






激活函数
概念
神经网络中的每个神经元节点接受上一层的输出值作为本神经元的输入值,并将输入值传递给下一层,输入层神经元节点会将输入属性值直接传递给下一层(隐层或输出层)。在多层神经网络中,上层节点的输出和下层节点的输入之间具有一个函数关系,这个函数称为激活函数。(也称激励函数)
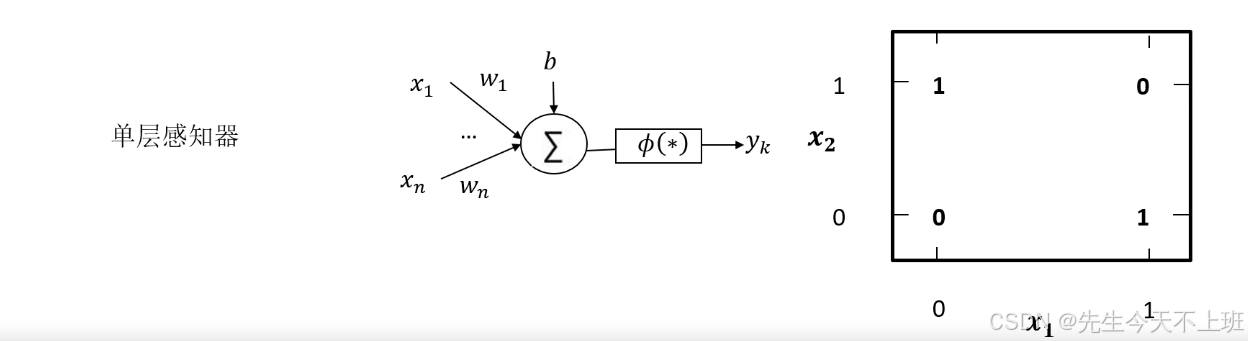
激活函数对神经网络影响
- 如果不运用激活函数,则输出信号只能是一个简单线性函数。线性函数的复杂性有限,从数据中学习复杂函数映射能力更小。激活函数相当于在神经网络中加入了非线性因素,使神经网络变成非线性模型。
o u t p u t = ϕ ( w 1 x 1 + w 2 x 2 + w 3 x 3 . . . ) = ϕ ( W T ⋅ X ) output = \phi(w_1x_1+w_2x_2+w_3x_3 ...)=\phi(W^T \cdot X) output=ϕ(w1x1+w2x2+w3x3...)=ϕ(WT⋅X)
常用激活函数
Sigmoid function
单调
f(x) =
损失函数 loss function
神经网络使用的代价函数称为损失函数。
损失函数衡量了预测与真实样本标签的距离。
Loss的值都会设置为预测值和真实值的温和成都负相关。如果算法公式是正相关,定义损失函数时候加负号,调整为负相关。
回归问题的损失函数为均方误差损失函数,分类问题选择交叉熵损失函数。
神经网络训练的过程是通过最小化在训练集上的损失函数进行 的。
均方误差损失函数
执行回归任务时,选择均方误差损失函数。
通过计算实际目标值和预测值之间的平方差的平均值来计算的。
L ( Y , f ( X ) ) = 1 n ( Y − f ( X ) ) 2 L(Y,f(X))=\frac 1n (Y -f(X))^2 L(Y,f(X))=n1(Y−f(X))2
交叉熵损失函数
相比于MSE,交叉熵损失在分类预测结果和真实结构相差很大时,有更大的梯度。更适合神经网络训练,损失函数公式如下:
C
E
=
−
∑
i
=
1
n
p
(
x
i
)
l
o
g
(
q
(
x
i
)
)
CE = -\sum_{i=1}^{n} p(x_i)log(q(x_i))
CE=−i=1∑np(xi)log(q(xi))
梯度下降
优化器
- 模型训练的目的是使损失函数 E ( W ) E(W) E(W)最小的权值向量W,希望从100等高线到0等高线位置。我们采用优化器工具。
- 在梯度下降算法中,有各种不同的改进版本。在面向对象的语言实现中,往往把不同的梯度下降算法封装成一个对象称为优化器。
- 常见的优化器如:普通梯度下降优化器、动量优化器、Nesterov、Adagrad、Adadelta、RMSProp、Adam、AdaMax、Nadam
梯度下降法
· 梯度下降 就是通过求损失值对所有参数的偏导(梯度),梯度的意义是变化最快的方向,因此可以沿着梯度的负方向更新所有参数。学习率 η \eta η (Learaning Rate ,LR)是梯度下降中重要的超参数,根据误差梯度调整权重数值的系数,通常记作 η \eta η。
w ′ = w − η ∗ ∂ L o s s ∂ w w' =w -\eta \ast \frac {\partial Loss} {\partial w} w′=w−η∗∂w∂Loss
根据批量大小,常用的梯度下降法有三中。
批量梯度下降(BGD):每次更新所有使用的训练数据,样本数量过多,更新速度会很慢。
随机梯度下降(SGD):每次更新的时候只考虑一个样本点,加快训练速度,函数不一定是朝着极小值方向更新,SGD对噪声更加敏感。
小批量梯度下降(MBGD): 每次更新会考虑一定数量的样本,解决了批量梯度下降法的训练速度慢问题,以及随机梯度下降对噪声敏感的问题。
梯度下降法的缺点
缺点:
- 没办法保证收敛性
- 学习率太低,收敛慢;学习率大,损失函数会在极小值处动荡甚至偏离。
- 容易陷在局部极小值处,或者鞍点处。
(不明白,如果学习率不同是否需要求均值)
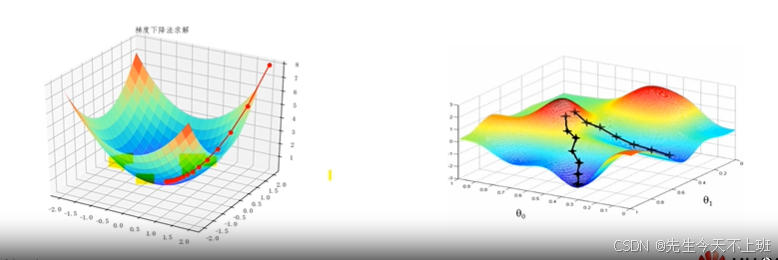
梯度下降优化器变种
动量优化器
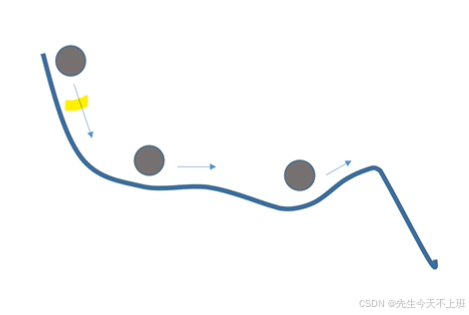
一个小球,从一个随机点开始,沿着误差曲面滚下。动量项的引入相当于赋予了小球惯性。动量优化器通过加入
γ
v
t
−
1
\gamma v_{t-1}
γvt−1加速SGD,并抑制震荡。
v
t
=
γ
v
t
−
1
−
η
▽
θ
J
(
θ
)
v_t=\gamma v_{t-1}-\eta \bigtriangledown_{\theta}J(\theta)
vt=γvt−1−η▽θJ(θ)
θ
←
θ
+
v
t
\theta \gets \theta +v_{t}
θ←θ+vt
其中,
v
t
−
1
v_{t-1}
vt−1为上次更新时的反向梯度,
▽
θ
J
(
θ
)
\bigtriangledown_{\theta}J(\theta)
▽θJ(θ)为本次更新的反向梯度,
η
\eta
η为学习率,
0
⩽
η
<
1
0\leqslant \eta < 1
0⩽η<1是一个常数,称为动量(Momentum),表示要在多个程度上保留原来的更新方向。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









