






Elasticsearch
一、概念
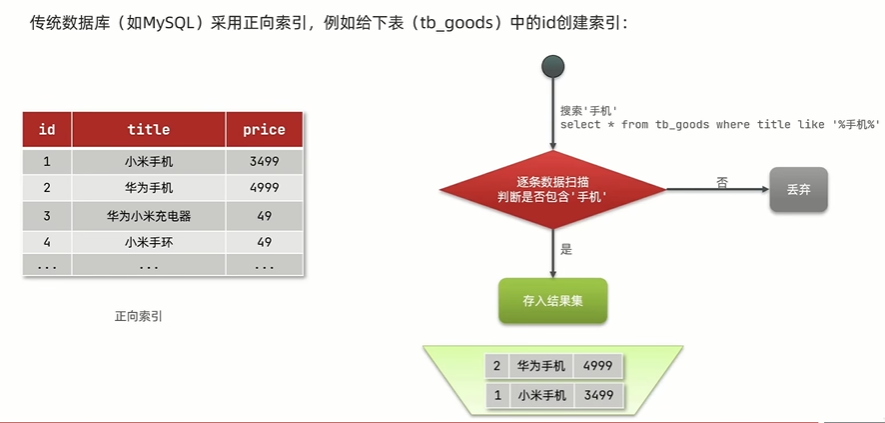
正向索引
基于文档id创建索引,查询词条时必须先找到文档,而后判断是否包含词条
倒排索引
对文档内容分词,对词条创建索引,并记录词条所在文档的信息,查询时先根据词条查询到文档id,而后获取到文档
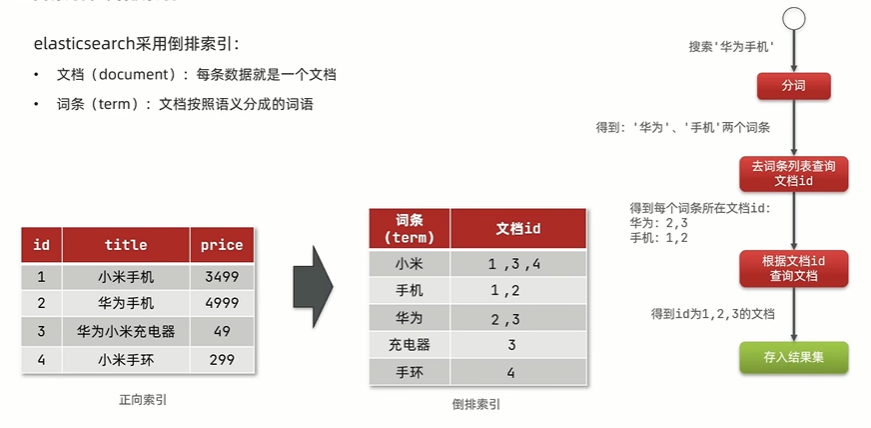
文档
elasticsearch是面向文档存储的,可以是数据库中的一条商品数据,一个订单信息。文档数据会被序列化为json格式后存储在elasticsearch中

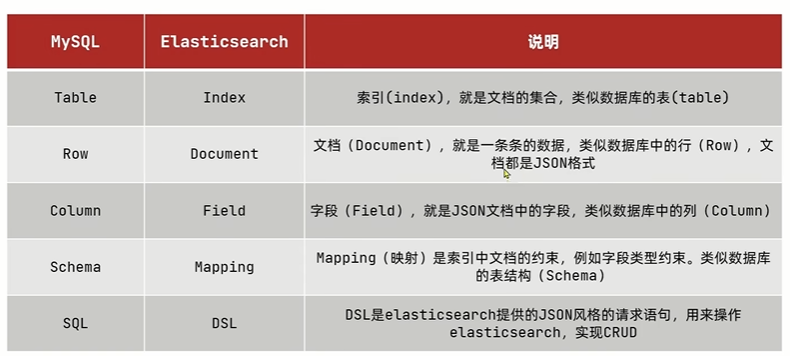
索引(index)
索引(index):相同类型文档的集合
映射(mapping):索引中文档字段约束信息,类似表的结构约束

概念对比
二、安装
安装es
1、部署单节点es
首先创建一个网络,让kibana与es使用同一个网络
docker network create es-net
2、拉取镜像
# 拉取es镜像,指定版本号
docker pull elasticsearch:7.17.18
# 拉取kibana镜像
docker pull kibana:7.17.18
3、运行命令
docker run -d --name es \
--network es-net \
--ulimit memlock=-1:-1 \
-v /home/es/data:/usr/share/elasticsearch/data \
-v /home/es/plugins:/usr/share/elasticsearch/plugins \
-v /home/es/config:/usr/share/elasticsearch/config \
-p 9200:9200 \
-p 9300:9300 \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "network.host=0.0.0.0" \
-e "discovery.type=single-node" \
-e "bootstrap.memory_lock=true" \
elasticsearch:7.17.18
命令解释:
- -e “cluster.name=es-docker-cluster”:设置集群名称
- -e “http.host=0.0.0.0”:监听的地址,可以外网访问
- -e “discovery.type=single-node”:非集群模式
- -e “ES_JAVA_OPTS=-Xms512m -Xmx512m”:内存大小
- -v /home/es/data:/usr/share/elasticsearch/data:挂载数据卷,绑定es的数据目录
- -v /home/es/plugins:/usr/share/elasticsearch/plugins:挂载数据卷,绑定es的插件目录
- -v /home/es/logs:/usr/share/elasticsearch/logs:挂载数据卷,绑定es的日志目录
- –privileged:授予数据卷访问权
- –network es-net:加入一个名为es-net的网络中
- -p 9200:9200:端口映射
通过命令查看是否运行成功
docker ps -a
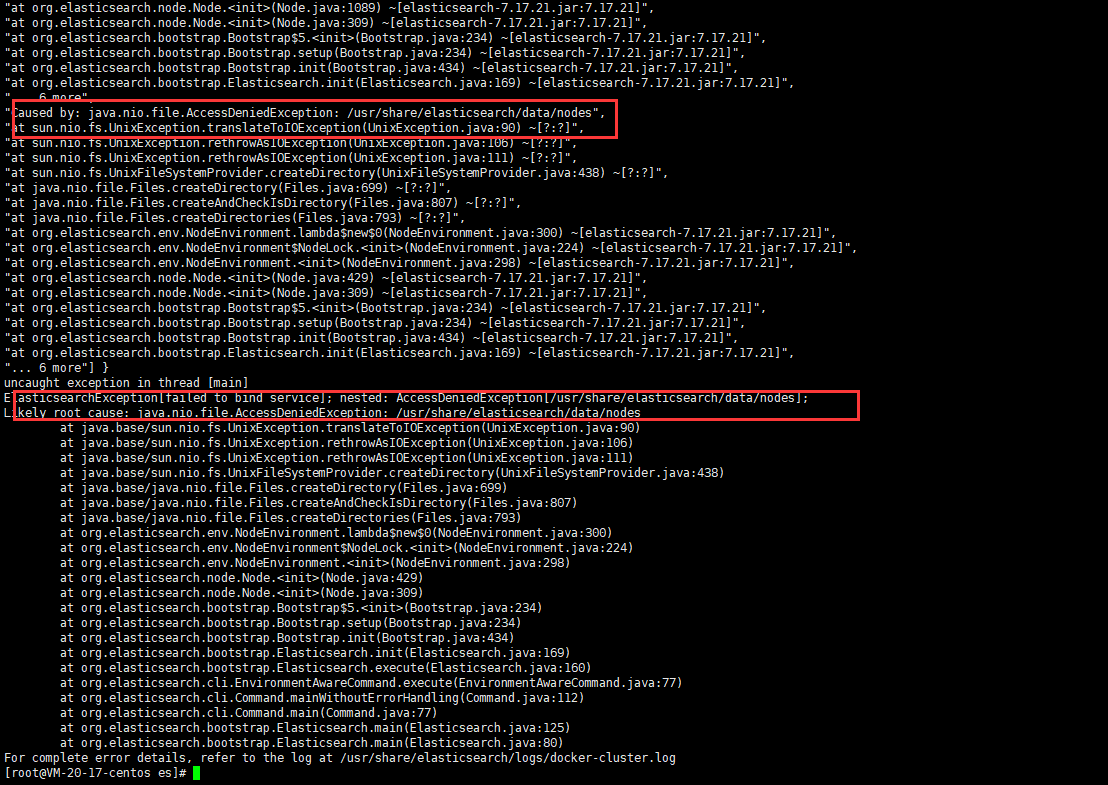
问题:
由于挂载在宿主机上的目录,es执行写入时权限不足导致的无法启动,需要分配权限
# 直接给两个目录最高权限
chmod 777 /home/es/data
chmod 777 /home/es/plugins
重新启动,浏览器访问 ip+9200端口,出现json数据输出为成功启动
安装kibana
用于执行es命令
(1)执行命令
# 直接安装,不需要自定义yml
docker run -d --name kibana \
--network=es-net \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
-v /home/kibana/config:/usr/share/kibana/config \
-p 5601:5601 \
kibana:7.17.18
# 使用自定义的yml配置,挂载config配置目录在宿主机上
docker run -d --name kibana \
--network=es-net \
-v /home/kibana/config:/usr/share/kibana/config \
-p 5601:5601 \
kibana:7.17.18
命令解读:
- –network es-net:设置网络
- -e ELASTICSEARCH_HOST=http://es:9200:连接到es,容器名+端口号
(2)启动成功后
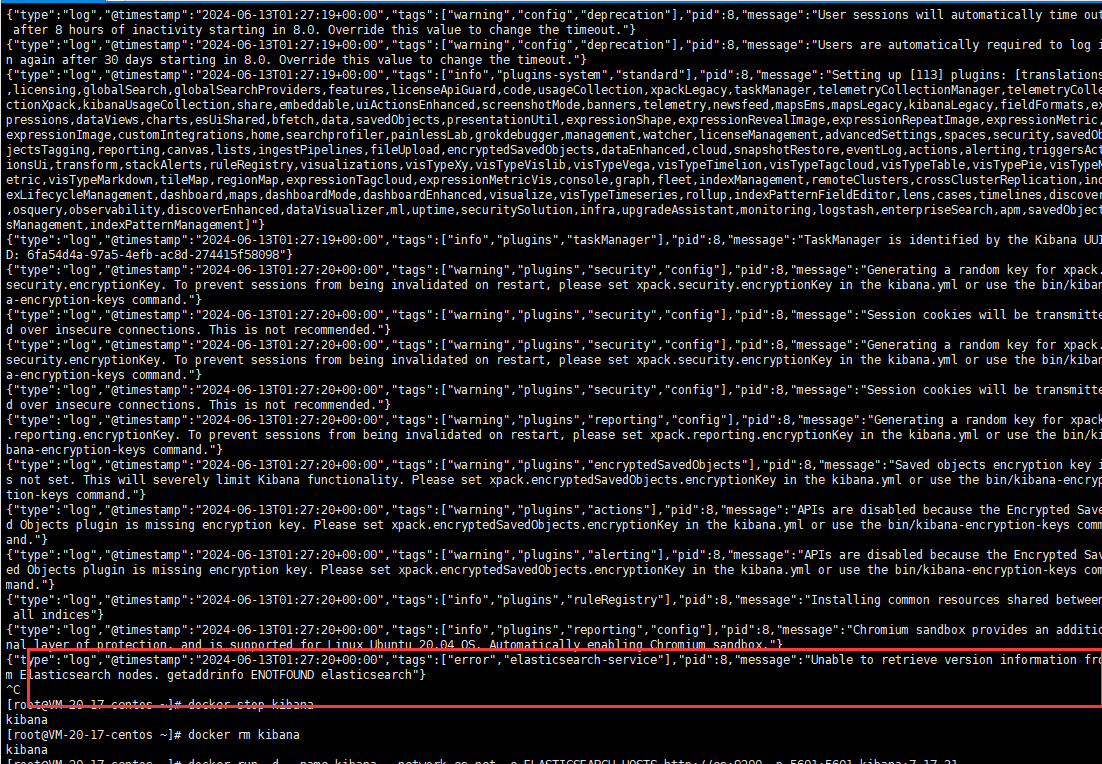
(3)报错
未连接上Elasticsearch,检查配置的es地址是否是正确的
安装IK分词器
(1)下载分词器
到github官网下载ik分词器对应版本,版本要跟es相同:https://github.com/infinilabs/analysis-ik
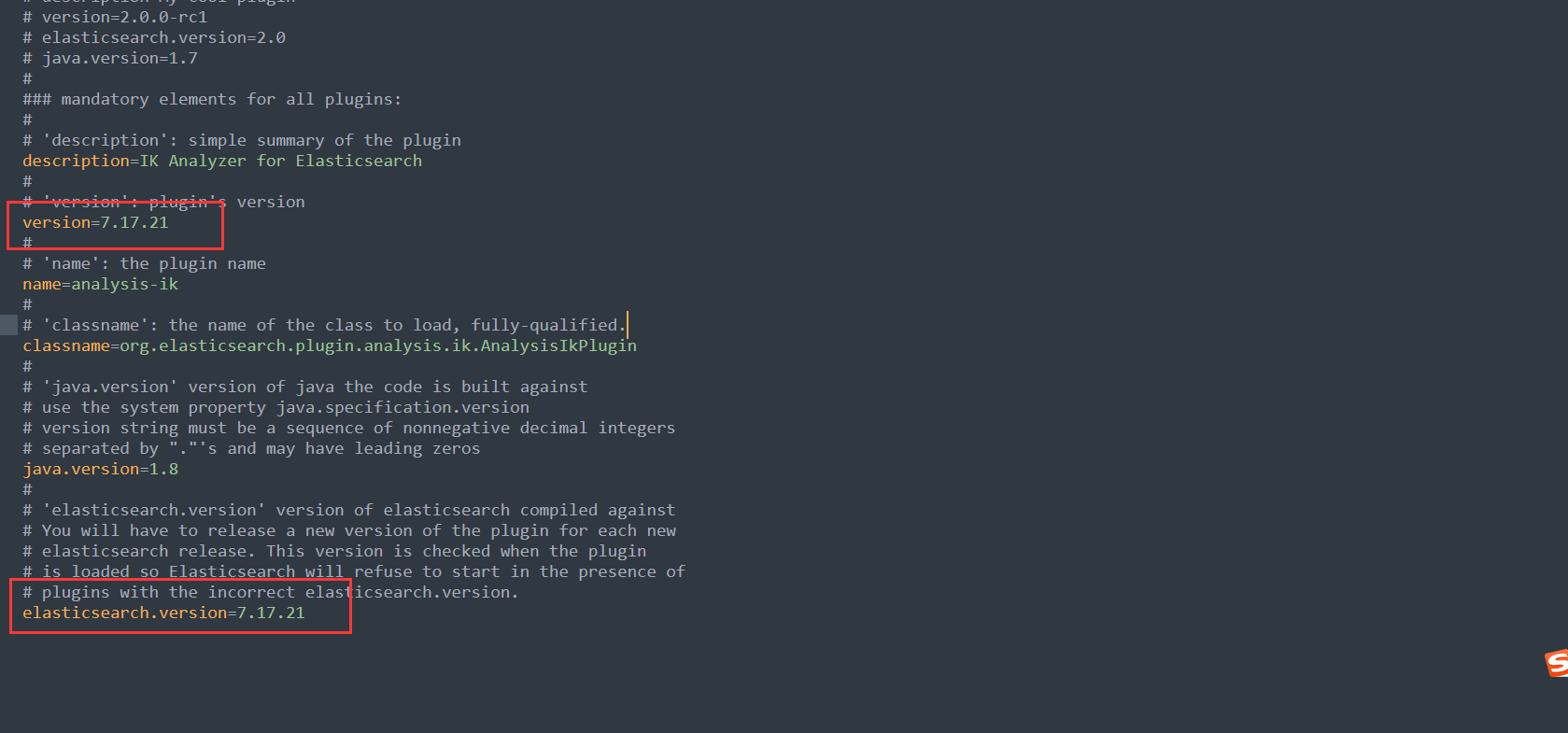
如果没有找到相同版本的,那就下载一个,解压后修改 plugin-descriptor.properties 文件中的版本号
(2)上传
在es容器的宿主机数据卷目录下,新建一个ik目录,将解压后的文件全部上传,上传完成后,重启es容器
docker restart es
(3)测试
ik分词器包含两种模式:
- ik_smart:最少切分
- ik_max_word:最细切分
(4)分词调整
ik中的config目录下可以使用自定义分词
修改config目录下的 IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
默认config目录下已经存在了 stopword.dic 这个文件,直接在xml文件中配置即可
新建ext.dic文件,并将自定义的词放进去,添加完成后,放在 config目录下即可
ext.dic文件配置如下图所示:
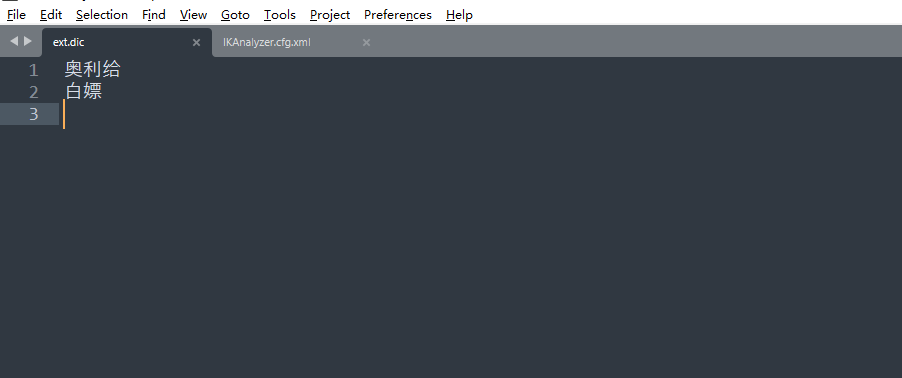
stopword.dic 文件配置同理
添加完成后,重启es容器,重新加载
docker restart es
测试结果:
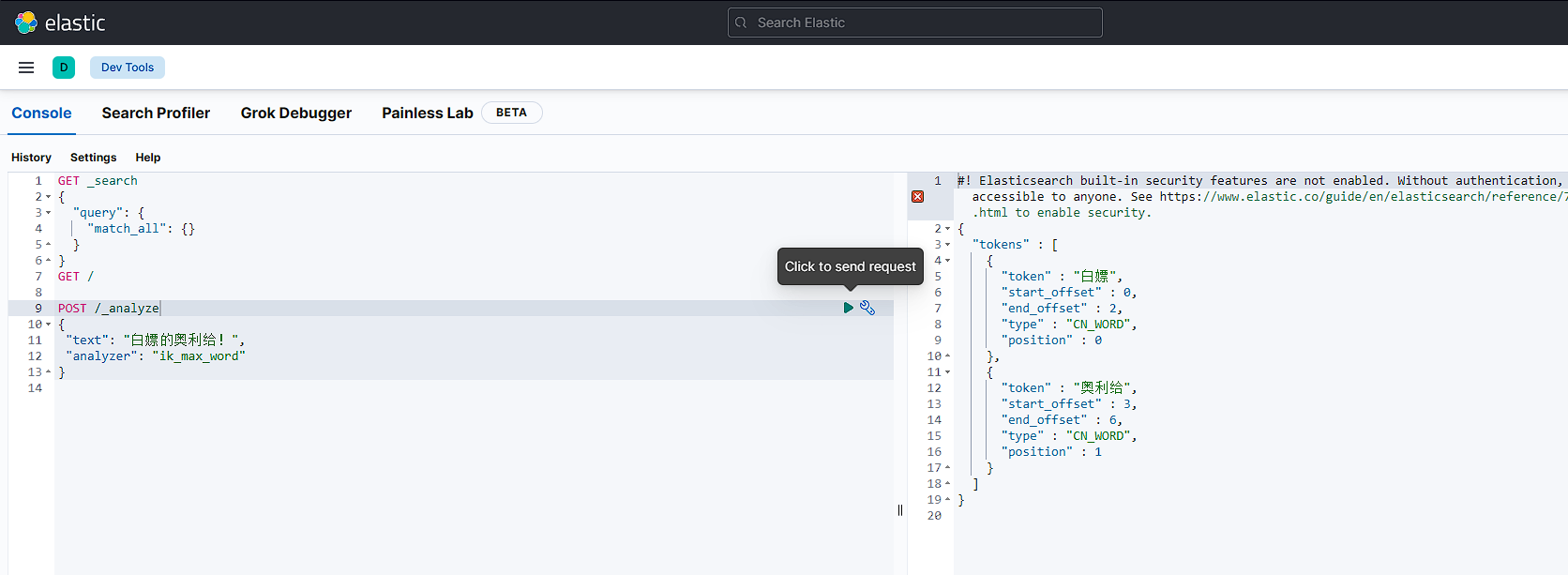
三、索引库
官方手册:https://www.elastic.co/guide/en/elasticsearch/reference/7.17/index.html
1、mapping属性(常见)
mapping是对索引库中文档的约束,常见的mapping属性包括:
- type:字段数据类型,常见的简单类型有:
- 字符串:text(可分词文本)、keyword(精确值:例如:品牌、国家、ip地址)
- 数值:long、integer、short、byte、double、float
- 布尔:boolean
- 日期:date
- 对象:object
- index:是否创建索引,默认为true,是否参与搜索,不参与搜索的即可为false
- analyzer:使用那种分词器
- properties:该字段的子字段
以上为常见的属性,更多属性可在 https://www.elastic.co/guide/en/elasticsearch/reference/7.17/mapping-params.html 查询
2、索引库操作
(1)新增
使用DSL语法进行创建,语法是json风格的
# 创建名为 /test1 的索引库
PUT test1
{
"mappings": {
"properties": {
"info": {
"type": "text",
"analyzer": "ik_smart"
},
"email": {
"type": "keyword",
"index": false
},
"name": {
"type": "object",
"properties": {
"firstName": {
"type": "keyword"
},
"lastName": {
"type": "keyword"
}
}
}
}
}
}
(2)查询
GET /索引库名称
# 示例
GET /test1
(3)删除
DELETE /索引库名称
# 示例
DELETE /test2
(4)修改
es是禁止修改索引库,因为一旦修改了索引库,就会导致原有的倒排索引就会失效
可以进行新增索引
PUT /索引库/_mapping
{
"properties": {
"属性名": {
"type": "类型"
}
}
}
# 示例
PUT /test1/_mapping
{
"properties": {
"age": {
"type": "integer"
}
}
}
3、文档操作
(1)新增
DSL语法
POST /索引库名/_doc/文档id
{
"字段1":"值1",
"字段2":"值2",
"字段3": {
"子属性1":"值3",
"子属性2":"值4"
}
}
# 示例
POST /test1/_doc/1
{
"age":23,
"email":"1066541346@qq.com",
"info":"一个正在学习java的程序员",
"name":{
"firstName":"张",
"lastName":"三"
}
}
注意:如果不加文档id,那么es就会认为这个文档没有id,es就会默认生成一个id
(2)查询文档
DSL语法
GET /索引库名/_doc/文档id
# 示例
GET /test1/_doc/1
查询结果:
{
"_index" : "test1", # 所在索引库
"_type" : "_doc", # 类型为文档
"_id" : "3", # 文档id
"_version" : 1, # 版本控制,每做一次修改,版本都会更新
"_seq_no" : 2,
"_primary_term" : 1,
"found" : true,
"_source" : { # 插入的原始文档
"age" : 23,
"email" : "1066541346@qq.com",
"info" : "一个正在学习python的程序员",
"name" : {
"firstName" : "王",
"lastName" : "五"
}
}
}
(3)删除文档
DELETE /索引库名/_doc/文档id
# 示例
DELETE /test1/_doc/4
(4)修改文档
方式一:全量修改,会将旧文档删除,添加新文档,与新增文档差不多,只是POST请求变为PUT请求
如果传入的文档id在索引库中不存在,那么就不会执行旧文档删除的步骤,直接新增新文档
PUT /索引库名/_doc/文档id
{
"字段1":"值1",
"字段2":"值2",
"字段3": {
"子属性1":"值3",
"子属性2":"值4"
}
}
# 示例
PUT /test1/_doc/1
{
"age":23,
"email":"1066541346@qq.com",
"info":"一个正在学习java的程序员",
"name":{
"firstName":"张",
"lastName":"三"
}
}
方式二:增量修改,修改指定的字段值
这个方式的文档只修改文档中的指定要修改的属性的值,并不会去修改其他的值
如果在索引库中根据文档id查询时,没有这个文档,则修改时会报404错误,找不到该文档
POST /索引库名/_update/文档id
{
"doc": {
"属性名":"属性值"
}
}
# 示例
POST /test1/_update/1
{
"doc": {
"age": 100
}
四、RestClient操作
ES官方提供了各种不同语言的客户端,用来操作ES。这些客户端本质就是组装DSL语句,通过http请求发送给ES
官方文档地址:https://www.elastic.co/guide/en/elasticsearch/client/index.html
在使用RestClien之前先初始化一个springboot项目
首先准备一个数据库,表名为:tb_hotel
CREATE TABLE `tb_hotel` (
`id` bigint NOT NULL COMMENT '酒店id',
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '酒店名称',
`address` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '酒店地址',
`price` int NOT NULL COMMENT '酒店价格',
`score` int NOT NULL COMMENT '酒店评分',
`brand` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '酒店品牌',
`city` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '所在城市',
`star_name` varchar(16) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '酒店星级,1星到5星,1钻到5钻',
`business` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '商圈',
`latitude` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '纬度',
`longitude` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '经度',
`pic` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '酒店图片',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci ROW_FORMAT=COMPACT;
插入100条酒店数据
INSERT INTO `tb_hotel` VALUES (1, '阳光大酒店', '北京市朝阳区大街123号', 500, 9, '如家', '北京', '五星级', '朝阳区', '39.904202', '116.407394', 'pic1.jpg');
INSERT INTO `tb_hotel` VALUES (2, '海景度假村', '上海市浦东新区海滨大道456号', 600, 8, '锦江之星', '上海', '四星级', '浦东新区', '31.230391', '121.473701', 'pic2.jpg');
INSERT INTO `tb_hotel` VALUES (3, '华美达酒店', '广州市天河区东风东路789号', 450, 7, '华住', '广州', '三星级', '天河区', '23.129163', '113.264435', 'pic3.jpg');
INSERT INTO `tb_hotel` VALUES (4, '绿洲宾馆', '深圳市南山区科技园101号', 300, 8, '维也纳', '深圳', '四星级', '南山区', '22.543097', '114.057861', 'pic4.jpg');
INSERT INTO `tb_hotel` VALUES (5, '江南酒店', '杭州市西湖区文三路202号', 350, 9, '开元', '杭州', '五星级', '西湖区', '30.274085', '120.155070', 'pic5.jpg');
INSERT INTO `tb_hotel` VALUES (6, '云海酒店', '重庆市渝中区解放碑123号', 400, 7, '格林豪泰', '重庆', '四星级', '渝中区', '29.563761', '106.550464', 'pic6.jpg');
INSERT INTO `tb_hotel` VALUES (7, '山水酒店', '成都市锦江区春熙路456号', 320, 8, '全季', '成都', '三星级', '锦江区', '30.572815', '104.066803', 'pic7.jpg');
INSERT INTO `tb_hotel` VALUES (8, '君悦酒店', '武汉市武昌区中南路789号', 480, 9, '亚朵', '武汉', '五星级', '武昌区', '30.546498', '114.341745', 'pic8.jpg');
INSERT INTO `tb_hotel` VALUES (9, '湖滨酒店', '苏州市姑苏区观前街101号', 360, 7, '布丁', '苏州', '四星级', '姑苏区', '31.298886', '120.585316', 'pic9.jpg');
INSERT INTO `tb_hotel` VALUES (10, '紫荆花酒店', '西安市莲湖区大庆路202号', 380, 8, '希尔顿', '西安', '五星级', '莲湖区', '34.341574', '108.939770', 'pic10.jpg');
INSERT INTO `tb_hotel` VALUES (11, '银杏树酒店', '南京市玄武区中山路123号', 330, 7, '丽枫', '南京', '三星级', '玄武区', '32.060255', '118.796877', 'pic11.jpg');
INSERT INTO `tb_hotel` VALUES (12, '星空酒店', '天津市和平区南京路456号', 450, 9, '喜来登', '天津', '五星级', '和平区', '39.085100', '117.199370', 'pic12.jpg');
INSERT INTO `tb_hotel` VALUES (13, '海天大酒店', '青岛市市南区东海西路789号', 410, 8, '香格里拉', '青岛', '四星级', '市南区', '36.067235', '120.382606', 'pic13.jpg');
INSERT INTO `tb_hotel` VALUES (14, '彩虹酒店', '大连市中山区人民路101号', 300, 7, '万豪', '大连', '三星级', '中山区', '38.914003', '121.614682', 'pic14.jpg');
INSERT INTO `tb_hotel` VALUES (15, '天鹅湖酒店', '沈阳市和平区中山路202号', 380, 8, '锦江之星', '沈阳', '四星级', '和平区', '41.805699', '123.431472', 'pic15.jpg');
INSERT INTO `tb_hotel` VALUES (16, '凤凰酒店', '长春市朝阳区解放大路123号', 320, 7, '维也纳', '长春', '三星级', '朝阳区', '43.817072', '125.323544', 'pic16.jpg');
INSERT INTO `tb_hotel` VALUES (17, '兰花酒店', '哈尔滨市南岗区中山路456号', 390, 9, '华住', '哈尔滨', '五星级', '南岗区', '45.803775', '126.534967', 'pic17.jpg');
INSERT INTO `tb_hotel` VALUES (18, '牡丹江酒店', '郑州市金水区东风路789号', 360, 8, '开元', '郑州', '四星级', '金水区', '34.746303', '113.625350', 'pic18.jpg');
INSERT INTO `tb_hotel` VALUES (19, '玉龙雪山酒店', '昆明市盘龙区北京路101号', 330, 7, '如家', '昆明', '三星级', '盘龙区', '25.040609', '102.712251', 'pic19.jpg');
INSERT INTO `tb_hotel` VALUES (20, '海韵酒店', '厦门市思明区湖滨南路202号', 410, 8, '布丁', '厦门', '四星级', '思明区', '24.479834', '118.089425', 'pic20.jpg');
INSERT INTO `tb_hotel` VALUES (21, '金鹰酒店', '济南市历下区泉城路123号', 370, 9, '全季', '济南', '五星级', '历下区', '36.651216', '117.120095', 'pic21.jpg');
INSERT INTO `tb_hotel` VALUES (22, '天海酒店', '福州市鼓楼区五一路456号', 340, 8, '亚朵', '福州', '四星级', '鼓楼区', '26.075302', '119.306239', 'pic22.jpg');
INSERT INTO `tb_hotel` VALUES (23, '丽晶酒店', '南宁市青秀区民族大道789号', 350, 7, '格林豪泰', '南宁', '三星级', '青秀区', '22.817002', '108.366543', 'pic23.jpg');
INSERT INTO `tb_hotel` VALUES (24, '海角酒店', '海口市龙华区滨海大道101号', 420, 9, '丽枫', '海口', '五星级', '龙华区', '20.044002', '110.198293', 'pic24.jpg');
INSERT INTO `tb_hotel` VALUES (25, '紫金山酒店', '贵阳市云岩区中山西路202号', 310, 7, '希尔顿', '贵阳', '四星级', '云岩区', '26.647003', '106.630242', 'pic25.jpg');
INSERT INTO `tb_hotel` VALUES (26, '星辰酒店', '长沙市芙蓉区五一路123号', 380, 8, '喜来登', '长沙', '五星级', '芙蓉区', '28.228209', '112.938814', 'pic26.jpg');
INSERT INTO `tb_hotel` VALUES (27, '天际线酒店', '南昌市东湖区中山路456号', 370, 9, '香格里拉', '南昌', '四星级', '东湖区', '28.682892', '115.858197', 'pic27.jpg');
INSERT INTO `tb_hotel` VALUES (28, '星海湾酒店', '合肥市包河区金寨路789号', 340, 7, '万豪', '合肥', '三星级', '包河区', '31.820591', '117.227219', 'pic28.jpg');
INSERT INTO `tb_hotel` VALUES (29, '都市阳光酒店', '呼和浩特市新城区新华大街101号', 360, 8, '锦江之星', '呼和浩特', '四星级', '新城区', '40.841490', '111.751990', 'pic29.jpg');
INSERT INTO `tb_hotel` VALUES (30, '蓝海酒店', '兰州市城关区东方红广场202号', 330, 7, '维也纳', '兰州', '三星级', '城关区', '36.061089', '103.834304', 'pic30.jpg');
INSERT INTO `tb_hotel` VALUES (31, '西部酒店', '乌鲁木齐市天山区人民路123号', 400, 9, '华住', '乌鲁木齐', '五星级', '天山区', '43.825592', '87.616848', 'pic31.jpg');
INSERT INTO `tb_hotel` VALUES (32, '绿洲宾馆', '银川市兴庆区解放东路456号', 310, 7, '开元', '银川', '四星级', '兴庆区', '38.487194', '106.230909', 'pic32.jpg');
INSERT INTO `tb_hotel` VALUES (33, '江南酒店', '石家庄市长安区中山东路789号', 380, 8, '如家', '石家庄', '三星级', '长安区', '38.042759', '114.514297', 'pic33.jpg');
INSERT INTO `tb_hotel` VALUES (34, '云海酒店', '太原市小店区迎泽大街101号', 390, 9, '布丁', '太原', '五星级', '小店区', '37.870590', '112.548879', 'pic34.jpg');
INSERT INTO `tb_hotel` VALUES (35, '君悦酒店', '郑州市金水区花园路202号', 370, 8, '全季', '郑州', '四星级', '金水区', '34.746303', '113.625350', 'pic35.jpg');
INSERT INTO `tb_hotel` VALUES (36, '湖滨酒店', '长春市朝阳区解放大路123号', 350, 7, '亚朵', '长春', '三星级', '朝阳区', '43.817072', '125.323544', 'pic36.jpg');
INSERT INTO `tb_hotel` VALUES (37, '紫荆花酒店', '沈阳市和平区太原街456号', 400, 9, '格林豪泰', '沈阳', '五星级', '和平区', '41.805699', '123.431472', 'pic37.jpg');
INSERT INTO `tb_hotel` VALUES (38, '银杏树酒店', '合肥市庐阳区长江中路789号', 360, 8, '丽枫', '合肥', '四星级', '庐阳区', '31.820591', '117.227219', 'pic38.jpg');
INSERT INTO `tb_hotel` VALUES (39, '星空酒店', '福州市鼓楼区东街口101号', 340, 7, '希尔顿', '福州', '三星级', '鼓楼区', '26.075302', '119.306239', 'pic39.jpg');
INSERT INTO `tb_hotel` VALUES (40, '海天大酒店', '哈尔滨市南岗区学府路202号', 380, 9, '喜来登', '哈尔滨', '五星级', '南岗区', '45.803775', '126.534967', 'pic40.jpg');
INSERT INTO `tb_hotel` VALUES (41, '彩虹酒店', '杭州市西湖区湖滨路123号', 360, 8, '香格里拉', '杭州', '四星级', '西湖区', '30.274085', '120.155070', 'pic41.jpg');
INSERT INTO `tb_hotel` VALUES (42, '天鹅湖酒店', '贵阳市南明区花溪大道456号', 350, 7, '万豪', '贵阳', '三星级', '南明区', '26.647003', '106.630242', 'pic42.jpg');
INSERT INTO `tb_hotel` VALUES (43, '凤凰酒店', '成都市青羊区顺城大街789号', 370, 9, '锦江之星', '成都', '五星级', '青羊区', '30.572815', '104.066803', 'pic43.jpg');
INSERT INTO `tb_hotel` VALUES (44, '兰花酒店', '南宁市兴宁区朝阳路101号', 330, 8, '维也纳', '南宁', '四星级', '兴宁区', '22.817002', '108.366543', 'pic44.jpg');
INSERT INTO `tb_hotel` VALUES (45, '牡丹江酒店', '昆明市五华区滇池路202号', 340, 7, '华住', '昆明', '三星级', '五华区', '25.040609', '102.712251', 'pic45.jpg');
INSERT INTO `tb_hotel` VALUES (46, '玉龙雪山酒店', '苏州市吴中区东环路123号', 310, 9, '开元', '苏州', '五星级', '吴中区', '31.298886', '120.585316', 'pic46.jpg');
INSERT INTO `tb_hotel` VALUES (47, '海韵酒店', '南昌市青山湖区北京东路456号', 390, 8, '如家', '南昌', '四星级', '青山湖区', '28.682892', '115.858197', 'pic47.jpg');
INSERT INTO `tb_hotel` VALUES (48, '金鹰酒店', '厦门市湖里区仙岳路789号', 360, 7, '布丁', '厦门', '三星级', '湖里区', '24.479834', '118.089425', 'pic48.jpg');
INSERT INTO `tb_hotel` VALUES (49, '天海酒店', '广州市越秀区环市东路101号', 350, 9, '全季', '广州', '五星级', '越秀区', '23.129163', '113.264435', 'pic49.jpg');
INSERT INTO `tb_hotel` VALUES (50, '丽晶酒店', '西安市碑林区南大街202号', 400, 8, '亚朵', '西安', '四星级', '碑林区', '34.341574', '108.939770', 'pic50.jpg');
INSERT INTO `tb_hotel` VALUES (51, '海角酒店', '乌鲁木齐市沙依巴克区友好北路123号', 330, 7, '格林豪泰', '乌鲁木齐', '三星级', '沙依巴克区', '43.825592', '87.616848', 'pic51.jpg');
INSERT INTO `tb_hotel` VALUES (52, '紫金山酒店', '济南市市中区经十路456号', 370, 9, '丽枫', '济南', '五星级', '市中区', '36.651216', '117.120095', 'pic52.jpg');
INSERT INTO `tb_hotel` VALUES (53, '星辰酒店', '昆明市官渡区春城路789号', 310, 8, '希尔顿', '昆明', '四星级', '官渡区', '25.040609', '102.712251', 'pic53.jpg');
INSERT INTO `tb_hotel` VALUES (54, '天际线酒店', '长沙市天心区劳动西路101号', 340, 7, '喜来登', '长沙', '三星级', '天心区', '28.228209', '112.938814', 'pic54.jpg');
INSERT INTO `tb_hotel` VALUES (55, '星海湾酒店', '贵阳市花溪区贵黄路202号', 390, 9, '香格里拉', '贵阳', '五星级', '花溪区', '26.647003', '106.630242', 'pic55.jpg');
INSERT INTO `tb_hotel` VALUES (56, '都市阳光酒店', '福州市台江区五一路456号', 360, 8, '万豪', '福州', '四星级', '台江区', '26.075302', '119.306239', 'pic56.jpg');
INSERT INTO `tb_hotel` VALUES (57, '蓝海酒店', '银川市金凤区正源南街123号', 350, 7, '锦江之星', '银川', '三星级', '金凤区', '38.487194', '106.230909', 'pic57.jpg');
INSERT INTO `tb_hotel` VALUES (58, '西部酒店', '成都市武侯区科华南路789号', 320, 9, '维也纳', '成都', '五星级', '武侯区', '30.572815', '104.066803', 'pic58.jpg');
INSERT INTO `tb_hotel` VALUES (59, '绿洲宾馆', '呼和浩特市赛罕区新华东街101号', 390, 8, '华住', '呼和浩特', '四星级', '赛罕区', '40.841490', '111.751990', 'pic59.jpg');
INSERT INTO `tb_hotel` VALUES (60, '江南酒店', '兰州市七里河区西站东路202号', 340, 7, '开元', '兰州', '三星级', '七里河区', '36.061089', '103.834304', 'pic60.jpg');
INSERT INTO `tb_hotel` VALUES (61, '云海酒店', '南宁市西乡塘区明秀东路123号', 310, 9, '如家', '南宁', '五星级', '西乡塘区', '22.817002', '108.366543', 'pic61.jpg');
INSERT INTO `tb_hotel` VALUES (62, '君悦酒店', '厦门市集美区银江路456号', 370, 8, '布丁', '厦门', '四星级', '集美区', '24.479834', '118.089425', 'pic62.jpg');
INSERT INTO `tb_hotel` VALUES (63, '湖滨酒店', '西安市雁塔区小寨东路789号', 400, 7, '全季', '西安', '三星级', '雁塔区', '34.341574', '108.939770', 'pic63.jpg');
INSERT INTO `tb_hotel` VALUES (64, '紫荆花酒店', '贵阳市南明区解放路101号', 330, 9, '亚朵', '贵阳', '五星级', '南明区', '26.647003', '106.630242', 'pic64.jpg');
INSERT INTO `tb_hotel` VALUES (65, '银杏树酒店', '福州市晋安区鼓山大道202号', 380, 8, '格林豪泰', '福州', '四星级', '晋安区', '26.075302', '119.306239', 'pic65.jpg');
INSERT INTO `tb_hotel` VALUES (66, '星空酒店', '成都市高新区天府大道123号', 350, 7, '丽枫', '成都', '三星级', '高新区', '30.572815', '104.066803', 'pic66.jpg');
INSERT INTO `tb_hotel` VALUES (67, '海天大酒店', '杭州市拱墅区湖墅南路456号', 360, 9, '希尔顿', '杭州', '五星级', '拱墅区', '30.274085', '120.155070', 'pic67.jpg');
INSERT INTO `tb_hotel` VALUES (68, '彩虹酒店', '昆明市西山区滇池路789号', 310, 8, '喜来登', '昆明', '四星级', '西山区', '25.040609', '102.712251', 'pic68.jpg');
INSERT INTO `tb_hotel` VALUES (69, '天鹅湖酒店', '兰州市安宁区桃林路101号', 340, 7, '香格里拉', '兰州', '三星级', '安宁区', '36.061089', '103.834304', 'pic69.jpg');
INSERT INTO `tb_hotel` VALUES (70, '凤凰酒店', '呼和浩特市玉泉区大南街202号', 390, 9, '万豪', '呼和浩特', '五星级', '玉泉区', '40.841490', '111.751990', 'pic70.jpg');
INSERT INTO `tb_hotel` VALUES (71, '兰花酒店', '重庆市渝北区金开大道123号', 370, 8, '锦江之星', '重庆', '四星级', '渝北区', '29.563761', '106.550464', 'pic71.jpg');
INSERT INTO `tb_hotel` VALUES (72, '牡丹江酒店', '郑州市二七区大学路456号', 400, 7, '维也纳', '郑州', '三星级', '二七区', '34.746303', '113.625350', 'pic72.jpg');
INSERT INTO `tb_hotel` VALUES (73, '玉龙雪山酒店', '济南市槐荫区经十西路789号', 360, 9, '华住', '济南', '五星级', '槐荫区', '36.651216', '117.120095', 'pic73.jpg');
INSERT INTO `tb_hotel` VALUES (74, '海韵酒店', '南宁市江南区白沙大道101号', 350, 8, '开元', '南宁', '四星级', '江南区', '22.817002', '108.366543', 'pic74.jpg');
INSERT INTO `tb_hotel` VALUES (75, '金鹰酒店', '海口市美兰区海甸岛人民大道202号', 370, 7, '如家', '海口', '三星级', '美兰区', '20.044002', '110.198293', 'pic75.jpg');
INSERT INTO `tb_hotel` VALUES (76, '天海酒店', '长沙市雨花区万家丽中路123号', 330, 9, '布丁', '长沙', '五星级', '雨花区', '28.228209', '112.938814', 'pic76.jpg');
INSERT INTO `tb_hotel` VALUES (77, '丽晶酒店', '南京市秦淮区中华路456号', 380, 8, '全季', '南京', '四星级', '秦淮区', '32.060255', '118.796877', 'pic77.jpg');
INSERT INTO `tb_hotel` VALUES (78, '海角酒店', '杭州市滨江区江南大道789号', 340, 7, '亚朵', '杭州', '三星级', '滨江区', '30.274085', '120.155070', 'pic78.jpg');
INSERT INTO `tb_hotel` VALUES (79, '紫金山酒店', '福州市仓山区金山大道101号', 390, 9, '格林豪泰', '福州', '五星级', '仓山区', '26.075302', '119.306239', 'pic79.jpg');
INSERT INTO `tb_hotel` VALUES (80, '星辰酒店', '成都市金牛区人民北路456号', 360, 8, '丽枫', '成都', '四星级', '金牛区', '30.572815', '104.066803', 'pic80.jpg');
INSERT INTO `tb_hotel` VALUES (81, '天际线酒店', '南宁市青秀区长湖路123号', 340, 7, '希尔顿', '南宁', '三星级', '青秀区', '22.817002', '108.366543', 'pic81.jpg');
INSERT INTO `tb_hotel` VALUES (82, '星海湾酒店', '昆明市盘龙区金色大道202号', 330, 9, '喜来登', '昆明', '五星级', '盘龙区', '25.040609', '102.712251', 'pic82.jpg');
INSERT INTO `tb_hotel` VALUES (83, '都市阳光酒店', '呼和浩特市赛罕区腾飞路456号', 370, 8, '香格里拉', '呼和浩特', '四星级', '赛罕区', '40.841490', '111.751990', 'pic83.jpg');
INSERT INTO `tb_hotel` VALUES (84, '蓝海酒店', '兰州市红古区海淀路789号', 400, 7, '万豪', '兰州', '三星级', '红古区', '36.061089', '103.834304', 'pic84.jpg');
INSERT INTO `tb_hotel` VALUES (85, '西部酒店', '重庆市巴南区龙洲湾101号', 360, 9, '锦江之星', '重庆', '五星级', '巴南区', '29.563761', '106.550464', 'pic85.jpg');
INSERT INTO `tb_hotel` VALUES (86, '绿洲宾馆', '银川市金凤区正源南街456号', 340, 8, '维也纳', '银川', '四星级', '金凤区', '38.487194', '106.230909', 'pic86.jpg');
INSERT INTO `tb_hotel` VALUES (87, '江南酒店', '南宁市西乡塘区大学东路789号', 330, 7, '华住', '南宁', '三星级', '西乡塘区', '22.817002', '108.366543', 'pic87.jpg');
INSERT INTO `tb_hotel` VALUES (88, '云海酒店', '厦门市思明区莲花南路101号', 370, 9, '开元', '厦门', '五星级', '思明区', '24.479834', '118.089425', 'pic88.jpg');
INSERT INTO `tb_hotel` VALUES (89, '君悦酒店', '贵阳市云岩区北京东路456号', 360, 8, '如家', '贵阳', '四星级', '云岩区', '26.647003', '106.630242', 'pic89.jpg');
INSERT INTO `tb_hotel` VALUES (90, '湖滨酒店', '昆明市五华区人民中路789号', 310, 7, '布丁', '昆明', '三星级', '五华区', '25.040609', '102.712251', 'pic90.jpg');
INSERT INTO `tb_hotel` VALUES (91, '紫荆花酒店', '杭州市江干区秋涛北路123号', 390, 9, '全季', '杭州', '五星级', '江干区', '30.274085', '120.155070', 'pic91.jpg');
INSERT INTO `tb_hotel` VALUES (92, '银杏树酒店', '成都市双流区华阳大道456号', 350, 8, '亚朵', '成都', '四星级', '双流区', '30.572815', '104.066803', 'pic92.jpg');
INSERT INTO `tb_hotel` VALUES (93, '星空酒店', '福州市马尾区儒江西路789号', 400, 7, '格林豪泰', '福州', '三星级', '马尾区', '26.075302', '119.306239', 'pic93.jpg');
INSERT INTO `tb_hotel` VALUES (94, '海天大酒店', '南宁市青秀区厢竹大道101号', 360, 9, '丽枫', '南宁', '五星级', '青秀区', '22.817002', '108.366543', 'pic94.jpg');
INSERT INTO `tb_hotel` VALUES (95, '彩虹酒店', '杭州市余杭区良渚路456号', 310, 8, '希尔顿', '杭州', '四星级', '余杭区', '30.274085', '120.155070', 'pic95.jpg');
INSERT INTO `tb_hotel` VALUES (96, '天鹅湖酒店', '昆明市盘龙区白塔路789号', 340, 7, '喜来登', '昆明', '三星级', '盘龙区', '25.040609', '102.712251', 'pic96.jpg');
INSERT INTO `tb_hotel` VALUES (97, '凤凰酒店', '呼和浩特市赛罕区新城大道123号', 390, 9, '香格里拉', '呼和浩特', '五星级', '赛罕区', '40.841490', '111.751990', 'pic97.jpg');
INSERT INTO `tb_hotel` VALUES (98, '兰花酒店', '南宁市良庆区玉洞大道202号', 370, 8, '万豪', '南宁', '四星级', '良庆区', '22.817002', '108.366543', 'pic98.jpg');
INSERT INTO `tb_hotel` VALUES (99, '牡丹江酒店', '厦门市湖里区金山西路789号', 400, 7, '锦江之星', '厦门', '三星级', '湖里区', '24.479834', '118.089425', 'pic99.jpg');
INSERT INTO `tb_hotel` VALUES (100, '玉龙雪山酒店', '福州市鼓楼区五一路101号', 360, 9, '维也纳', '福州', '五星级', '鼓楼区', '26.075302', '119.306239', 'pic100.jpg');
项目准备好后,根据表结构,建立es的索引库
小提示:ES中支持两种地理坐标数据类型
- geo_point:有纬度(latitude)和经度(longitude)确定的一个点。例如 “24.479834,119.306239”
- geo_shape:有多个geo_point组成的复杂几何图形。例如一条直线,“LINESTRING(24.479834 119.306239,-119.306239 24.479834)”
问题:假如需求是根据多个字段进行搜索,而不是单个字段进行搜索,那么该如何实现
在es中,每个字段都提供了一个属性值,copy_to ,这个可以将其他字段的值拷贝到指定的字段,就可实现在一个字段中搜索到其他字段的值
这种方法做了优化,并不是真的把其他字段的值拷贝进去,只是基于它创建动态索引,查的时候看不到这个字段,但是可以根据这个公共字段搜索
示例:
# 提供一个公共字段,整合其他字段
"all": {
"type": "text",
"analyzer": "ik_max_word"
},
# 将需要拷贝到公共字段的字段添加上copy_to属性
"name": {
"type": "text",
"analyzer": "ik_max_word",
"copy_to": "all"
}
完整的创建索引库
PUT hotel
{
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"name": {
"type": "text",
"analyzer": "ik_max_word",
"copy_to": "all"
},
"address": {
"type": "keyword",
"index": false
},
"price": {
"type": "integer"
},
"score": {
"type": "integer"
},
"brand": {
"type": "keyword",
"copy_to": "all"
},
"city": {
"type": "keyword"
},
"starName": {
"type": "keyword"
},
"business": {
"type": "keyword",
"copy_to": "all"
},
"location": {
"type": "geo_point"
},
"pic": {
"type": "keyword",
"index": false
},
"all": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
1、初始化示例工程
(1)引入依赖,版本需要与现在使用的es版本一致
<!-- https://mvnrepository.com/artifact/org.elasticsearch.client/elasticsearch-rest-high-level-client -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.17.21</version>
</dependency>
注意:此时的大部分依赖已经为 7.17.21,但是由于所有的依赖都是由springboot所进行管理的,还需要额外的在父工程规定依赖版本,在properties标签下添加,自此,所有关于es的依赖都以我们自己规定版本的为主
<properties>
<elasticsearch.version>7.17.21</elasticsearch.version>
</properties>
(2)编写测试类
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import java.io.IOException;
/**
* @author Patrick Star
* @date 2024/6/14 0:51
*/
public class EsHotelIndexTest {
private RestHighLevelClient client;
/**
* 在测试前运行
*/
@BeforeEach
void setUp() {
this.client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://175.178.189.171:9200")
));
}
/**
* 测试完后自动销毁
*/
@AfterEach
void tearDown() throws IOException {
this.client.close();
}
}
2、RestHighLevelClient操作(已过时的API)
索引库
(1)新增索引库
可将dslStr封装为静态常量
/**
* 创建索引库
*/
@Test
void testCreateIndex() throws IOException {
//dsl创建索引库语句
String dslStr = "{\n" +
" \"mappings\": {\n" +
" \"properties\": {\n" +
" \"id\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"name\": {\n" +
" \"type\": \"text\", \n" +
" \"analyzer\": \"ik_max_word\",\n" +
" \"copy_to\": \"all\"\n" +
" },\n" +
" \"address\": {\n" +
" \"type\": \"keyword\", \n" +
" \"index\": false\n" +
" },\n" +
" \"price\": {\n" +
" \"type\": \"integer\"\n" +
" },\n" +
" \"score\": {\n" +
" \"type\": \"integer\"\n" +
" },\n" +
" \"brand\": {\n" +
" \"type\": \"keyword\",\n" +
" \"copy_to\": \"all\"\n" +
" },\n" +
" \"city\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"starName\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"business\": {\n" +
" \"type\": \"keyword\",\n" +
" \"copy_to\": \"all\"\n" +
" },\n" +
" \"location\": {\n" +
" \"type\": \"geo_point\"\n" +
" },\n" +
" \"pic\": {\n" +
" \"type\": \"keyword\", \n" +
" \"index\": false\n" +
" },\n" +
" \"all\": {\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_max_word\"\n" +
" }\n" +
" }\n" +
" }\n" +
"}";
//1、创建request对象
CreateIndexRequest request = new CreateIndexRequest("hotel");
//2、准备DSL语句
request.source(dslStr, XContentType.JSON);
//3、发起请求
this.client.indices().create(request, RequestOptions.DEFAULT);
}
(2)判断是否存在和删除索引库
判断索引库是否存在
/**
* 判断索引库是否存在
* @throws IOException
*/
@Test
void testExistIndex() throws IOException {
GetIndexRequest request = new GetIndexRequest("hotel");
boolean exists = this.client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println("索引库是否存在 ---------- > " + exists);
}
删除索引库
/**
* 删除索引库
* @throws IOException
*/
@Test
void testDeleteIndex() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("hotel");
this.client.indices().delete(request, RequestOptions.DEFAULT);
}
文档
(1)新增文档
新增一个实体类,方便将hotel对象转为存在索引库的对象
@Data
@NoArgsConstructor
public class HotelDoc {
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String location;
private String pic;
public HotelDoc(Hotel hotel) {
this.id = hotel.getId();
this.name = hotel.getName();
this.address = hotel.getAddress();
this.price = hotel.getPrice();
this.score = hotel.getScore();
this.brand = hotel.getBrand();
this.city = hotel.getCity();
this.starName = hotel.getStarName();
this.business = hotel.getBusiness();
this.location = hotel.getLatitude() + "," + hotel.getLongitude();
this.pic = hotel.getPic();
}
}
测试类
/**
* 新增文档
* @throws IOException
*/
@Test
void testAddDoc() throws IOException {
//1、查询数据库,获取数据对象
Hotel hotel = iHotelService.getById(1L);
//2、将hotel对象转为文档对象
HotelDoc hotelDoc = new HotelDoc(hotel);
//3、准备request对象
IndexRequest request = new IndexRequest("hotel").id(hotelDoc.getId().toString());
//4、准备json文档数据
request.source(JSON.toJSONString(hotelDoc), XContentType.JSON);
//5、发起请求
this.client.index(request, RequestOptions.DEFAULT);
}
(2)查询文档
/**
* 查询文档
* @throws IOException
*/
@Test
void testGetDoc() throws IOException {
//1、创建GetRequest对象,传入索引库名,文档id
GetRequest request = new GetRequest("hotel", "1");
//2、发起请求
GetResponse response = client.get(request, RequestOptions.DEFAULT);
String json = response.getSourceAsString();
System.out.println("查询到的对象 ---------- > " + json);
}
(3)局部更新文档
注意这里的准备参数,参数与之用逗号隔开,一个属性一个值,每一对属性和值也用逗号隔开
/**
* 根据文档id更新文档
* @throws IOException
*/
@Test
void testUpdateDoc() throws IOException {
//1、创建UpdateRequest对象,传入索引库名,文档id
UpdateRequest request = new UpdateRequest("hotel", "1");
//2、准备参数
request.doc(
"name","鲁光大道大酒店",
"price","777"
);
//3、发起请求
client.update(request, RequestOptions.DEFAULT);
}
(4)删除文档
/**
* 根据文档id删除文档
* @throws IOException
*/
@Test
void testDeleteDoc() throws IOException {
DeleteRequest request = new DeleteRequest("hotel", "1");
client.delete(request, RequestOptions.DEFAULT);
}
(5)批量新增
/**
* 批量提交
* @throws IOException
*/
@Test
void testBulkDoc() throws IOException {
//获取所有的酒店数据
List<Hotel> list = iHotelService.list();
BulkRequest request = new BulkRequest();
//for循环处理数据
for (Hotel hotel : list) {
HotelDoc hotelDoc = new HotelDoc(hotel);
//构建IndexRequest对象
IndexRequest indexRequest = new IndexRequest("hotel").id(hotelDoc.getId().toString());
indexRequest.source(JSON.toJSONString(hotelDoc), XContentType.JSON);
request.add(indexRequest);
}
client.bulk(request, RequestOptions.DEFAULT);
}
3、RestClient基本查询 (已过时API)
(1)查询所有
/**
* 查询所有
* @throws IOException
*/
@Test
void testMatchAll() throws IOException {
//1、准备request
SearchRequest request = new SearchRequest("hotel");
//2、准备查询条件
request.source().query(QueryBuilders.matchAllQuery());
//3、发起请求,获取响应结果
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4、处理响应结果
SearchHits hits = response.getHits();
for (SearchHit hit : hits) {
HotelDoc hotelDoc = JSON.parseObject(hit.getSourceAsString(), HotelDoc.class);
System.out.println("结果 --------- > " + hotelDoc);
}
}
(2)字段查询
/**
* 字段查询
* @throws IOException
*/
@Test
void testMatch() throws IOException {
//1、准备request
SearchRequest request = new SearchRequest("hotel");
//2-1、单字段查询(字段名,查询的值)
//request.source().query(QueryBuilders.matchQuery("all", "阳光"));
//2-2、多字段查询
request.source().query(QueryBuilders.multiMatchQuery("阳光南宁", "name", "city"));
//3、发起请求,获取响应结果
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4、处理响应结果
SearchHits hits = response.getHits();
long value = hits.getTotalHits().value;
System.out.println("一共搜索数据 --------- > "+value+" 条数据");
for (SearchHit hit : hits) {
HotelDoc hotelDoc = JSON.parseObject(hit.getSourceAsString(), HotelDoc.class);
System.out.println("结果 --------- > " + hotelDoc);
}
}
(3)其他查询api使用方式都差不多
(4)排序和分页
/**
* 查询所有
* @throws IOException
*/
@Test
void testMatchAll() throws IOException {
//1、准备request
SearchRequest request = new SearchRequest("hotel");
//2、准备查询条件
request.source().query(QueryBuilders.matchAllQuery());
//排序
request.source().sort("price",SortOrder.ASC);
//分页
request.source().from(0).size(10);
//3、发起请求,获取响应结果
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4、处理响应结果
SearchHits hits = response.getHits();
long value = hits.getTotalHits().value;
System.out.println("一共搜索数据 --------- > "+value+" 条数据");
for (SearchHit hit : hits) {
HotelDoc hotelDoc = JSON.parseObject(hit.getSourceAsString(), HotelDoc.class);
System.out.println("结果 --------- > " + hotelDoc);
}
}
(5)文本高亮
/**
* 文本高亮
* @throws IOException
*/
@Test
void testMatchAll() throws IOException {
//1、准备request
SearchRequest request = new SearchRequest("hotel");
//2、准备查询条件
request.source().query(QueryBuilders.matchQuery("all", "阳光"));
request.source().highlighter(new HighlightBuilder()
.field("name").requireFieldMatch(false)
.field("city").requireFieldMatch(false));
//3、发起请求,获取响应结果
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4、处理响应结果
SearchHits hits = response.getHits();
long value = hits.getTotalHits().value;
System.out.println("一共搜索数据 --------- > "+value+" 条数据");
for (SearchHit hit : hits) {
HotelDoc hotelDoc = JSON.parseObject(hit.getSourceAsString(), HotelDoc.class);
System.out.println("结果 --------- > " + hotelDoc);
//解析高亮结果
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
HighlightField field = highlightFields.get("name");
String resp = field.getFragments()[0].toString();
System.out.println("高亮 ----------- > " + resp);
}
}
五、DSL基本语法
官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.17/query-filter-context.html
DSL Query的分类
常见的查询类型包括:
- 查询所有:查询出所有数据,一般测试用,例如 match_all ,这里的match_all一般只会查询出10条数据,避免一次性查询所有数据导致服务器内存消耗过大
- 全文检索(full text)查询:利用分词器对用户输入内容分词,然后去倒排索引库中匹配。例如:
- match_all
- multi_match_query
- 精确查询:根据精确词条值查询数据,一般是查询keyword、数值、日期、boolean等类型字段,例如:
- ids 根据id查询
- range 数值范围查询
- term
- 地理(geo)查询:根据经纬度查询,例如
- geo_distance
- geo_bounding_box
- 复合(compound)查询:复合查询可以将上述各种查询条件组合起来,合并查询条件,例如
- bool
- function_score
查询的基本语法:
GET /索引库名/_search
{
"query": {
"查询类型":{
"查询条件":"条件值"
}
}
}
1、查询所有
GET /hotel/_search
{
"query": {
"match_all": {} # 查询所有
}
}
2、全文检索
match查询
全文检索查询的一种,会对用户输入内容分词,然后去倒排索引检索,语法:
GET /indexName/_search
{
"query": {
"match": {
"FIELD":"TEXT"
}
}
}
示例:
GET /hotel/_search
{
"query": {
"match": {
"all": "如家西乡塘"
}
}
}
multi_match查询
与match查询类似,不过允许多字段查询,语法:
GET /indexName/_search
{
"query": {
"multi_match": {
"query": "text",
"fields": ["FIELD1","FIELD2"]
}
}
}
示例:
GET /hotel/_search
{
"query": {
"multi_match": {
"query": "云海",
"fields": ["brand", "business", "name"]
}
}
}
3、精确查询
根据精确词条值查询数据,一般是查询keyword、数值、日期、boolean等类型字段,一般是不会对词条进行分词查询
- term:根据词条精确查询
- range:根据值范围查询
term查询
语法:
GET /indexName/_search
{
"query": {
"term": {
"FIELD": {
"value": "VALUE"
}
}
}
}
示例:
GET /hotel/_search
{
"query": {
"term": {
"city": {
"value": "南宁"
}
}
}
}
range查询
语法:
GET /indexName/_search
{
"query": {
"range": {
"FIELD": {
"gte": 10,
"lte": 20
}
}
}
}
示例:
GET /hotel/_search
{
"query": {
"range": {
"price": {
"gte": 500, # gt 大于 gte 大于等于
"lte": 600 # lt 小于 lte 小于等于
}
}
}
}
4、地理查询
geo_bounding_box查询
查询geo_point值落在某个矩形范围内的所有文档,这个FIELD字段必须是geo_point类型
语法:
GET /indexName/_search
{
"query": {
"geo_bounding_box": {
"FIELD": {
"top_left": {
"lat": 40.73,
"lon": -74.1
},
"bottom_right": {
"lat": 40.01,
"lon": -71.12
}
}
}
}
}
geo_distance查询
查询到指定中心点小于某个距离值的所有文档
语法:
GET /indexName/_search
{
"query": {
"geo_distance": {
"distance":"5km", # 距离
"FIELD":"22.817002,108.366543" # 地理坐标字段
}
}
}
示例:
GET /hotel/_search
{
"query": {
"geo_distance": {
"distance":"5km",
"location":"22.817002,108.366543"
}
}
}
5、复合查询
复合(compound)查询:复合查询可以将上述各种查询条件组合起来,合并查询条件,例如
boolean_query查询
布尔查询时一个或多个查询子句的组合。子查询的组合方式有:
- must:必须匹配每个子查询,类似 “与”
- should:选择性匹配子查询,类似 “或”
- must_not:必须不匹配,不参与算分,类似 “非”
- filter:必须匹配,不参与算分
语法:
GET /hotel/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "阳光"
}
}
],
"must_not": [
{
"range": {
"price": {
"gt": 500
}
}
}
],
"filter": [
{
"geo_distance": {
"distance": "100km",
"location": {
"lat": 26.07,
"lon": 119.30
}
}
}
]
}
}
}
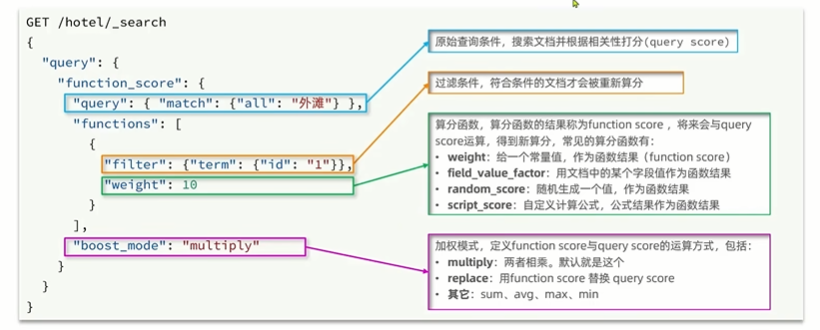
function_score查询
算分函数查询,可以控制文档相关性算分,控制文档排名。例如百度搜索
相关性算分:当我们利用match查询时,文档结果会根据与搜索词条的关联度打分(_score),返回结果时按照分值降序排列
规则:

es版本后的es默认采用的是BM25算法
TF-IDF算法中,词频越高,将来的得分就会无限的增加,会越来越高,BM25算法在词频的得分会趋于水平
语法:
GET /hotel/_search
{
"query": {
"function_score": {
"query": {
"match": {
"city": "南宁"
}
},
"functions": [
{
"filter": {
"term": {
"id": "1"
}
},
"weight": 10
}
],
"boost_mode": "multiply"
}
}
}
6、搜索结果处理
排序
es支持对搜索结果排序,默认是根据相关度算分(_score)来排序。可以排序字段类型有:keyword类型、数值类型、地理坐标类型、日期类型
语法:
GET /hotel/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"FIELD": {
"order": "desc" //排序字段和排序方式 ASC、DESC
}
}
]
}
地理坐标排序
GET /hotel/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"_geo_distance": {
"FIELD": { //地理坐标字段
"lat": 40,
"lon": -70
},
"order": "asc", //排序方式
"unit": "km" //排序单位
}
}
]
}
分页
es默认情况下只返回top10的数据,而如果要查询更多数据就需要修改分页参数
es通过修改from,size参数来控制要返回的分页结果
语法
GET /hotel/_search
{
"query": {
"match_all": {}
},
"from": 0, //分页开始的位置,默认是0
"size": 30, //期望获取的文档总数
"sort": [
{
"price": {
"order": "desc"
}
}
]
}
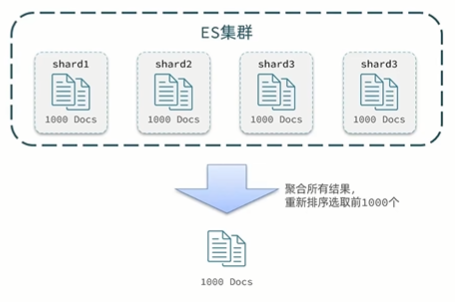
深度分页问题
es是分布式的,所以会面临深度分页的问题。例如按price排序后,获取from=990,size=10的数据:
1、首先在每个数据分片上都有排序并查询前1000条文档
2、然后将所有节点的结果聚合,在内存中重新排序选出前1000条文档
3、最后从这1000条中,选取从990开始的10条文档
如果搜索页数过深,或者结果集(from+size)越大,对内存和CPU的消耗也越高。因此es设定结果集查询的上限是10000条
深度分页解决方案
- search after:分页是需要排序,原理是从上一次的排序值开始,查询下一页数据,缺点是只能向后翻页,不可向前翻页,因为这种方式记录了这一次分页的最后一个文档的值,查询下一页的时候,是根据这个记录的值去获取下一页的文档,官方推荐使用的方式
- scroll:原理将排序数据形成快照,保存在内存中,缺点是数据量大的时候,需要的内存也越大,官方不推荐。
高亮
在搜索结果中把搜索关键字高亮
- 将搜索结果中的关键字用标签标记出来
- 在页面中给标签添加css样式
语法:
注意:
- 在默认情况下,es的搜索字段必须与高亮字段一致,否则不会高亮
- 在搜索条件中必须要带关键字查询,不可使用match_all,否则不会显示高亮
GET /hotel/_search
{
"query": {
"match": { //必须指定搜索字段,并且不能使用match_all
"all": "阳光酒店"
}
},
"highlight": {
"fields": { //指定要高亮的字段
"name": {
"pre_tags": "<em>", //用来标记高亮字段的前置标签
"post_tags": "</em>",//用来标记高亮字段的后置标签
"require_field_match": "false" //不需要字段匹配,作用是为了取消搜索字段与高亮字段不匹配,从而不高亮的问题
},
"city": {
"pre_tags": "<em>",
"post_tags": "</em>",
"require_field_match": "false"
}
}
}
}
六、数据聚合
1、聚合分类
聚合(aggregations)可以实现对文档数据的统计、分析、运算。聚合常见的有三大类:
- 桶(Bucket)聚合:用来对文档做分组
- termAggregation:按照文档字段值分组
- Date Histogram:按照日期阶梯分组,例如一周为一组,一个月为一组
- 度量(Metric)聚合:用以计算一些值,比如:最大值、最小值、平均值等
- Avg:求平均值
- Max:求最大值
- Min:求最小值
- Stats:同时求max、min、avg、sum等
- 管道(pipeline)聚合:其他聚合结果为基础做聚合
2、使用DSL实现聚合
(1)桶(Bucket)聚合
语法
GET /hotel/_search
{
"size": 0, //设置size为0,结果不包含文档,只包含聚合结果
"aggs": { //定义聚合
"brandAgg": { //自定义聚合名称
"terms": { //聚合类型,按照什么进行聚合就写什么,这里是按照词条进行聚合
"field": "brand", //聚合的字段
"size": 30 //期望获取的聚合结果数量
}
}
}
}
示例:
根据品牌进行聚合
GET /hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 10
}
}
}
}
默认情况下,Bucket聚合会统计Bucket内的文档数量,记为_count,并且按照 _count 降序排序。这个可自行修改规则,方式如下
GET /hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 100,
"order": { //添加自定义排序规则
"_count": "asc"
}
}
}
}
}
默认情况下,Bucket聚合是对索引库的所有文档做聚合,我们可以限定要聚合的文档范围,只要添加query条件即可:
GET /hotel/_search
{
"query": { //添加聚合条件,不对索引库中的所有文档进行聚合
"range": {
"price": {
"lte": 400
}
}
},
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 100,
"order": {
"_count": "asc"
}
}
}
}
}
(2)度量(Metric)聚合
语法:
GET /hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 100,
"order": {
"_count": "asc"
}
},
"aggs": { //在桶聚合中添加新的聚合
"scoreAggs": { //聚合名,自定义
"stats": { //聚合类型
"field": "score" //聚合的字段
}
}
}
}
}
}
可自定义排序规则
GET /hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 100,
"order": {
"scoreAggs.avg": "asc" //添加自定义的排序规则
}
},
"aggs": {
"scoreAggs": {
"stats": {
"field": "score"
}
}
}
}
}
}
3、使用RestApi实现聚合
(1)桶聚合
语法:
/**
* 查询所有
* @throws IOException
*/
@Test
void testAggregation() throws IOException {
//1、准备request
SearchRequest request = new SearchRequest("hotel");
//2、准备聚合条件
request.source().size(0);
request.source().aggregation(
AggregationBuilders
.terms("brand_agg")
.field("brand")
.size(20)
);
//3、发起请求,获取响应结果
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4、解析结果
Aggregations aggregations = response.getAggregations();
//根据名称获取聚合结果
Terms brandAgg = aggregations.get("brand_agg");
//获取桶
List<? extends Terms.Bucket> buckets = brandAgg.getBuckets();
//遍历桶
for (Terms.Bucket bucket : buckets) {
String keyAsString = bucket.getKeyAsString();
long docCount = bucket.getDocCount();
System.out.println("品牌名称 --- > " + keyAsString + " 品牌数量 --- > " + docCount);
}
}
(2)多条件聚合
例子:
1.在接口中声明一个filters接口
public interface IHotelService extends IService<Hotel> {
Map<String, List<String>> filters();
}
2.实现类
@Service
public class HotelServiceImpl extends ServiceImpl<HotelMapper, Hotel> implements IHotelService {
@Autowired
private RestHighLevelClient client;
@Override
public Map<String, List<String>> filters() {
try {
//1、准备request
SearchRequest request = new SearchRequest("hotel");
//2、准备聚合条件
request.source().size(0);
//创造聚合条件
aggregationBuild(request);
//3、发起请求,获取响应结果
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
Map<String, List<String>> map = new HashMap<>();
//4、解析结果
Aggregations aggregations = response.getAggregations();
List<String> brandAgg = getAggreResp(aggregations, "brand_agg");
map.put("品牌", brandAgg);
List<String> cityAgg = getAggreResp(aggregations, "city_agg");
map.put("城市", cityAgg);
List<String> starAgg = getAggreResp(aggregations, "star_agg");
map.put("星级", starAgg);
return map;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private List<String> getAggreResp(Aggregations aggregations, String aggName) {
//根据名称获取聚合结果
Terms brandAgg = aggregations.get(aggName);
//获取桶
List<? extends Terms.Bucket> buckets = brandAgg.getBuckets();
List<String> keys = new ArrayList<>();
//遍历桶
for (Terms.Bucket bucket : buckets) {
String key = bucket.getKeyAsString();
keys.add(key);
}
return keys;
}
private void aggregationBuild(SearchRequest request) {
request.source().aggregation(
AggregationBuilders
.terms("brand_agg")
.field("brand")
.size(100)
);
request.source().aggregation(
AggregationBuilders
.terms("city_agg")
.field("city")
.size(100)
);
request.source().aggregation(
AggregationBuilders
.terms("star_agg")
.field("starName")
.size(100)
);
}
}
3.单元测试
@SpringBootTest
class EsHotelServiceApplicationTests {
@Autowired
private IHotelService iHotelService;
@Test
void contextLoads() {
Map<String, List<String>> filters = iHotelService.filters();
System.out.println("结果 ---------- > " + filters);
}
}
七、自动补全
1、安装拼音分词器
下载地址:https://github.com/infinilabs/analysis-pinyin
下载对应版本后,上传到docker容器所挂载的es的插件数据卷下,重启容器,等待容器重启完成即可
docker restart es
测试:
分词器使用的是 pinyin
POST _analyze
{
"text": ["如家酒店还不错"],
"analyzer": "pinyin"
}
2、自定义分词器
es中分词器(analyzer)的组成包含三部分:
- character filters:在tokenizer之前对文本进行处理,例如删除字符,替换字符
- tokenizer:将文本按照一定的规则切割成词条(term),例如keyword,就是不分词,还有ik_smart
- tokenizer filter:将tokenizer输出的词条进一步处理。例如大小写转换、同义词处理,拼音处理等
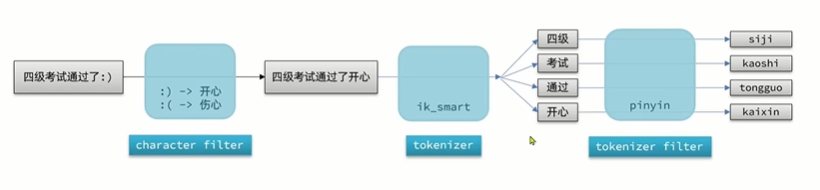
(1)创建自定义分词器
语法:
PUT /test
{
"settings": { //索引库配置,只针对当前索引库的
"analysis": {
"analyzer": { //自定义分词器
"my_analyzer": { //自定义分词器的名称
"tokenizer": "ik_max_word",
"filter": "py" //下边过滤名称
}
},
"filter": { //自定义的tokenizer filter
"py": { //过滤器名称
"type":"pinyin", //过滤器类型,这里是pinyin,一下配置可在pinyin分词器官网找到
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": { //建立mapping映射
"properties": {
"name": {
"type": "text",
"analyzer": "my_analyzer" //使用自定义分词器
}
}
}
}
用法:
//错误用法,因为定义的分词器只能针对当前索引库的,所以这里使用会报错
POST /_analyze
{
"text": ["如家酒店还不错"],
"analyzer": "my_analyzer" //使用自定义分词器
}
//正确用法,需要指定是哪个索引库
POST /test/_analyze
{
"text": ["如家酒店还不错"],
"analyzer": "my_analyzer" //使用自定义分词器
}
(2)自定义分词器存在的问题
问题复现:
首先插入两条数据
POST /test/_doc/1
{
"id":1,
"name":"狮子"
}
POST /test/_doc/2
{
"id":2,
"name":"虱子"
}
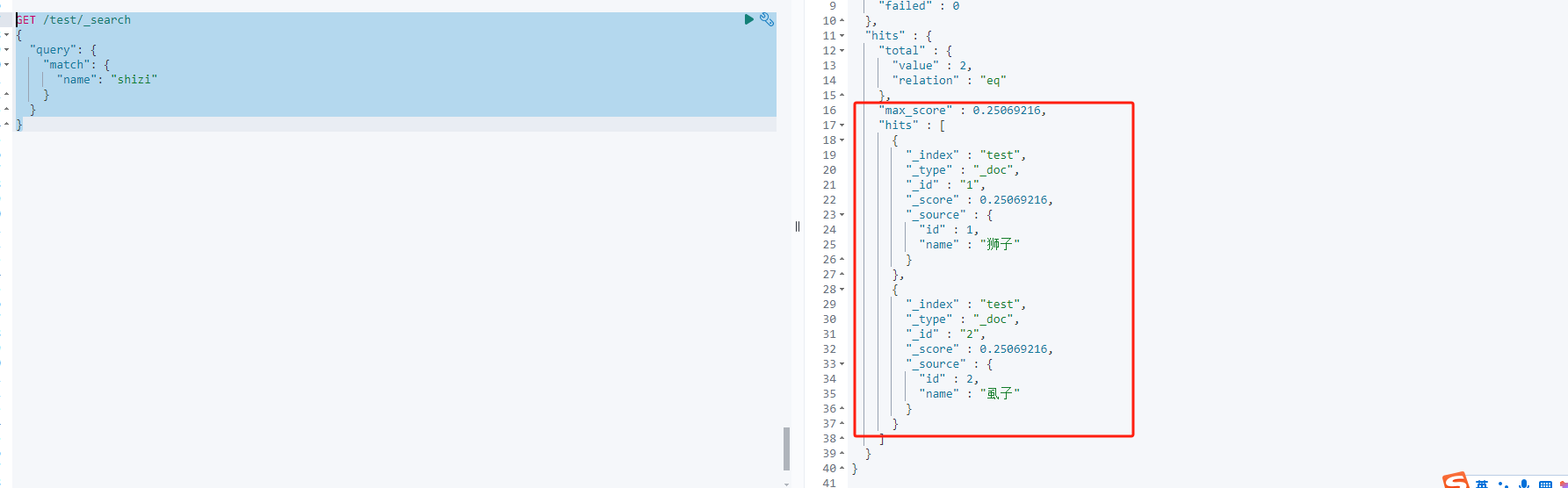
使用拼音查询:
//使用拼音查询,没有问题,可以搜索出两条结果
GET /test/_search
{
"query": {
"match": {
"name": "shizi"
}
}
}
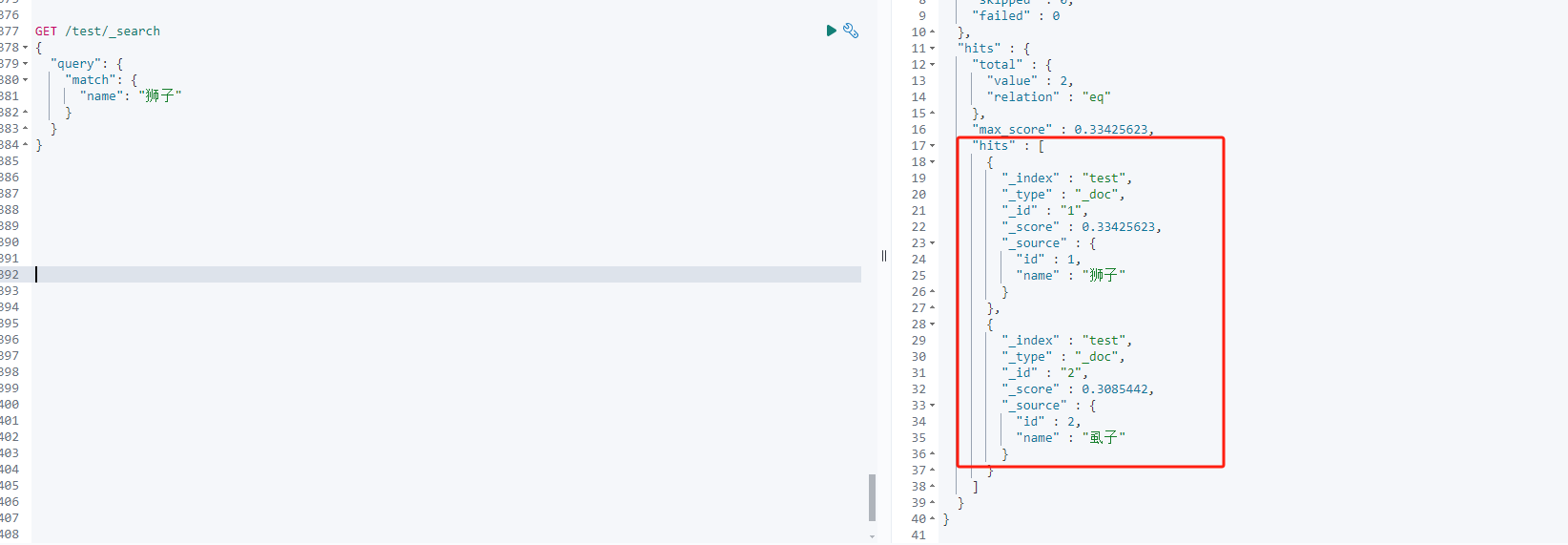
使用中文查询:
//使用中文查询,还是会出现两条结果,出现问题
GET /test/_search
{
"query": {
"match": {
"name": "狮子"
}
}
}
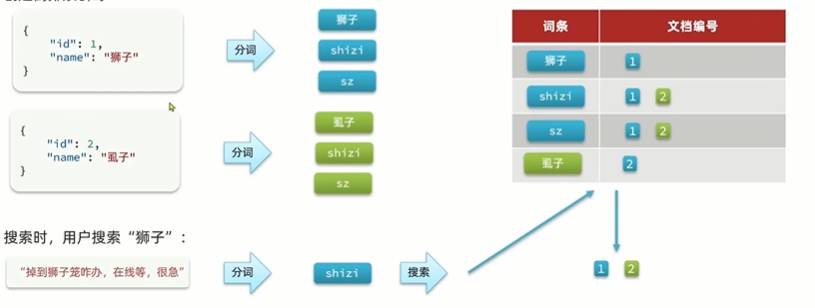
总结:在创建索引库时,使用自定义分词器后,在插入数据创建倒排索引时,es会将进行拆分,如果词条的拼音一样,那么就不会再创建倒排索引,而是在之前一样的拼音的文档编号上将一样拼音的id放入,结果就是查询的时候出现了这样的问题
(3)自定义分词器问题解决方案
在创建索引库时使用拼音分词器,但是搜索时不使用拼音分词器
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": {
"py": {
"type":"pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "my_analyzer",
"search_analyzer": "ik_smart" //指定搜索时的分词器
}
}
}
}
3、DSL自动补全(其中一种,一共三种)
completion suggester查询
es提供了Completion Suggester查询来实现自动补全功能。这个查询会匹配以用户输入内容开头的词条并返回。为了提高补全的效率,对于文档中字段的类型有一些约束:
- 参与自动补全查询的字段必须是 completion 类型
- 字段的内容一般是用来补全的多个词条形成的数组
创建索引库时指定自动补全字段:
PUT test2
{
"mappings": {
"properties": {
"title": {
"type": "completion" //指定索引库中属性的字段类型为 completion
}
}
}
}
插入数据(词条以数组的形式):
POST test2/_doc
{
"title": ["Sony", "WH-10000XM3"]
}
POST test2/_doc
{
"title": ["SK-II", "PITERA"]
}
POST test2/_doc
{
"title": ["NIntendo", "switch"]
}
自动补全查询:
GET /test2/_search
{
"suggest": {
"title_suggest": { //自定义自动补全查询名称
"text": "so", //输入的查询文本
"completion": { //自动补全类型
"field": "title", //自动补全字段
"skip_duplicates": true, //跳过重复的值
"size": 10 //获取前10条结果
}
}
}
}
4、示例
1、修改hotel索引库,支持自动补全和拼音分词器
// 删除原有的hotel索引库
DELETE hotel
//创建hotel索引库
PUT hotel
{
"settings": {
"analysis": {
"analyzer": {
"text_analyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
},
"completion_analyzer": {
"tokenizer": "keyword",
"filter": "py"
}
},
"filter": {
"py": {
"type":"pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"name": {
"type": "text",
"analyzer": "text_analyzer",
"search_analyzer": "ik_smart",
"copy_to": "all"
},
"address": {
"type": "keyword",
"index": false
},
"price": {
"type": "integer"
},
"score": {
"type": "integer"
},
"brand": {
"type": "keyword",
"copy_to": "all"
},
"city": {
"type": "keyword"
},
"starName": {
"type": "keyword"
},
"business": {
"type": "keyword",
"copy_to": "all"
},
"location": {
"type": "geo_point"
},
"pic": {
"type": "keyword",
"index": false
},
"all": {
"type": "text",
"analyzer": "text_analyzer",
"search_analyzer": "ik_smart"
},
"suggestion": {
"type": "completion",
"analyzer": "completion_analyzer"
}
}
}
}
2、修改原有的java对象 HotelDoc.java,新增suggestion属性,用来做自动补全
@Data
@NoArgsConstructor
public class HotelDoc {
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String location;
private String pic;
private List<String> suggestion;
public HotelDoc(Hotel hotel) {
this.id = hotel.getId();
this.name = hotel.getName();
this.address = hotel.getAddress();
this.price = hotel.getPrice();
this.score = hotel.getScore();
this.brand = hotel.getBrand();
this.city = hotel.getCity();
this.starName = hotel.getStarName();
this.business = hotel.getBusiness();
this.location = hotel.getLatitude() + "," + hotel.getLongitude();
this.pic = hotel.getPic();
//将现有数据作为自动补全存入suggestion
this.suggestion = Arrays.asList(this.brand, this.business, this.name);
}
}
3、导入数据
运行之前的单元测试批量导入数据
4、DSL测试
//测试自动补全
GET /hotel/_search
{
"suggest": {
"hotel_suggestion": {
"text": "江南",
"completion": {
"field": "suggestion",
"skip_duplicates": true
}
}
}
}
//测试拼音分词器
GET /hotel/_search
{
"query": {
"match": {
"all": "buding"
}
}
}
4、RestApi实现
/**
* 自动补全
* @throws IOException
*/
@Test
void testSuggest() throws IOException {
//1、准备request
SearchRequest request = new SearchRequest("hotel");
//2、查询条件
request.source().suggest(new SuggestBuilder().addSuggestion(
"hotel_suggestion",
SuggestBuilders
.completionSuggestion("suggestion")
.prefix("sh")
.skipDuplicates(true)
.size(10)
));
//3、发起请求,获取响应结果
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
System.out.println("相应结果 ---------- > " + response);
//解析返回值,获取自动补全结果
Suggest suggest = response.getSuggest();
CompletionSuggestion suggestion = suggest.getSuggestion("hotel_suggestion");
for (CompletionSuggestion.Entry.Option option : suggestion.getOptions()) {
String text = option.getText().toString();
System.out.println("自动补全词条值--------- > " + text);
}
}
八、数据同步
1、数据同步方式
方式一:同步调用
- 优点:实现简单、粗暴
- 缺点:业务耦合度高
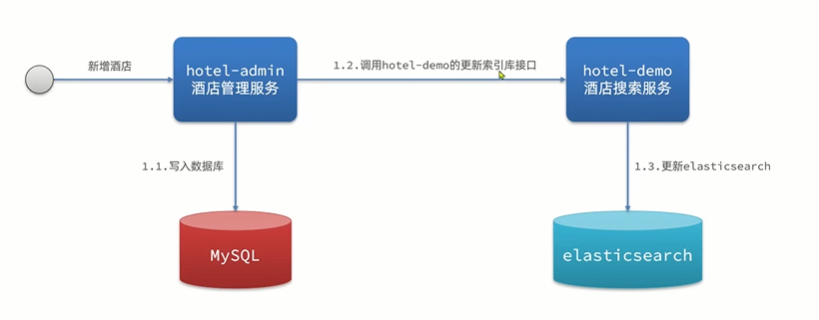
方式二:异步通知
- 优点:低耦合、实现难度一般
- 缺点:依赖mq的可靠性
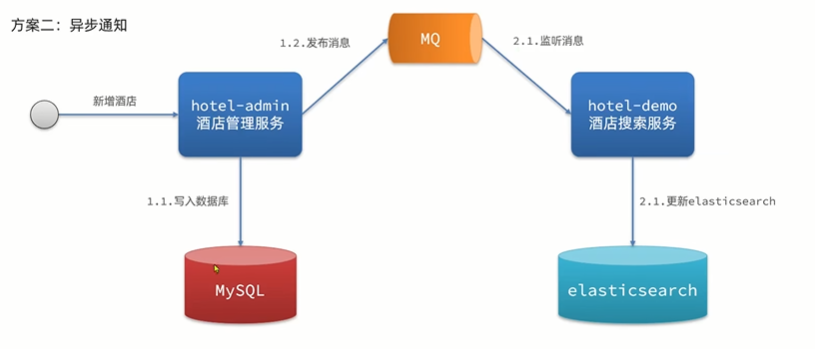
方式三:监听mysql的binlog
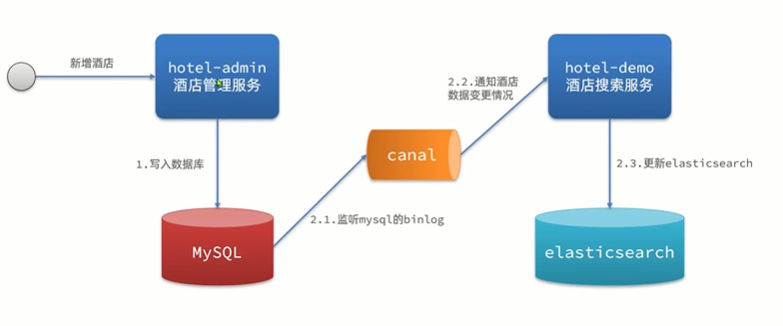
- 完全解除服务间的耦合
- 缺点:开启binlog增加数据库负担、实现复杂度高
2、基于mq实现数据同步
根据之前所学,进行练习
九、集群
1、结构
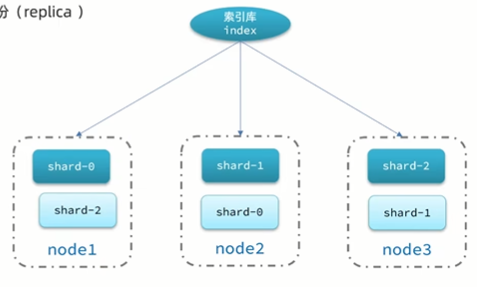
单机的es做数据存储,必然面临两个问题:海量数据存储问题、单点故障问题
- 海量数据存储问题:将索引库从逻辑上拆分为N个分片(shard),存储到多个节点
- 单点故障问题:将分片数据在不同节点备份(replica)
2、搭建集群
命令方式部署(不同的服务器上)
# 第一台服务器上的es容器
docker run -d \
--name es01 \
--network es-net \
--ulimit memlock=-1:-1 \
-p 9200:9200 \
-p 9300:9300 \
-e "network.host=0.0.0.0" \
-e "network.publish_host=192.168.132.128" \
-e "node.name=es01" \
-e "cluster.name=es-docker-cluster" \
-e "discovery.seed_hosts=192.168.132.129,192.168.132.131" \
-e "cluster.initial_master_nodes=es01,es02,es03" \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "bootstrap.memory_lock=true" \
-v /home/es/data01:/usr/share/elasticsearch/data \
-v /home/es/plugins01:/usr/share/elasticsearch/plugins \
elasticsearch:7.17.18
# 第二台服务器上的es容器
docker run -d \
--name es02 \
--network es-net \
--ulimit memlock=-1:-1 \
-p 9200:9200 \
-p 9300:9300 \
-e "network.host=0.0.0.0" \
-e "network.publish_host=192.168.132.129" \
-e "node.name=es02" \
-e "cluster.name=es-docker-cluster" \
-e "discovery.seed_hosts=192.168.132.128,192.168.132.131" \
-e "cluster.initial_master_nodes=es01,es02,es03" \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "bootstrap.memory_lock=true" \
-v /home/es/data02:/usr/share/elasticsearch/data \
-v /home/es/plugins02:/usr/share/elasticsearch/plugins \
elasticsearch:7.17.18
# 第三台服务器上的es容器
docker run -d \
--name es03 \
--network es-net \
--ulimit memlock=-1:-1 \
-p 9200:9200 \
-p 9300:9300 \
-e "network.host=0.0.0.0" \
-e "network.publish_host=192.168.132.131" \
-e "node.name=es03" \
-e "cluster.name=es-docker-cluster" \
-e "discovery.seed_hosts=192.168.132.128,192.168.132.129" \
-e "cluster.initial_master_nodes=es01,es02,es03" \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "bootstrap.memory_lock=true" \
-v /home/es/data03:/usr/share/elasticsearch/data \
-v /home/es/plugins03:/usr/share/elasticsearch/plugins \
elasticsearch:7.17.18
运行命令后,集群部署成功,使用cerebro进行容器管理
问题:
(1)报错原因:
bootstrap check failure [2] of [2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决方案:
需要修改linux权限
# 修改 /etc/sysctl.conf
vim /etc/sysctl.conf
# 在这个文件添加
vm.max_map_count=262144
# 让修改后的文件生效
sysctl -p
做完这些步骤之后,将es容器先删除,再重新run
(2)报错原因:
bootstrap check failure [1] of [1]: memory locking requested for elasticsearch process but memory is not locked
解决方法一:将bootstrap.memory_lock=true改成false,取消内存锁定
解决方法二:在环境变量中新增 –ulimit memlock=-1:-1
(3)报错原因:
每个节点都能启动,但是节点之间缺不能互相连接,形成不了集群
{"type": "server", "timestamp": "2024-06-21T08:29:34,750Z", "level": "WARN", "component": "o.e.d.HandshakingTransportAddressConnector", "cluster.name": "es-docker-cluster", "node.name": "es01", "message": "[connectToRemoteMasterNode[192.168.132.129:9300]] completed handshake with [{es02}{gDSdsTzfRC-4Y5_DyJlFfQ}{yYnnMJJsQQiJdTYqtgd-lQ}{172.18.0.2}{172.18.0.2:9300}{cdfhilmrstw}{ml.machine_memory=16637534208, ml.max_open_jobs=512, xpack.installed=true, ml.max_jvm_size=536870912, transform.node=true}] but followup connection failed",
"stacktrace": ["org.elasticsearch.transport.ConnectTransportException: [es02][172.18.0.2:9300] handshake failed. unexpected remote node {es01}{8C6LL9h1QyKrdcAp-Rin9w}{QgVGe5pVT-uw9A88tQh--w}{172.18.0.2}{172.18.0.2:9300}{cdfhilmrstw}{ml.machine_memory=16637542400, ml.max_open_jobs=512, xpack.installed=true, ml.max_jvm_size=536870912, transform.node=true}",
"at org.elasticsearch.transport.TransportService.lambda$connectionValidator$6(TransportService.java:468) ~[elasticsearch-7.17.18.jar:7.17.18]",
"at org.elasticsearch.action.ActionListener$MappedActionListener.onResponse(ActionListener.java:95) [elasticsearch-7.17.18.jar:7.17.18]",
"at org.elasticsearch.transport.TransportService.lambda$handshake$9(TransportService.java:577) [elasticsearch-7.17.18.jar:7.17.18]",
"at org.elasticsearch.action.ActionListener$DelegatingFailureActionListener.onResponse(ActionListener.java:219) [elasticsearch-7.17.18.jar:7.17.18]",
"at org.elasticsearch.action.ActionListenerResponseHandler.handleResponse(ActionListenerResponseHandler.java:43) [elasticsearch-7.17.18.jar:7.17.18]",
"at org.elasticsearch.transport.TransportService$ContextRestoreResponseHandler.handleResponse(TransportService.java:1471) [elasticsearch-7.17.18.jar:7.17.18]",
"at org.elasticsearch.transport.TransportService$ContextRestoreResponseHandler.handleResponse(TransportService.java:1471) [elasticsearch-7.17.18.jar:7.17.18]",
"at org.elasticsearch.transport.InboundHandler.doHandleResponse(InboundHandler.java:352) [elasticsearch-7.17.18.jar:7.17.18]",
"at org.elasticsearch.transport.InboundHandler.lambda$handleResponse$1(InboundHandler.java:340) [elasticsearch-7.17.18.jar:7.17.18]",
"at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingRunnable.run(ThreadContext.java:718) [elasticsearch-7.17.18.jar:7.17.18]",
"at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1144) [?:?]",
"at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:642) [?:?]",
"at java.lang.Thread.run(Thread.java:1583) [?:?]"] }
解决方法:
使用docker进行部署的时候,官方提供的方法是在相同的服务器使用docker进行容器隔离进行集群部署
在不同服务器上的节点,因为都是不同的ip,所以要指定每个es容器对外交互的ip
# 容器对外交互的ip,设置成为容器所在服务器的ip
network.publish_host=192.168.132.129
3、集群状态监控
监控工具下载地址:https://github.com/lmenezes/cerebro/releases
cerebro工具
下载对应的操作系统的压缩包,解压之后直接运行bin目录下的bat文件,运行完成后使用 ip+9000端口浏览器访问,输入其中一个es节点的地址即可
4、创建索引库
(1)使用kibana创建索引库并分片
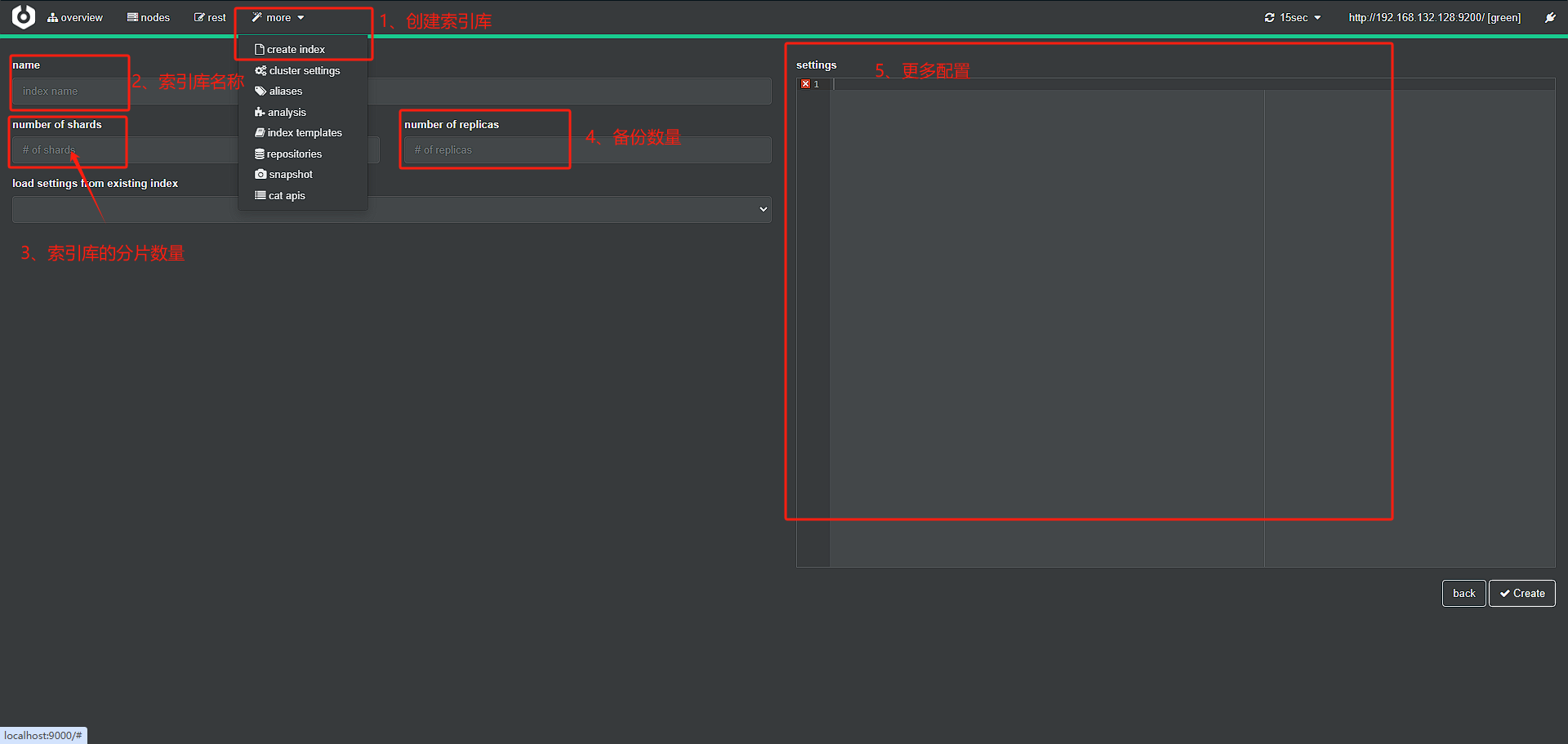
(2)使用cerebro创建索引库分片
步骤如下图
创建完成后,即可在首页查看
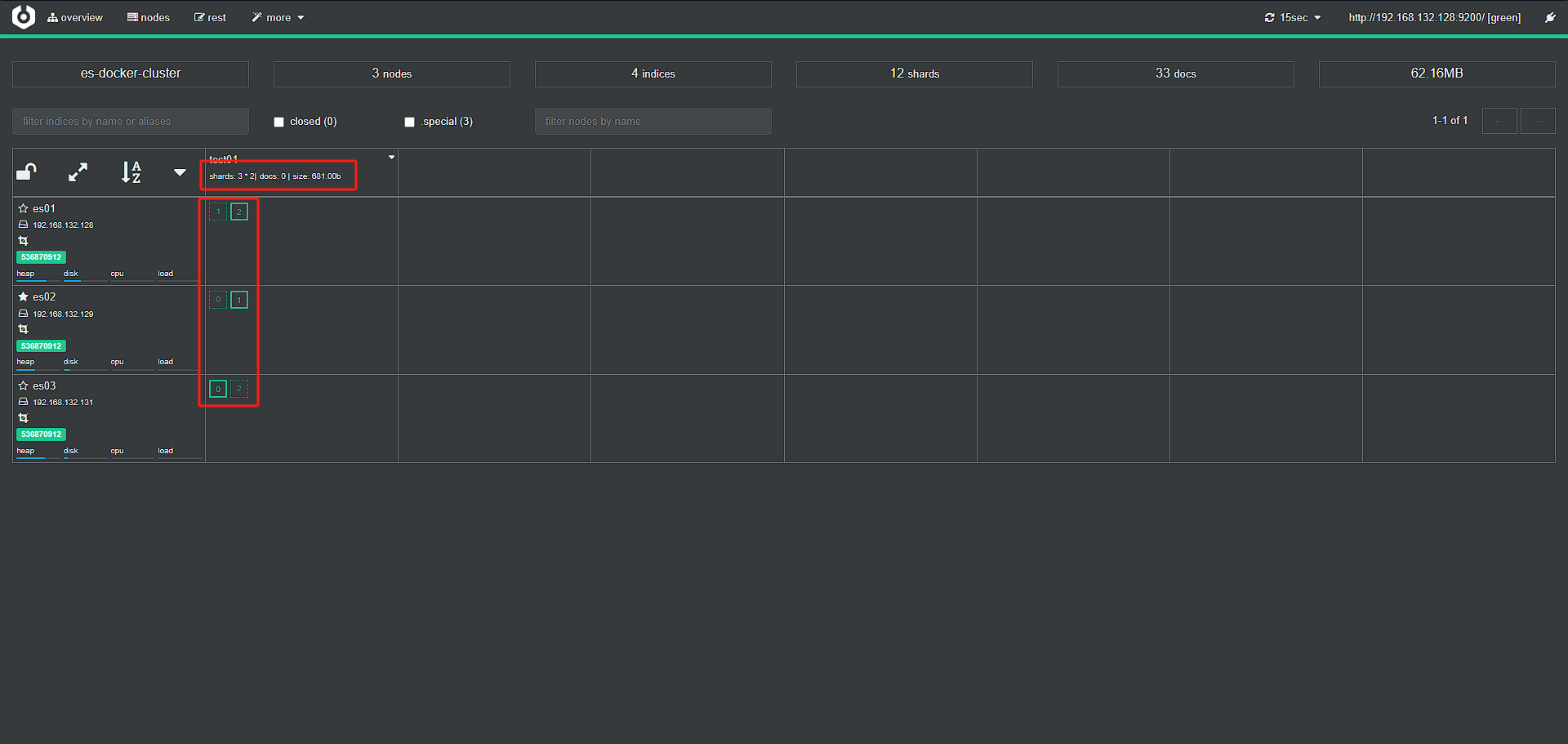
第一个红框表示索引库的分片信息
-
3*2:因为设置了分成3片,并且每个片区都进行了1个备份,所以每个节点上都是会有两份数据
-
实线绿色框表示为该节点的主分片,虚线绿色框表示为该节点当前所备份的数据分片
-
实线框与虚线框的数字不一样,原因是每个节点上虚线框为备份分片,es集群的备份分片不能放在与主分片相同的节点上,确保了如果有任意一个节点宕机,那么数据仍在另一节点上
5、集群职责与脑裂
5.1 集群职责
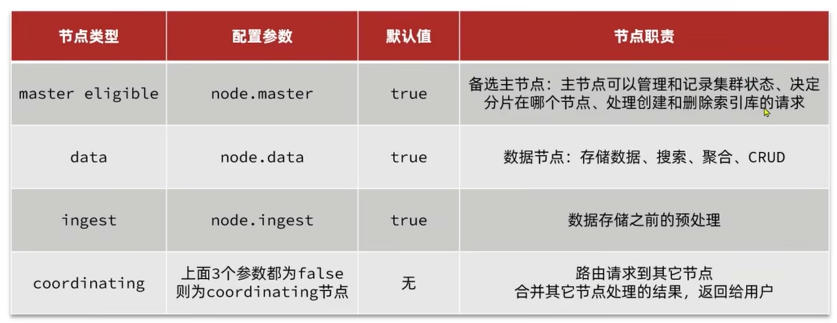
- master eligible:备选主节点,为了做高可用,万一主节点宕机了,可以充当主节点使用
- data:数据节点
- ingest:数据预处理节点,可以对数据存储之前做一下预处理,比如删除一些字段,插入一下字段,或者对内容进行修改,如果说在准备文档时用java代码对文档进行处理,那么该节点就没什么用处
- coordinating:协调节点,不做业务处理,做协调处理,路由+负载均衡
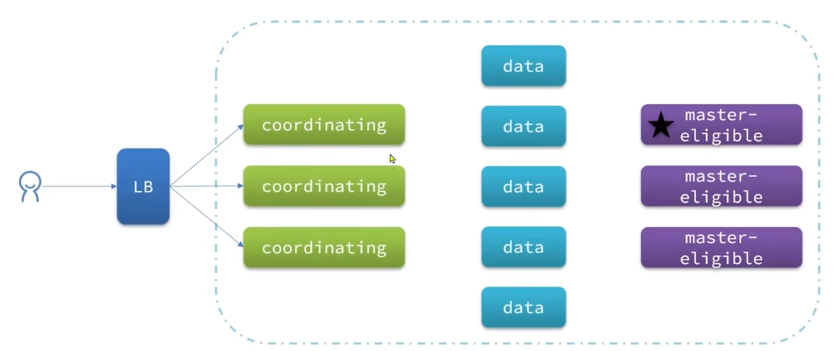
默认情况下,es的节点同时具备这四种角色,正常开发时,需要做配置,不推荐一个节点同时身兼数职
典型的es集群
5.2 脑裂问题
默认情况下,每个节点都是master eligible节点,因此一旦master节点宕机,其他候选节点会选举一个成为主节点。当主节点与其他节点网络故障时,可能发生脑裂问题。
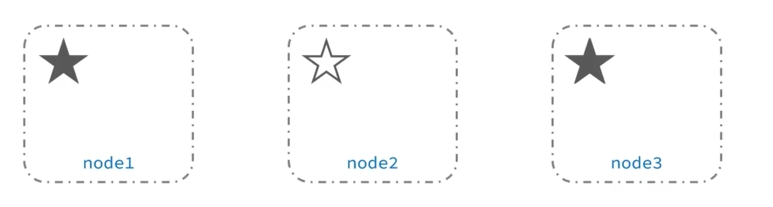
为了避免脑裂,需要要求选票超过(eligible节点数量 + 1)/ 2 才能当选为主,因此eligible节点数量最好是奇数。对应配置项是discovery.zen.minimum_master_nodes,在es7.0以后,已经默认配置,因此一般不会出现脑裂问题
通俗的讲就是当主节点还是好的,但是突然因为网络等原因,与其他节点断开连接,那么其他节点就会重新选举一个新的主节点,但是原来的主节点仍然能处理用户的请求数据,那么这两个就会导致有两个主节点在同时处理数据,最后主节点连接上其他节点后,就会造成数据不一致的情况。
6、分布式新增与查询
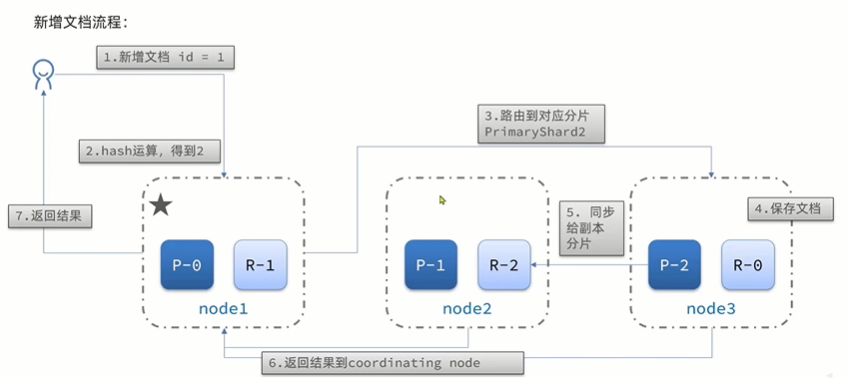
当新增文档时,应该保存到不同分片,保证数据均衡,es会通过hash算法来计算文档应该存储到哪个分片:

说明:
- _routing默认是文档的id
- 算法与分片数量有关,索引库一旦建立,分片数量不可修改,如果中途分片数量修改,那么插入的数据可能丢失
新增流程:
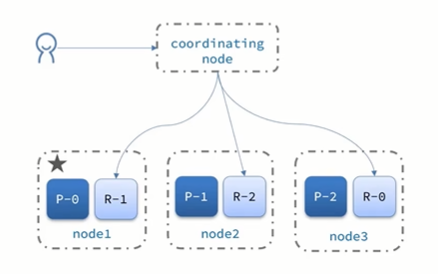
查询流程:
分两个阶段:
- scatter phase:分散阶段,coordinating node(协调节点)会把请求分发给每一个分片
- gather phase:聚集阶段,coordinating node(协调节点)汇总data node的搜索结果,并处理为最终结果集返回给用户
十、安全认证
es的x-pack安全认证
1、单机版
(1)进入容器内部,将es的config目录挂载到宿主机上,修改elasticsearch.yml文件
# 前面是默认的配置
cluster.name: "docker-cluster"
network.host: 0.0.0.0
ingest.geoip.downloader.enabled: false
# 新增xpack配置
xpack.security.enabled: true # 开启安全认证
xpack.license.self_generated.type: basic # 指定许可类型
xpack.security.transport.ssl.enabled: true # 用于启用节点之间的传输层安全
xpack.license.self_generated.type类型:
-
basic:免费许可证,提供基本功能,包括基础监控、Canvas、SQL 和安全性(基本认证和 TLS/SSL)。
-
trial:试用许可证,有效期为 30 天,提供所有 X-Pack 功能,包括高级安全性、机器学习、Graph 和 Kibana 的高级功能。
-
gold:收费许可证,提供高级监控、Alerting、Canvas 和 SQL 等功能。
-
platinum:收费许可证,提供所有 X-Pack 功能,包括机器学习、Graph 和高级安全性。
-
enterprise:最全面的收费许可证,提供企业级功能和支持。
(2)修改完成elasticsearch.yml配置文件后,重启es容器,让es容器使用自定义的yml配置文件
docker restart es
启动成功后, 通过浏览器 ip+端口 访问es,出现需要输入用户名和密码的警告窗就说明已经开启了防护
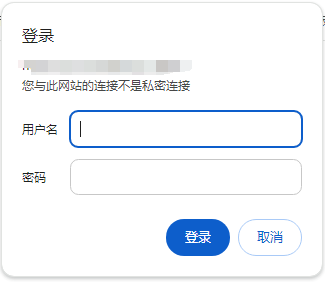
(3)进入容器,设置密码
# 进入容器
docker exec -it es bash
# 进入bin目录下,运行命令 interactive为手动设置密码
./elasticsearch-setup-passwords interactive
# ./elasticsearch-setup-passwords auto 自动生成密码
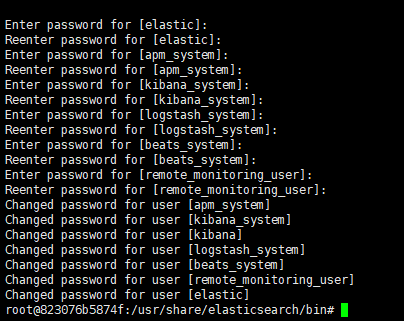
es内置elastic、apm_system、logstash_system、kibana等内置用户设置密码,手动设置需要一个个输入,建议使用同样的密码
输入完成后即可在浏览器的弹出框使用elastic内置用户进行登录,用户名为elastic,密码为刚刚输入的密码
输入密码确定后即可访问成功
内置用户的权限与作用
| 角色 | 用途 | 权限 | 描述 |
|---|---|---|---|
| elastic | 超级用户 | 拥有所有权限 | 用于初始设置和管理所有 Elasticsearch 功能。这个用户通常用于配置和管理整个集群,是具有最高权限的用户 |
| apm_system | 用于 Elastic APM(应用性能监控) | 具有对 APM 索引的读写权限,以及一些监控权限 | 用于 Elastic APM 服务器与 Elasticsearch 的通信,确保 APM 数据能够正确存储和检索 |
| kibana_system | 用于 Kibana 服务 | 具有对 .kibana* 索引的读写权限,并可以访问一些监控 API | 用于 Kibana 应用程序与 Elasticsearch 交互,管理 Kibana 索引和保存的对象,如仪表板、可视化等 |
| logstash_system | 用于 Logstash 服务 | 具有对 logstash-* 索引的读写权限,以及对 .logstash 内部索引的管理权限 | 用于 Logstash 服务与 Elasticsearch 交互,确保 Logstash 能够索引和管理数据流 |
| beats_system | 用于 Beats(如 Filebeat、Metricbeat 等) | 具有对 beats-* 索引的读写权限,以及对 .monitoring-beats-* 索引的读写权限 | 用于 Beats 客户端与 Elasticsearch 交互,确保 Beats 能够收集和索引数据 |
| remote_monitoring_user | 用于集群的远程监控 | 具有对监控相关的 API 和索引(如 .monitoring-*)的读写权限 | 用于 X-Pack Monitoring 功能,允许远程监控集群的状态和性能数据 |
2、集群版
(1)挂载配置
将每个es容器中的config配置文件挂载到宿主机上,每个节点都需要拷贝,方便后续使用自定义配置启动容器
# 将es容器中的config目录拷贝出来,做挂载
docker cp es01:/usr/share/elasticsearch/config /home/es
(2)证书生成
证书的作用主要是用于让每个es节点都能认识对方,然后建立通信
选择任意es节点,进入容器容器内部,使用x-pack提供的工具生成证书,工具在容器内的bin目录下
# 生成第一个证书
./elasticsearch-certutil ca
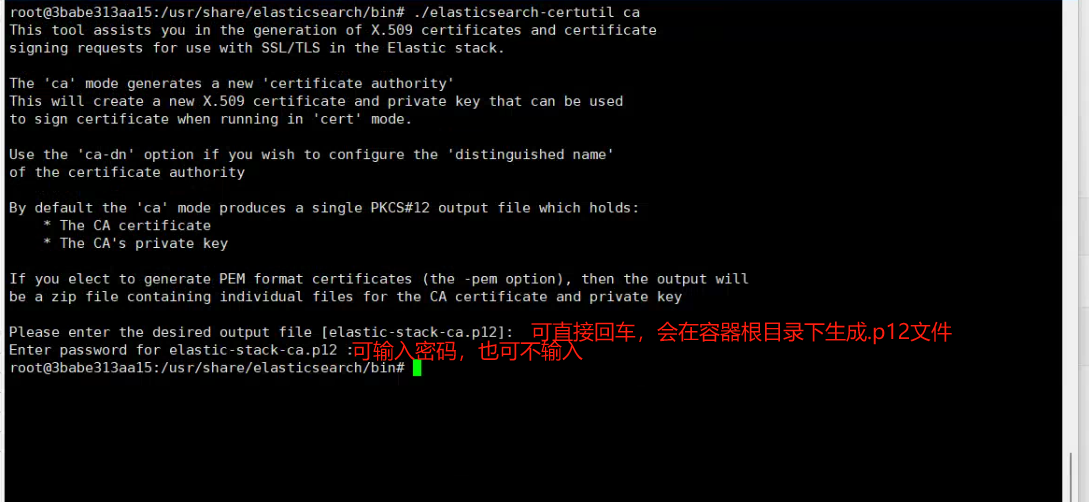
执行第二个命令
# 生成第二个证书,同第一个证书一样,可配置也可不配置,看个人情况
./elasticsearch-certutil cert -- ca elastic-stack-ca.p12
执行完成后即可在容器的根目录下出现两个证书
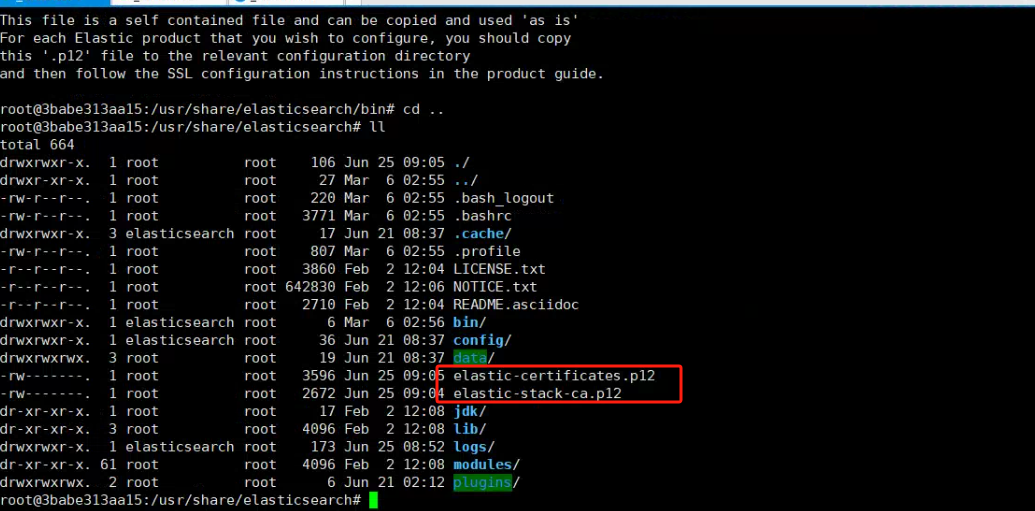
注意:需要注意拷贝出来的证书权限,权限不足的话容器无法读取证书
(3)配置证书
将这两个证书拷贝到宿主机上,放入第一步的config配置目录下,所有节点也是如此
# 两个证书都复制出来
docker cp es01:/usr/share/elasticsearch/elastic-certificates.p12 /home/es/config01
docker cp es01:/usr/share/elasticsearch/elastic-stack-ca.p12 /home/es/config01
(4)修改配置
修改每个节点的elasticsearch.yml配置文件
# 前三个配置在单机部署已有解释
xpack.security.enabled: true
xpack.license.self_generated.type: basic
xpack.security.transport.ssl.enabled: true
# 集群需要配置
xpack.security.transport.ssl.verification_mode: certificate # 校验签名和主机名
# 证书位置,注意这个位置是容器内config目录的位置,不是宿主机挂载的位置
xpack.security.transport.ssl.keystore.path: /usr/share/elasticsearch/config/elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: /usr/share/elasticsearch/config/elastic-certificates.p12
xpack.security.transport.ssl.verification_mode解释:用于指定节点之间在传输层安全(Transport Layer Security, TLS/SSL)通信时的证书验证模式
-
none:不进行任何验证。这意味着节点之间的通信将是加密的,但不会验证证书。这种模式通常用于测试环境,不推荐用于生产环境。
-
certificate:验证证书的签名和主机名。这是默认和推荐的选项,确保通信双方的证书是由受信任的 CA 签名的。
-
full:除了验证证书外,还验证证书的完整性和主机名。这是最严格的模式。
(5)重启容器
删除所有节点的docker容器,然后重新部署,将容器的config目录挂载到自定义的config目录下
# 第一台服务器上的es容器
docker run -d \
--name es01 \
--network es-net \
--ulimit memlock=-1:-1 \
-p 9200:9200 \
-p 9300:9300 \
-e "network.host=0.0.0.0" \
-e "network.publish_host=192.168.132.128" \
-e "node.name=es01" \
-e "cluster.name=es-docker-cluster" \
-e "discovery.seed_hosts=192.168.132.129,192.168.132.131" \
-e "cluster.initial_master_nodes=es01,es02,es03" \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "bootstrap.memory_lock=true" \
-v /home/es/data01:/usr/share/elasticsearch/data \
-v /home/es/plugins01:/usr/share/elasticsearch/plugins \
-v /home/es/config01:/usr/share/elasticsearch/config \
elasticsearch:7.17.18
# 第二台服务器上的es容器
docker run -d \
--name es02 \
--network es-net \
--ulimit memlock=-1:-1 \
-p 9200:9200 \
-p 9300:9300 \
-e "network.host=0.0.0.0" \
-e "network.publish_host=192.168.132.129" \
-e "node.name=es02" \
-e "cluster.name=es-docker-cluster" \
-e "discovery.seed_hosts=192.168.132.128,192.168.132.131" \
-e "cluster.initial_master_nodes=es01,es02,es03" \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "bootstrap.memory_lock=true" \
-v /home/es/data02:/usr/share/elasticsearch/data \
-v /home/es/plugins02:/usr/share/elasticsearch/plugins \
-v /home/es/plugins02:/usr/share/elasticsearch/plugins \
-v /home/es/config02:/usr/share/elasticsearch/config \
elasticsearch:7.17.18
# 第三台服务器上的es容器
docker run -d \
--name es03 \
--network es-net \
--ulimit memlock=-1:-1 \
-p 9200:9200 \
-p 9300:9300 \
-e "network.host=0.0.0.0" \
-e "network.publish_host=192.168.132.131" \
-e "node.name=es03" \
-e "cluster.name=es-docker-cluster" \
-e "discovery.seed_hosts=192.168.132.128,192.168.132.129" \
-e "cluster.initial_master_nodes=es01,es02,es03" \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "bootstrap.memory_lock=true" \
-v /home/es/data03:/usr/share/elasticsearch/data \
-v /home/es/plugins03:/usr/share/elasticsearch/plugins \
-v /home/es/config03:/usr/share/elasticsearch/config \
elasticsearch:7.17.18
随机访问当前的一个es节点,需要输入密码的就说明已经成功,使用cerebro集群监控也需要输入密码
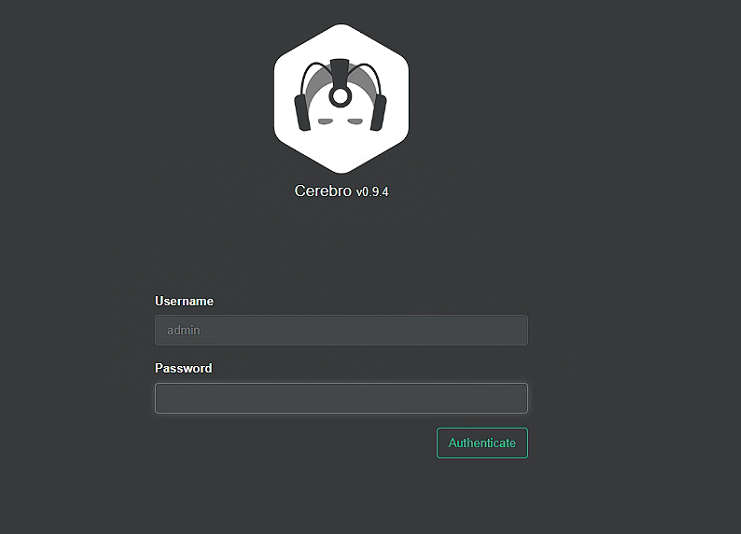
(6)设置密码
设置密码的方式与单机版相同,随机选择一个es节点,进入容器内部,使用x-pack工具设置密码即可
只需要在随机的一个es节点设置即可,不需要全部节点都要设置
3、kibana设置
es开启安全认证后,kibana需要连接到es也需要认证
3.1明文配置
通过在kibana.yml配置文件中配置es的用户名和密码进行连接
(1)修改yml配置
将kibana在容器中的config配置放到宿主机上
# 将kibana容器内的config配置复制到宿主机上
docker cp kibana:/usr/share/kibana/config /home/kibana
修改kibana.yml配置文件
# 默认配置
server.host: "0.0.0.0"
server.shutdownTimeout: "5s"
elasticsearch.hosts: [ "http://elasticsearch:9200" ] # es节点ip地址
monitoring.ui.container.elasticsearch.enabled: true
# 开启es安全认证
kibana.index: ".kibana" # kibana在es中存储数据的索引名称
i18n.locale: "zh-CN" # 语言设置,这里设置成中文
elasticsearch.username: "elastic" # es的用户名
elasticsearch.password: "123456" # es的连接密码
xpack.reporting.encryptionKey: "a_random_string" # 用于设置用于加密和解密报表数据的密钥,这里是随机字符
xpack.security.encryptionKey: "something_at_least_32_characters" # 用于加密和解密存储在 Kibana 中的敏感数据,这里是随机字符
(2)重启容器
指定好config的挂载目录,重新运行容器,也可删除容器后重新运行
docker run -d --name kibana \
--network=es-net \
-v /home/kibana/config:/usr/share/kibana/config \
-p 5601:5601 \
kibana:7.17.18
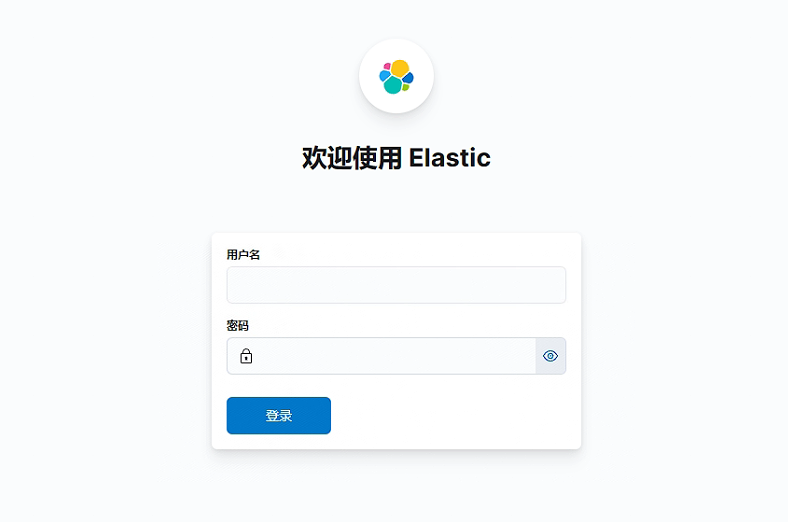
ip+端口访问kibana管理,出现需要输入用户名和密码即可成功,输入在kibana.yml中设置的用户名和密码即可访问

















 2864
2864

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









