







探秘Transformer系列之(1):注意力机制
0x00 概述
因为各种事情,好久没有写博客了,之前写得一些草稿也没有时间整理(都没有时间登录博客和微信,导致最近才发现好多未读消息,在这里和各位朋友说下万分抱歉)。
现在恢复更新,是因为最近有些从非AI领域转过来的新同学来找我询问是否有比较好的学习资料,他们希望在短期内迅速上手 Transformer。我在网上找了下,但是没有找到非常合适的系统的学习资料,于是就萌发了自己写一个系列的想法,遂有此系列。在整理过程中,我也发现了自己很多似是而非的错误理解,因此这个系列也是自己一个整理、学习和提高的过程。
本系列试图从零开始解析Transformer,目标是
-
解析Transformer如何运作,以及为何如此运作,让新同学可以入门Transformer。
-
力争融入一些比较新的或者有特色的论文或者理念,让老鸟也可以通过阅读本系列来了解一些新观点,有所收获。
几点说明:
- 本系列是对论文、博客和代码的学习和解读,借鉴了很多网上朋友的文章,在此表示感谢,并且会在参考中列出。因为本系列参考文章太多,可能有漏给出处的现象。如果原作者发现,还请指出,我在参考文献中进行增补。
- 本系列有些内容是个人梳理和思考的结果(反推或者猜测),可能和原始论文作者的思路或者与实际历史发展轨迹不尽相同。这么写是因为这样推导让我觉得可以给出直观且合理的解释。如果理解有误,还请各位读者指出。
- 对于某些领域,这里会融入目前一些较新的或者有特色的解释,因为笔者的时间和精力有限,难以阅读大量文献。如果有遗漏的精品文献,也请各位读者指出。
本文为系列第一篇,主要目的是引入Transformer概念和其相关背景。在2017年,Google Brain的Vaswani等人在论文”Attention is All You Need“中发布了Transformer。原始论文中给出Transformer的定义如下:
Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence aligned RNNs or convolution。
其中提到了sequence,RNN,convolution,self-attention等概念,所以我们接下来就从这些概念入手进行分析。我们先开始从Seq2Seq介绍,然后逐渐切换到注意力机制,最后再导出Transformer模型架构。
文章目录
注:全部文章列表在这里,估计最终在35篇左右,后续每发一篇文章,会修改文章列表。
csdn 探秘Transformer系列之文章列表
0x01 背景知识
本节我们将介绍一些背景知识和概念。
1.1 seq2seq
seq2seq(Sequence to Sequence/序列到序列)概念最早由Bengio在2014年的论文“Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation”中提出,其代表从一个源序列生成一个目标序列的操作。因为机器翻译是大家较熟悉且容易理解的领域,因此后续我们主要使用机器翻译来进行讲解,避免引入过多概念。
1.2 文本生成机制
机器翻译其实就是文本生成。语言模型将文本看作是时间序列。在此视角下,每个单词都和它之前的单词相关,通过学习前面单词序列的统计规律就可以预测下一个单词。因此,机器翻译会从概率角度对语言建模,让新预测的单词和之前单词连成整个句子后最合理,即原有句子加上新预测单词后,成为整个句子的概率最大。这就涉及到自回归模型。
1.3 自回归模型
自回归(Autoregressive)模型是一种生成模型,其语言建模目标是根据给定的上下文来预测下一个单词。遵循因果原则(当前单词只受到其前面单词的影响),自回归模型的核心思想是利用一个变量的历史值来预测其未来的值,其将"序列数据的生成"建模为一个逐步预测每个新元素的条件概率的过程。在每个时间步,模型根据之前生成的元素预测当前元素的概率分布。
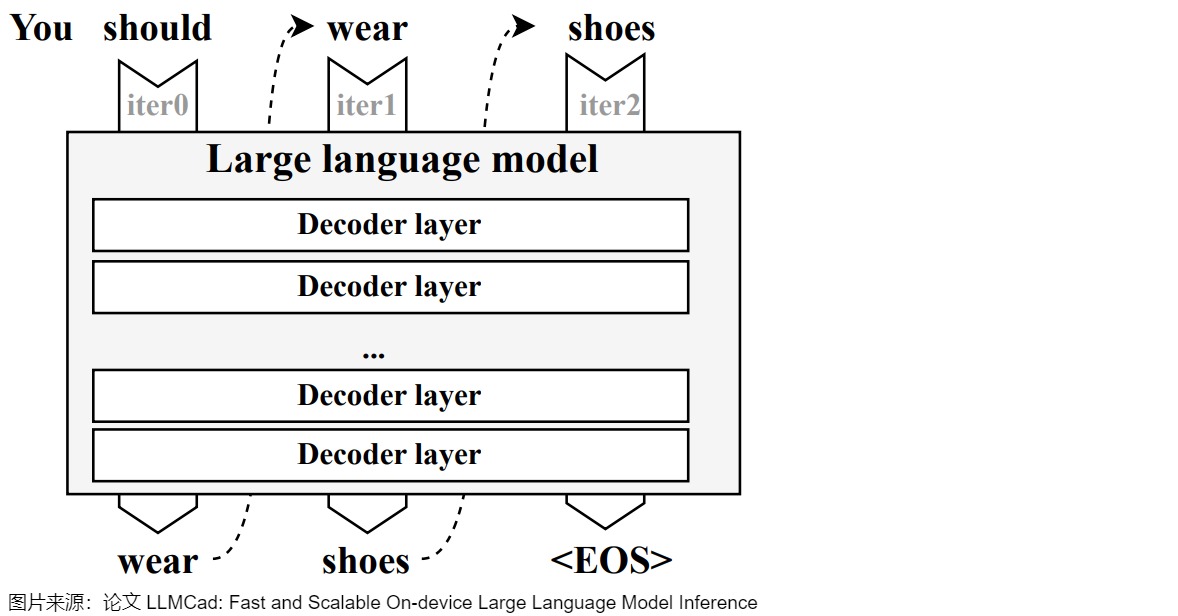
下图给出了自回归模型的示例。模型每次推理只会预测输出一个 token,当前轮输出token 与历史输入 token 拼接,作为下一轮的输入 token,这样逐次生成后面的预测token,直到新输出一个结束符号或者句子长度达到预设的最大阈值。就下图来说,模型执行序列如下:
-
第一轮模型的输入是“You should”。
-
第一轮模型推理输出“wear”。
-
将预测出的第一个单词“wear”结合原输入一起提供给模型,即第二次模型的输入是“You should wear”。
-
第二次模型推理输出“shoes”。
-
将预测出的第二个单词“shoes”结合原输入一起提供给模型,即第三次模型的输入是“You should wear shoes”。
-
第三次推理输出结束符号,本次预测结束。
该过程中的每一步预测都需要依赖上一步预测的结果,且从第二轮开始,前后两轮的输入只相差一个 token。
自回归模式有几个弊端:
- 容易累积错误,导致训练效果不佳,因为后面的推理对之前推理的输出会有依赖。在训练初期,模型尚不成熟,几次随机输出会导致随后的训练很难学到任何东西。“一步错,步步错”,训练会变得极不稳定,很难收敛,浪费训练资源。
- 只能以串行方式进行,这意味着很难以并行化的方式开展训练、提升效率。
1.4 隐变量自回归模型
隐变量模型是一种引入隐变量来表示过去信息的模型。自回归模型在预测时会把过去观测到的信息总结起来记作 h t h_t ht,并且更新预测 x t x_t xt。即总结 h t = g ( h t − 1 , x t − 1 ) h_t = g(h_{t-1}, x_{t-1}) ht=g(ht−1,xt−1),然后基于 x t = P ( x t ∣ h t ) x_t = P(x_t \mid h_{t}) xt=P(xt∣ht)来估计 x t x_t xt。由于 h t h_t ht从未被观测到,因此 h t h_t ht就是隐变量,这类模型也被称为隐变量自回归模型(latent autoregressive models)。
有了 h t ℎ_t ht之后,其实预测变换为两个子问题。一个问题是如何根据之前的隐变量 h t − 1 ℎ_{t−1} ht−1 和之前的输入信息 x t − 1 x_{t-1} xt−1得到现在的隐变量 h t ℎ_t ht,另一个问题是如何根据当前的隐变量 h t ℎ_t ht和之前的输入 x t − 1 x_{t-1} xt−1得到当前的 x t x_t xt 。其实,这就是编码器-解码器模型要面对的问题。
1.5 编码器-解码器模型
目前,处理序列转换的神经网络模型大多是编码器-解码器(Encoder-Decoder)模型。传统的RNN架构仅适用于输入和输出等长的任务。然而,大多数情况下,机器翻译的输出和输入都不是等长的,因此,对于输入输出都是变长的序列,研究人员决定使用一个定长的状态机来作为输入和输出之间的桥梁。于是人们使用了一种新的架构:前半部分的RNN只有输入,后半部分的RNN只有输出(上一轮的输出会当作下一轮的输入以补充信息),两个部分通过一个隐状态(hidden state)来传递信息。把隐状态看成对输入信息的一种编码的话,前半部分可以叫做编码器(Encoder),后半部分可以叫做解码器(Decoder)。这种架构因而被称为编码器-解码器架构,所用到的模型就是编码器-解码器模型,具体如下图所示,图中编码器和解码器通过一个中间隐状态C来完成信息交互。
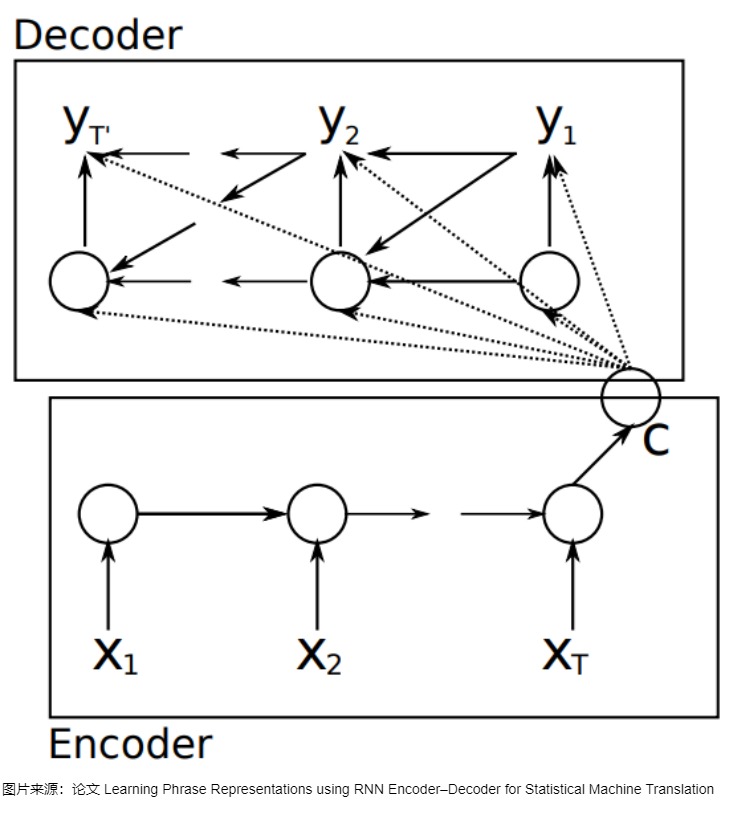
编码器和解码器的作用分别如下:
- 编码器把输入句子的所有语义信息压缩成一个固定长度的中间语义向量(也称为上下文向量或隐向量或隐状态),该向量包含了可供计算与学习的、代表句子语言特点和含义的特征信息,是输入的浓缩摘要。具体逻辑为:
- 编码器会对输入句子 X = ( x 1 , . . . , x n ) X = (x_1, ..., x_n) X=(x1,...,xn) 的每个词进行处理,处理每个词之后会产生一个隐状态。
- 从输入的第二个词开始,编码器每个时刻的输入是上一个时刻的隐状态和输入的新单词。
- 编码器输出的最后一个时刻的隐状态就是编码了整个句子语义的语义上下文(context),这是一个固定长度的高维特征向量 C = ( z 1 , . . . , z n ) C = (z_1, ..., z_n) C=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 559
559

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









