







DeepSeek 是什么?
英文名代表的 深入(Deep)探索(Seek),DeepSeek-R1 是 DeepSeeK 最新的深度推理模型,对标 OpenAI 的 OpenAI o1
能做什么?
回答问题、撰写文章、写代码(debug)等,进行文案创作、内容生成、翻译、最主要是可以进行复杂问题的推理。
原文链接:DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
http://arxiv.org/pdf/2501.12948
交流学术思想,
加入QQ群:984548465
加入wx群:私聊我,拉进群,免费交流。
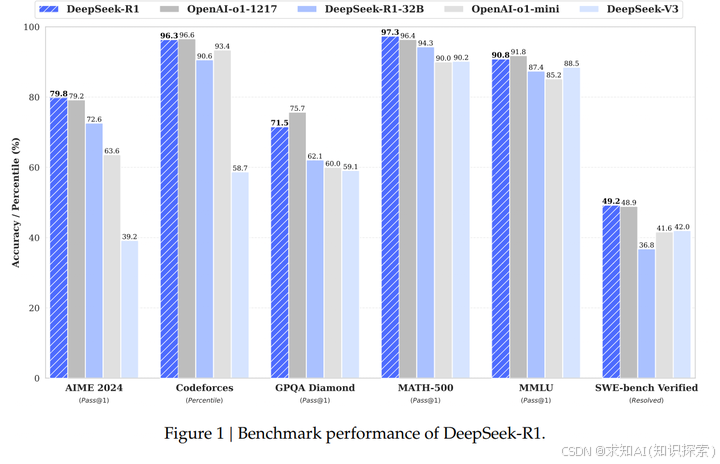
deepseek论文中效果对比
数据集介绍:
| 数据集 | 介绍 |
|---|---|
| AIME | 2024数学竞赛数据集 |
| Codeforces | 数据结构 |
| GPQA Diamond | 考察化学、物理和生物学方面的专业知识 |
| MATH-500 | 数学类问题数据集 |
| MMLU | 57 个不同的领域,其中有 6 个领域与医学知识相关,包括解剖学 (anatomy)、临床知识 (clinical knowledge)、专业医学 (professional medicine)、遗传学 (medical genetics)、大学医学 (college medicine)和大学生物学 (college biology) 。语言模型在多任务上的表现的基准 |
| SWE-bench | 一个评估框架,包括从12个受欢迎的Python仓库中选出的、源自真实GitHub问题和相应拉取请求的2,294个软件工程问题 |
**
解决问题和难点:
**
文中引言说出LLM的推理能力如何通过强化学习(RL)提升,本身无需进行SFT过程,并保持良好的可读性和语言一致性。亮点:提出了 DeepSeek-R1-Zero和DeepSeek-R1两个模型,包含不同尺寸 and six dense models (1.5B, 7B, 8B, 14B, 32B, 70B) 。
探索了大规模RL 在无SFT情况下对推理能力的提升,并引入了冷启动数据以增强模型性能。亮点:首次证明了纯RL可以有效提升LLM 的推理能力,且多阶段训练的策略能够进一步增强性能。
**
方法概述
**
先进行简单的介绍,后续会针对具体每个技术展开介绍。如何有效设计RL算法和奖励机制,提成推理能力而并非依赖监督数据。亮点:提出一种PPO的改进版本GRPO(Group Relative Policy Optimization),使用GRPO算法和基于规则的奖励系统,规则的奖励学习系统,避免了复杂的神经奖励模型。简化了训练流程。从这里能够体现。这是对经典PPO算法的创新改进,不仅增强了模型的数学推理能力,还优化了内存使用效率。
为了解决PPO中的一些弊端,Group Relative Policy Optimization (GRPO)。避免创造额外的价值函数近似,而是使用相同问题下,进行多个采样的输出的平均奖励作为基线。具体讲解会放在其他章节之中。
**
DeepSeek-R1-Zero: 基础模型上的强化学习
**
重点数据:使用GRPO算法,通过组内评分估计基线,优化策略模型
奖励建模
重点数据: 包括准确性奖励和格式奖励,确保输出的正确性和结构化。
训练模板
重点数据: 设计了一个简单的模板,指导模型先生成推理过程再给出最终答案。
**
DeepSeek-R1: 冷启动下的强化学习
**
解决的问题和难点: 如何通过引入少量高质量冷启动数据来加速收敛和提升性能。 亮点: 结合冷启动数据和多阶段训练,提高了模型的可读性和推理性能。
冷启动
重点数据: 收集了数千条长CoT数据,用于冷启动阶段的微调。
推理导向的强化学习
重点数据: 引入了语言一致性奖励,减少了语言混合问题。
拒绝采样和监督微调
重点数据: 生成了约60万条推理相关训练样本,结合其他领域的数据进行微调。
所有场景的强化学习
重点数据: 通过多样化的提示分布和奖励信号,使模型在不同领域表现出色。
蒸馏:赋予小模型推理能力
解决的问题和难点: 如何将大模型的推理能力蒸馏到更小的模型中。 亮点: 直接蒸馏DeepSeek-R1,使得小型模型如Qwen和Llama在推理任务上表现出色。
个人理解:DeepSeek通过改进的GRPO算法提升了PPO的推理能力和内存效率。冷启动利用高质量数据加速收敛,强化学习结合多阶段训练提升性能,多样奖励信号确保跨领域表现出色。蒸馏将大模型推理能力赋予小模型,提高小模型Qwen和Llama的效能。这些方法显著提升模型准确性、可读性和推理性能。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











