







接续上一次介绍的LSTM ,这里我又很不要脸地使用“人人都能看懂的xxx”来作为标题,来将对GRU进行介绍。同样这里的内容是对台大李宏毅老师课程视频的一些记录以及自己的一些整理和思考。对于不懂基础RNN和LSTM的同学可以先看看我的上一篇文章 人人都能看懂的LSTM。有任何疑问欢迎交流。
1. 什么是GRU
GRU(Gate Recurrent Unit)是循环神经网络(Recurrent Neural Network, RNN)的一种。和LSTM(Long-Short Term Memory)一样,也是为了解决长期记忆和反向传播中的梯度等问题而提出来的。
GRU和LSTM在很多情况下实际表现上相差无几,那么为什么我们要使用新人GRU(2014年提出)而不是相对经受了更多考验的LSTM(1997提出)呢。
下图1-1引用论文中的一段话来说明GRU的优势所在。

简单译文:我们在我们的实验中选择GRU是因为它的实验效果与LSTM相似,但是更易于计算。
简单来说就是贫穷限制了我们的计算能力…
相比LSTM,使用GRU能够达到相当的效果,并且相比之下更容易进行训练,能够很大程度上提高训练效率,因此很多时候会更倾向于使用GRU。
OK,那么为什么说GRU更容易进行训练呢,下面开始介绍一下GRU的内部结构。
2. GRU浅析
2.1 GRU的输入输出结构
GRU的输入输出结构与普通的RNN是一样的。

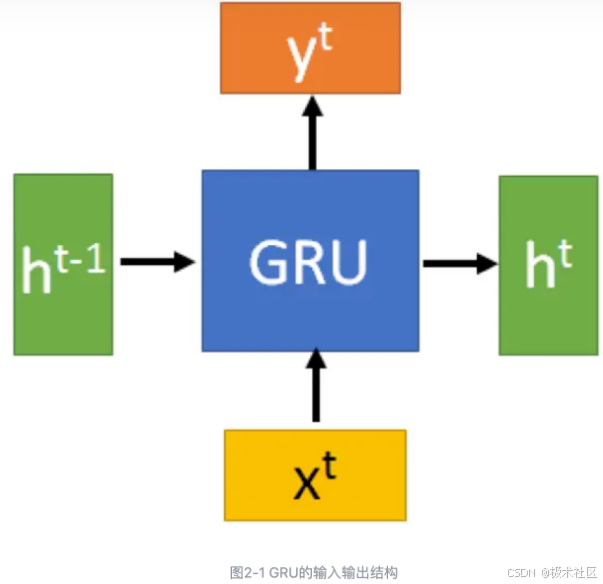
那么,GRU到底有什么特别之处呢?下面来对它的内部结构进行分析!
2.2 GRU的内部结构

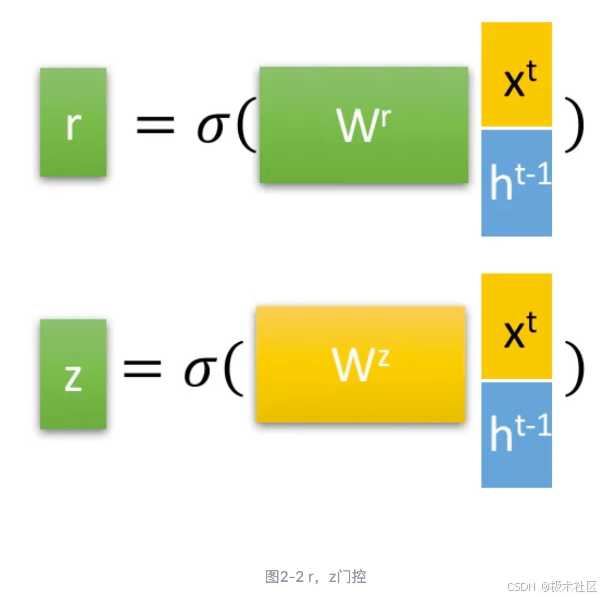
Tips:为sigmoid函数,通过这个函数可以将数据变换为0-1范围内的数值,从而来充当门控信号。
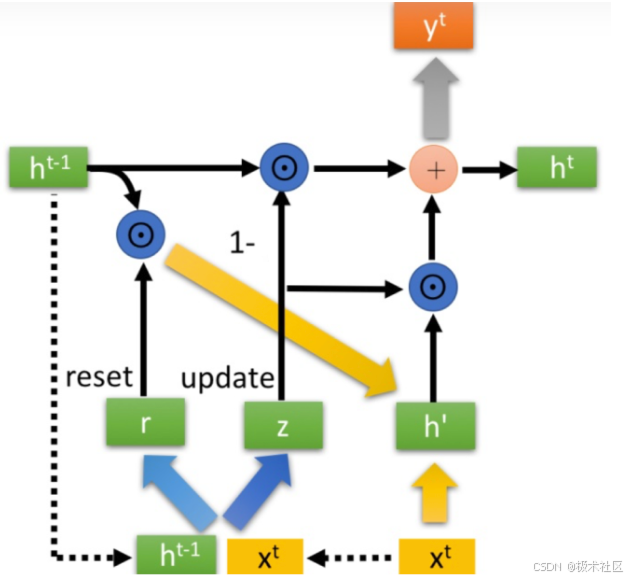
与LSTM分明的层次结构不同,下面将对GRU进行一气呵成的介绍~~~ 请大家屏住呼吸,不要眨眼。

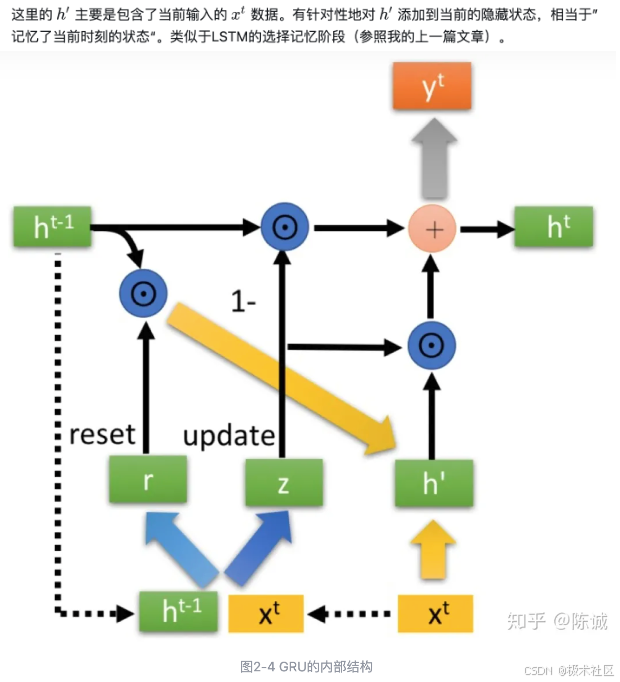
图2-4中的是Hadamard Product,也就是操作矩阵中对应的元素相乘,因此要求两个相乘矩阵是同型的。则代表进行矩阵加法操作。
最后介绍GRU最关键的一个步骤,我们可以称之为”更新记忆“阶段。
在这个阶段,我们同时进行了遗忘了记忆两个步骤。我们使用了先前得到的更新门控(update gate)。

3. LSTM与GRU的关系
GRU是在2014年提出来的,而LSTM是1997年。他们的提出都是为了解决相似的问题,那么GRU难免会参考LSTM的内部结构。那么他们之间的关系大概是怎么样的呢?这里简单介绍一下。
大家看到 (reset gate)实际上与他的名字有点不符。我们仅仅使用它来获得了。
那么这里的 实际上可以看成对应于LSTM中的hidden state;上一个节点传下来的 则对应于LSTM中的cell state。1-z对应的则是LSTM中的 forget gate,那么 z我们似乎就可以看成是选择门 了。大家可以结合我的两篇文章来进行观察,这是非常有趣的。
4. 总结
GRU输入输出的结构与普通的RNN相似,其中的内部思想与LSTM相似。
与LSTM相比,GRU内部少了一个”门控“,参数比LSTM少,但是却也能够达到与LSTM相当的功能。考虑到硬件的计算能力和时间成本,因而很多时候我们也就会选择更加”实用“的GRU啦。
作者:陈诚
文章来源:知乎
推荐阅读
更多芯擎AI开发板干货请关注芯擎AI开发板专栏。欢迎添加极术小姐姐微信(id:aijishu20)加入技术交流群,请备注研究方向。

















 4985
4985

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









