







 本文探讨了Hive中通过设置 CombineHiveInputFormat 进行小文件合并来提升MapReduce任务执行效率的过程。在启用合并后,Map任务数量减少,而Reduce任务保持不变,从而优化了查询性能。反之,使用默认的HiveInputFormat会导致每个小文件分别触发一个Map任务,影响效率。
本文探讨了Hive中通过设置 CombineHiveInputFormat 进行小文件合并来提升MapReduce任务执行效率的过程。在启用合并后,Map任务数量减少,而Reduce任务保持不变,从而优化了查询性能。反之,使用默认的HiveInputFormat会导致每个小文件分别触发一个Map任务,影响效率。
1.数据准备
测试表
create table test(
field1 int,
field2 int,
field3 int
)
comment'小文件合并及排序测试表'
;
数据
insert into table test values(1,6,14);
insert into table test values(2,3,4);
insert into table test values(6,2,6);
insert into table test values(1,3,2);
insert into table test values(7,13,7);
insert into table test values(5,9,1);
insert into table test values(2,3,4);
insert into table test values(4,3,8);
insert into table test values(1,6,4);
insert into table test values(7,1,9);
insert into table test values(9,8,2);
insert into table test values(5,2,7);
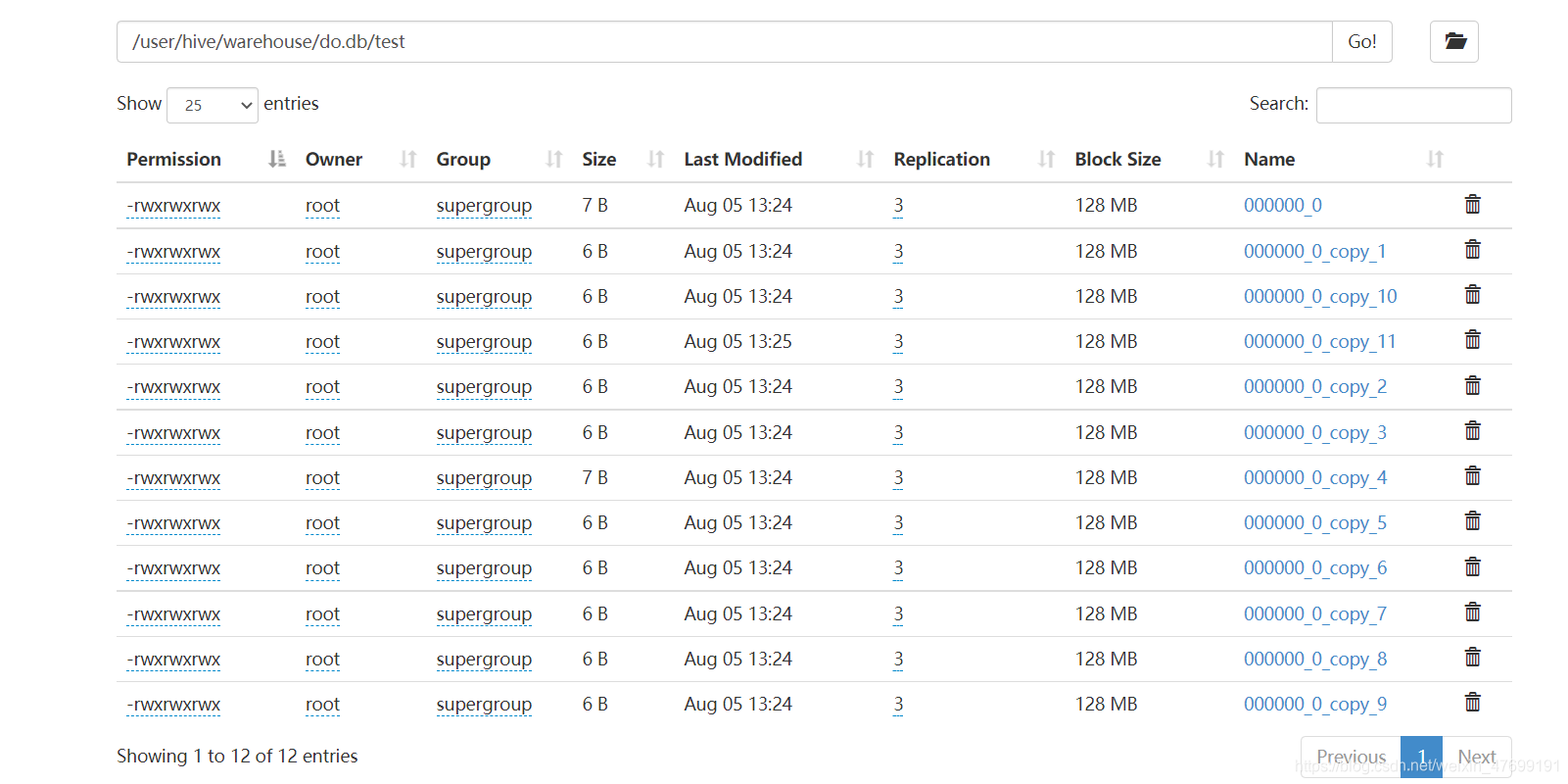
hdfs中表数据文件
表test 有12个小文件
2.小文件合并CombineHiveInputFormat
执行Map前进行小文件合并(默认)
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
reducetask的数量为2
set mapred.reduce.tasks=2;
执行sql
select * from test sort by field1;
job: 1
Map: 1 Reduce: 2

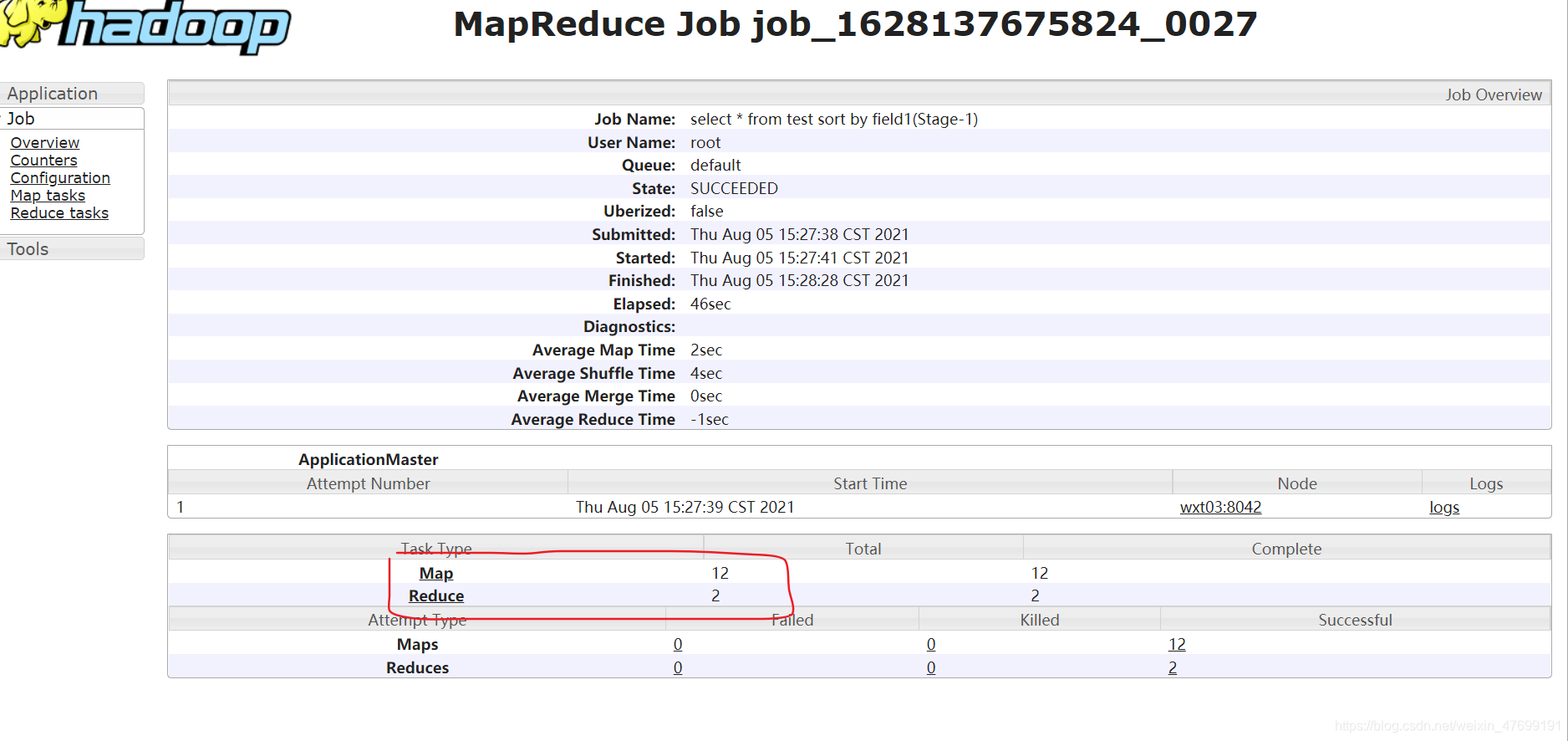
3.没有对小文件合并HiveInputFormat
– HiveInputFormat没有对小文件合并功能。
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
执行sql
select * from test sort by field1;
job: 1
Map: 12 Reduce: 2


















 5336
5336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









