






一、索引(index)
1、定义
索引在数据库表的字段上添加,是为了提高查询效率存在的一种机制。
一张表的一个字段可以添加一个索引,当然,多个字段联合起来也可以添加索引。
索引相当于一本书的目录,是为了缩小扫描范围而存在的一种机制。
【对于一本字典来说,查找某个汉字有两种方式:】
- 第一种方式:一页一页查找,直到找到为止,这种查找方式属于全字典扫描。效率比较低。
- 第二种方式:先通过目录(索引)去定位一个大概的位置,然后直接定位到这个位置,做局域性扫描,缩小扫描的范围,快速的查找。这种查找方式属于通过索引检索,效率较高。
MySQL在查询方面主要就是两种方式:
- 第一种方式:全表扫描。
- 第二种方式:根据索引检索。
注意:
在实际中,汉语字典前面的目录是排序的,按照a b c d e ...排序。
为什么排序?因为只有排序了,才会有区间查找这一说(缩小扫描范围其实就是扫描某个区间罢了)
在mysql数据库当中索引也是需要排序的,并且这个索引的排序和TreeSet数据结构相同。Treeset(TreeMap)底层是一个自平衡的二叉树!在mysql当中索引是一个B-Tree数据结构。
遵循左小右大原则存放。采用中序遍历方式遍历取数据。
2、实现原理
实现原理:缩小扫描范围,避免全表扫描。
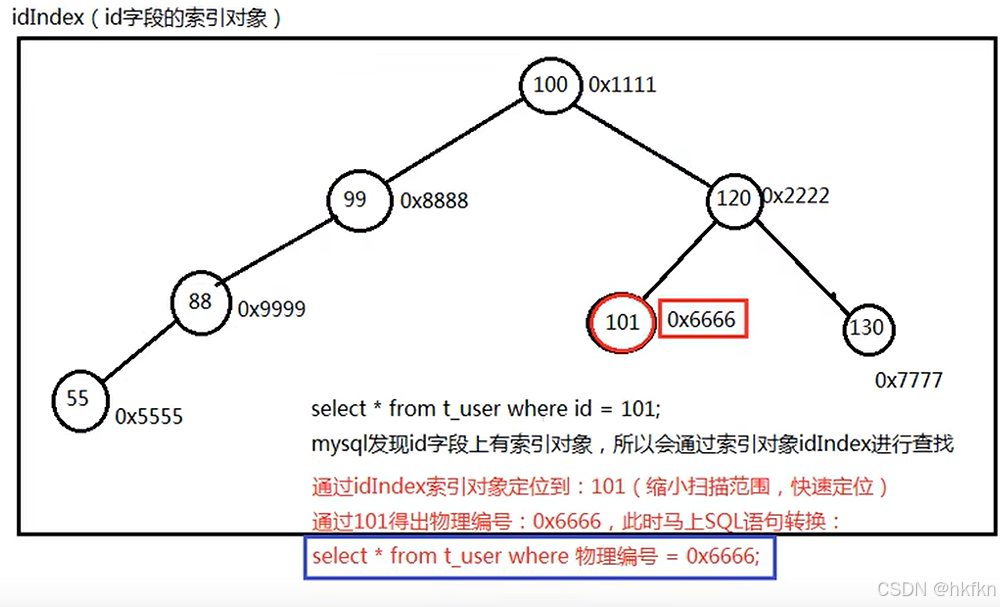
假设有一张用户表:t_user
id(PK) name 每一行记录在硬盘上都有物理存储编号
-----------------------------------------------------------------------------------------------------------------------------
100 zhangsan 0x1111
120 lisi 0x2222
99 wangwu 0x8888
88 zhaoliu 0x9999
101 jack 0x6666
55 lucy 0x5555
130 tom 0x7777
提醒1:在任何数据库当中主键都会自动添加索引对象,id字段上自动有索引,因为id是PK。另外在mysql当中,一个字段上如果有unique约束的话,也会自动创建索引对象。
提醒2:在任何数据库中,任何一张表的任何一张记录在硬盘存储上都有一个硬盘的物理存储编号。
提醒3:在mysql当中,索引是一个单独的对象,不同的存储引擎以不同的形式存在,在MyISAM存储引擎中,索引存储在一个.MYI文件中。在InnoDB存储引擎中,索引存储在一个逻辑名称叫做tablespace当中。在MEMORY存储引擎当中索引被存储在内存当中。不管索引存储在哪里,索引在mysql当中都是一个树的形式存在(子平衡二叉树:B-Tree)
3、在mysql当中,主键以及unique字段上都会自动添加索引!!
什么条件下,会考虑给字段添加索引:
- 条件1:数据量庞大(到底多庞大,需要测试,因为每个硬件环境不同)
- 条件2:该字段经常出现在where的后面,以条件的形式存在,也就是说这个字段经常被扫描
- 条件3:该字段很少的DML(insert、delete、update)操作。(因为DML之后,索引需要重新排序)
建议不要随意添加索引,因为索引也需要维护,太多的话反而会降低系统的性能。建议通过主键查询,建议通过unique约束的字段进行查询,效率是比较高的。
4、索引怎么创建?怎么删除?语法是啥?
创建索引:
create index emp_ename_index on emp(ename);//给emp表的ename字段添加索引,起名:emp_ename_index删除索引:
drop index emp_ename_index on emp;//将emp表上的emp_ename_index索引对象删除5、在mysql中,怎么查看一个SQL语句是否使用了索引进行检索?
explain select * from emp where ename='KING';
扫描14条记录,说明没有使用索引。type=ALL
创建索引,查看是否通过索引进行检索
create index emp_ename_index on emp(ename);
explain select * from emp where ename='KING';
type=ref:使用索引(底层是B-Tree)
6、索引有失效的时候,什么时候索引失效?
①失效的第一种情况("%"开头):
select * from emp where ename like '%T';
ename上即使添加了索引也不会走索引,为什么?
因为模糊匹配当中以"%"开头了!尽量避免模糊查询的时候以"%"开始。(必须知道第一个字母是啥才能进行比对)
这是一种优化的手段。

②失效的第二种情况(or):
使用or的时候会失效,如果使用or,要求or两边的条件字段都要有索引,才会走索引,如果其中一边有一个字段没有索引,另一个字段的索引也会失效。这就是为什么不建议使用or的原因。
explain select * from emp where ename = 'KING' or job='MANAGER';
③失效的第三种情况(复合索引):
使用复合索引的时候,没有使用左侧的列查找,索引失效。
什么是复合索引?
两个字段,或者更多的字段联合起来添加一个索引,叫做复合索引。
create index emp_ename_sal_index on emp(job,sal);
explain select * from emp where job = 'MANAGER';
explain select * from emp where sal = 800;
④失效的第四种情况 (where当中索引列参加了运算):
where当中索引参加了运算,索引失效。
create index emp_sal_index on emp(sal);
explain select * from emp where sal+1=800;
⑤失效的第五种情况(where当中索引列使用了函数):
explain select * from emp where lower(ename) = 'smith';
7、索引的类别
索引是各种数据库进行优化的重要手段。优化的时候优先考虑的因素就是索引。
- 单一索引:一个字段上添加索引
- 复合索引:两个字段或者更多字段上添加索引
- 主键索引:主键上添加索引
- 唯一性索引:具有unique约束的字段上添加索引
........
注意:唯一性比较弱的字段上添加索引用处不大。
二、视图(view)
1、定义
站在不同的角度看待同一份数据。
2、如何创建视图对象?怎么删除视图对象?
创建新表dept2:
create table dept2 as select * from dept;
select * from dept2;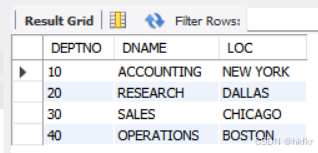
创建视图对象:
create view dept2_view as select * from dept2;
删除视图对象:
drop view dept2_view;注意:只有DQL语句才能以view的形式创建。
create view view_name as 这里的语句必须是DQL语句。
3、用视图做什么?
可以面向视图对象进行增删改查,对视图对象的增删改查,会导致原表被操作!
视图特点:通过对视图的操作,会影响到原表数据!!!
①面向视图查询:
select * from dept2_view;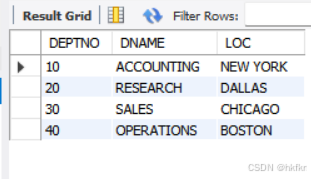
②面向视图插入:
insert into dept2_view(deptno,dname,loc) values (50,'MARKETING','BEIJING');
select * from dept2_view;//查询原表数据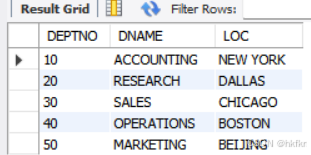
③面向视图删除:
delete from dept2_view;
④面向视图更新(原表被更改)
update dept2_view set loc='LONDON' where deptno=50;4、视图对象在实际开发中到底有什么用?(方便,简化开发,利于维护)
create view
emp_dept_view
as
select
e.ename,e.sal,d.dname
from
emp e
join
dept d
on
e.deptno=d.deptno;假设有一条非常复杂的sql语句,而这条sql语句需要在不同的位置重复使用。每一次使用这个sql语句的时候需要重新编写,很长,很麻烦,怎么办?
- 可以把这条复杂的sql语句以视图对象的形式新建。
- 在需要编写sql语句的位置直接使用视图对象,可以大大简化开发。
- 并且利于后期的维护,因为修改的时候只需要一个位置就行,只需要修改视图对象所映射的sql语句。
面向视图开发的时候,使用视图可以像table一样对视图进行增删改查等操作。视图不是在内存当中,视图对象存储在磁盘上,不会消失。
再提醒:视图对应的语句只能是DQL语句。但是视图对象创建完成之后,可以对视图进行增删改查等操作。
小插曲:
增删改查,又叫做:CRUD
C:Create(增)
R:Retrive(查:检索)
U:Update(改)
D:delete(删)
三、DBA常用命令
重点掌握数据的导入、导出(数据的备份)
1、数据的导出
注意:在windows的dos命令窗口中,而不是mysql命令行中:
mysqldump -u root -p bjpowernode > D:\bjpowernode.sql 
可以到处指定的表吗?
mysqldump -u root -p bjpowernode emp > D:\bjpowernode_emp.sql 
2、数据的导入
注意:
- 需要先登录到mysql数据库服务器上
- 然后创建数据库:create database bjpowernode;
- 使用数据库:use bjpowernode;
- 然后初始化数据库:source D:\bjpowernode.sql;
四、数据库设计的三范式
1、什么是数据库设计范式?
数据库表的设计依据。教你怎么进行数据库表的设计。
2、数据库设计范式共有3个
- 第一范式:要求任何一张表必须有主键,每一个字段原子不可再分。
- 第二范式:建立在第一范式的基础之上,要求所有非主键字段完全依赖主键,不要产生部分依赖。
- 第三范式:建立在第二范式的基础之上,要求所有非主键字段直接依赖主键,不要产生传递依赖。
声明:三范式是面试官经常问的,一定要熟记于心!!
设计数据库表的时候,按照以上的范式进行,可以避免表中数据的冗余,空间的浪费。
3、第一范式
最核心、最重要,所有表的设计都需要满足。
必须有主键,并且每一个字段都是原子不可再分。
学生编号 学生姓名 联系方式
-----------------------------------------------------------------------
1001 张三 zs@gmail.com,1359999999
1002 李四 ls@gmail.com,13699999999
1001 王五 ww@163.net,13488888888
以上是学生表,满足第一范式吗?
不满足:第一,没有主键。第二,联系方式可以分为邮箱、地址、电话。
学生编号(pk) 学生姓名 邮箱地址 联系电话
--------------------------------------------------------------------------------------------
1001 张三 zs@gmail.com 1359999999
1002 李四 ls@gmail.com 13699999999
1003 王五 ww@163.net 13488888888
4、第二范式
建立在第一范式的基础之上,要求所有非主键字段完全依赖主键,不要产生部分依赖。
学生编号 学生姓名 教师编号 教师姓名
---------------------------------------------------------------
1001 张三 001 王老师
1002 李四 002 赵老师
1003 王五 001 王老师
1004 张三 002 赵老师
是否满足第二范式?
不满足:第一,不满足第一范式,没有主键;第二,存在部分依赖。
如何满足第一范式?
学生编号+教师编号(pk) 学生姓名 教师姓名
-----------------------------------------------------------------------
1001 001 张三 王老师
1002 002 李四 赵老师
1003 001 王五 王老师
1004 002 张三 赵老师
学生编号,教师编号,两个字段联合做主键,复合主键(pk:学生编号+教师编号)
不满足第二范式,张三依赖1001,王老师依赖001,显然产生了部份依赖。(缺点:数据冗余、空间浪费)
如何满足第二范式?
使用三张表,表示多对多关系!!
学生表:
学生编号(pk) 学生名字
------------------------------------
1001 张三
1002 李四
1003 王五
教师表:
教师编号(pk) 教师姓名
--------------------------------------
001 王老师
002 赵老师
学生教师关系表:
id(pk) 学生编号(fk) 教师编号(fk)
------------------------------------------------------
1 1001 001
2 1002 002
3 1003 001
4 1001 002
背口诀:多对多怎么设计?
多对多,三张表,关系表两个是外键!!!
5、第三范式
建立在第二范式的基础之上,要求所有非主键字段直接依赖主键,不要产生传递依赖。
学生编号(PK) 学生姓名 班级编号 班级名称
--------------------------------------------------------------
1001 张三 01 一年一班
1002 李四 02 一年二班
1003 王五 03 一年三班
1004 赵六 03 一年三班
以上表的设计描述是:班级和学生的关系。很显然是一对多关系!
满足第一范式
满足第二范式,以为主键不是复合主键,没有产生部份依赖。主键是单一主键。
是否满足第三范式?
一年一班依赖01,01依赖1001,产生传递依赖。
如何设计一对多?
班级表:一
班级编号(pk) 班级名称
----------------------------------------
01 一年一班
02 一年二班
03 一年三班
学生表:多
学生编号(PK) 学生姓名 班级编号(fk)
-------------------------------------------
1001 张三 01
1002 李四 02
1003 王五 03
1004 赵六 03
背诵口诀:一对多怎么设计?
一对多,两张表,多的表加外键!!!
5、总结
- 一对多:
一对多,两张表,多的表加外键!!!!!!!!!!!!
- 多对多:
多对多,三张表,关系表两个外键!!!!!!!!!!!!!!!
- 一对一:
一对一,外键唯一!!!!!!!!!!!!!!!
一对一放到一张表中不就行了吗?为啥还要拆分表?
在实际的开发中,可能存在一张表字段太多,太庞大。这个时候要拆分表。
一对一怎么设计?
没有拆分表之前:一张表
t_user:
id login_name login_pwd real_name email address........
---------------------------------------------------------------------------
1 zhangsan 123 张三 zhangsan@xxx
2 lisi 123 李四 lisi@xxx
...
这种庞大的表建议拆分为两张:
t_login 登录信息表
id(pk) login_name login_pwd
---------------------------------------
1 zhangsan 123
2 lisi 123
t_user 用户详细信息表
id(pk) real_name email address........ login_id(fk+unique)
-----------------------------------------------------------------------------------------
100 张三 zhangsan@xxx 1
200 李四 lisi@xxx 2

















 1194
1194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









