







什么是 Kafka
kafka 最初是 LinkedIn 的一个内部基础设施系统。最初开发的起因是,LinkedIn 虽然有了数据库和其他系统可以用来存储数据,但是缺乏一个可以帮 助处理持续数据流的组件。所以在设计理念上,开发者不想只是开发一个能够存储数据的系统,如关系数据库、Nosql 数据库、搜索引擎等等,更希望把数据看成一个持续变化和不断增长的流,并基于这样的想法构建出一个数据系统,一个数据架构。诶?不是说kafka是一个消息中间件么?怎么照这个说法更像一个数据库呢?我们接着介绍。
Kafka与传统消息系统相比有哪些特点
Kafka 外在表现很像消息系统,允许发布和订阅消息流,但是它和传统的消息系统有很大的差异:
- Kafka 是个现代分布式系统,以集群的方式运行,可以自由伸缩。
- Kafka 可以按照要求存储数据,保存多久都可以,
- 流式处理将数据处理的层次提示到了新高度,消息系统只会传递数据,Kafka 的流式处理能力可以让我们用很少的代码就能动态地处理派生流和数据集(数据不一定需要完全交给消费者进行处理,而是在中间件中就可以提前进行流式处理。此技术在大数据中使用颇为广泛)。
所以 Kafka 不仅仅是个消息中间件,同时它是一个流平台,这个平台上可以发布和订阅数据流(Kafka 的流,有一个单独的包 Stream 的处理),并把他们保存起来,进行处理,这个是 Kafka 作者的设计理念。
Kafka中的一些基本概念
在深入学习kafka之前,我们需要先对Kafka的结构,以及一些专有名词进行了解。
Kafka的结构
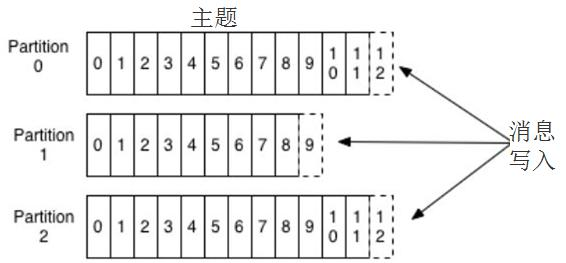
主题和分区 (Partition)
Kafka 里的消息用主题进行分类(主题好比数据库中的表),主题下有可以被分为若干个分区(分表技术)。分区本质上是个提交日志文件,有新消息,这个消息就会以追加的方式写入分区(写文件的形式),然后用先入先出的顺序读取。
但是因为主题会有多个分区,所以在整个主题的范围内,是无法保证消息的顺序的,单个分区则可以保证。
Kafka 通过分区来实现数据冗余和伸缩性,因为分区可以分布在不同的服务器上,那就是说一个主题可以跨越多个服务器(这是 Kafka 高性能的一个原因,多台服务器的磁盘读写性能总值比单台更高)。
对比RabbitMQ的"假"分布式来说,kafka这样的设计结构具备天然分布式的优势,消费的时候可以保证不同的生产者,不同的消费者之间互不打扰的进行消费。
前面我们说 Kafka 可以看成一个流平台,很多时候,我们会把一个主题的数据看成一个流,不管有多少个分区。
消息和批次
消息,Kafka 里的数据单元,也就是我们一般消息中间件里的消息的概念(可以比作数据库中一条记录)。消息由字节数组组成。消息还可以包含键(key)(可选元数据,也是字节数组),主要用于对消息选取分区。
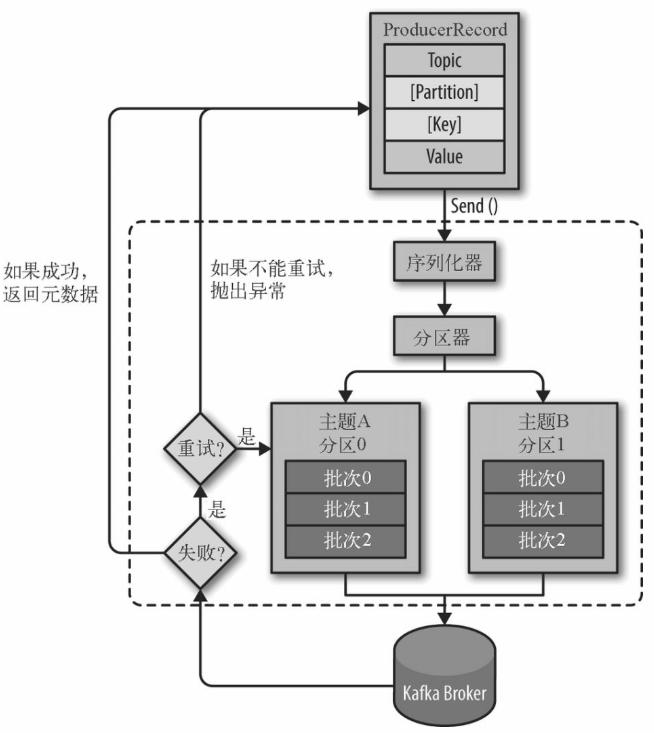
作为一个高效的消息系统,为了提高效率,消息可以被分批写入 Kafka。批次就是一组消息,这些消息属于同一个主题和分区。如果只传递单个消息,会导致大量的网络开销,把消息分成批次传输可以减少这开销。但是,这个需要权衡(时间延迟和吞吐量之间),批次里包含的消息越多,单位时间内处理的消息就越多,单个消息的传输时间就越长(吞吐量高延时也高)。如果进行压缩,可以提升数据的传输和存储能力,但需要更多的计算处理。
对于 Kafka 来说,消息是晦涩难懂的字节数组,一般我们使用序列化和反序列化技术,格式常用的有 JSON 和 XML,还有 Avro(Hadoop 开发的一款序列化框架),具体怎么使用依据自身的业务来定。
批次的弊端(消息重复)
当然,和RabbitMQ一样,批次发送可能会导致数据丢失的风险。原因是发送者将一个批次的消息中的一部分消息发布到Kafka中进行处理,另一部发送失败了。此时如果批次中的某个消息发送失败了,整个批次的消息会全部返回给发送者。
如果消息因为网络原因,或是Kafka中的主节点宕机,从而进行重新选举主节点而导致的消息会在Kafka内部不断地重试。但是重试我们可以设置时长,若是一段时间始终无法重试成功,依旧会导致消息发布失败返回到客户端。此时再次重发消息就会导致消息重复(以为Kafka中已经执行了该批次的部分信息了)。
Kafka的键和RabbitMQ的路由键
RabbitMQ中的路由键可以见过我们的路由器,将消息发送到指定的队列中,然后消费者可以对特定的队列进行绑定消费。
实际上在Kafka中是不存在路由键这个概念的。 Kafka为大数据而生,因此如果不主动设计路由键的话,我们的消息会根据Partition的个数均匀的进行散列。消费者一般也不会去指定特定分区去消费,而是直接订阅主题,随机分配到一个Partition中进行消费。
当然,我们的生产者API也提供了消息指定分区的功能。只不过,指定分区会影响Kafka的运行效率,同时也对生产者的负载均衡有所影响,缺失了原本的动态性。
生产者和消费者、偏移量、消费者群组(消费者负载均衡)
就是一般消息中间件里生产者和消费者的概念。一些其他的高级客户端 API,像数据管道 API 和流式处理的 Kafka Stream,都是使用了最基本的生产者和消费者作为内部组件,然后提供了高级功能。
生产者默认情况下把消息均衡分布到主题的所有分区上,如果需要指定分区,则需要使用消息里的消息键和分区器。
消费者订阅主题,一个或者多个,并且按照消息的生成顺序读取。消费者通过检查所谓的偏移量来区分消息是否读取过。偏移量是一种元数据,一个不断递增的整数值,创建消息的时候,Kafka 会把他加入消息。在一个主题中一个分区里,每个消息的偏移量是唯一的。每个分区最后读取的消息偏移量会保存到Zookeeper 或者 Kafka 上,这样分区的消费者关闭或者重启,读取状态都不会丢失。
多个消费者可以构成一个消费者群组。怎么构成?共同读取一个主题的消费者们,就形成了一个群组。群组可以保证每个分区只被一个消费者使用。
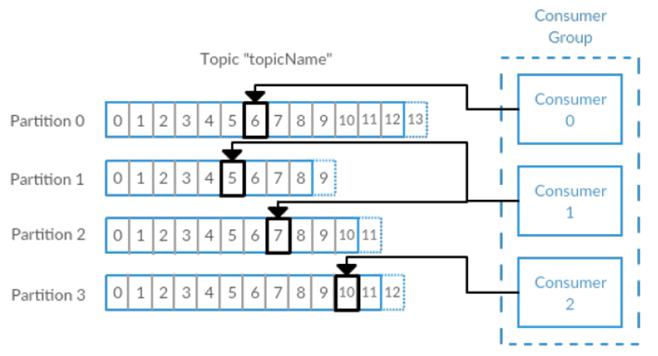
如何理解消费者的负载均衡
再举个例子子:我们现在穿越到古代。假设一个主题中的所有分区被我比喻为中国的女人。而消费者群组被我比喻为中国男人。所有的中国男人会抱团去和女人结婚。如果女人少男多的情况下,有些男人就有了多个妻子(一个消费者可以对应多个partition)。而如果男多女少的情况下,根据我们国家古时候的法律规定,女人只能有一个丈夫。因此当每个女人都配对了一个男人后,主动有一部分男人找不到对象,就注定做单身狗了。然而世事无常,战争频起,许多有了妻子的男人战死沙场后,许多女人(分区)成了寡妇。这时候这些没找到对象的男人就再次有了"转正"的机会,立刻和这些无消费者的分区进行配对,开始继续消费。这个概念被称为群组协调。
再假如,某个消费者不是我们这个组群的,那他就不具备群组协调的功能。也就是哪怕单身的女人(分区)再多,不在组群的消费者也不会去进行消费。
我们发现族群的无用消费者,往往让我们在消费端的可用性得到了巨大的保障。(高可用)
现在再回想我们之前的那个问题,如果不是有非常严格的需求需要我们生产者绑定特定的分区,就尽量不要直接绑定分区,这相当于屏蔽了分区器的工作,严重影响了负载均衡的效果,从而影响可用性。同时也会影响Kafka的吞吐量。是不是更能理解设计者的理念了呢?
Broker 和分区复制
一个独立的 Kafka 服务器叫 Broker。broker 的主要工作是,接收生产者的消息,设置偏移量,提交消息到磁盘保存;为消费者提供服务,响应请求,返回消息。在合适的硬件上,单个 broker 可以处理上千个分区和每秒百万级的消息量。(要达到这个目的需要做操作系统调优和 JVM 调优) 。
多个 broker 可以组成一个集群。每个集群中 broker 会选举出一个集群控制器。控制器会进行管理,包括将分区分配给 broker 和监控 broker。集群里,一个分区从属于一个 broker,这个 broker 被称为首领(后面我就简称主Broker了)。但是分区可以被分配给多个 broker,这个时候会发生分区复制。集群中 Kafka 内部一般使用管道技术进行高效的复制。
分区复制带来的好处是,提供了消息冗余。一旦首领 broker 失效,其他 broker 可以接管领导权。当然相关的消费者和生产者都要重新连接到新的首领上。
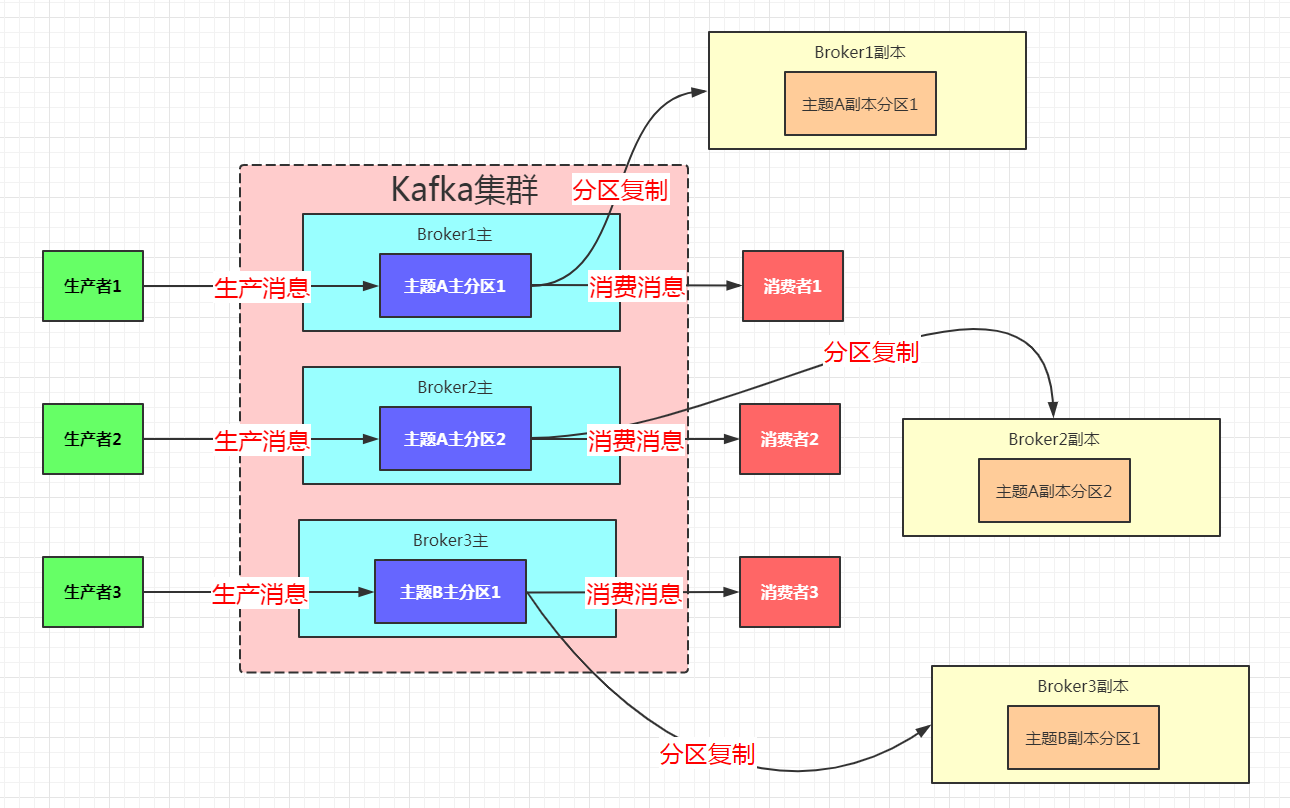
如图,这张图中每一个Broker都是一个服务器。每一个分区都存在一个主服务器,以及其他一个或多个备用服务器。生产者和消费者打交道的都是主分区的节点,而其他副本分区都不进行实际的业务处理。副本分区的工作就是不断地同步主分区的消息。这样,当某个分区的主分区所在的Broker挂了之后,该分区的其他副本
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











