







消息队列
- 限流削峰
- 异步解藕
- 数据收集
消息队列的模式
一、点对点模式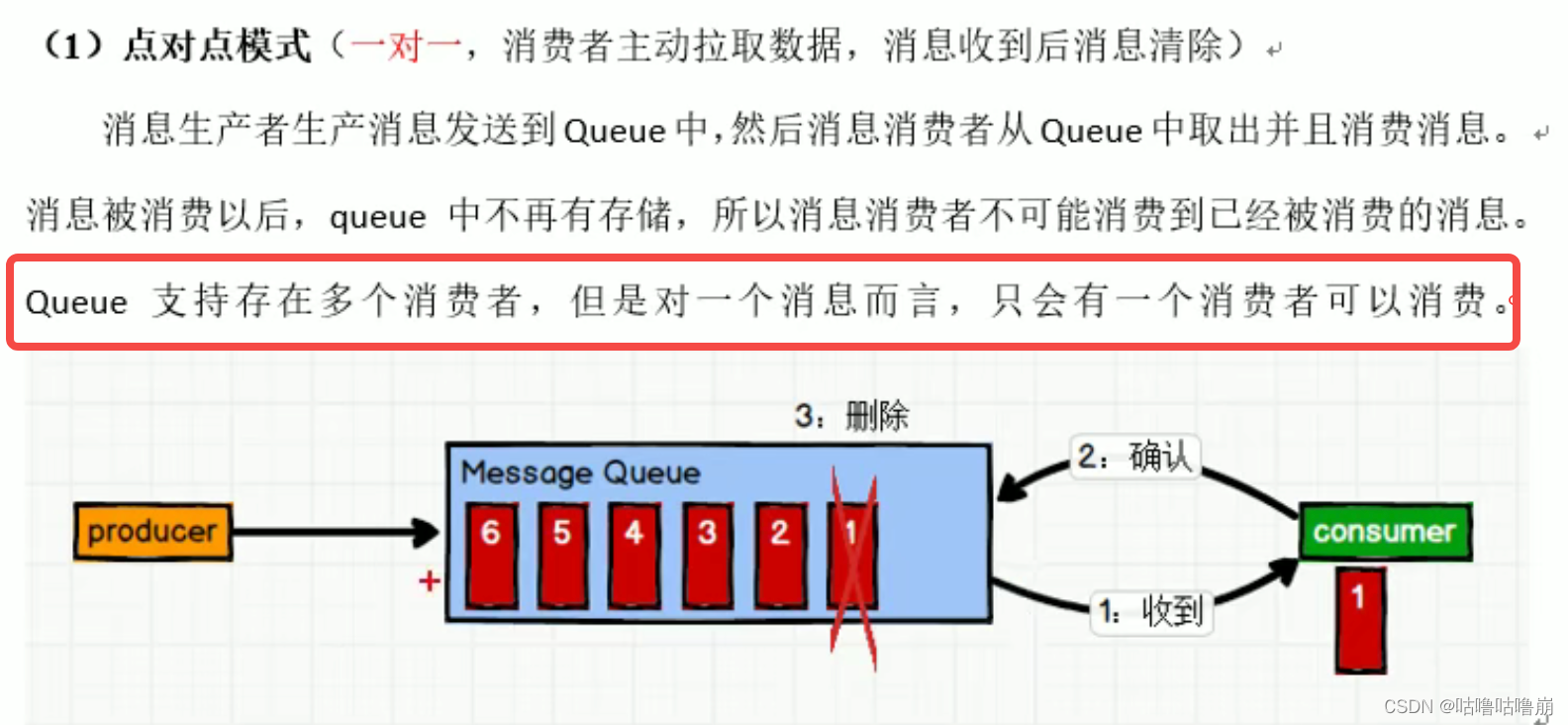
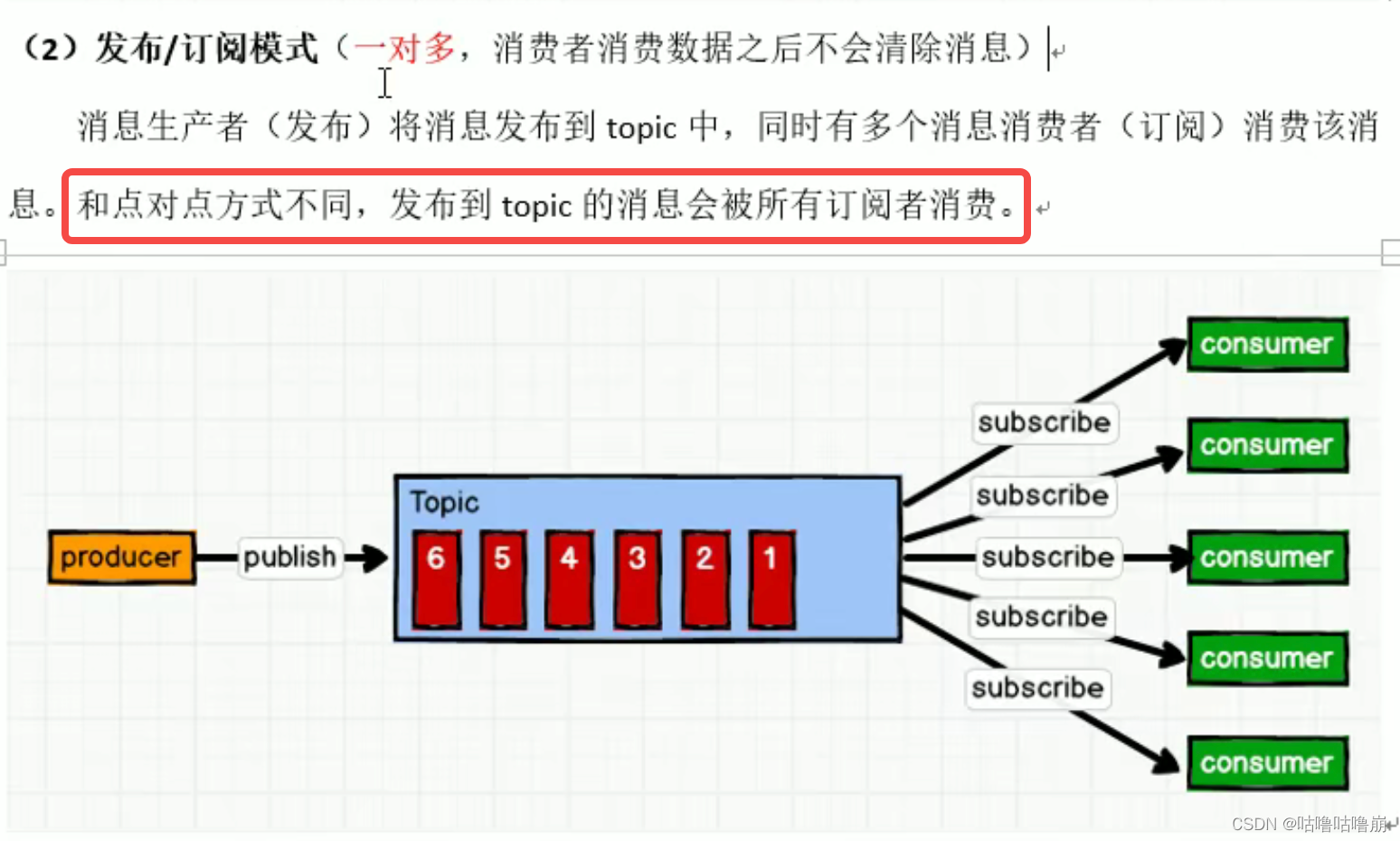
二、发布/订阅模式
发布订阅模式其实分为两种方式:
- 发布:即推送,消息队列主动将消息推送给消费者(缺点:消费者处理不来,导致推送失败)
- 订阅:即拉去,消费者主动去消息队列中拉去数据(缺点:需要消费者不断轮询消息队列)
Kafka
kafka是基于发布订阅者模式的消息队列。【订阅者模式,消费者主动拉去!】
基本架构
- Producer:消息生产者
- Broker:节点,就是存储消息的一台台机器
- Topic:消息分类,同一种消息发送到同一个Topic中
- Partition:将同一个Topic分区进行负载均衡,生产者将消息轮询发不到不同Partition中
- Leader:主Topic
- Follower:从Topic,Leader的副本,Leader挂了Follower上(ISR),所以Leader和Follower不能在同一个机器中!
- Consumer:消息消费者
- Consumer Group:消费组,即相同功能的消费者。同一个消息被消费组中的任意一个消费者消费了就可以
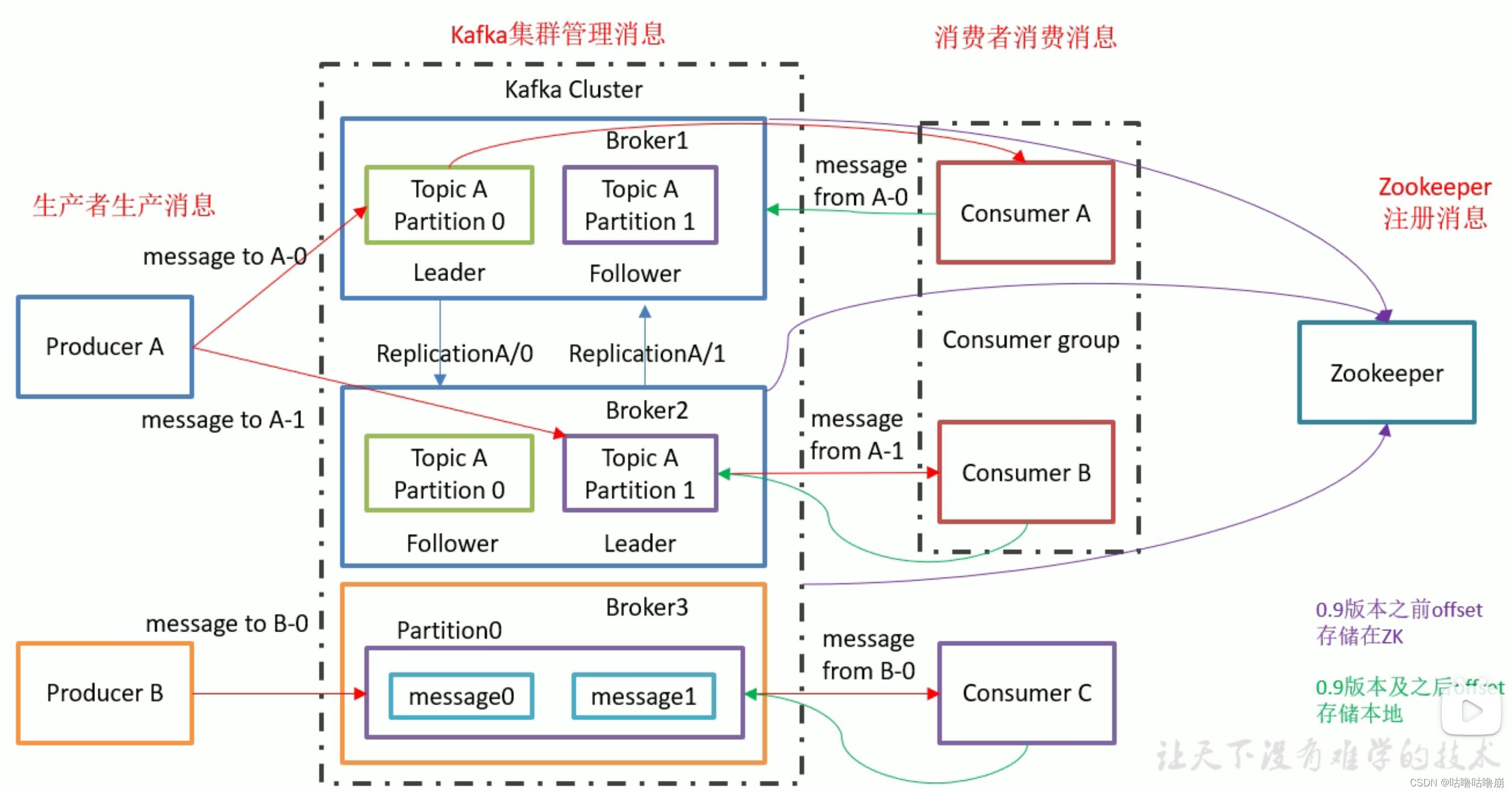
那作为Producer/Consumer具体是怎样发送/消费消息的呢?
- metadata:路由表
metadata信息包括了整个集群的每个topic的所有partition的信息!
- metadata特点
– Kafka的metadata是由zookeeper维护的【2.8.0 版本,Kafka Raft(KRaft)模式【存在一个特殊的Broker(控制器Controller)维护元数据,并同步给其他Broker】,使得它可以在没有 Zookeeper 的情况下运行】(RecoketMQ的分布式实现是由内部的NameServer实现的)
– Broker定时从zookeeper中刷新最新的metadata就可
– 我们给Producer/Consumer客户端配置一个或多个Broker
– 这样Producer/Consumer客户端就可以获取整个集群的metadata信息
– 然后我们给Producer/Consumer客户端配置需要生产/消费的Topic后,kafka客户端就知道将消息发送到哪了/从哪获取!
Raft协议
Raft 协议将节点分为三种角色:领导者(Leader)、跟随者(Follower)和候选人(Candidate)。Raft 协议通过选举机制来保证只有一个领导者存在,并使用日志复制来确保所有节点的状态一致。
- 领导者负责处理客户端的请求,并将日志复制到其他节点。
- 跟随者接收领导者的日志复制,并在领导者故障时转换为候选人,参与领导者选举。
- 候选人则在选举过程中竞争成为领导者。
重新平衡(Rebalance)过程
当Kafka 会通过与 ZooKeeper得知消费者组中的消费者数量发生变化,通过分区分配策略,重新分类分区给消费者。
- Range 范围策略:计算分配,计算每个消费者平均分配个数,为每个消费者分配一定数量分区。
- Round - Robin 轮训策略:轮流为每个消费者分配一个分区,直到所有分区分配完毕。
- Sticky 粘性策略:尽量保持消费者原有的分区分配情况。

















 2167
2167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









