









爬虫学习日常记录:enicode反扒技术
练习网址:大众点评
OCR使用:百度智能云字体识别
woff文件阅读工具:mac与win通用
字体反扒:
顾名思义就是让你无法获取他的字体使用enicode编码制作独有的映射,呈现在网页源代码上让你无法阅读明白
通用思路:
1.找到该处所使用的css样式,进入link加载的样式文件
2.获取样式所对应的字体文件
3.获取文字,将编码与文字对应上
4.替换网页上的编码变成文字
找到该处所使用的css样式,进入link加载的样式文件:
从页面源代码head处能找到加载的css文件
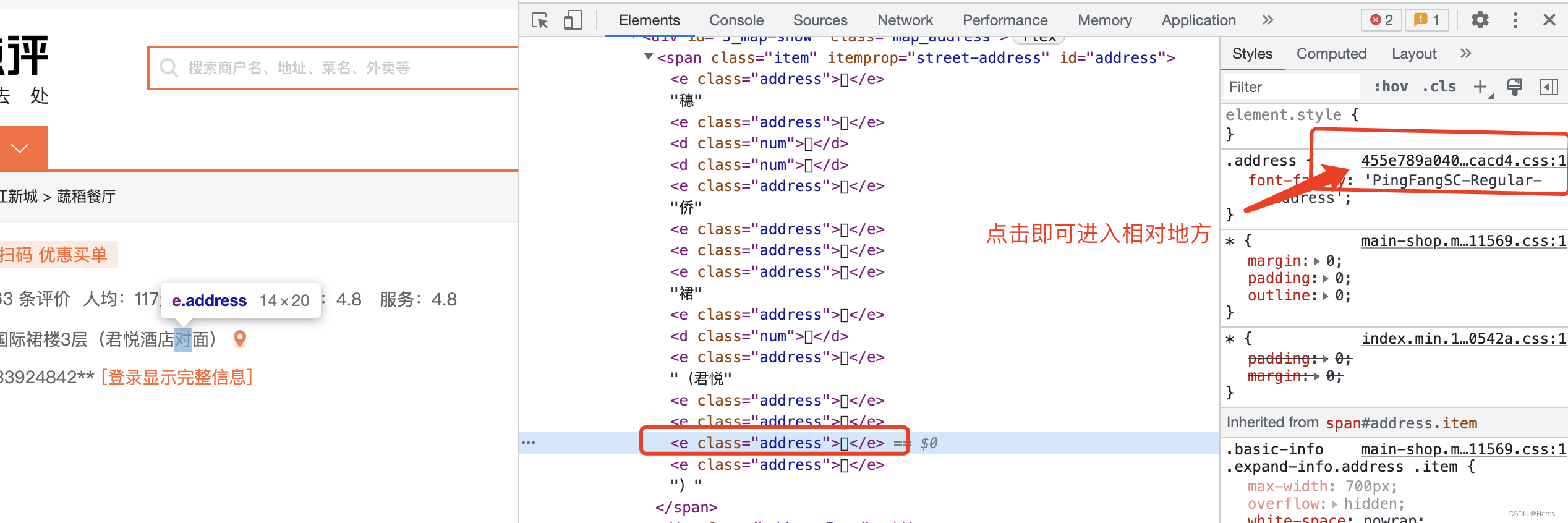
找到css文件名字记录下来
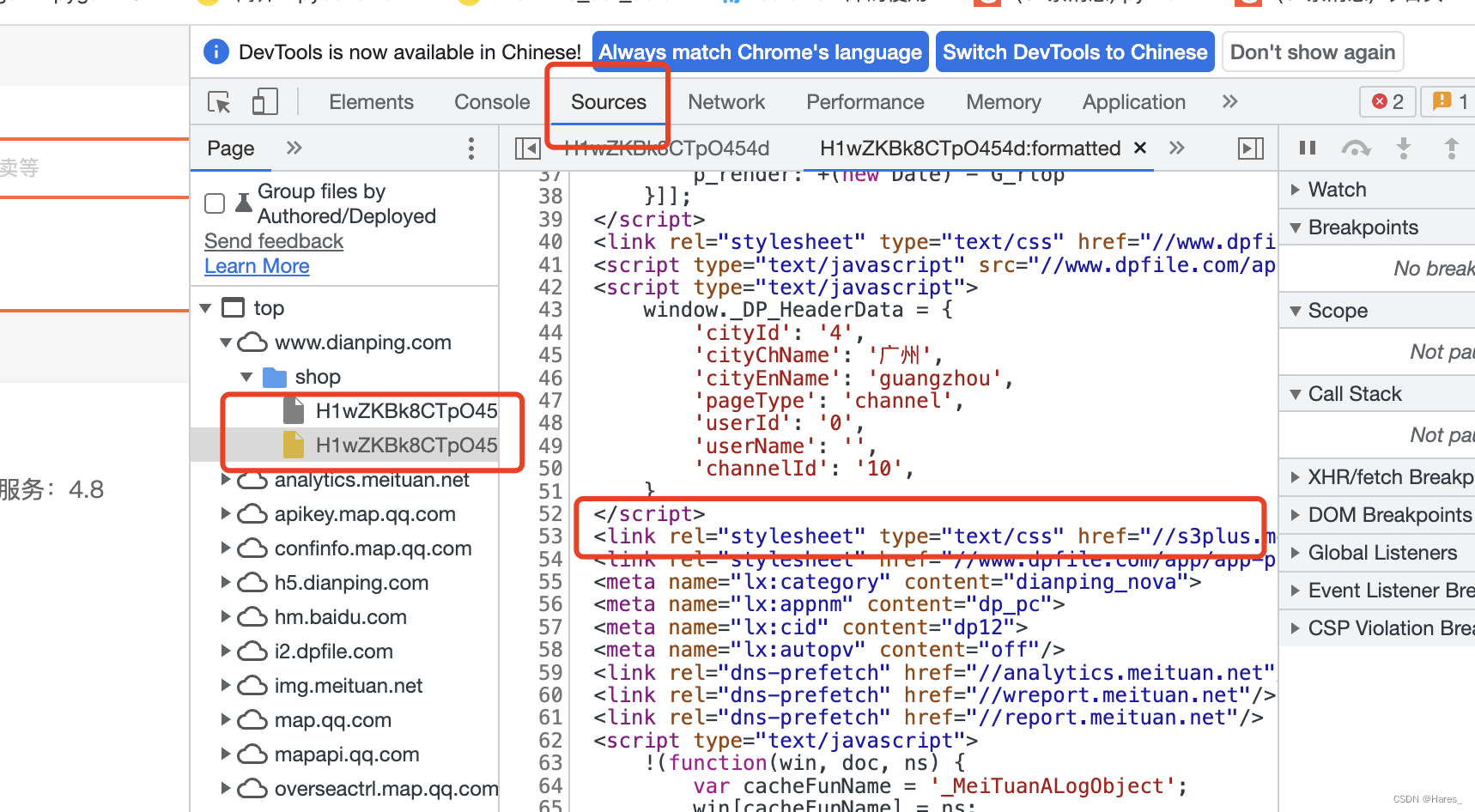
接着再页面源代码找到对应的css链接将它提取出来
获取页面源代码中的href:
代码:
import re
from urllib.parse import urljoin
import requests
import parsel
#找到反扒处字体css样式,1,获取本页,2,提取css地址,3,访问链接获得css内容
headers = {
"referer": "https://www.dianping.com/",
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36",
"authority": "www.dpfile.com"
} #基础伪装
first_resp = requests.get("https://www.dianping.com/shop/H1wZKBk8CTpO454d",headers=headers).text
f_resp = parsel.Selector(first_resp)
css = "http:"+ f_resp.xpath("//link[@type='text/css']/@href").extract()[1]请求获取来的地址获得css样式内容中的文件下载并保存:
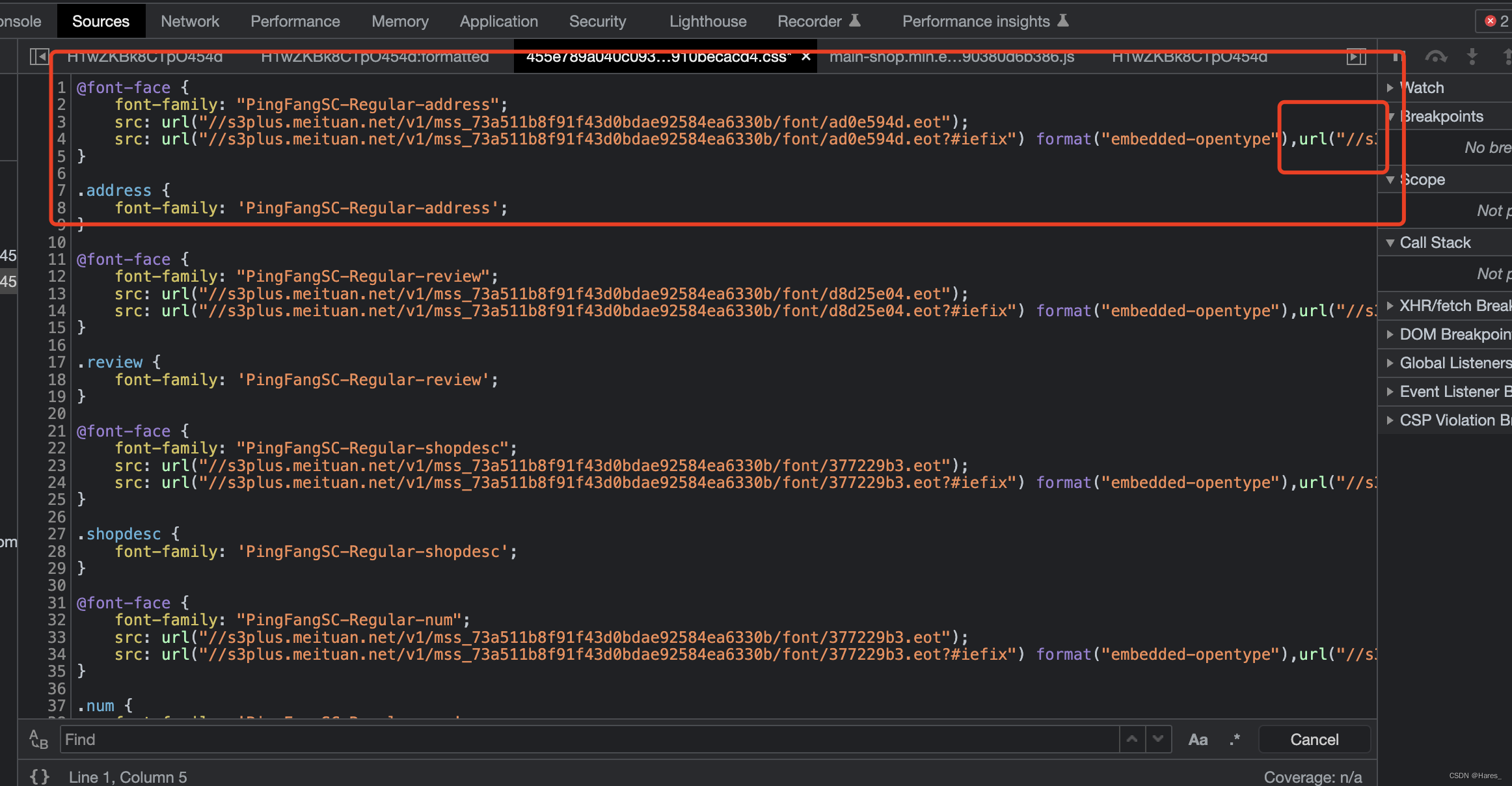
代码:
css_resp = requests.get(url=css,headers=headers).text
#开始定位获取css文件中的字体包路径,需要re定位两次
# re_f = re.compile(".address{font-family: 'PingFangSC-Regular-address';}(?P<fi>.*).review{font-family: '",re.S)
re_f = re.compile("(?P<fi>.*).address{font-family: 'PingFangSC-Regular-address';}",re.S)
retext = re_f.search(css_resp).group("fi")
re_s = re.compile(',url\("(?P<fe>.*)"\);}')
re_url = re_s.search(retext).group("fe")
#获得字体包链接
font_url = urljoin(css,re_url)
print(font_url)
#保存
with open("font_pl.woff","wb")as f:
f.write(font_resp.content)用阅读工具打开看看文件中的内容处理编码:

读取文件,将名字提出出来换前缀名\u,因为\的问题所以用\\的方式先写入,再用.encode().decode("unicode-escape")即可解决处理
#读取字体编码
from fontTools.ttLib import ttFont
ttf = ttFont.TTFont("font_pl.woff")
ttf_t = ttf.getGlyphOrder()[2:]
uni_text = list(map(lambda x:"\\u"+x[3:],ttf_t)) #处理成\\ue2b1将内容画出来然后读取:
#将内容画出来与之对应
from PIL import Image
from PIL import ImageFont
from PIL import ImageDraw
img = Image.new("RGB",(1800,1000),color=(255,255,255)) #创建图片
#准备画笔
img_draw = ImageDraw.Draw(img)
#准备画图的字符
img_font = ImageFont.truetype("font_pl.woff",40)
#写入图片
new_line = []
line_length = 43#每行43个需要调试出合理的图片
for i in range(len(uni_text)):
uni = uni_text[i].encode().decode("unicode-escape")
if i % line_length == 0 and i !=0:
new_line_s = "".join(new_line)
img_draw.text((20,(i//line_length+1)*line_length),new_line_s,fill=1,font=img_font)
new_line = [uni]
else:
new_line.append(uni)
if new_line:
new_line_s = "".join(new_line)
img_draw.text((20, (i // line_length + 2) * line_length), new_line_s, fill=1, font=img_font)
img.save("tu.jpg")图片:

接着使用OCR将内容读取出来:
from aip import AipOcr
""" 你的 APPID AK SK """
APP_ID = '自己appid'
API_KEY = '自己key'
SECRET_KEY = '自己skey'
f = open("tu.jpg","rb")
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
r = client.basicGeneral(f.read())
result_list = []
for txt in r["words_result"]:
result_list.extend(txt["words"]) #将字符串换成list
font_dic = dict(zip(uni_text,result_list)) #zip将内容对应存储
print(font_dic)现在获得了编码与字体的映射
接着请求到内容后,就可以执行替换,从而实现还原:
headers = {
"referer": "https://www.dianping.com/",
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36",
"authority": "www.dpfile.com"
}
first_resp = requests.get("https://www.dianping.com/shop/H1wZKBk8CTpO454d",headers=headers).text
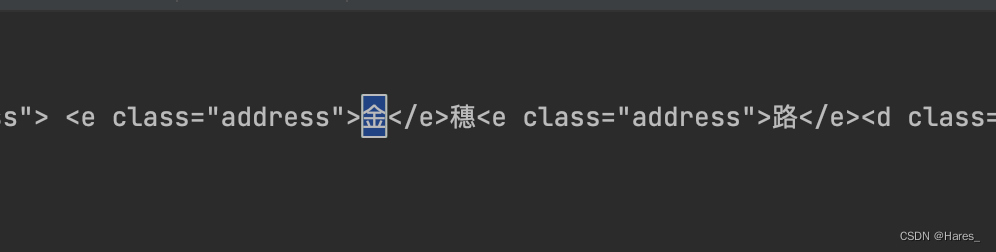
# first_resp = '<e class="address"></e>穗<e class="address"></e><d class="num"></d>'
for un in font_dic:
uni = font_dic[un]
funi = un.replace("\\u","&#x") + ";"
print(funi,uni)
first_resp = first_resp.replace(funi,uni)
print(first_resp)将\\u替换成页面源代码中的格式,接着替换掉,最后实现还原:
页面源代码中有许多样式设置了反爬,所以将所有的样式还原出来后,既可还原整个页面




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











