




1. 阻塞与非阻塞I/O
阻塞操作是指在执行设备操作时,如果不能获得资源,则挂起进程直到满足可操作的条件后再进行操作。被挂起的进程进入睡眠状态,被从调度器的运行队列移走,知道等待的条件被满足。而非阻塞操作的进程再不能进行设备操作时,并不挂起,要么放弃,要么不停地查询,直到可操作。
阻塞访问和非阻塞访问如下图:
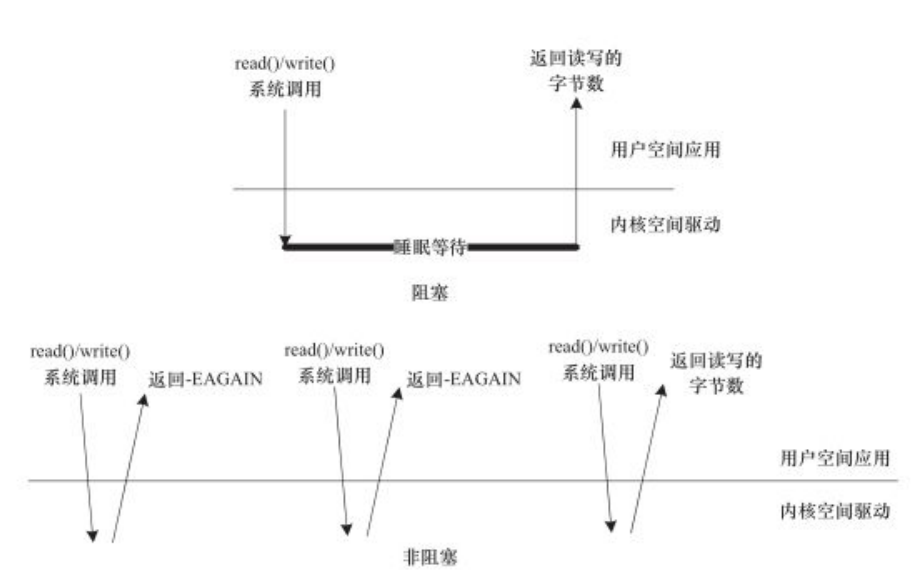
下列代码演示了以阻塞式的方式读取串口一个字符的代码,在打开时没有O_NONBLOCK标记:
char buf;
fd = open("/dev/ttyS1", O_RDWR);
...
res = read(fd, &buf, 1); /* 当串口上有输入时才返回 */
if(res == 1)
printf("%c\n", buf);
下列代码演示了以阻塞式的方式读取串口一个字符的代码,在打开时有O_NONBLOCK标记:
char buf;
fd = open("/dev/ttyS1", O_RDWR|O_NONBLOCK);
...
res = read(fd, &buf, 1); /* 当串口上无输入也返回,因此要循环尝试读取串口 */
if(res == 1)
printf("%c\n", buf);
除了在打开文件时可以指定以阻塞或者非阻塞方式以外,在文件打开后,也可以通过ioctrl()和fcntl()改变读写方式,如fctnl(fd, F_SETFL, O_NONBLOCK)可以设置fd对应的I/O为非阻塞。
1.1 等待队列
1.1.1 相关API
- 定义头文件:
#include <linux/wait.h>
- 等待队列头结构体:
typedef struct __wait_queue_head wait_queue_head_t;
struct __wait_queue_head {
spinlock_t lock;
struct list_head task_list;
};
- 定义和初始化等待队列头(workqueue):
静态定义:
#define DECLARE_WAIT_QUEUE_HEAD(name) \
wait_queue_head_t name = __WAIT_QUEUE_HEAD_INITIALIZER(name)
#define __WAIT_QUEUE_HEAD_INITIALIZER(name) { \
.lock = __SPIN_LOCK_UNLOCKED(name.lock), \
.task_list = { &(name).task_list, &(name).task_list } }
动态定义:
#define init_waitqueue_head(q) \
do { \
static struct lock_class_key __key; \
\
__init_waitqueue_head((q), #q, &__key); \
} while (0)
- 等待队列结构体:
typedef struct __wait_queue wait_queue_t;
struct __wait_queue {
unsigned int flags;
void *private;
wait_queue_func_t func;
struct list_head task_list;
};
- 定义等待队列元素
静态定义:
tsk是进程结构体,一般是current
#define DECLARE_WAITQUEUE(name, tsk) \
wait_queue_t name = __WAITQUEUE_INITIALIZER(name, tsk)
#define __WAITQUEUE_INITIALIZER(name, tsk) { \
.private = tsk, \
.func = default_wake_function, \
.task_list = { NULL, NULL } }
动态定义:
static inline void init_waitqueue_entry(wait_queue_t *q, struct task_struct *p)
{
q->flags = 0;
q->private = p;
q->func = default_wake_function;
}
- 添加/移除等待队列
extern void add_wait_queue(wait_queue_head_t *q, wait_queue_t *wait);
extern void add_wait_queue_exclusive(wait_queue_head_t *q, wait_queue_t *wait);
extern void remove_wait_queue(wait_queue_head_t *q, wait_queue_t *wait);
- 阻塞接口:
其中wq是我们定义的等待队列头,condition为条件表达式,当wake up后,condition为真时,唤醒阻塞的进程,为假时,继续睡眠。
wait_event:不可中断的睡眠,条件一直不满足,会一直睡眠。
wait_event_timeout:不可中断睡眠,当超过指定的timeout(单位是jiffies)时间,不管有没有wake up,还是条件没满足,都要唤醒进程,此时返回的是0。在timeout时间内条件满足返回值为timeout或者1;
wait_event_interruptible:可被信号中断的睡眠,被信号打断唤醒时,返回负值-ERESTARTSYS;wake up时,条件满足的,返回0。除了wait_event没有返回值,其它的都有返回,有返回值的一般都要判断返回值
TASK_RUNNING: 正在运行或处于就绪状态:就绪状态是指进程申请到了CPU以外的其他所有资源,提醒:一般的操作系统教科书将正在CPU上执 行的进程定义为RUNNING状态、而将可执行但是尚未被调度执行的进程定义为READY状态,这两种状态在Linux下统一为 TASK_RUNNING状态.
TASK_INTERRUPTIBLE: 处于等待队伍中,等待资源有效时唤醒(比如等待键盘输入、socket连接、信号等等),但可以被中断唤醒.一般情况下,进程列表中的绝大多数进程都处于 TASK_INTERRUPTIBLE状态.毕竟皇帝只有一个(单个CPU时),后宫佳丽几千;如果不是绝大多数进程都在睡眠,CPU又怎么响应得过来.
TASK_UNINTERRUPTIBLE:处于等待队伍中,等待资源有效时唤醒(比如等待键盘输入、socket连接、信号等等),但不可以被中断唤醒.
TASK_ZOMBIE:僵死状态,进程资源用户空间被释放,但内核中的进程PCB并没有释放,等待父进程回收.
TASK_STOPPED:进程被外部程序暂停(如收到SIGSTOP信号,进程会进入到TASK_STOPPED状态),当再次允许时继续执行(进程收到SIGCONT信号,进入TASK_RUNNING状态),因此处于这一状态的进程可以被唤醒
wait_event(wq, condition)
wait_event_timeout(wq, condition, timeout)
wait_event_interruptible(wq, condition)
wait_event_interruptible_timeout(wq, condition, timeout)
wait_event_hrtimeout(wq, condition, timeout)
wait_event_interruptible_hrtimeout(wq, condition, timeout)
wait_event_interruptible_exclusive(wq, condition)
wait_event_interruptible_locked(wq, condition)
wait_event_interruptible_locked_irq(wq, condition)
wait_event_interruptible_exclusive_locked(wq, condition)
wait_event_interruptible_exclusive_locked_irq(wq, condition)
wait_event_killable(wq, condition)
wait_event_lock_irq_cmd(wq, condition, lock, cmd)
wait_event_lock_irq(wq, condition, lock)
wait_event_interruptible_lock_irq_cmd(wq, condition, lock, cmd)
wait_event_interruptible_lock_irq(wq, condition, lock)
wait_event_interruptible_lock_irq_timeout(wq, condition, lock, timeout)
- 解除阻塞接口(唤醒)
wake_up:一次只能唤醒挂在这个等待队列头上的一个进程
wake_up_nr:一次唤起nr个进程(等待在同一个wait_queue_head_t有很多个)
wake_up_all:一次唤起所有等待在同一个wait_queue_head_t上所有进程
wake_up_interruptible:对应wait_event_interruptible版本的wake up
wake_up_interruptible_sync:保证wake up的动作原子性,wake_up这个函数,很有可能函数还没执行完,就被唤起来进程给抢占了,这个函数能够保证wak up动作完整的执行完成。
#define wake_up(x) __wake_up(x, TASK_NORMAL, 1, NULL)
#define wake_up_nr(x, nr) __wake_up(x, TASK_NORMAL, nr, NULL)
#define wake_up_all(x) __wake_up(x, TASK_NORMAL, 0, NULL)
#define wake_up_locked(x) __wake_up_locked((x), TASK_NORMAL, 1)
#define wake_up_all_locked(x) __wake_up_locked((x), TASK_NORMAL, 0)
#define wake_up_interruptible(x) __wake_up(x, TASK_INTERRUPTIBLE, 1, NULL)
#define wake_up_interruptible_nr(x, nr) __wake_up(x, TASK_INTERRUPTIBLE, nr, NULL)
#define wake_up_interruptible_all(x) __wake_up(x, TASK_INTERRUPTIBLE, 0, NULL)
#define wake_up_interruptible_sync(x) __wake_up_sync((x), TASK_INTERRUPTIBLE, 1)
1.1.2 wait_event实现
/**
* wait_event - sleep until a condition gets true
* @wq: the waitqueue to wait on
* @condition: a C expression for the event to wait for
*
* The process is put to sleep (TASK_UNINTERRUPTIBLE) until the
* @condition evaluates to true. The @condition is checked each time
* the waitqueue @wq is woken up.
*
* wake_up() has to be called after changing any variable that could
* change the result of the wait condition.
*/
#define wait_event(wq, condition) \
do { \
might_sleep(); \
if (condition) \ /* 如果条件为真,则直接返回 */
break; \
__wait_event(wq, condition); \ /* 进入等待函数 */
} while (0)
#define __wait_event(wq, condition) \
(void)___wait_event(wq, condition, TASK_UNINTERRUPTIBLE, 0, 0, \
schedule())
/*
* The below macro ___wait_event() has an explicit shadow of the __ret
* variable when used from the wait_event_*() macros.
*
* This is so that both can use the ___wait_cond_timeout() construct
* to wrap the condition.
*
* The type inconsistency of the wait_event_*() __ret variable is also
* on purpose; we use long where we can return timeout values and int
* otherwise.
*/
#define ___wait_event(wq, condition, state, exclusive, ret, cmd) \
({ \
__label__ __out; \
/*定义并且初始化等待队列项,后面我们会将这个等待队列项加入我们的等待队列当中,同时在初始化的过程中,
会定义func函数的调用函数autoremove_wake_function函数,该函数会调用default_wake_function函数。*/
wait_queue_t __wait; \
long __ret = ret; /* explicit shadow */ \
\
INIT_LIST_HEAD(&__wait.task_list); \
if (exclusive) \
__wait.flags = WQ_FLAG_EXCLUSIVE; \
else \
__wait.flags = 0; \
\
for (;;) { \
/* 将工作队列wait加入到工作队列头q,并将当前进程设置为state指定的状态,
一般是TASK_UNINTERRUPTIBLE或TASK_INTERRUPTIBLE状态(在这函数里有调用set_current_state)。 */
long __int = prepare_to_wait_event(&wq, &__wait, state);\
\
/* 继续判断条件是否满足 */
if (condition) \
break; \
\
/* 如果状态为TASK_INTERRUPTIBLE且prepare_to_wait_event失败 */
if (___wait_is_interruptible(state) && __int) { \
__ret = __int; \
if (exclusive) { \
abort_exclusive_wait(&wq, &__wait, \
state, NULL); \
goto __out; \
} \
break; \
} \
\
/* 如果不满足,则交出CPU的控制权,使当前进程进入休眠状态 */
cmd; \
} \
finish_wait(&wq, &__wait); \
__out: __ret; \
})
long prepare_to_wait_event(wait_queue_head_t *q, wait_queue_t *wait, int state)
{
unsigned long flags;
if (signal_pending_state(state, current))
return -ERESTARTSYS;
wait->private = current;
wait->func = autoremove_wake_function;
spin_lock_irqsave(&q->lock, flags);
if (list_empty(&wait->task_list)) { //判断等待队列是否为空,即只要检查等待队列头的task_list是否指向本身就可以了
if (wait->flags & WQ_FLAG_EXCLUSIVE) //如果具有WQ_FLAG_EXCLUSIVE标记,则放在队列尾
__add_wait_queue_tail(q, wait);
else //否则放在对立头
__add_wait_queue(q, wait);
}
set_current_state(state); //切换进程状态
spin_unlock_irqrestore(&q->lock, flags);
return 0;
}
从上诉的宏可以看出,最终实现是___wait_event函数,可以看出睡眠进程过程,prepare_to_wait先修改进程到睡眠状态,条件不满足,schedule()就放弃CPU控制权,睡眠;阻塞在wq(也可以说阻塞在wait_event处)等待队列头上的进程,再次得到运行,接着执行schedule()后面的代码,这里,显然是个循环,prepare_to_wait再次设置当前进程为睡眠状态,然后判断条件是否满足,满足就退出循环,finish_wait将当前进程恢复到TASK_RUNNING状态,也就意味着阻塞解除。不满足,继续睡下去。如此反复等待条件成立。
wait_queue_t成员flage重要的标志WQ_FLAG_EXCLUSIVE,表示:
- 当一个等待队列入口有 WQ_FLAG_EXCLUSEVE 标志置位, 它被添加到等待队列的尾部. 没有这个标志的入口项, 添加到开始.
- 当 wake_up 被在一个等待队列上调用, 它在唤醒第一个有 WQ_FLAG_EXCLUSIVE 标志的进程后停止.
wait_event默认总是将waitqueue加入开始,而wake_up时总是一个一个的从开始处唤醒,如果不断有waitqueue加入,那么最开始加入的,就一直得不到唤醒,有这个标志,就避免了这种情况。
prepare_to_wait_exclusive()就是加入了这个标志的。
1.1.3 wake_up实现
/**定义wake_up函数宏,同时其需要一个wait_queue_head_t的结构体指针,在该宏中调用__wake_up方法。*/
#define wake_up(x) __wake_up(x, TASK_NORMAL, 1, NULL)
/**
* __wake_up - wake up threads blocked on a waitqueue.
* @q: the waitqueue
* @mode: which threads
* @nr_exclusive: how many wake-one or wake-many threads to wake up
* @key: is directly passed to the wakeup function
*
* It may be assumed that this function implies a write memory barrier before
* changing the task state if and only if any tasks are woken up.
*/
void __wake_up(wait_queue_head_t *q, unsigned int mode,
int nr_exclusive, void *key)
{
unsigned long flags;
spin_lock_irqsave(&q->lock, flags);
__wake_up_common(q, mode, nr_exclusive, 0, key);
spin_unlock_irqrestore(&q->lock, flags);
}
/*其中:q是等待队列,mode指定进程的状态,用于控制唤醒进程的条件,nr_exclusive表示将要唤醒的设置了WQ_FLAG_EXCLUSIVE标志的进程的数目,这里其值是1,
表示只有一个这样白标识的等待进程。 然后扫描链表,调用func(注册的进程唤醒函数,默认为default_wake_function)唤醒每一个进程,
直至队列为空,或者没有更多的进程被唤醒,或者被唤醒的的独占进程数目已经达到规定数目。*/
static void __wake_up_common(wait_queue_head_t *q, unsigned int mode,
int nr_exclusive, int wake_flags, void *key)
{
wait_queue_t *curr, *next;
/* 这个宏的作用是遍历整个等待队列,其实就相当于一个for函数 */
list_for_each_entry_safe(curr, next, &q->task_list, task_list) {
/* 将当前进程的标志位赋给flag,再调用func函数,以及其他判断机制唤醒等待队列上的进程 */
unsigned flags = curr->flags;
if (curr->func(curr, mode, wake_flags, key) &&
(flags & WQ_FLAG_EXCLUSIVE) && !--nr_exclusive)
break;
}
}
int default_wake_function(wait_queue_t *curr, unsigned mode, int wake_flags,
void *key)
{
return try_to_wake_up(curr->private, mode, wake_flags);
}
/**
* try_to_wake_up - wake up a thread
* @p: the thread to be awakened
* @state: the mask of task states that can be woken
* @wake_flags: wake modifier flags (WF_*)
*
* Put it on the run-queue if it's not already there. The "current"
* thread is always on the run-queue (except when the actual
* re-schedule is in progress), and as such you're allowed to do
* the simpler "current->state = TASK_RUNNING" to mark yourself
* runnable without the overhead of this.
*
* Return: %true if @p was woken up, %false if it was already running.
* or @state didn't match @p's state.
*/
static int
try_to_wake_up(struct task_struct *p, unsigned int state, int wake_flags)
{
unsigned long flags;
int cpu, success = 0;
/*
* If we are going to wake up a thread waiting for CONDITION we
* need to ensure that CONDITION=1 done by the caller can not be
* reordered with p->state check below. This pairs with mb() in
* set_current_state() the waiting thread does.
*/
smp_mb__before_spinlock();
raw_spin_lock_irqsave(&p->pi_lock, flags);
if (!(p->state & state))
goto out;
success = 1; /* we're going to change ->state */
cpu = task_cpu(p);
if (p->on_rq && ttwu_remote(p, wake_flags))
goto stat;
#ifdef CONFIG_SMP
/*
* If the owning (remote) cpu is still in the middle of schedule() with
* this task as prev, wait until its done referencing the task.
*/
while (p->on_cpu)
cpu_relax();
/*
* Pairs with the smp_wmb() in finish_lock_switch().
*/
smp_rmb();
p->sched_contributes_to_load = !!task_contributes_to_load(p);
p->state = TASK_WAKING;
if (p->sched_class->task_waking)
p->sched_class->task_waking(p);
cpu = select_task_rq(p, p->wake_cpu, SD_BALANCE_WAKE, wake_flags);
if (task_cpu(p) != cpu) {
wake_flags |= WF_MIGRATED;
set_task_cpu(p, cpu);
}
#endif /* CONFIG_SMP */
ttwu_queue(p, cpu);
stat:
ttwu_stat(p, cpu, wake_flags);
out:
raw_spin_unlock_irqrestore(&p->pi_lock, flags);
return success;
}
1.1.4 示例模板
static ssize_t xxx_write(struct file *file, const char *buffer, size_t count, loff_t *ppos)
{
...
DECLARE_WAITQUEUE(wait, current) /* 定义等待队列元素 */
add_wait_queue(&xxx_wait, &wait); /* 添加元素到等待队列 */
/* 等待设备缓存区可写 */
do {
avail = device_writable(...);
if(avail < 0){
if(file->f_flag & O_NONBLOCK){ /* 非阻塞 */
ret = -EAGAIN;
goto out;
}
__set_current_state(TASK_INTERRUPTIBLE); /* 改变进程状态 */
schedule();
if(signal_pending(current)){ /* 如果因为信号唤醒 */
ret = - ERESTARTSYS;
goto out;
}
}
}while(avail < 0);
/* 写设备缓冲区 */
device_write(...);
out:
remove_wait_queue(&xxx_write, &wait); /* 将元素移出xxx_wait指引的队列 */
set_current_state(TASK_RUNNING); /* 设置进程为TASK_RUNNING */
return ret;
}
2. 轮询操作
2.1 轮询的概念与左右
在用户程序中,使用非阻塞I/O的应用程序通常会使用select()和poll()系统调用查询是否可对设备进行无阻塞的访问。select()和poll系统调用最终会使用设备驱动中的poll()函数执行,在linux2.5.45内核,还引入了epoll()。
2.2 应用程序中的轮询编程
2.2.1 select
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
nfds:
这个参数的值设置成所有需要使用 select 函数检测事件的 fd 中的最大 fd 值加 1
readfds、writefds、exceptfds:
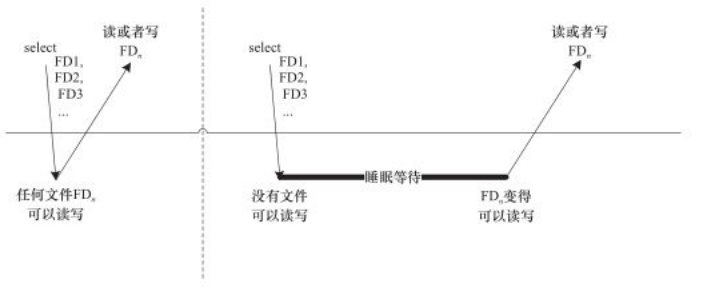
其中readfds、writefds和exceptfds分别是被select()监视的读、写和异常处理的文件描述符集合。readfds和writefds文件集任意一个发送变化,select返回。
如下图,第一次对n个文件进行select()的时候,若任意一个文件满足要求,select()就直接返回;第二次再进行select()的时候,没有文件满足读写要求,select()的进程阻塞且睡眠。由于调用select()的时候,每个驱动的poll()接口都会被调用,实际上执行select()的进程被挂到了每个驱动的等待队列上,可以被任意一个驱动唤醒。
fd_set:
一个文件描述符集合保存在fd_set变量中,可读,可写,异常这三个描述符集合需要使用三个变量来保存,分别是 readfds,writefds,exceptfds。我们可以认为一个fd_set变量是由很多个二进制构成的数组,每一位表示一个文件描述符是否需要监视。
对于fd_set类型的变量,我们只能使用相关的函数来操作:
void FD_CLR(int fd, fd_set *set);//清除某一个被监视的文件描述符。 int FD_ISSET(int fd, fd_set *set);//测试一个文件描述符是否是集合中的一员 void FD_SET(int fd, fd_set *set);//添加一个文件描述符,将set中的某一位设置成1; void FD_ZERO(fd_set *set);//清空集合中的文件描述符,将每一位都设置为0;
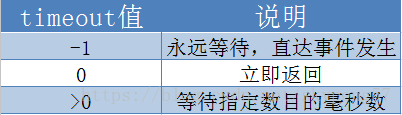
timeout:
超时时间,即在这个参数设定的时间内检测这些 fd 的事件,超过这个时间后 select 函数将立即返回
struct timeval { long tv_sec; /* seconds */ long tv_usec; /* microseconds */ };
return value:
>0:有事件发生;=0:timeout,超时;<0:出错
示例:
fd_set readfds;
int fd;
FD_ZERO(&readfds); //新定义的变量要清空一下。相当于初始化。
FD_SET(fd,&readfds); //把文件描述符fd加入到readfds中。
//select 返回
if(FD_ISSET(fd,&readset)) //判断是否成功监视
{
//dosomething
}
2.2.2 poll
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
fds:
指向一个结构体数组的第0个元素的指针,每个数组元素都是一个struct pollfd结构,用于指定测试某个给定的fd的条件
struct pollfd { int fd; /* 待检测事件的 fd */ short events; /* 关心的事件组合 */ short revents; /* 检测后的得到的事件类型 */ };
nfds:
参数 fds 结构体数组的长度,nfds_t 本质上是 unsigned long int,其定义如下:
typedef unsigned long int nfds_t;
timeout:
表示 poll 函数的超时时间,单位为毫秒
return value:
成功时,poll() 返回结构体中 revents 域不为 0 的文件描述符个数;如果在超时前没有任何事件发生,poll()返回 0;
失败时,poll() 返回 -1,并设置 errno 为下列值之一:
EBADF:一个或多个结构体中指定的文件描述符无效。
EFAULT:fds 指针指向的地址超出进程的地址空间。
EINTR:请求的事件之前产生一个信号,调用可以重新发起。
EINVAL:nfds 参数超出 PLIMIT_NOFILE 值。
ENOMEM:可用内存不足,无法完成请求。
struct pollfd的 events 字段是由开发者来设置,告诉内核我们关注什么事件,而 revents 字段是 poll 函数返回时内核设置的,用以说明该 fd 发生了什么事件。events 和 revents 一般有如下取值:
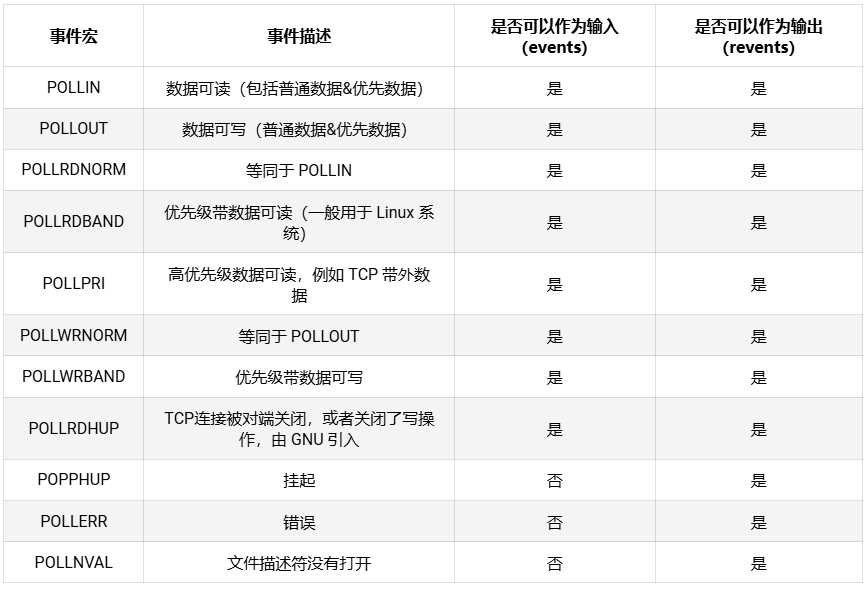
示例:
std::vector<pollfd> fds;
pollfd listen_fd_info;
listen_fd_info.fd = listenfd;
listen_fd_info.events = POLLIN;
listen_fd_info.revents = 0;
fds.push_back(listen_fd_info);
//是否存在无效的fd标志
bool exist_invalid_fd;
int n;
while (true)
{
exist_invalid_fd = false;
n = poll(&fds[0], fds.size(), 1000);
if (n < 0)
{
//被信号中断
if (errno == EINTR)
continue;
//出错,退出
break;
}
else if (n == 0)
{
//超时,继续
continue;
}
for (size_t i = 0; i < fds.size(); ++i)
{
// 事件可读
if (fds[i].revents & POLLIN)
{
//do something
}
}// end outer-for-loop
}
2.2.3 epoll
int epoll_create(int size);
参数 size 从 Linux 2.6.8 以后就不再使用,但是必须设置一个大于 0 的值。epoll_create 函数调用成功返回一个非负值的 epollfd,调用失败返回 -1。
有了 epollfd 之后,我们需要将我们需要检测事件的其他 fd 绑定到这个 epollfd 上,或者修改一个已经绑定上去的 fd 的事件类型,或者在不需要时将 fd 从 epollfd 上解绑,这都可以用 epoll_ctl 函数:
int epoll_ctl(int epfd, int op, int fd, struct epoll_event* event);
参数说明:
-
参数 epfd 即上文提到的 epollfd;
-
参数 op,操作类型,取值有 EPOLL_CTL_ADD、EPOLL_CTL_MOD 和 EPOLL_CTL_DEL,分别表示向 epollfd 上添加、修改和移除一个其他 fd,当取值是 EPOLL_CTL_DEL,第四个参数 event 忽略不计,可以设置为 NULL;
-
参数 fd,即需要被操作的 fd;
-
参数 event,这是一个 epoll_event 结构体的地址,epoll_event 结构体定义如下:
struct epoll_event { uint32_t events; /* 需要检测的 fd 事件,取值与 poll 函数一样 */ epoll_data_t data; /* 用户自定义数据 */ };epoll_event 结构体的 data 字段的类型是 epoll_data_t,我们可以利用这个字段设置一个自己的自定义数据,它本质上是一个 Union 对象,在 64 位操作系统中其大小是 8 字节,其定义如下:
typedef union epoll_data { void* ptr; int fd; uint32_t u32; uint64_t u64; } epoll_data_t; -
函数返回值:epoll_ctl 调用成功返回 0,调用失败返回 -1,你可以通过 errno 错误码获取具体的错误原因。
创建了 epollfd,设置好某个 fd 上需要检测事件并将该 fd 绑定到 epollfd 上去后,我们就可以调用 epoll_wait 检测事件了,epoll_wait 函数签名如下:
int epoll_wait(int epfd, struct epoll_event* events, int maxevents, int timeout);
参数的形式和 poll 函数很类似,参数 events 是一个 epoll_event 结构数组的首地址,这是一个输出参数,函数调用成功后,events 中存放的是与就绪事件相关 epoll_event 结构体数组;参数 maxevents 是数组元素的个数;timeout 是超时时间,单位是毫秒,如果设置为 0,epoll_wait 会立即返回。
当 epoll_wait 调用成功会返回有事件的 fd 数目;如果返回 0 表示超时;调用失败返回 -1。
示例:
while (true)
{
epoll_event epoll_events[1024];
int n = epoll_wait(epollfd, epoll_events, 1024, 1000);
if (n < 0)
{
//被信号中断
if (errno == EINTR)
continue;
//出错,退出
break;
}
else if (n == 0)
{
//超时,继续
continue;
}
for (size_t i = 0; i < n; ++i)
{
if (epoll_events[i].events & EPOLLIN)
{
// 处理可读事件
}
else if (epoll_events[i].events & EPOLLOUT)
{
// 处理可写事件
}
else if (epoll_events[i].events & EPOLLERR)
{
//处理出错事件
}
}
}
2.3 设备驱动的轮询编程
函数原型:
unsigned int (*poll)(struct file *file, struct poll_table_struct *poll_table)
第一个参数为file结构体指针,第二个为轮询表指针。这个函数应该进行两项工作
1)对可能引起设备文件状态变化的等待队列调用poll_wait()函数,将对应的等待队列头部添加到poll_table中。
2)返回表示是否能对设备进行无阻塞读、写访问的掩码。
用于向poll_table注册等待队列的关键poll_wait()函数原型如下:
void poll_wait(struct file * filp, wait_queue_head_t * wait_address, poll_table *p)
poll_wait()函数所做的工作是把当前进程添加到wait参数指定的等待列表(poll_table),实际作用是让唤醒参数queue对应的等待队列可以唤醒因select()而睡眠的进程。
驱动程序poll()函数应该返回设备资源的可获取状态,即POLLIN、POLLOUT、POLLPRI、POLLERR、POLLNVAL等宏的位“或”结果。每个宏的含义都表明设备的一种状态,如POLLIN意味着设备可以无阻塞的读,POLLOUT意味着设备可以无阻塞的写。
示例模板:
static unsigned int xxx_poll(struct file *filp, poll_table *wait)
{
unsigned int max = 0;
struct xxx_dev *dev = filp->private_data; /* 获得设备结构体指针 */
...
poll_wait(filp, &dev->r_wait, wait); /* 加入读等待队列 */
poll_wait(filp, &dev->w_wait, wait); /* 加入写等待队列 */
if(...) /* 可读 */
mask |= POLLIN | POLLRDNORM; /* 标示数据可获得(对用户可读) */
if(...) /* 可写 */
mask |= POLLOUT | POLLWRNORM; /* 标示数据可写入 */
...
return mask;
}

















 1488
1488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









