








Graph Convolutional Networks 数据分析
前言
在前文中,已经对图卷积神经网络(Graph Convolutional Neural Networks, GCN)的理论基础和实践操作进行了深入探讨。相信你按照顺序阅读看到这里已经对GCN有一个全面而详细的认识,这里是一个额外的章节,准确的说是我的个人的实验部分,其主要目的是分享自己在学习GCN中的面对相关问题的思考。 如果你仅仅是想对GCN有一个初步的认识,当然可以不看这部分的内容。
当然我也希望这个文章能像这个题目一样,真正的帮助到有需要在此寻找答案的人。
这是原文的代码地址,感兴趣的读者自行下载即可 https://github.com/tkipf/pygcn

😃要是觉得还不错的话,烦请点赞,收藏➕关注👍
1.实验和论文的准确率差异问题?
GCN详解博文由于是我今年年初的创作。所以并没有对其论文进行精讲,但是相信有些查到这个文章的作者一定会有和我一样的疑问,就是为什么作者提供pytorch的GCN代码中在Cora数据集测试的准确率这么高,随随便便跑一次就能到83+。但是论文给出的结果是80左右。在后续的过程中我翻阅了其他人的论文多数都采用了80的结果,难道是我的实验环境有问题??
我对TF版本的代码进行复现。得到了和论文中一致的实验结果,但是我发现明明是一样的数据集,为什么TF中却使用格式是这样的?
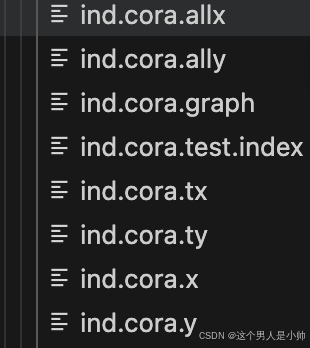
而pytorch版本的数据集却是这样的???
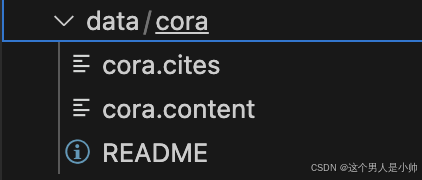
数据集的问题是不是影响准确率的关键呢??这个问题在我的小脑袋瓜子里油然而生???
但是这个时候还是没有办法验证,于是我在主流的DGL中试图复现GCN在Cora数据集下的结果,同样得到了和原始论文中接近的结果。并且其DGL中使用的数据集是和TFGCN一样的数据集。
我心想难道我发现了提升了GCN性能的关键了嘛?顶刊在想我招手,于是我对此进行了详细的分析。没发现什么问题,因此我推断可能是数据集的问题,导致的结果出现了偏差,但是这似乎并没有办法验证我的想法。因为我不知道这个Cora数据集是如何被预处理了x,y,tx,ty,allx,ally这样的形式。于是乎我开始了自己找寻Cora数据集是如何被预处理了x,y,tx,ty,allx,ally这样的形式的道路。
1.1 Pygcn的Readme
我试图通过PYGCN的作者那里找到答案。作者在的原文
Note: There are subtle differences between the TensorFlow
implementation in https://github.com/tkipf/gcn and this PyTorch
re-implementation. This re-implementation serves as a proof of concept
and is not intended for reproduction of the results reported in [1].This implementation makes use of the Cora dataset from [2].
翻译结果:
注:在 https://github.com/tkipf/gcn 提供的 TensorFlow 实现与此 PyTorch 重实现之间存在一些细微的差异。这个重实现主要是作为一个概念验证,并不旨在复现文献 [1] 中报告的结果。
本实现使用了来自 [2] 的 Cora 数据集。
作者说仅仅是为了展示这个torch的实现,所以不考虑太多细节问题,仅仅是为了展示其卷积行为。所以torch版本并不能对原文中的实验结果进行复现,这就表明作者实际上是知道结果不太准的,但是并没有提到Cora原始数据集是怎么变成x,y,tx,ty,allx,ally这种形式。所以俺去TF版本的github进行了刨根问题。
1.2 Tfgcn的Readme
我翻看了tf版本的GCN实现代码,也没找到这个这个Cora是如何处理成x,y,tx,ty,allx,ally这种形式。仅仅找到了这个数据集是怎么来的:
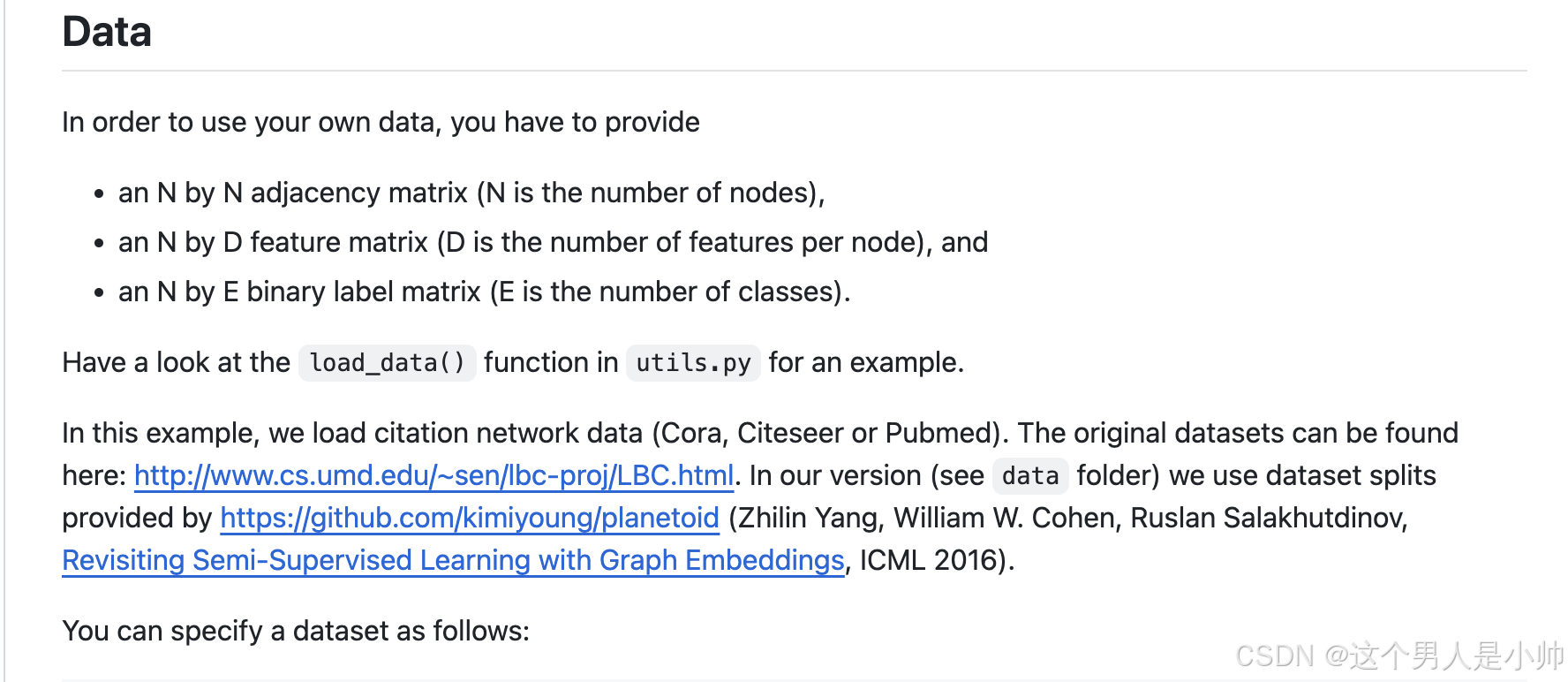
翻译成中文

作者指出这个Cora的数据分割版数据集并不是他处理得到的而是作者从网络上找到。而其pytorch版本的数据集使用的是原始数据集。据我分析,由于其论文中指出其使用的数据本身使用的就非原始版本,所以人家这个torch版本纯就是开源压榨自己实践给大家看看的。在此我断定那就是数据集的问题了,原作者也懒得观察人家这个数据集到底是怎么划分的所以仅仅使用顺序节点作为测试和训练所以这个数据的分布有问题,导致某一个简单的类别分的比较多才造成了结果的上升。但是我现阶段还是不想手动的去修改分布,一方面是有难度另一方面是还是不能作为基准这是我个人的猜想而已。也不利于后续做实验。所以所以我顺着这个链接找到了提供这个数据集的原始论文。
1.3 planetoid的Readme
我希望论文的原始作者能够提供这个Cora到x,y,tx,ty,allx,ally的数据预处理代码,这样的话。我就对数据进行预处理然后接上torch版本的GCN看看能不能复现论文中的结果。从此俺就能无缝的做实验了,还有一个基准,而不必依赖于这个被划分好的数据集,可以在原始数据集上大展身手。
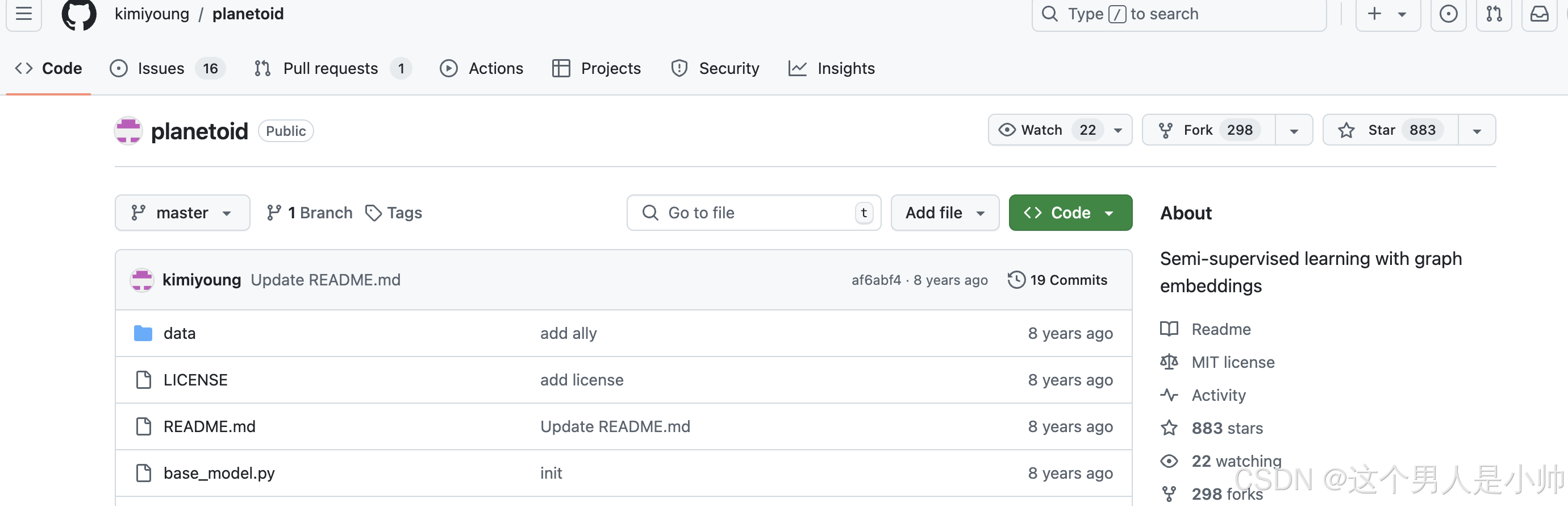
事实却是,这个大佬确实是大佬,我点开github人家这难以企及的高度,咱也没法问人家啊,并且在这个项目的Issues里面一大群人问大佬这个问题,没得到回复,我看简历人家忙着创业呢,另外这大老是metaAI的前员工,我寻思得了这线索又断了。不过我发现大多数人都和我有一样的需求,但是我是真闹心啊,怎么也找不到答案了。没办法了自己复现吧。
2. 分析问题
找了一路的线索断了,碎碎念了半天,走到头发现还需要靠自己,并且俺找这个代码找了三天。浪费了大量的时间,太难受了自己来吧。一顿心里挣扎,开工。
首先说下我的思路,我的目的是将Cora数据转换成x,y,tx,ty,allx,ally这样的形式。将处理文件给tfGCN作为原始数据集进行预测训练得到训练的结果。看看是不是和论文原始提供的一致,如果一致的话说明我处理的是有效的并且符合原作者的处理思路。
第二点就是我使用将Cora数据转换成x,y,tx,ty,allx,ally这样的形式。仅仅是一种数据集的划分方式直接接上pyGCN的代码,看看这个准确率是不是下降到了论文中的水平这样就能证明论文的GCN是有效的。其原始方案性能比论文中好,仅仅是处理数据集的分布方式有问题,并不是模型的问题。因此想好了问题的开工开工。
首先,就是分析x,y,tx,ty,allx,ally这数据集,看看其具体的什么构成的文件的形态是什么样子才能构建啊。
# 本代码的目的是尽可能的将cora的原始数据处理成和tfGCN中使用的到的数据集一致
import torch
import os
from utils import *
# 首先来看一下tfGCN中数据集的形状
import pickle
import numpy as np
# 文件介绍
# x,训练实例的特征向量,y,训练实例的独热标签,==train==
# tx,测试实例的特征向量,ty,测试实例的独热标签,==test==
# allx,有标签和无标签的特征数据都在这里,指出其实x和tx都是其子集。
# ally,中的实例的标签allx。同样y和ty都是其子集
# graph,dict格式为{index: [index_of_neighbor_nodes]}
# 其中邻居节点以列表形式组织。当前版本仅支持二进制图。就是低1行的数据为27表示第一个节点和第27存在边连接
# ------------------------------------------------------------------------------------------------------------------------------------------------
# #features = normalize(features) 在之前的作者是没有正则化过
# ------------------------------------------------------------------------------------------------------------------------------------------------
# 数据集原作者指出以预处理格式存储为 numpy/scipy 文件。对原始下载的cora数据使用稀疏处理所以要用到scipy
names = ['y', 'ty','ally','x', 'tx', 'allx','graph']
objects = []
# 加载数据文件并解析
for i in range(len(names)):
filepath = f"/Users/wangyang/Desktop/图神经网络实验代码/gcn-master/gcn/data/ind.cora.{names[i]}" # 数据集位置自己需要修改啊
with open(filepath, 'rb') as f:
data = pickle.load(f, encoding='latin1')
print(f"--- {names[i]} ---")
print(f"Type of data: {type(data)}")
# 根据数据类型决定打印方式
if isinstance(data, np.ndarray):
# 如果是NumPy数组,显示形状和前几个条目
print("Shape:", data.shape)
print("First few entries:\n", data[:10])
elif isinstance(data, dict):
# 如果是字典,显示键和一些键的值
keys = list(data.keys())
print("Keys:", keys[:5]) # 显示前5个键
sample_key = keys[0]
print(f"Sample value for key {sample_key}:\n", data[sample_key][:5])
elif isinstance(data, list):
# 如果是列表,直接显示前几个元素
print("First few entries:", data[:5])
else:
# 对其他未知类型简单展示
print("Data contents:\n", data[:200])
看一下输出结果吧,好分析下然后在模仿人家啊:
--- y ---
Type of data: <class 'numpy.ndarray'>
Shape: (140, 7)
First few entries:
[[0 0 0 1 0 0 0]
[0 0 0 0 1 0 0]
[0 0 0 0 1 0 0]
[1 0 0 0 0 0 0]
[0 0 0 1 0 0 0]
[0 0 1 0 0 0 0]
[1 0 0 0 0 0 0]
[0 0 0 1 0 0 0]
[0 0 0 1 0 0 0]
[0 0 1 0 0 0 0]]
--- ty ---
Type of data: <class 'numpy.ndarray'>
Shape: (1000, 7)
First few entries:
[[0 0 0 1 0 0 0]
[0 1 0 0 0 0 0]
[0 0 0 0 0 0 1]
[0 0 1 0 0 0 0]
[0 0 0 0 1 0 0]
[0 0 0 1 0 0 0]
[0 0 0 0 0 0 1]
[0 0 0 0 0 0 1]
[0 1 0 0 0 0 0]
[0 1 0 0 0 0 0]]
--- ally ---
Type of data: <class 'numpy.ndarray'>
Shape: (1708, 7)
First few entries:
[[0 0 0 1 0 0 0]
[0 0 0 0 1 0 0]
[0 0 0 0 1 0 0]
[1 0 0 0 0 0 0]
[0 0 0 1 0 0 0]
[0 0 1 0 0 0 0]
[1 0 0 0 0 0 0]
[0 0 0 1 0 0 0]
[0 0 0 1 0 0 0]
[0 0 1 0 0 0 0]]
--- x ---
Type of data: <class 'scipy.sparse._csr.csr_matrix'>
Data contents:
<Compressed Sparse Row sparse matrix of dtype 'float32'
with 2647 stored elements and shape (140, 1433)>
Coords Values
(0, 19) 1.0
(0, 81) 1.0
(0, 146) 1.0
(0, 315) 1.0
(0, 774) 1.0
(0, 877) 1.0
(0, 1194) 1.0
(0, 1247) 1.0
(0, 1274) 1.0
(1, 19) 1.0
(1, 88) 1.0
(1, 149) 1.0
(1, 212) 1.0
(1, 233) 1.0
(1, 332) 1.0
(1, 336) 1.0
(1, 359) 1.0
(1, 472) 1.0
(1, 507) 1.0
(1, 548) 1.0
(1, 687) 1.0
(1, 763) 1.0
(1, 808) 1.0
(1, 889) 1.0
(1, 1058) 1.0
: :
(138, 1263) 1.0
(138, 1274) 1.0
(138, 1290) 1.0
(138, 1307) 1.0
(138, 1406) 1.0
(139, 1) 1.0
(139, 41) 1.0
(139, 187) 1.0
(139, 212) 1.0
(139, 357) 1.0
(139, 404) 1.0
(139, 464) 1.0
(139, 505) 1.0
(139, 507) 1.0
(139, 581) 1.0
(139, 635) 1.0
(139, 874) 1.0
(139, 988) 1.0
(139, 1071) 1.0
(139, 1230) 1.0
(139, 1231) 1.0
(139, 1258) 1.0
(139, 1263) 1.0
(139, 1274) 1.0
(139, 1393) 1.0
--- tx ---
Type of data: <class 'scipy.sparse._csr.csr_matrix'>
Data contents:
<Compressed Sparse Row sparse matrix of dtype 'float32'
with 3642 stored elements and shape (200, 1433)>
Coords Values
(0, 311) 1.0
(0, 314) 1.0
(0, 353) 1.0
(0, 505) 1.0
(0, 510) 1.0
(0, 621) 1.0
(0, 1075) 1.0
(0, 1132) 1.0
(0, 1171) 1.0
(0, 1226) 1.0
(0, 1230) 1.0
(0, 1301) 1.0
(0, 1379) 1.0
(0, 1389) 1.0
(0, 1392) 1.0
(1, 78) 1.0
(1, 121) 1.0
(1, 228) 1.0
(1, 505) 1.0
(1, 510) 1.0
(1, 617) 1.0
(1, 662) 1.0
(1, 931) 1.0
(1, 988) 1.0
(1, 993) 1.0
: :
(198, 621) 1.0
(198, 670) 1.0
(198, 699) 1.0
(198, 724) 1.0
(198, 734) 1.0
(198, 782) 1.0
(198, 911) 1.0
(198, 972) 1.0
(198, 1116) 1.0
(198, 1139) 1.0
(198, 1149) 1.0
(198, 1308) 1.0
(198, 1330) 1.0
(198, 1334) 1.0
(199, 225) 1.0
(199, 284) 1.0
(199, 619) 1.0
(199, 646) 1.0
(199, 774) 1.0
(199, 824) 1.0
(199, 835) 1.0
(199, 964) 1.0
(199, 1079) 1.0
(199, 1253) 1.0
(199, 1424) 1.0
--- allx ---
Type of data: <class 'scipy.sparse._csr.csr_matrix'>
Data contents:
<Compressed Sparse Row sparse matrix of dtype 'float32'
with 3713 stored elements and shape (200, 1433)>
Coords Values
(0, 19) 1.0
(0, 81) 1.0
(0, 146) 1.0
(0, 315) 1.0
(0, 774) 1.0
(0, 877) 1.0
(0, 1194) 1.0
(0, 1247) 1.0
(0, 1274) 1.0
(1, 19) 1.0
(1, 88) 1.0
(1, 149) 1.0
(1, 212) 1.0
(1, 233) 1.0
(1, 332) 1.0
(1, 336) 1.0
(1, 359) 1.0
(1, 472) 1.0
(1, 507) 1.0
(1, 548) 1.0
(1, 687) 1.0
(1, 763) 1.0
(1, 808) 1.0
(1, 889) 1.0
(1, 1058) 1.0
: :
(198, 1381) 1.0
(198, 1389) 1.0
(198, 1412) 1.0
(198, 1414) 1.0
(199, 132) 1.0
(199, 135) 1.0
(199, 145) 1.0
(199, 336) 1.0
(199, 359) 1.0
(199, 474) 1.0
(199, 494) 1.0
(199, 507) 1.0
(199, 533) 1.0
(199, 570) 1.0
(199, 647) 1.0
(199, 724) 1.0
(199, 872) 1.0
(199, 971) 1.0
(199, 1141) 1.0
(199, 1184) 1.0
(199, 1257) 1.0
(199, 1272) 1.0
(199, 1352) 1.0
(199, 1388) 1.0
(199, 1389) 1.0
--- graph ---
Type of data: <class 'collections.defaultdict'>
Keys: [0, 1, 2, 3, 4]
Sample value for key 0:
[633, 1862, 2582]
看了下其实就是选择了140个节点作为测试,x这个集合是1708节点allx集合的子集。tx就是测试集合。tx的形状是1000所以就是1000个节点。1708+1000=2708 正好是全部的节点。
在此解释下:
数据集内容说明
Cora数据集包含以下文件,用于图神经网络研究中的节点分类任务:
-
ind.cora.x: 训练集节点特征向量,保存为scipy.sparse.csr.csr_matrix。实际展开后的大小为:(140, 1433)。 -
ind.cora.tx: 测试集节点特征向量,保存为scipy.sparse.csr.csr_matrix。实际展开后的大小为:(1000, 1433)。 -
ind.cora.allx: 包含有标签和无标签的训练节点特征向量,保存为scipy.sparse.csr.csr_matrix。实际展开后的大小为:(1708, 1433)。可以理解为除测试集以外的其他节点特征集合,训练集是它的子集。allx和tx共同构成了全部的数据集节点特征 -
ind.cora.y: 训练节点的标签,采用one-hot表示,保存为numpy.ndarray。 -
ind.cora.ty: 测试节点的标签,采用one-hot表示,保存为numpy.ndarray。 -
ind.cora.ally: 对应ind.cora.allx的标签,采用one-hot表示,保存为numpy.ndarray。 -
ind.cora.graph: 保存节点之间边的信息,格式为{ index : [ index_of_neighbor_nodes ] }。 -
ind.cora.test.index: 保存测试集节点的索引,为List类型,用于后面的归纳学习设置。
我想着先看看TF代码中测试验证训练数据的类别分布情况吧,我推测是不是torch 版本选择数据集仅仅是按顺序选择的没有考虑分布的问题呢,这才导致了训练的问题????
# 观察不同数据中的类别分布情况,从而判断是不是仅仅只是随便的设定数据集
import os
import pickle
import numpy as np
# 定义文件名和空列表以存储对象
names = ['y','ty','ally']
objects = []
# 加载数据文件并解析
for name in names:
filepath = f"/Users/wangyang/Desktop/图神经网络实验代码/gcn-master/gcn/data/ind.cora.{name}"
with open(filepath, 'rb') as f:
data = pickle.load(f, encoding='latin1')
print(f"Loaded {name} data with shape {data.shape}")
# 计算每个类别的计数
# data是一个二维numpy矩阵,其中data的每一行渲染one-hot编码的标签
class_counts = np.sum(data, axis=0) # 沿着行合计,得到每个类别的总计
# 输出每个类的计数
print("Counts for each class:", class_counts)
# 可以看到每一个类别的数据是均匀的。也就疏松pytorh的版本数据某种意义上是和这个tf数据不一致的
运行结果如下:
Loaded y data with shape (140, 7)
Counts for each class: [20 20 20 20 20 20 20]
Loaded ty data with shape (1000, 7)
Counts for each class: [130 91 144 319 149 103 64]
Loaded ally data with shape (1708, 7)
Counts for each class: [221 126 274 499 277 195 116]
看上文数量上其实看不出这个类别的分布情况,但是看训练集合y中类别情况是一致的。这就验证了我的猜想,很有可能是是数据分布出了问题,torch版本的代码中仅选择了前140和顺序选择的1000个节点用来做测试,并没有考虑分布问题,原始杂乱的Cora难道就会提前考虑分布问题吗??显然不会考虑那就是分布出了问题代来的torch版本的性能提升。
不过我还是对tf版本的Cora数据进行了分布的计算:
import numpy as np
# 全数据集(包括有标签和无标签数据的节点,不只是训练数据)类别分布
allx_distribution = np.array([221, 126, 274, 499, 277, 195, 116])
# 训练数据集类别分布(教学说明用,事实上已包含在allx中)
x_distribution = np.array([20, 20, 20, 20, 20, 20, 20])
# 测试数据集类别分布
tx_distribution = np.array([130, 91, 144, 319, 149, 103, 64])
# 计算整个数据集(包括训练、无标签和测试集的节点)的类别分布
overall_distribution = allx_distribution + tx_distribution # allx 和 tx 合并
# 计算整个数据集中每个类别的比例
overall_proportions = overall_distribution / np.sum(overall_distribution)
# 计算 allx 中每个类别的比例
allx_proportions = allx_distribution / np.sum(allx_distribution)
# 计算 tx 中每个类别的比例
tx_proportions = tx_distribution / np.sum(tx_distribution)
# 计算allx与tx 与整体的比例差异
difference_overall_allx = overall_proportions - allx_proportions
difference_overall_tx = overall_proportions - tx_proportions
# 输出各类的绝对数量和比例
print("Overall Class Distribution:", overall_distribution)
print("Overall Class Proportions:", overall_proportions)
# 打印出具体的比例和差异
print("Proportions in allx:", allx_proportions)
print("Proportions in tx:", tx_proportions)
print("Difference in proportions (Overall - Allx):", difference_overall_allx)
print("Difference in proportions (Overall - Tx):", difference_overall_tx)
结果可想而知,可以看到数据集合中测试集合全部集合的类别分布是相同的并且两个数据集的类别分布差值很小。测试集的分布相对接近整体数据集的分布,偏差在可接受范围内。所以其1000个数据节点的设定是按照原始数据集的分布均匀设定的。这表明测试集的 1000 个数据节点是根据原始数据集的类别比例来均匀设定的,确保了测试集能够代表性地反映整个数据集的特点。
可以说明其pytorch版本差异就是来源于数据集
Overall Class Distribution: [351 217 418 818 426 298 180]
Overall Class Proportions: [0.12961595 0.08013294 0.15435746 0.30206795 0.15731167 0.11004431
0.06646972]
Proportions in allx: [0.1293911 0.07377049 0.16042155 0.29215457 0.16217799 0.11416862
0.06791569]
Proportions in tx: [0.13 0.091 0.144 0.319 0.149 0.103 0.064]
Difference in proportions (Overall - Allx): [ 0.00022485 0.00636245 -0.00606409 0.00991338 -0.00486632 -0.00412431
-0.00144597]
Difference in proportions (Overall - Tx): [-0.00038405 -0.01086706 0.01035746 -0.01693205 0.00831167 0.00704431
0.00246972]
3. 解决问题
那就按分析出来的分布情况去设计测试集合就可以了,训练集合就采用每个类别20个节点进行测试呗:
import numpy as np
from collections import Counter
# 设置路径和文件名
path = "/Users/wangyang/Desktop/图神经网络实验代码/使用cora对原始数据集生成x,y/cora/"
dataset = "cora"
file_path = "{}{}.content".format(path, dataset)
# 加载数据
idx_features_labels = np.genfromtxt(file_path, dtype=np.dtype(str))
# 分离ID、特征和标签
IDs = idx_features_labels[:, 0] # ID 在第一列
features = idx_features_labels[:, 1:-1] # 特征在中间列
labels = idx_features_labels[:, -1] # 标签在最后一列
# 统计各类别的数量
label_counts = Counter(labels)
total_samples = len(labels)
print("类别分布:", label_counts)
# 计算测试集每个类别所需抽取的样本数
num_samples_for_test = 1000
samples_per_class = {label: int((count / total_samples) * num_samples_for_test) for label, count in label_counts.items()}
print("抽取各类别计算样本数:", samples_per_class)
np.random.seed(42) # 确保可复现性
test_idx = np.array([], dtype=int)
# 按类别抽取测试样本
for label, count in samples_per_class.items():
idx = np.where(labels == label)[0]
chosen_idx = np.random.choice(idx, count, replace=False)
test_idx = np.concatenate((test_idx, chosen_idx))
# 从原始数据中分离出测试集
test_data = idx_features_labels[test_idx, :]
np.random.shuffle(test_data)
# 从原始数据中删除测试用的样本
remaining_data = np.delete(idx_features_labels, test_idx, axis=0)
# 在剩余数据中选取每个类别的20个样本作为训练集
train_idx = np.array([], dtype=int)
for label in set(labels):
idx = np.where(remaining_data[:, -1] == label)[0]
chosen_idx = np.random.choice(idx, 20, replace=False)
train_idx = np.concatenate((train_idx, chosen_idx))
# 将选定训练样本移到数据集前端
train_data = remaining_data[train_idx, :]
non_train_data = np.delete(remaining_data, train_idx, axis=0)
np.random.shuffle(train_data)
np.random.shuffle(non_train_data)
ordered_data = np.vstack([train_data, non_train_data, test_data])
# 输出新的数据集情况
print("新数据集的总行数:", ordered_data.shape[0])
print("原始数据集的行数:", idx_features_labels.shape[0]) # 验证行数是否一致
# 存储或进一步处理 ordered_data
print(ordered_data[:, -1] )
然后看下模型的展示出来的数据个数和分布情况:
类别分布: Counter({'Neural_Networks': 818, 'Probabilistic_Methods': 426, 'Genetic_Algorithms': 418, 'Theory': 351, 'Case_Based': 298, 'Reinforcement_Learning': 217, 'Rule_Learning': 180})
抽取各类别计算样本数: {'Neural_Networks': 302, 'Rule_Learning': 66, 'Reinforcement_Learning': 80, 'Probabilistic_Methods': 157, 'Theory': 129, 'Genetic_Algorithms': 154, 'Case_Based': 110}
新数据集的总行数: 2708
原始数据集的行数: 2708
['Theory' 'Probabilistic_Methods' 'Neural_Networks' ...
'Probabilistic_Methods' 'Neural_Networks' 'Neural_Networks']
新构建的这个和tf使用的还是看起来很一致的。
看下数据的分布情况:
# 计算训练集中各类别的分布情况
train_labels = train_data[:, -1] # 提取训练数据的标签部分
train_label_distribution = Counter(train_labels)
print("训练集各类别分布情况:", train_label_distribution)
# 计算测试集中各类别的分布情况
test_labels = test_data[:, -1] # 提取测试数据的标签部分
test_label_distribution = Counter(test_labels)
print("测试集各类别分布情况:", test_label_distribution)
训练集各类别分布情况: Counter({'Theory': 20, 'Probabilistic_Methods': 20, 'Neural_Networks': 20, 'Reinforcement_Learning': 20, 'Case_Based': 20, 'Genetic_Algorithms': 20, 'Rule_Learning': 20})
测试集各类别分布情况: Counter({'Neural_Networks': 302, 'Probabilistic_Methods': 157, 'Genetic_Algorithms': 154, 'Theory': 129, 'Case_Based': 110, 'Reinforcement_Learning': 80, 'Rule_Learning': 66})
上面代码整体是将测试集合特征节点最后一千个节点进行作为测试,并且其类别分布和整体一致。作为最终的测试数据。
其整体顺序是被打乱的主要是不想让相同类的数据索引数紧挨着,使用140个数据节点作为训练,每个类别20个并最终做进行了打乱。最终得到的数据形态
0-139是训练后面的到1707是没用上作为无标签只使用特征, 后面的1000作为最终的测试集合。
将修改后的数据处理代码对pyGCN中使用的load_data进行修改。将训练集合的类别分布做的和tf代码中的一致。测试集合的也一致的和总体一致。
我在此分享我修改的load_data的代码部分:
import numpy as np
import scipy.sparse as sp
import torch
import numpy as np
from collections import Counter
def encode_onehot(labels): # 将全部label数据转换成独热编码表示
classes = set(labels) # 去除重复元素
classes_dict = {c: np.identity(len(classes))[i, :] for i, c in enumerate(classes)}
# 首先对全部类别进行编码。然后将索引和数值反转下,生成字典。一开始是[0,labelname],
# 反转后变成了labelname:类别的独热编码
labels_onehot = np.array(list(map(classes_dict.get, labels)),
dtype=np.int32)
# map() 会根据提供的函数对指定序列做映射。
# 将全部的特征都进行提花
return labels_onehot
def new_load_data(path="/Users/wangyang/Desktop/图神经网络实验代码/GCN/data/cora/", dataset="cora"):
file_path = "{}{}.content".format(path, dataset)
# 加载数据
idx_features_labels = np.genfromtxt(file_path, dtype=np.dtype(str))
# 分离ID、特征和标签
IDs = idx_features_labels[:, 0] # ID 在第一列
features = idx_features_labels[:, 1:-1] # 特征在中间列
labels = idx_features_labels[:, -1] # 标签在最后一列
# 统计各类别的数量
label_counts = Counter(labels)
total_samples = len(labels)
print("类别分布:", label_counts)
# 计算测试集每个类别所需抽取的样本数
num_samples_for_test = 1000
samples_per_class = {label: int((count / total_samples) * num_samples_for_test) for label, count in label_counts.items()}
print("抽取各类别计算样本数:", samples_per_class)
np.random.seed(42) # 确保可复现性
test_idx = np.array([], dtype=int)
# 按类别抽取测试样本
for label, count in samples_per_class.items():
idx = np.where(labels == label)[0]
chosen_idx = np.random.choice(idx, count, replace=False)
test_idx = np.concatenate((test_idx, chosen_idx))
# 从原始数据中分离出测试集
test_data = idx_features_labels[test_idx, :]
np.random.shuffle(test_data)
# 从原始数据中删除测试用的样本
remaining_data = np.delete(idx_features_labels, test_idx, axis=0)
# 在剩余数据中选取每个类别的20个样本作为训练集
train_idx = np.array([], dtype=int)
for label in set(labels):
idx = np.where(remaining_data[:, -1] == label)[0]
chosen_idx = np.random.choice(idx, 20, replace=False)
train_idx = np.concatenate((train_idx, chosen_idx))
# 将选定训练样本移到数据集前端
train_data = remaining_data[train_idx, :]
non_train_data = np.delete(remaining_data, train_idx, axis=0)
np.random.shuffle(train_data)
np.random.shuffle(non_train_data)
ordered_data = np.vstack([train_data, non_train_data, test_data])
idx_features_labels =ordered_data
# # 输出新的数据集情况
# print("新数据集的总行数:", ordered_data.shape[0])
# print("原始数据集的行数:", idx_features_labels.shape[0]) # 验证行数是否一致
# # 存储或进一步处理 ordered_data
# print(ordered_data[:, -1] )
features = sp.csr_matrix(idx_features_labels[:, 1:-1], dtype=np.float32)# sp.csr_matrix主要是对稀疏矩阵进行处理
# 全部行的第一列和倒数第二列的数据。第一列是索引信息 最后一列是标签信息,所以都不能用来做特征
labels = encode_onehot(idx_features_labels[:, -1]) # 将特征数据中的标签全部转换成度热向量
# build graph 图构建
idx = np.array(idx_features_labels[:, 0], dtype=np.int32) # 取出节点ID,引用文件中的第一列
idx_map = {j: i for i, j in enumerate(idx)} # 对ID进行编码然后做成字典。将一组身份id变成1,2,3这样的有序数据。和前面的技术一样翻过来做成字典
edges_unordered = np.genfromtxt("{}{}.cites".format(path, dataset),
dtype=np.int32) # 打开边信息的文件
edges = np.array(list(map(idx_map.get, edges_unordered.flatten())),
dtype=np.int32).reshape(edges_unordered.shape) # 通过构建的id到index进行映射。就从id-id变成index-index
adj = sp.coo_matrix((np.ones(edges.shape[0]), (edges[:, 0], edges[:, 1])), # 这里构建的方式使用了一个稀疏化的处理
shape=(labels.shape[0], labels.shape[0]), # 没有重复的节点所以直接点特征的数据的个数就行了
dtype=np.float32)
adj = adj + adj.T.multiply(adj.T > adj) - adj.multiply(adj.T > adj)
features = normalize(features) # 特征归一化
adj = normalize(adj + sp.eye(adj.shape[0])) # 加闭环然后邻接矩阵也进行归一化,这主要是GCN的能力
idx_train = range(140) # 训练节点个数
idx_val = range(1708, 2708) # 验证节点
idx_test = range(140, 1708) # 测试节点
print(2)
features = torch.FloatTensor(np.array(features.todense())) # 特征进行从np变成torch使用,前文中进行过稀疏矩阵的处理现在要变成稠密的再从np变成torch使用
labels = torch.LongTensor(np.where(labels)[1]) # 去找向量为1的位置的索引然后作为其label的类别,从数值变成度热编码最终变成数值形式
adj = sparse_mx_to_torch_sparse_tensor(adj) # 从稀疏矩阵变成torch中的稀疏矩阵
idx_train = torch.LongTensor(idx_train) # 单纯的类型转换
idx_val = torch.LongTensor(idx_val)
idx_test = torch.LongTensor(idx_test)
return adj, features, labels, idx_train, idx_val, idx_test
def load_data(path="/Users/wangyang/Desktop/图神经网络实验代码/GCN/data/cora/", dataset="cora"):
"""Load citation network dataset (cora only for now)"""
print('Loading {} dataset...'.format(dataset)) # 打印一句话数据名称正在加载
idx_features_labels = np.genfromtxt("{}{}.content".format(path, dataset), # .format的工作就是将会对上文中传下来的两个字符穿进行送入
dtype=np.dtype(str)) # 前面的括号。然后使用np.genfromtxt读取这个文件,并对其格式类型进行修改
features = sp.csr_matrix(idx_features_labels[:, 1:-1], dtype=np.float32)# sp.csr_matrix主要是对稀疏矩阵进行处理
# 全部行的第一列和倒数第二列的数据。第一列是索引信息 最后一列是标签信息,所以都不能用来做特征
labels = encode_onehot(idx_features_labels[:, -1]) # 将特征数据中的标签全部转换成度热向量
# build graph 图构建
idx = np.array(idx_features_labels[:, 0], dtype=np.int32) # 取出节点ID,引用文件中的第一列
idx_map = {j: i for i, j in enumerate(idx)} # 对ID进行编码然后做成字典。将一组身份id变成1,2,3这样的有序数据。和前面的技术一样翻过来做成字典
edges_unordered = np.genfromtxt("{}{}.cites".format(path, dataset),
dtype=np.int32) # 打开边信息的文件
edges = np.array(list(map(idx_map.get, edges_unordered.flatten())),
dtype=np.int32).reshape(edges_unordered.shape) # 通过构建的id到index进行映射。就从id-id变成index-index
adj = sp.coo_matrix((np.ones(edges.shape[0]), (edges[:, 0], edges[:, 1])), # 这里构建的方式使用了一个稀疏化的处理
shape=(labels.shape[0], labels.shape[0]), # 没有重复的节点所以直接点特征的数据的个数就行了
dtype=np.float32)
# row = np.array([0, 2, 2, 0, 1, 2])
# col = np.array([0, 0, 1, 2, 2, 2])
# data = np.array([1, 2, 3, 4, 5, 6])
# csc_matrix((data, (row, col)), shape=(3, 3)).toarray()
# array([[1, 0, 4],
# [0, 0, 5],
# [2, 3, 6]])
# build symmetric adjacency matrix
# 非对称邻接矩阵转变为对称邻接矩阵(有向图转无向图)
adj = adj + adj.T.multiply(adj.T > adj) - adj.multiply(adj.T > adj)
features = normalize(features) # 特征归一化
adj = normalize(adj + sp.eye(adj.shape[0])) # 加闭环然后邻接矩阵也进行归一化,这主要是GCN的能力
idx_train = range(140) # 训练节点个数
idx_val = range(200, 500) # 验证节点
idx_test = range(500, 1500) # 测试节点
features = torch.FloatTensor(np.array(features.todense())) # 特征进行从np变成torch使用,前文中进行过稀疏矩阵的处理现在要变成稠密的再从np变成torch使用
labels = torch.LongTensor(np.where(labels)[1]) # 去找向量为1的位置的索引然后作为其label的类别,从数值变成度热编码最终变成数值形式
adj = sparse_mx_to_torch_sparse_tensor(adj) # 从稀疏矩阵变成torch中的稀疏矩阵
idx_train = torch.LongTensor(idx_train) # 单纯的类型转换
idx_val = torch.LongTensor(idx_val)
idx_test = torch.LongTensor(idx_test)
return adj, features, labels, idx_train, idx_val, idx_test
def normalize(mx):
"""Row-normalize sparse matrix"""
rowsum = np.array(mx.sum(1)) # 按行求和
r_inv = np.power(rowsum, -1).flatten() # 进行分数话处理1/x
r_inv[np.isinf(r_inv)] = 0. # 处理和0进行倒置变成无穷的情况
r_mat_inv = sp.diags(r_inv) # 变成对角矩阵
mx = r_mat_inv.dot(mx) # 做乘积归一化
return mx
def accuracy(output, labels): # 准确率计算
preds = output.max(1)[1].type_as(labels)
correct = preds.eq(labels).double()
correct = correct.sum()
return correct / len(labels) # 计算方式统计下计算结果然后全部的数据比上正确的数值个数
def sparse_mx_to_torch_sparse_tensor(sparse_mx): # 这里稀疏矩阵变成torch类型的
"""Convert a scipy sparse matrix to a torch sparse tensor."""
sparse_mx = sparse_mx.tocoo().astype(np.float32)
indices = torch.from_numpy(
np.vstack((sparse_mx.row, sparse_mx.col)).astype(np.int64))
values = torch.from_numpy(sparse_mx.data)
shape = torch.Size(sparse_mx.shape)
return torch.sparse_coo_tensor(indices, values, shape)
使用我代码中的文件去替换掉你GCN中utils的文件内容,如果你在训练中使用的是new_load_data得到的数据将会得到论文中的结果。最终可得计算准确率百分之80和论文中一致。如果不修改这个loadedate则会出现较高的acc准确率,经分析其主要原因就是类别分布是随机可能将大量的简单的分类节点作为测试集合所以准确率上升。主要是其类别分布有问题导致的准确率上升,这并不是真实的代码性能提升。
上面啰啰嗦嗦说了大变天,怎么修改代码得到和论文中一样的结果,但是这个x,y,tx,ty,allx,ally文件怎么得到???????
import numpy as np
import scipy.sparse as sp
import pickle
# 以上为所需的模块导入,以下开始定义存储函数
file_path_base = '/Users/wangyang/Desktop/图神经网络实验代码/使用cora对原始数据集生成x,y/new_cora'
def save_data(base_path, filename, data):
full_path = f"{base_path}/{filename}"
with open(full_path, 'wb') as file:
pickle.dump(data, file)
def encode_onehot(labels): # 将全部label数据转换成独热编码表示
classes = set(labels) # 去除重复元素
classes_dict = {c: np.identity(len(classes))[i, :] for i, c in enumerate(classes)}
# 首先对全部类别进行编码。然后将索引和数值反转下,生成字典。一开始是[0,labelname],
# 反转后变成了labelname:类别的独热编码
labels_onehot = np.array(list(map(classes_dict.get, labels)),
dtype=np.int32)
# map() 会根据提供的函数对指定序列做映射。
# 将全部的特征都进行提花
return labels_onehot
# 分割数据和编码标签等操作,这里假设 encode_onehot, ordered_data, train_idx, test_idx 已经准备好
train_data = ordered_data[:140]
test_data = ordered_data[-1000:]
non_test_data = ordered_data[:-1000] # 所有数据除去 test_data
# 特征和标签提取
x = sp.csr_matrix(train_data[:, 1:-1].astype(float))
tx = sp.csr_matrix(test_data[:, 1:-1].astype(float))
allx = sp.csr_matrix(non_test_data[:, 1:-1].astype(float))
y = encode_onehot(train_data[:, -1])
ty = encode_onehot(test_data[:, -1])
ally = encode_onehot(non_test_data[:, -1])
# 使用pickle序列化并保存数据
save_data(file_path_base, "ind.cora.x", x)
save_data(file_path_base, "ind.cora.tx", tx)
save_data(file_path_base, "ind.cora.allx", allx)
save_data(file_path_base, "ind.cora.y", y)
save_data(file_path_base, "ind.cora.ty", ty)
save_data(file_path_base, "ind.cora.ally", ally)
各位在jupyter中复制我的代码顺序执行即可得到x,y,tx,ty,allx,ally的文件,这样就实现了从Cora到x,y,tx,ty,allx,ally的文件的完美转换。具体的在tf中的结果就请各位自己去试试吧,童叟无欺放心使用。
对了还有一个后缀是graph的文件生成结果如下就是边信息的编码文件而已:
idx_features_labels =ordered_data
# build graph 图构建
idx = np.array(idx_features_labels[:, 0], dtype=np.int32) # 取出节点ID,引用文件中的第一列
idx_map = {j: i for i, j in enumerate(idx)} # 对ID进行编码然后做成字典。将一组身份id变成1,2,3这样的有序数据。和前面的技术一样翻过来做成字典
edges_unordered = np.genfromtxt("{}{}.cites".format(path, dataset),
dtype=np.int32) # 打开边信息的文件
edges = np.array(list(map(idx_map.get, edges_unordered.flatten())),
dtype=np.int32).reshape(edges_unordered.shape) # 通过构建的id到index进行映射。就从id-id变成index-index
adj = sp.coo_matrix((np.ones(edges.shape[0]), (edges[:, 0], edges[:, 1])), # 这里构建的方式使用了一个稀疏化的处理
shape=(labels.shape[0], labels.shape[0]), # 没有重复的节点所以直接点特征的数据的个数就行了
dtype=np.float32)
adj = adj + adj.T.multiply(adj.T > adj) - adj.multiply(adj.T > adj)
from collections import defaultdict
import pickle
# 将稀疏矩阵转换为邻接列表的字典形式
def sparse_to_dict(adj):
adj_dict = defaultdict(list)
adj_coo = adj.tocoo() # 确保稀疏矩阵是COO格式,这是一个三元组形式(row, col, data)。
for i, j in zip(adj_coo.row, adj_coo.col):
if i != j: # 排除自环
adj_dict[i].append(j)
return adj_dict
# 调用转换函数
graph_dict = sparse_to_dict(adj)
output_path = '/Users/wangyang/Desktop/图神经网络实验代码/使用cora对原始数据集生成x,y/new_cora/ind.cora.graph'
# 序列化保存
with open(output_path, 'wb') as f:
pickle.dump(graph_dict, f)
for i in range(5):
print(f"Key: {i}, Value: {graph_dict[i]}")
我已经做了详细的注释各位自行修改哦,接着各位再用我上面分析数据的代码去分析新生成的数据,就可以看到其和TF中提供的数据是高度一致的。
细心的同学可以看到我们可以还有最后一个没生成结束那就是testindex文件,这个文件就是存储用来测试节点的索引号。其索引的顺序是被打乱的。这是为什么呢,
其主要目的就是为了控制和管理测试集数据的顺序。这种处理方式常用于确保模型测试的泛化性和健壮性,防止特定顺序可能带来的偏见。上文中我们查看到这个文件中的数据
仅仅采用了最后1000个节点进行索引,然后打乱他们的顺序作为索引测试节点的输入顺讯。但是在pygcn的代码背景下显然没什么用。所以后续的这个部分我会在其讲解AMGCN的时候进行讲解这个奇怪的小trick不过,我相信各位看了这么多应该明白的差不多了。
总结
这个问题的思索我搜索了互联网的各种各样的角落都没好到我想要的答案,因此我将答案写在这里,希望能帮到路过的你,我对一些细节并没有像其他博文一样进行初学者是讲解,我相信这么刨根问底的你也不会是一个初学者。一定能够轻松的搞定的,感谢你的观看。如果您觉得还不错的话,可以奖励打赏小弟一杯咖啡钱,创作不易。如果你对此感兴趣,不妨点赞、收藏并关注,这是对我工作的最大支持和鼓励。非常感谢!如果有任何问题,欢迎随时私信我。期待与你的互动!





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











