






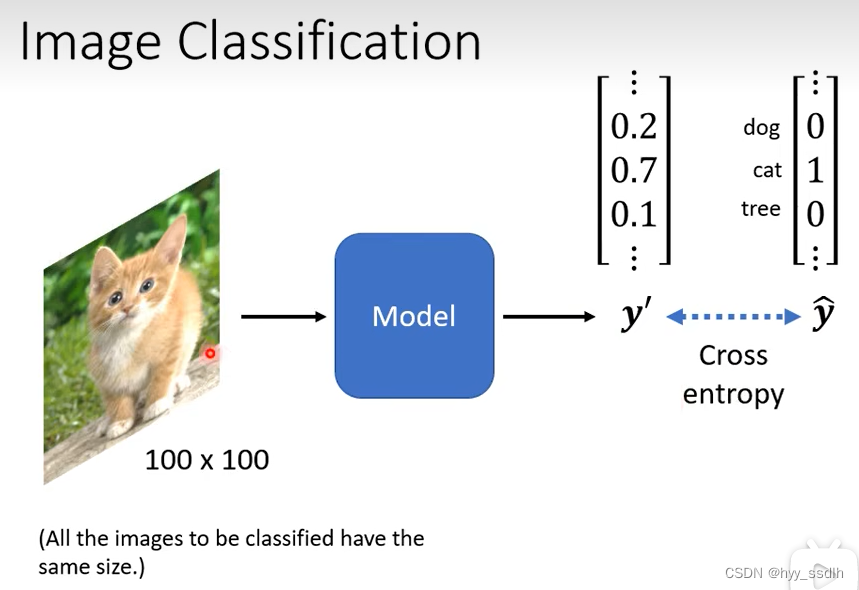
将一张映像输入到模型中,得到该映像的类别,其中y向量中每一个值代表该映像是该类型的可能性。
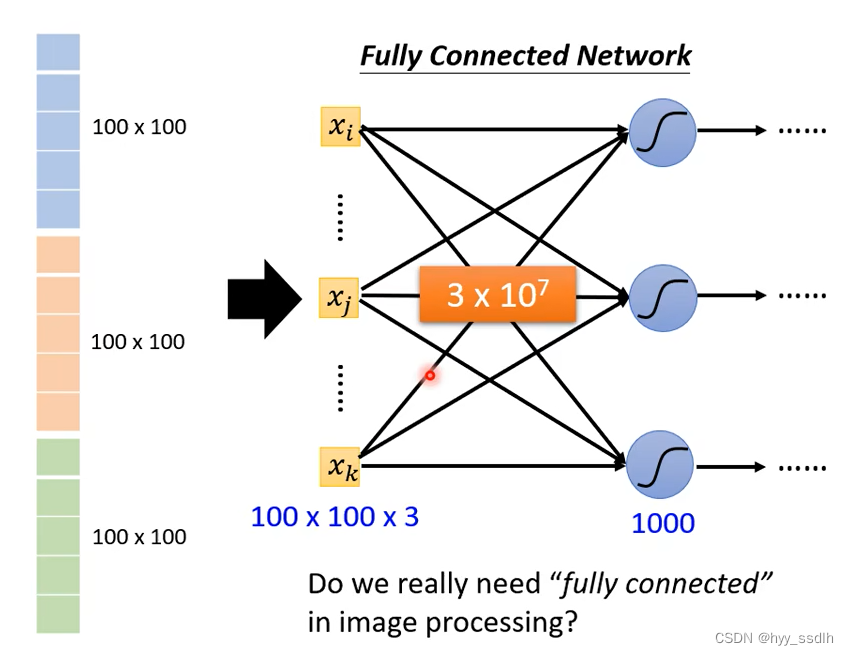
图片如何输入?
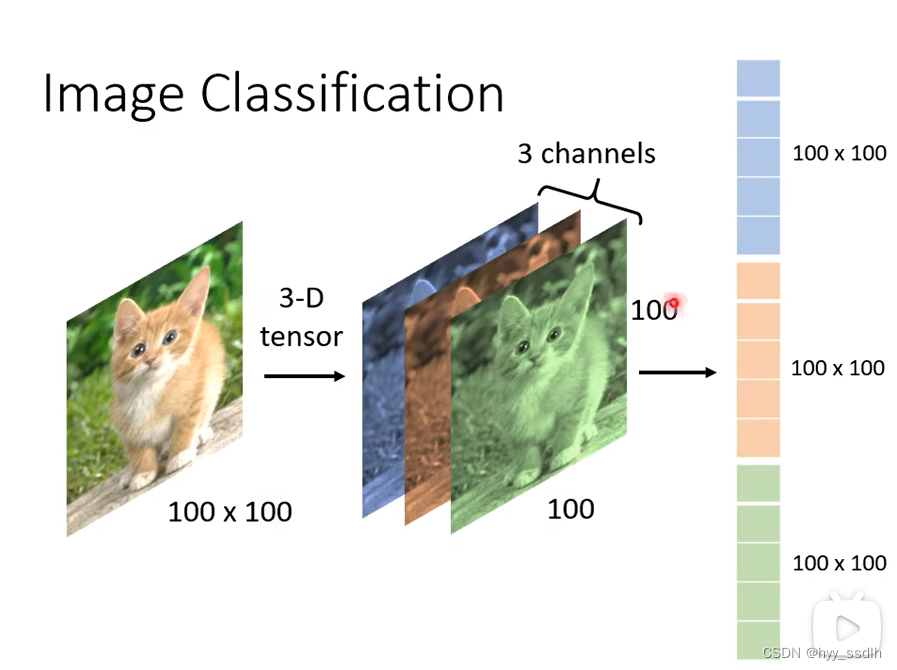
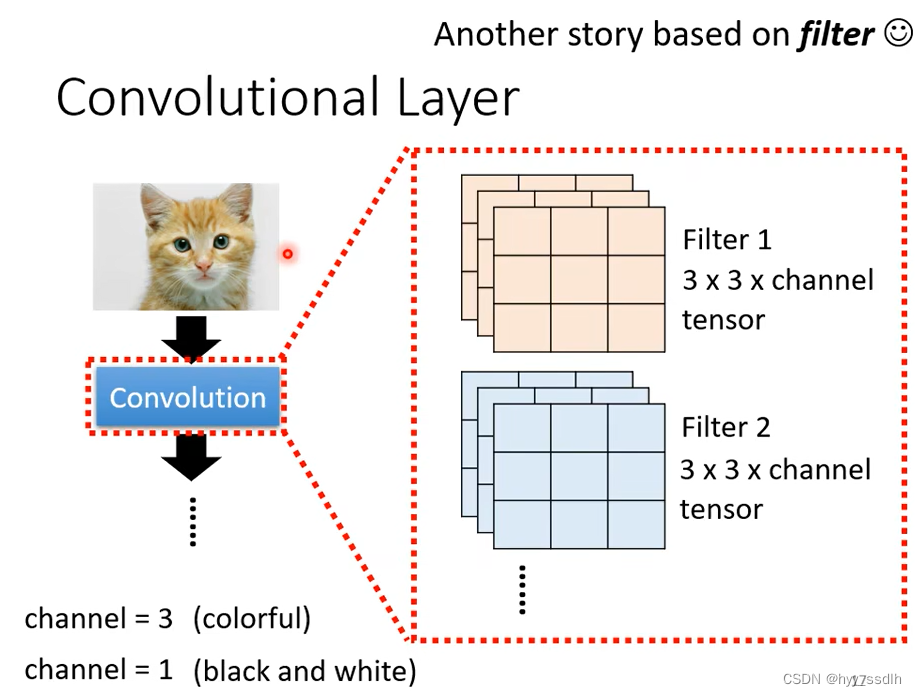
在电脑中,一个彩色图片由三个通道组成(RGB),将该向量写开,则向模型组输入该向量
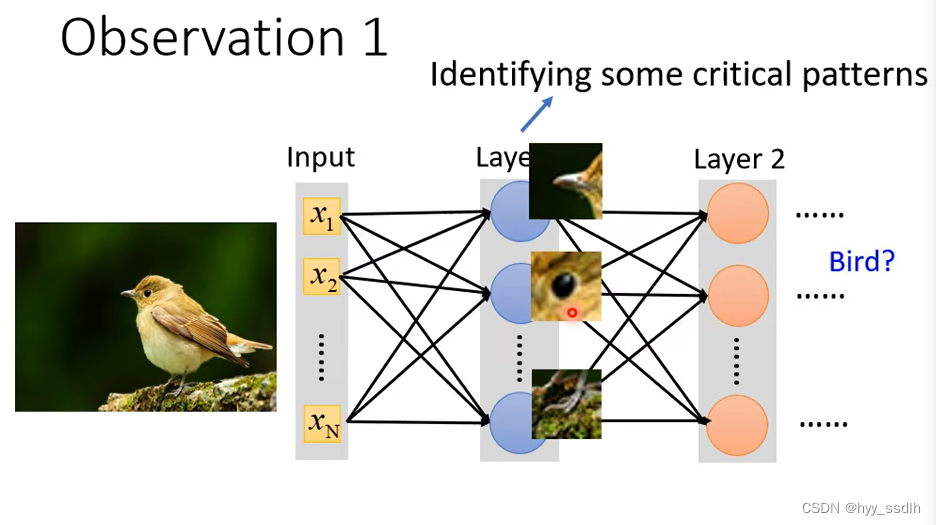
要对图像特征进行观察,定义一些显著的特征,从而识别出图像的实体。neuro负责判断其对应的patterns是否出现。
在CNN中每个neuro有一个自己的receptive field,每个neuro只负责自己receptive field中的事情。
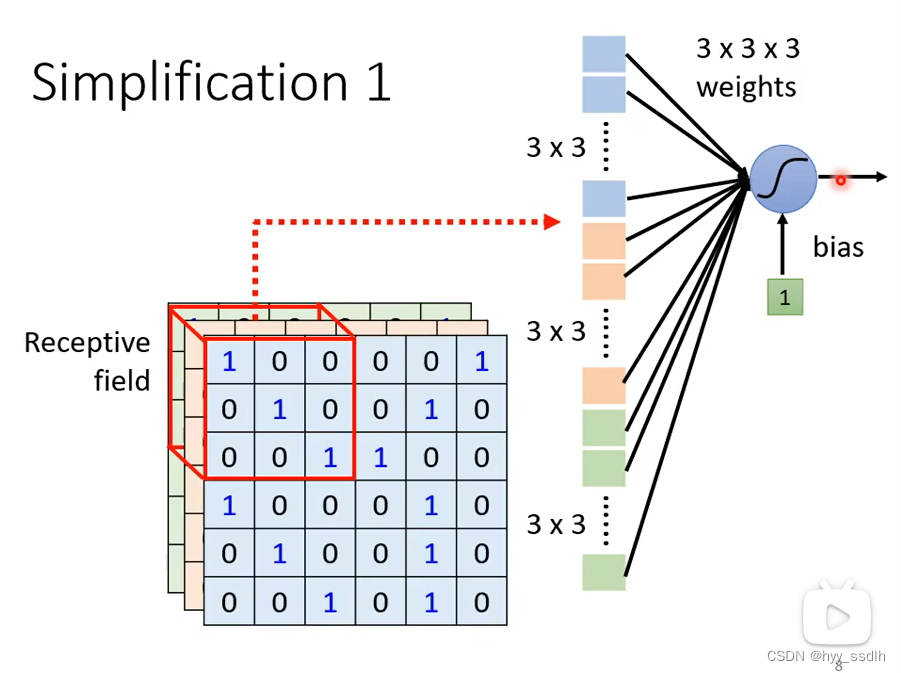
例如上图将neuro负责的receptive field展开成一个 3*3*3的向量,将 该27位向量作为输入进行处理,并将输出给下一层。
receptive field可以有重叠,多个neuro可守卫同一个receptive field。receptive field大小可以不一,可以任意设计
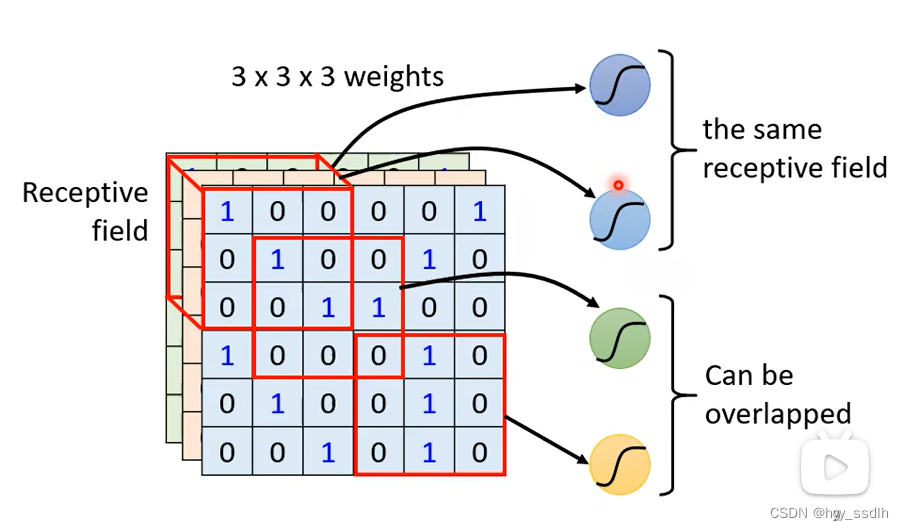
最经典的all channels
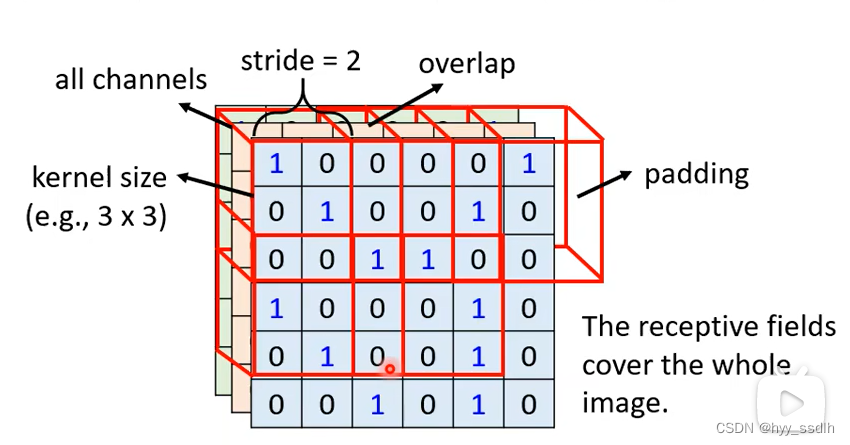
超出边界外的叫做padding,超出部分补数。整张图,每个地方都被receptive field扫过
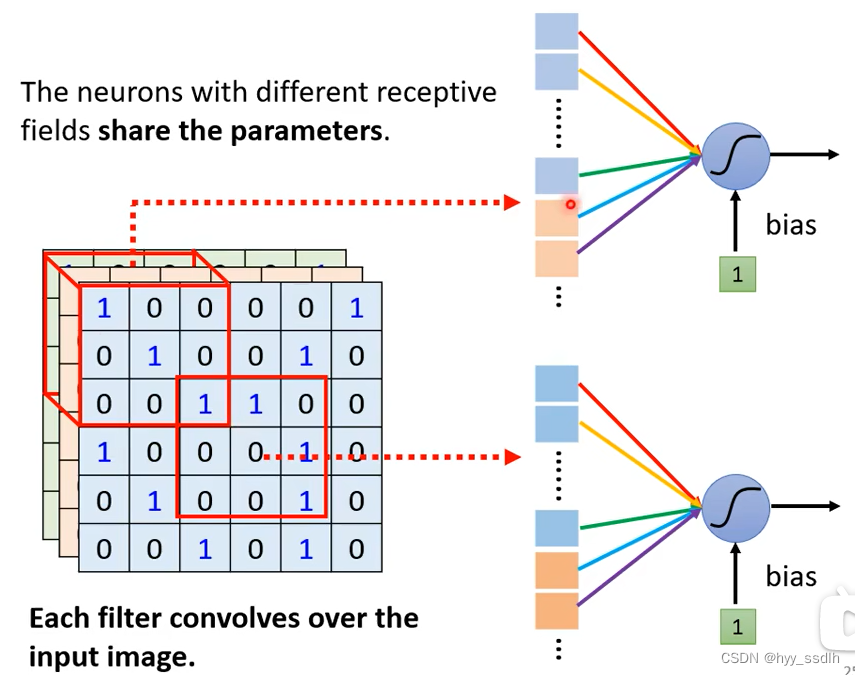
在不同的图像中,同样的pattern可能出现在图片的不同区域。neuro在对数据的处理时所作的操作都是相同的,不同的是所守卫的receptive field不同。每个receptive field并不需要都有一个对应pattern的neuro,只需要共享参数便可以解决这个问题。
如下图,两个neuro共享参数,即两个neuro的w完全一致。虽然两个neuro完全一致,但因为输入不同会得到不同的输出
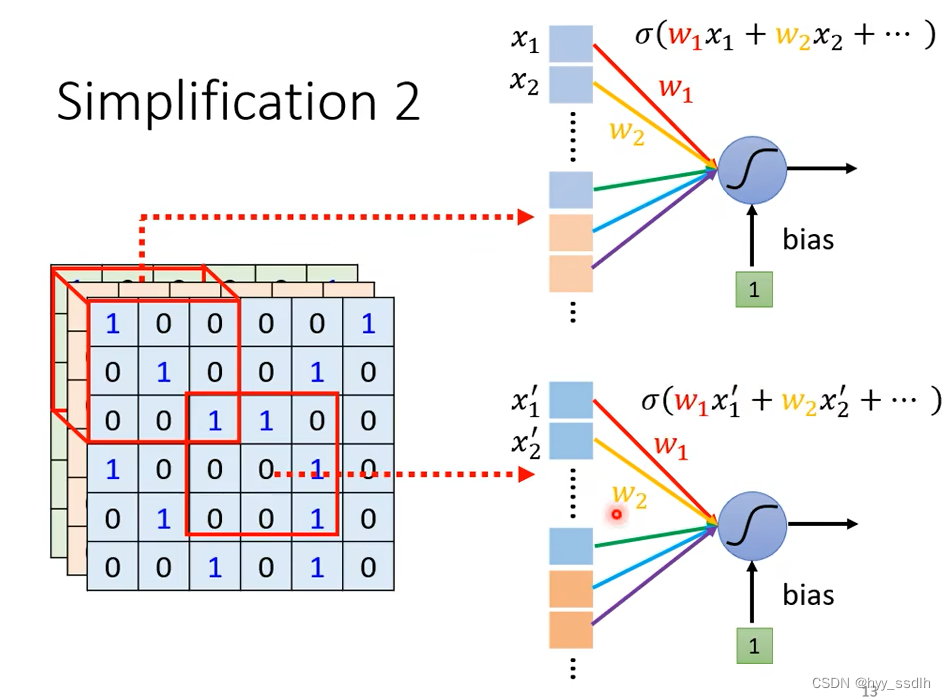
因此不能让两个receptive field完全一致的neuro共享参数。
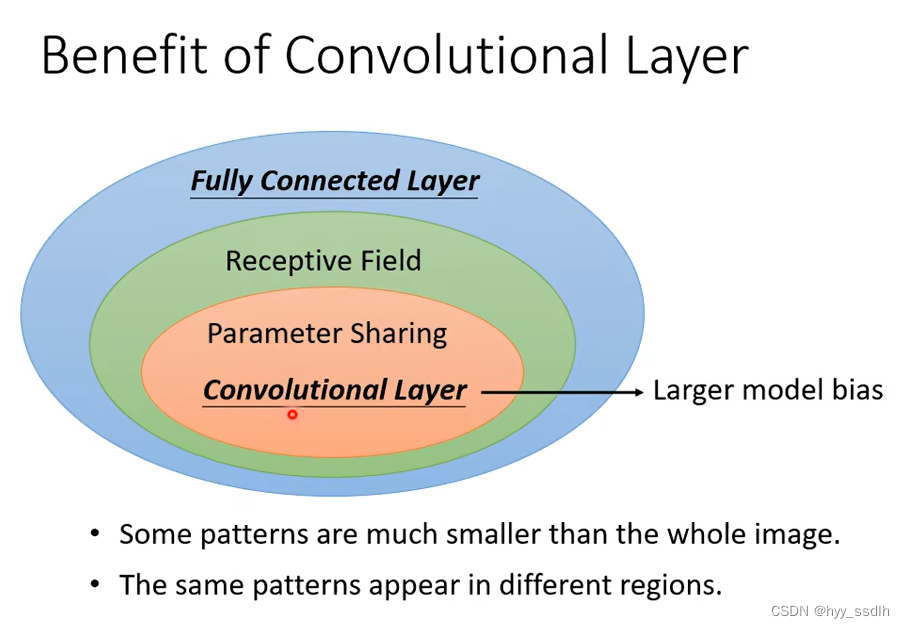
Fully connected layer会观察整个图像,加入receptive field后限制了neuro的弹性,neuro加入参数共享后会变成convolutional layer,此时model bias会更大,但model bias大不一定是件坏事。当model bias较小,model的灵活度太高时,更容易overfitting的情况。
Fully connected layer灵活度高,可以做各种事情各种变化。convolutional layer灵活度低,专门为图像设计,在图像处理上会做更好。
CNN的另一种解释
图像通过卷积层抓取图像的pattern,卷积层里有很多filter向图片中抓取pattern,下图设filter大小为3*3*channel
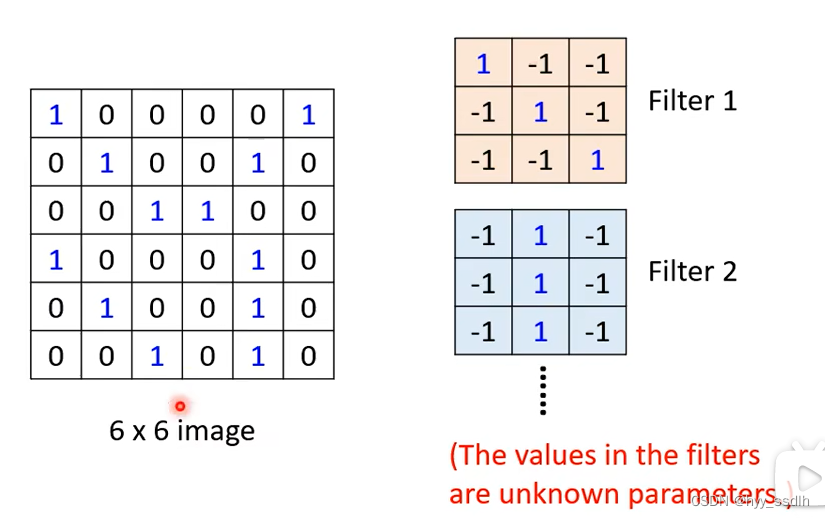
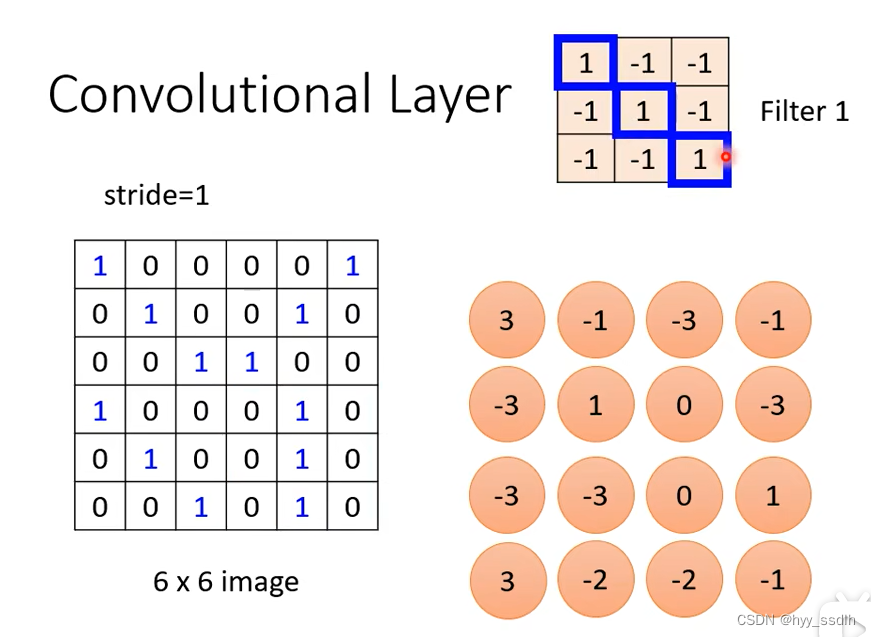
下面我们来看filter如何抓取pattern,下面我们设channel=1,得到如下右边两个filter,左边为图像。
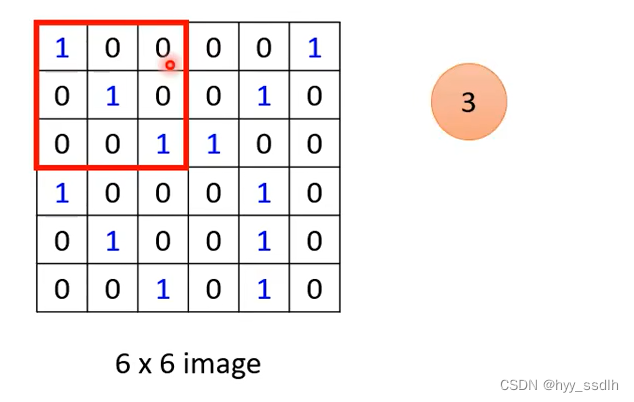
接下来使用filter1对图像pattern进行抓取。将filter1放在图像左上角,并与左上角九个值进行相乘并相加得到3
接下来将filter移动stride步,并继续与图像中九个值相乘相加,算出来是-1
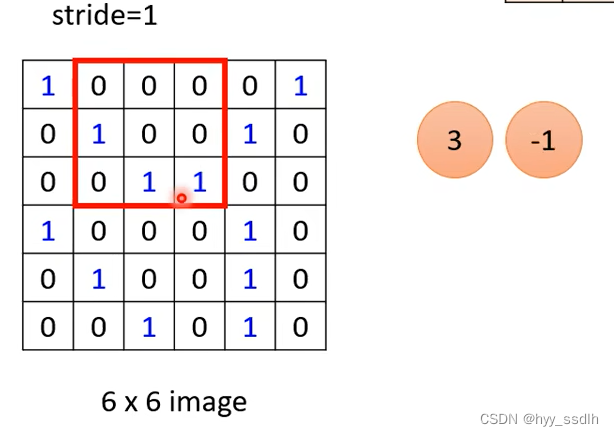
以此类推,将全部 图像中全部值都扫过一遍,得到以下结果。
观察filter1发现,filter1对角线全为1,估当img中也出现对角线三个1 时值最大
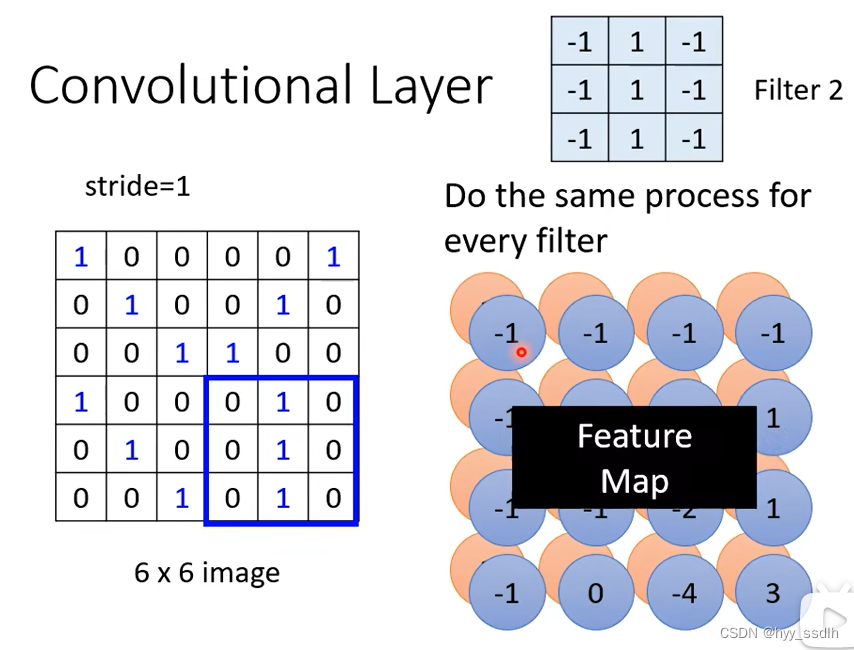
同理使用filter2抓取图像中的pattern,得到如下结果,有几组filter就可以得到多少组数据。我们将这些数据统一称为feature map。
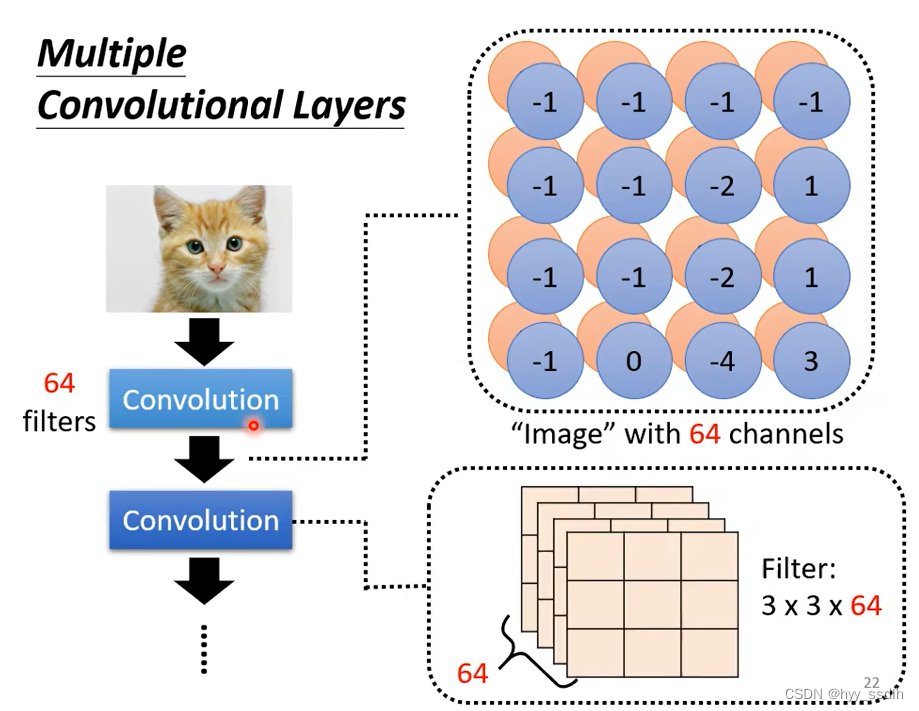
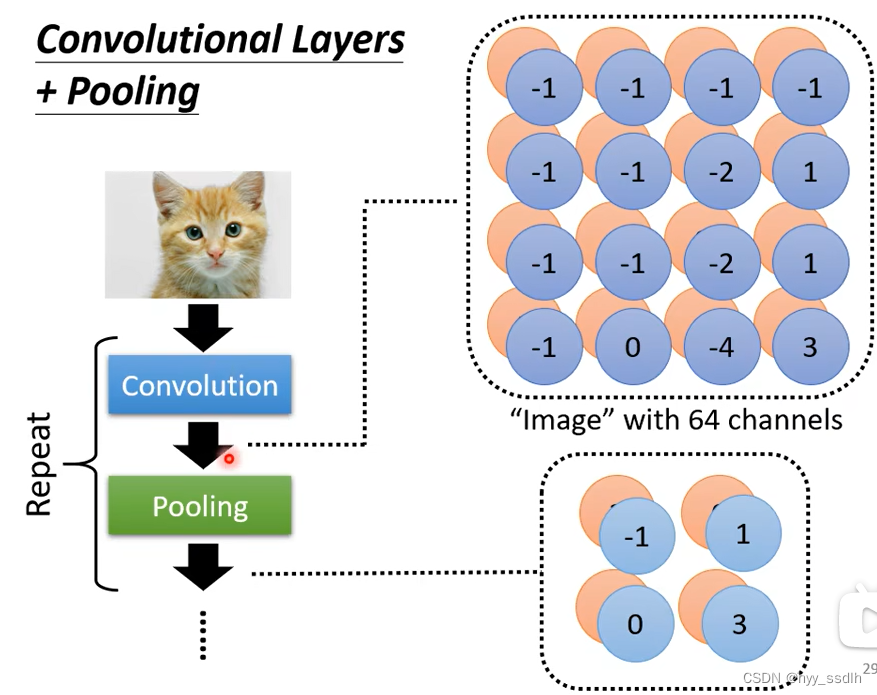
当一个图像通过一次卷积层,便可得到一个feature map。其中feature map的channel数主要由filter的个数决定。feature map仍可以继续深层次进行卷积。下图中filter1为64个,为了扫到feature map中全部的数值,filter2的高度也必须是64
下图中不同neuro共用参数实际上就是将filter扫过一整张图。
pooling
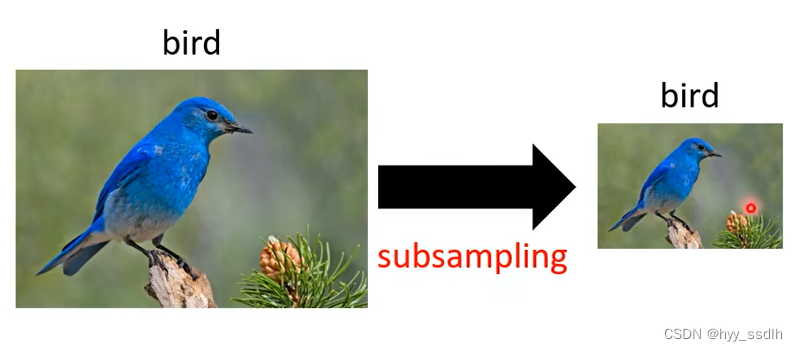
在处理图像问题时,我们还常用到pooling方法,如下图,将一个图片缩小,仍能看出它是一只鸟
pooling有很多种类,例如下图中max pooling中。将filter卷积后的数据每2*2进行一个分组。选取每一组中最大的数为代表。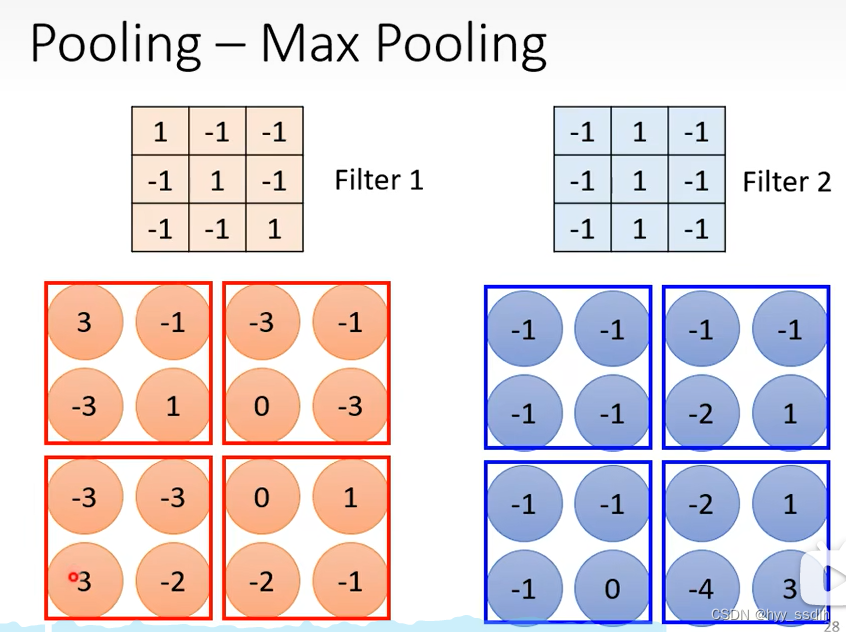
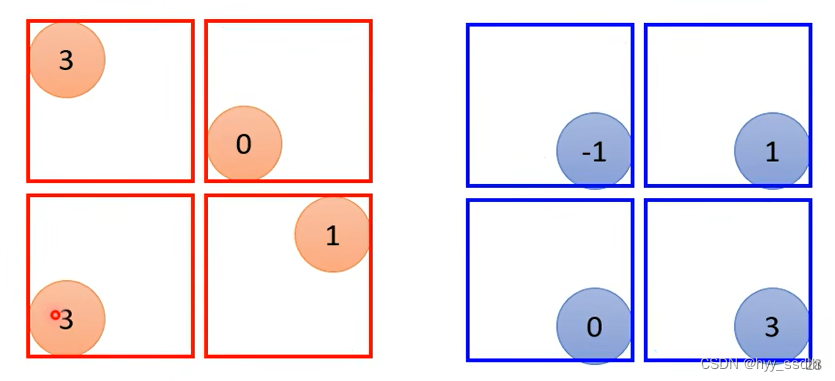
一般在实训中convolution往往和pooling交替使用,pooling主要负责将convolution的feature map缩小。
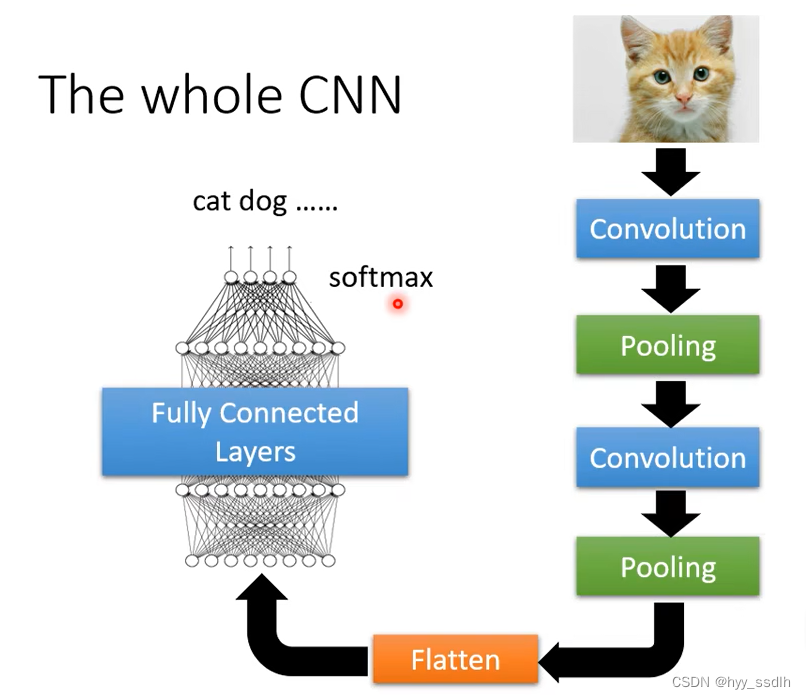
CNN的整个过程如下图,将图片进行convolution和pooling,之后将得到的feature map进行flatten,flatten是将多维数据展开成一维数组。之后将一位数组放在fully connected layers中进行训练,之后经过一个softmax得到该图片否类型。
CNN不能处理图像放大缩小或旋转的问题
**

















 1827
1827

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









