装饰器的函数名字可以随便命名,只要跟return的函数名相同即可
print('执行wrap()')
print('装饰器参数:', self.arg1, self.arg2)
print('执行' + func.__name__ + '()')
func(*args)
print(func.__name__ + '()执行完毕')
return baiyu_warp
@BaiyuDecorator('Hello', 'Baiyu')
def example(a1, a2, a3):
print('传入example()的参数:', a1, a2, a3)
if __name__ == '__main__':
print('准备调用example()')
example('Baiyu', 'Happy', 'Coder')
print('测试代码执行完毕')
装饰器的执行顺序是由里到外
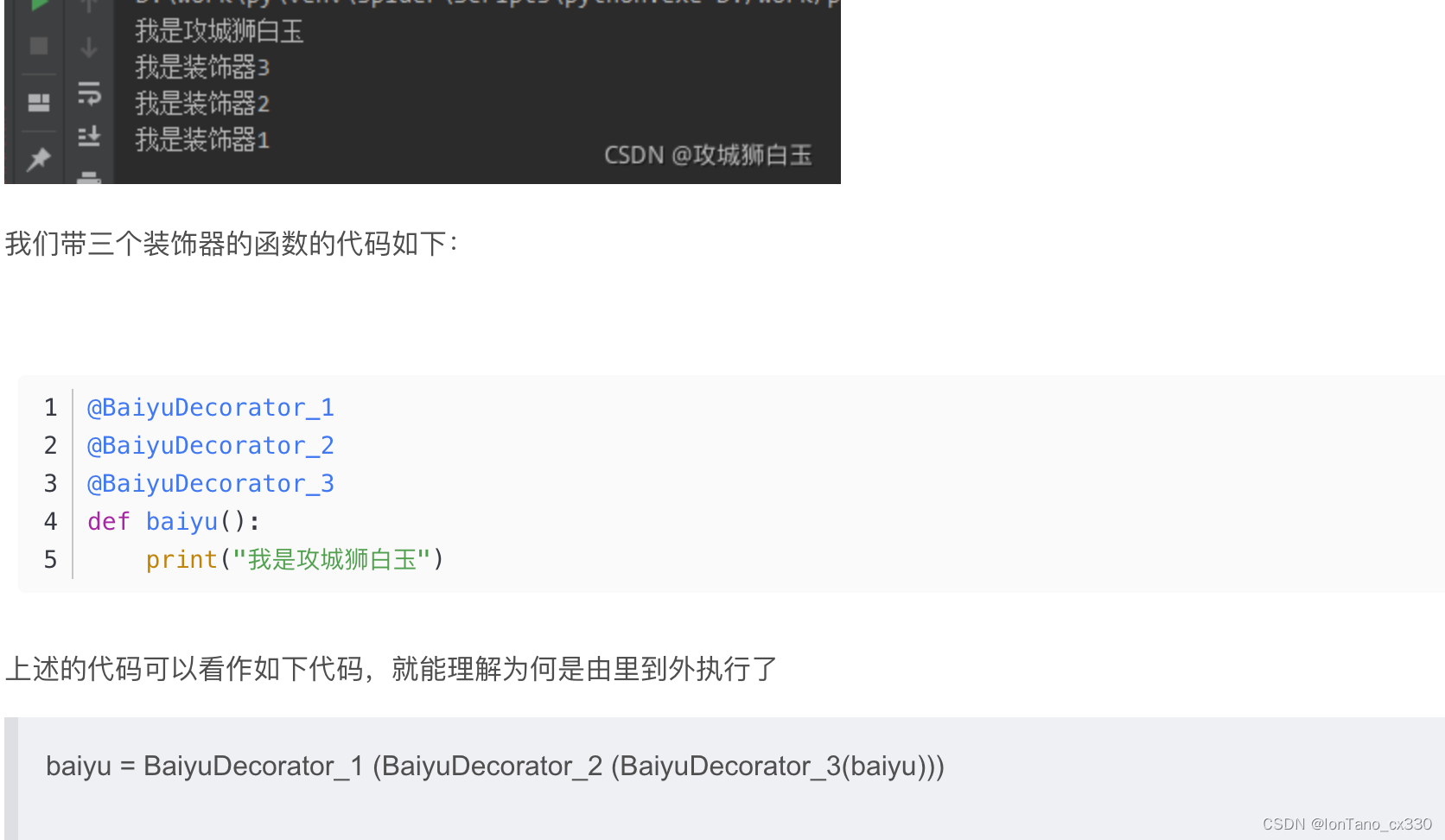
cls和self的区别
class Web():
name = 'Testclsname'
def uname(self):
print ("self:",self)
@classmethod
def public(cls):
cls.age = 18
print ("cls:",cls)
#############调用对应的方法和类变量#############
#实例化web类
web = Web()
#实例调用方法uname
web.uname()
#Web类直接调用修饰器方法
Web.public()
#调用类变量
print (Web.name)
#############################结果打印#############################
/opt/homebrew/bin/python3.9 /Users/dfg/Desktop/YuanMirror/yy.py
self: <__main__.Web object at 0x103753fa0>
cls: <class '__main__.Web'>
Testclsname
从上面结果可以得出:
- web类进行实例化后才能进行方法的调用,所以self代表的是实例本身(uname方法),并且self返回内存地址
- Web类直接调用方法(public),被classmethod修饰后的public方法传入的cls为类本身,并且cls打印为类名
- 类变量可以直接使用类名进行调用
深拷贝 浅拷贝
浅:两个变量之间指向同一个内存地址
b = a
深:两个变量指向不同的内存地址
import copy
b = copy.deepcopy(a) # 递归copy
b = a.copy.copy(a) 不递归copy,如下图
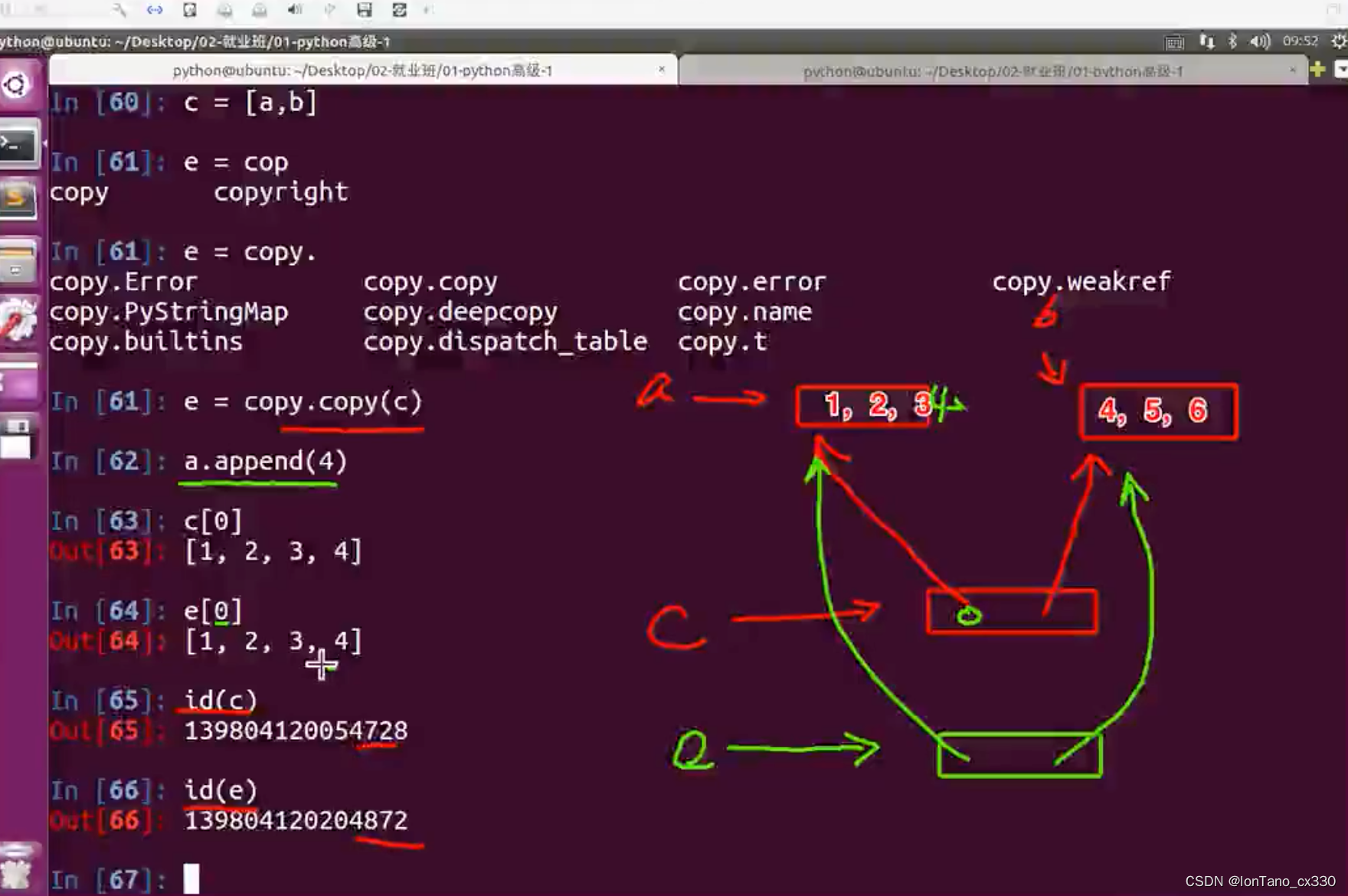
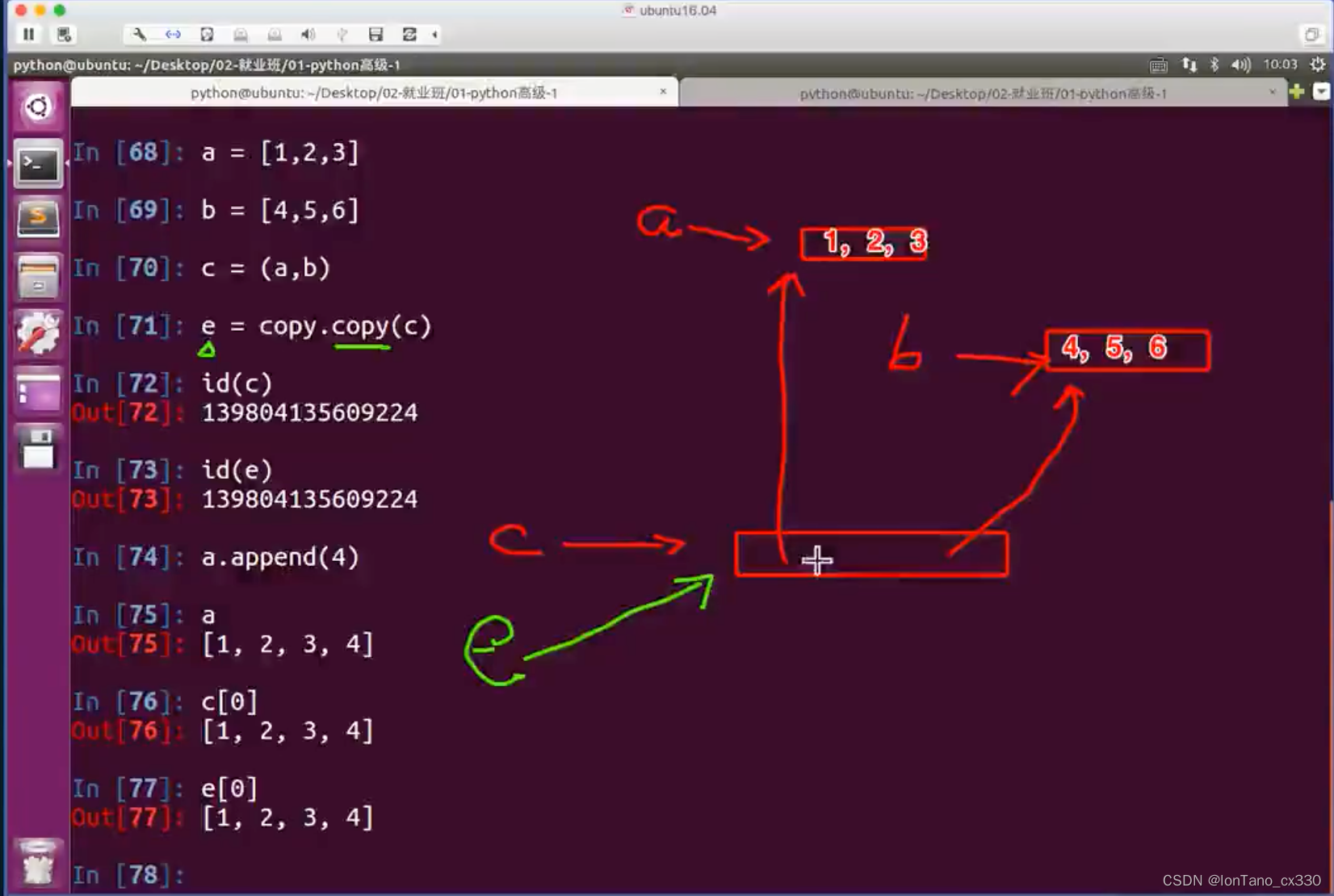
但是 当copy.copy指向的是一个不可变类型时(比如元组),其实相当于浅拷贝


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









