









🕶️师兄简介:机械专业,通过自学成功进入IT领域,求学期间实现经济独立,对自学、兼职、计算机、学习规划等有独到见解!「点击了解更多」
🤖师兄致力解决在大学生活与学习中遇到的各种问题.
🎁 公众号「渣师兄」内回复「渣学」可获得超 5T 的新生见面礼!
🔗官方网站: 渣学网 →「zhaxueit.cn」→ 大学生活与学习一站式解决方案.
🙏找师兄帮忙「无偿」请➕💓:zhaxueit
📓进资源群「每日分享」【免费】(坑位有限)也请➕💓:zhaxueit 并备注「进群」
👀个人主页:@渣师兄 ,欢迎关注、私信师兄!
🐐 登高必自卑,行远必自迩.
🍇 我始终坚信越努力越幸运
⭐️ 那些打不倒我们的终将会让我们变得强大
🍑 希望在编程道路上深耕的小伙伴都会越来越好
文章目录
Python内requests模块的使用
须知:一个网页右键检查(F12)所看到的代码是浏览器最终渲染完成的代码,它和网站服务器给你相应的源代码不一定相同,抓取数据的时候一定要以源代码为主,检查可以帮助你快速查找数据!!!
目标:
1:掌握 requests 模块的基本使用(获取url响应数据)
2:掌握 requests 模块响应对象一些基本属性
3:掌握 requests 模块响应对象的 json()方法作用
requests 模块的基本使用(获取url响应数据)
实现功能:向指定url发送请求(User-Agent经过包装)获取响应数据
语法:
1:res_obj = requests.get(url = url,headers = headers) →向目标url发送get请求,返回响应对象
html_data = res_obj.text →利用响应对象的text属性获取响应源代码
2:html_data = requests.get(url = url,headers = headers,timeout=3).text → 向目标url发送get请求,获取响应源代码
参数:
1.url:请求的目标url
2.headers:包装的请求标头信息
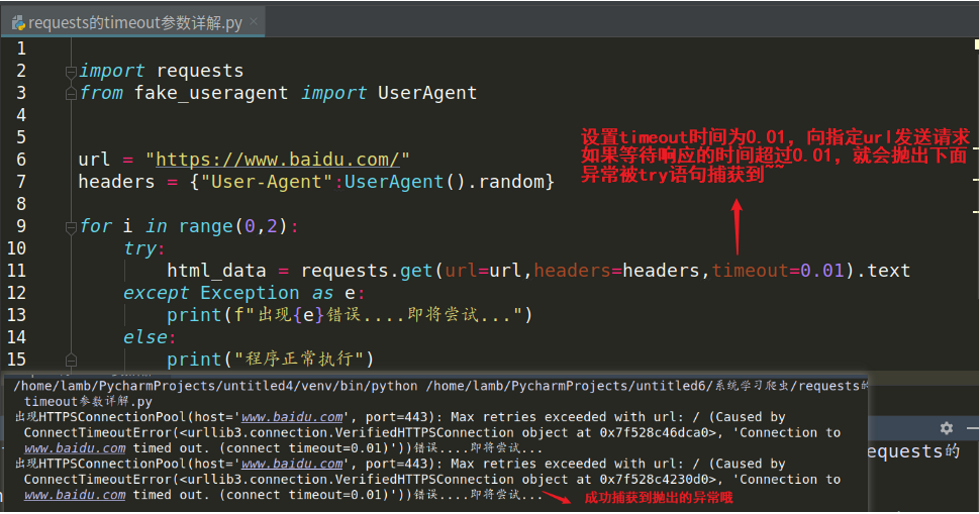
3.timeout:设置请求时间,如果向指定网站发送请求,等待的响应时间超过3秒,则抛出异常(可捕获用!)
注意事项:
1:在 requests 模块内的响应对象没有方法,全都是属性,例如 text 属性
2:requests 模块是第三方模块安装语法 pip3 install requests
3:响应对象的text属性获取的是字符串响应数据
截图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pAnolWv1-1638844758841)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20211013105030475.png)]
设置timeout参数抛出异常截图:
requests 模块响应对象一些基本属性
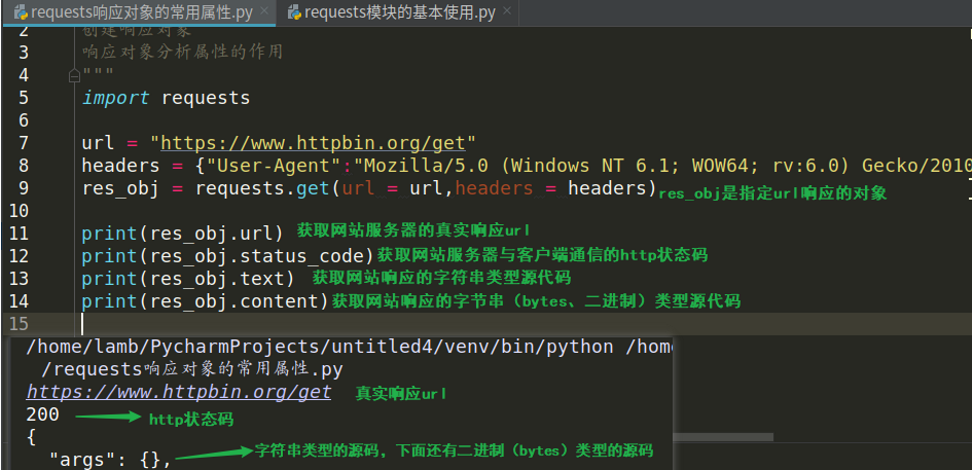
res_obj = requests.get(url = url,headers = headers) →创建指定url服务器的响应对象
下面是响应对象的一些常用属性
res_obj.text:获取指定url的响应源代码(字符串类型的)
res_obj.content:获取指定url的响应源代码(bytes类型的,也就是二进制的响应源代码)
res_obj.url:获取服务器响应数据的真实url地址
res_obj.status_code:获取客户端与服务端进行http通信的状态码
截图:
requests 模块响应对象的 json()方法作用
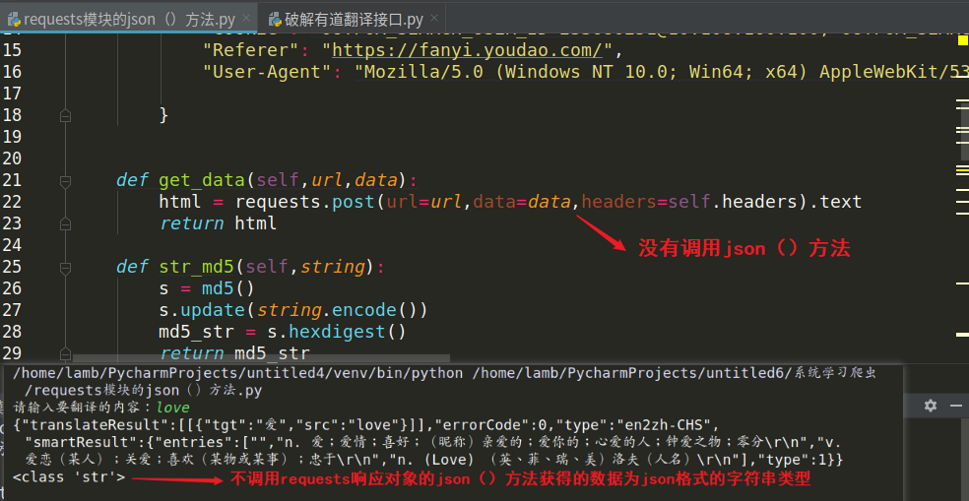
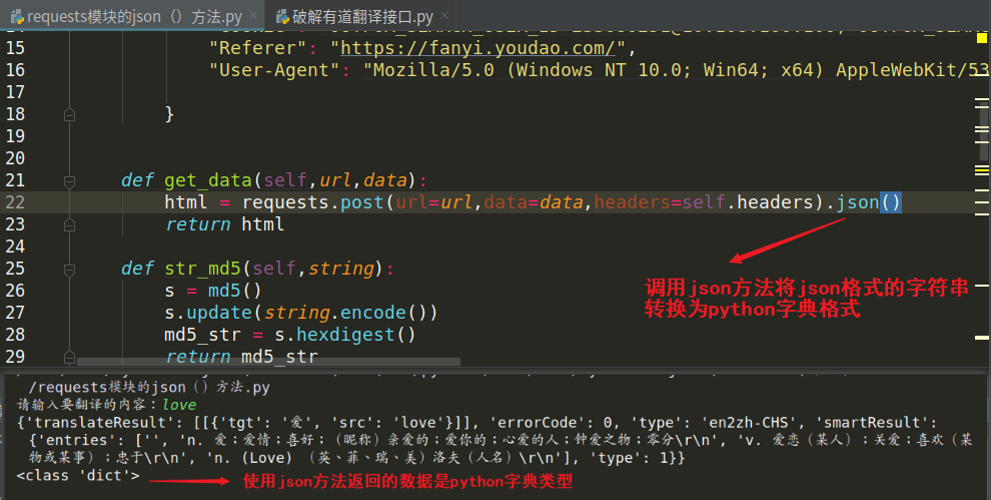
方法名:json()
语法:requests响应对象.json()
功能:将 json 格式的字符串【字典格式的字符串】转换为python格式的字典!
代码演示
不使用json()方法返回的数据类型
使用json()方法返回的数据类型
requests模块抓取图片、视频等【重点】
须知:一个网页右键检查(F12)所看到的代码是浏览器最终渲染完成的代码,它和网站服务器给你相应的源代码不一定相同,抓取数据的时候一定要以源代码为主,检查可以帮助你快速查找数据!!!
目标:
1:掌握抓取网站图片、视频的一些注意事项
2:掌握怎么利用 os 标准库判断一个路径是否存在以及怎么创建文件夹!
2:掌握利用 requests 模块抓取网站图片的步骤
抓取网站图片、视频的一些注意事项
图片、视频在计算机内的存储方式:图片、视频、音频均以二进制(bytes)数据的方式进行存储
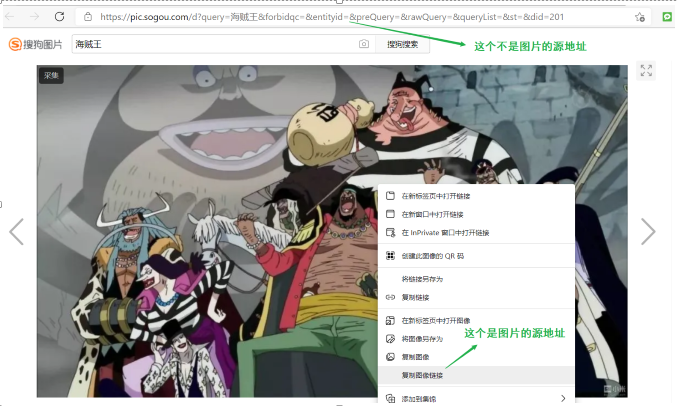
图片、视频等的 url 地址:图片、视频等文件的源url地址不是浏览器最上方的地址,而是在图片上右击选择复制图片源地址的地址
抓取注意事项:
1:因此在向图片、视频等 url 源地址发送请求获取源代码数据时,应该获取二进制(bytes)网页源代码
2:获取到二进制网页源代码后,保存文件时,只要是图片、视频等,都要以二进制的方式打开指定文件!!
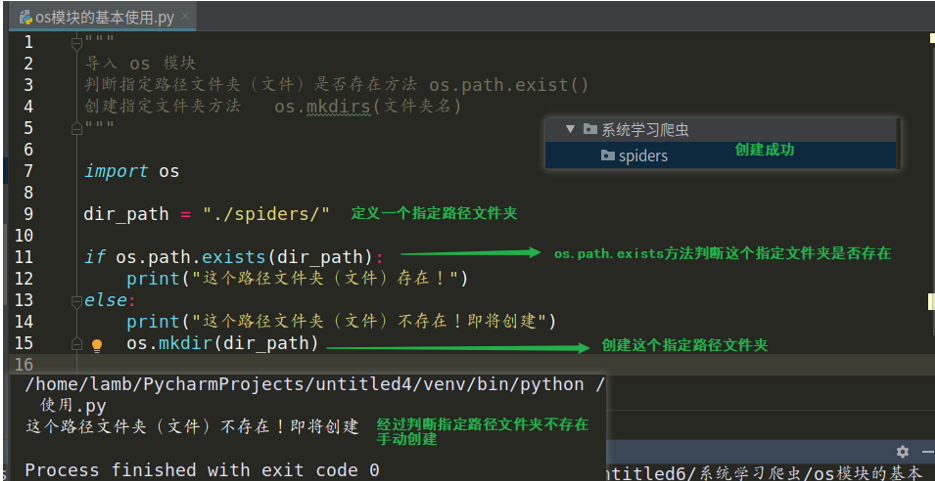
怎么利用 os 标准库判断一个路径是否存在以及怎么创建文件夹!
判断路径是否存在功能语法实现:
1.import os →导入模块
2.is_no = os.path.exists(指定路径文件夹或文件) →判断指定路径文件夹(文件)是否在计算机存在,是返回True,不在返回False
创建文件夹语法实现:
1.import os →导入模块
2.os.mkdir(文件夹名) →文件夹名可以是指定路径(绝对路径、相对路径)下的文件夹
代码演示:
利用 requests 模块抓取网站图片的步骤
第一步:找到图片的源地址(不是浏览器最上方的url)
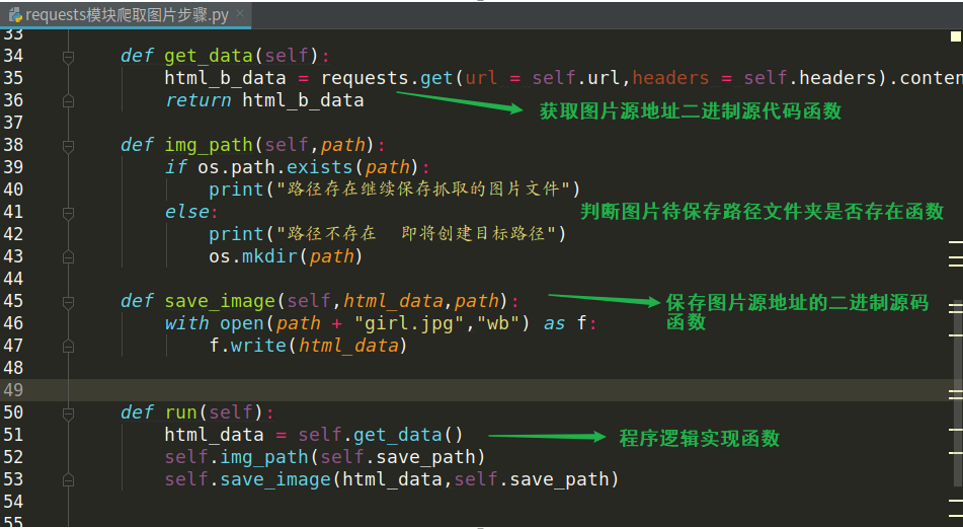
第二步:利用 requests 模块向图片源地址发送请求,获取二进制(bytes)类型的网页源代码
实现语法:
res_obj = requests.get(url=图片源地址,headers=包装的请求头) →创建图片源地址响应对象
html_b_data = res_obj.content →利用对象的content获取网页二进制源代码
第三步:利用 os 模块判断图片待保存的路径(文件夹)是否存在,不存在创建这个路径文件夹
实现语法:
if os.path.exists(图片待保存文件夹路径):
print(“路径存在”)
else:
print(“路径不存在即将创建”)
os.mkdir(图片待保存的文件夹路径)
第四步:根据自己的想法创建图片待保存的文件名,并且拼接图片待保存路径以及文件名
创建图片名实现语法:
1.根据图片源地址创建图片保存名称(源地址后缀必须是.jpg或者.png等): 图片源地址字符串 [ -10 : ] →获取图片源地址的最后10个字符串作为文件名
2:根据抓取的图片标题创建图片保存名称
3:单纯的遍历某个数字区间命名
拼接图片待保存路径以及文件名语法:带保存路径 + 图片带保存名
第五步:以二进制读写方法打开已经拼接好的的路径文件(不是路径文件夹)
实现语法:
with open (拼装好的路径文件,“wb”)as f :
f.wither(向图片源地址请求的二进制源代码)
实现代码截图(部分):



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











