







文章目录
- 一、序列
- 二、列表简介
- 1.定义
- 2.列表定义的格式
- 3.列表的操作
- 4.列表的创建
- 5.列表中切片
- 6.列表相关函数
- (1)len() 检测当前列表的长度,列表中元素的个数
- (2)count() 检测当前列表中指定元素出现的次数
- (3)append() 向列表的尾部追加新的元素,返回值为 None
- (4)insert() 可以向列表中指定的索引位置添加新的元素
- (5)pop() 可以对指定索引位置上的元素做 出栈 操作,返回出栈的元素
- (6)remove() 可以指定列表中的元素 进行 删除,只删除第一个。如果没有找到,则报错
- (7) index() 可以查找指定元素在列表中第一次出现的索引位置
- (8)extend() 接收一个容器类型的数据,把容器中的元素追加到原列表中
- (9)s.clear() # 清空列表内容
- (10)reverse() 列表翻转
- (11)sort() 对列表进行排序
- 7.其他内置函数
- 8. 深拷贝与浅拷贝
- (2)深拷贝
- 6.列表推到式
- 三、元组
一、序列
1.定义
序列是一种数据存储方式,用来存储一系列的数据。在内存中,序列就是一块用来存放 多个值的连续的内存空间。
2.存储方式
在内存中实际是按照如下方式存储的: a = [10,20,30,40]
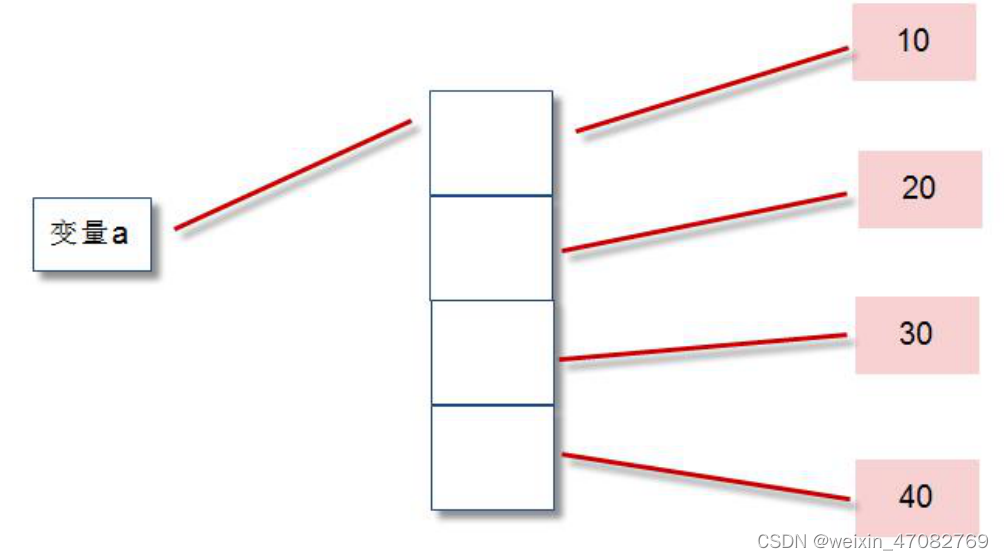
出序列中存储的是整数对象的地址,而不是整数对象的值。
python 中常用的序列结构有: 字符串、列表、元组、字典、集合
二、列表简介
1.定义
列表就是一组有序的数据组合,列表中的数据可以被修改
用于存储任意数目、任意类型的数据集合。
列表是内置可变序列,是包含多个元素的有序连续的内存空间。
2.列表定义的格式
(1)列表定义的标准语法格式:
a = [10,20,30,40] 其中,10,20,30,40 这些称为:列表 a 的元素。
(2)注意
3.列表的操作
- 列表定义-[],list()
- 列表相加-拼接
- 列表相乘-重复
- 列表的下标- 获取,更新
- 列表元素的添加-append()
- 列表元素的删除
- del 列表[下标]
- pop()函数 删除元素
增加、删除、访问、计数、列表长度、翻转列表、排序、浅拷贝
列表中的元素可以各不相同,可以是任意类型。比如: a = [10,20,‘abc’,True]
| 方法 | 要点 | 描述 |
|---|---|---|
| list.append(x) | 增加元素 | 将元素 x 增加到列表 list 尾部 |
| list.extend(aList) | 增加元素 | 将列表 alist 所有元素加到列表 list 尾部 |
| list.insert(index,x) | 增加元素 | 在列表 list 指定位置 index 处插入元素 x |
| list.remove(x) 删除元素 在列表 list 中删除首次出现的指定元素 x | ||
| list.pop([index]) | 删除元素 | 删除并返回列表 list 指定为止 index 处的元素,默认是 最后一个元素 |
| list.clear() | 删除所有元素 | 删除列表所有元素,并不是删除列表对象 |
| list.index(x) | 访问元素 返回第一个 x 的索引位置,若不存在 x 元素抛出异常 | |
| list.count(x) | 计数 | 返回指定元素 x 在列表 list 中出现的次数 len(list) 列表长度 返回列表中包含元素的个数 |
| list.reverse() | 翻转列表 | 所有元素原地翻转 |
| list.sort() | 排序 | 所有元素原地排序 |
| list.copy() | 浅拷贝 | 返回列表对象的浅拷贝 |
4.列表的创建
- 可以使用 中括号进行定义 []
- 也可以使用 list函数 定义
- 在定义列表中的元素时,需要在每个元素之间使用逗号,进行分隔。[1,2,3,4]
- 列表中的元素可以是任意类型的,通常用于存放同类项目的集合
(1)基本语法[]创建
>>> a = [10,20,'gaoqi','sxt']
>>>> a = [] #创建一个空的列表对象
(2)list()创建
使用 list()可以将任何可迭代的数据转化成列表。
>>> a = list() #创建一个空的列表对象
> >>> a = list(range(10)) >>> a [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> a = list("gaoqi,sxt")
>> a ['g', 'a', 'o', 'q', 'i', ',', 's', 'x', 't']
>
5.列表中切片
典型操作(三个量为正数的情况)如下:
| 操作和说明 | 示例 | 结果 |
|---|---|---|
| [:] | 提取整个列表 | [10,20,30][:] |
| [start:]从 start 索引开始到结尾 | [10,20,30][1:] | [20,30] |
| [:end]从头开始知道 end-1 | [10,20,30][:2] | [10,20] |
| [start:end]从 start 到 end-1 | [10,20,30,40][1:3] | [20,30] |
| [start🔚step] 从 start 提 取到 end-1,步长是 step | [10,20,30,40,50,60,70][1:6: 2] | [20, 40, 60] |
其他操作(三个量为负数)的情况:
| 示例 | 说明 | 结果 |
|---|---|---|
| [10,20,30,40,50,60,70][-3:] | 倒数三个 | [50,60,70] |
| 10,20,30,40,50,60,70][-5:-3] | 倒数第五个到倒数 第三个(包头不包尾) | [30,40] |
| [10,20,30,40,50,60,70][::-1] | 步长为负,从右到左 反向提取 | [70, 60, 50, 40, 30, 20, 10] |
语法==> 列表[开始索引:结束索引:步进值]
1。 列表[开始索引:] ==> 从开始索引到列表的最后
2。 列表[:结束值] ==> 从开始到指定的结束索引之前
3。 列表[开始索引:结束索引] ==> 从开始索引到指定结束索引之前
4。 列表[开始索引:结束索引:步进值] ==> 从指定索引开始到指定索引前结束,按照指定步进进行取值切片
5。 列表[:] 或 列表[::] ==> 所有列表元素的切片
6。 列表[::-1] ==> 倒着获取列表的元素
示例:
varlist = ['刘德华','张学友','张国荣','黎明','郭富城','小沈阳','刘能','宋小宝','赵四']
# 从开始索引到列表的最后
res = varlist[2:] # ['张国荣','黎明','郭富城','小沈阳','刘能','宋小宝','赵四']
# 从开始到指定的结束索引之前
res = varlist[:2] # ['刘德华','张学友']
# 从开始索引到指定结束索引之前
res = varlist[2:6] # ['张国荣', '黎明', '郭富城', '小沈阳']
# 从指定索引开始到指定索引前结束,按照指定步进进行取值切片
res = varlist[2:6:2] # ['张国荣', '郭富城']
# 所有列表元素的切片
res = varlist[:]
res = varlist[::]
# 倒着输出列表的元素
res = varlist[::-1]
# 使用切片方法 对列表数据进行更新和删除
print(varlist)
# 从指定下标开始,到指定下标前结束,并替换为对应的数据(容器类型数据,会拆分成每个元素进行赋值)
# varlist[2:6] = ['a','b','c',1,2,3]
# varlist[2:6:2] = ['a','b'] # 需要与要更新的元素个数对应
# 切片删除
# del varlist[2:6]
del varlist[2:6:2]
6.列表相关函数
varlist = ['刘德华','张学友','张国荣','张学友','黎明','郭富城','小沈阳','刘能','宋小宝','赵四']
(1)len() 检测当前列表的长度,列表中元素的个数
res = len(varlist)
(2)count() 检测当前列表中指定元素出现的次数
(3)append() 向列表的尾部追加新的元素,返回值为 None
varlist.append('川哥')
(4)insert() 可以向列表中指定的索引位置添加新的元素
varlist.insert(20,'aa')
(5)pop() 可以对指定索引位置上的元素做 出栈 操作,返回出栈的元素
res = varlist.pop() # 默认会把列表中的最后一个元素 出栈
res = varlist.pop(2) # 会在列表中把指定索引的元素进行 出栈
(6)remove() 可以指定列表中的元素 进行 删除,只删除第一个。如果没有找到,则报错
varlist = [1,2,3,4,11,22,33,44,1,2,3,4]
res = varlist.remove(1)
(7) index() 可以查找指定元素在列表中第一次出现的索引位置
varlist = [1,2,3,4,11,22,33,44,1,2,3,4]
res = varlist.index(1)
res = varlist.index(1,5,20) # 可以在指定索引范围内查找元素的索引位置
(8)extend() 接收一个容器类型的数据,把容器中的元素追加到原列表中
varlist.extend('123')
(9)s.clear() # 清空列表内容
varlist.clear()
(10)reverse() 列表翻转
varlist.reverse()
(11)sort() 对列表进行排序
res = varlist.sort() # 默认对元素进行从小到大的排序
res = varlist.sort(reverse=True) # 对元素进行从大到小的排序
res = varlist.sort(key=abs) # 可以传递一个函数,按照函数的处理结果进行排序
7.其他内置函数
(1)max 和 min 用于返回列表中最大和最小值。
[40, 30, 20, 10]
>>> a = [3,10,20,15,9]
>>> max(a)
20
>>> min(a)
3
(2)sum 对数值型列表的所有元素进行求和操作,
对非数值型列表运算则会报错。
>>> a = [3,10,20,15,9]
>>> sum(a)
57
8. 深拷贝与浅拷贝
(1)浅拷贝
浅拷贝只能拷贝列表中的一维元素,如果列表中存在二维元素或容器,则引用而不是拷贝
使用cpoy函数或者copy模块中的copy函数拷贝的都是浅拷贝
** 浅拷贝 只能拷贝当前列表,不能拷贝列表中的多维列表元素**
varlist = [1,2,3]
①简单的拷贝 就可以把列表复制一份
newlist = varlist.copy()
②对新拷贝的列表进行操作,也是独立的
del newlist[1]
# print(varlist,id(varlist))
# print(newlist,id(newlist))
'''
[1, 2, 3] 4332224992
[1, 3] 4332227552
'''
③多维列表
varlist = [1,2,3,['a','b','c']]
④使用copy函数 拷贝一个多维列表
newlist = varlist.copy()
'''
print(newlist,id(newlist))
print(varlist,id(varlist))
[1, 2, 3, ['a', 'b', 'c']] 4361085408
[1, 2, 3, ['a', 'b', 'c']] 4361898496
'''
== 如果是一个被拷贝的列表,对它的多维列表元素进行操作时,会导致原列表中的多维列表也发生了变化==
del newlist[3][1]
'''
通过id检测,发现列表中的多维列表是同一个元素(对象)
print(newlist[3],id(newlist[3]))
print(varlist[3],id(varlist[3]))
['a', 'c'] 4325397360
['a', 'c'] 4325397360
'''
(2)深拷贝
深拷贝就是不光拷贝了当前的列表,同时把列表中的多维元素或容器也拷贝了一份,而不是引用
使用copy模块中的 deepcopy 函数可以完成深拷贝
深拷贝 就是不光拷贝了当前的列表,同时把列表中的多维元素也拷贝了一份
import copy
varlist = [1,2,3,['a','b','c']]
# 使用 copy模块中 深拷贝方法 deepcopy
newlist = copy.deepcopy(varlist)
del newlist[3][1]
print(varlist)
print(newlist)
'''
print(newlist[3],id(newlist[3]))
print(varlist[3],id(varlist[3]))
['a', 'c'] 4483351248
['a', 'b', 'c'] 4483003568
'''
6.列表推到式
List-Comprehensions
列表推导式提供了一个更简单的创建列表的方法。
常见的用法是把某种操作应用于序列或可迭代对象的每个元素上,然后使用其结果来创建列表,或者通过满足某些特定条件元素来创建子序列。
采用一种表达式的当时,对数据进行过滤或处理,并且把结果组成一个新的列表
(1)基本的列表推到式使用方式
结果变量 = [变量或变量的处理结果 for 变量 in 容器类型数据]
示例:
假设我们想创建一个平方列表
①使用普通方法完成
varlist = []
for i in range(10):
varlist.append(i**2)
# print(varlist) # [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
②使用 map函数和list完成
varlist = list(map(lambda x: x**2, range(10)))
# print(varlist) # [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
③使用列表推到式完成
下面这个列表推到式和第一种方式是一样的
varlist = [i**2 for i in range(10)]
# print(varlist) # [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
# 2。 '1234' ==> [2,4,6,8]
# 常规方法完成需求
varstr = '1234'
newlist = []
for i in varstr:
newlist.append(int(i)*2)
# print(newlist) # [2, 4, 6, 8]
# 使用列表推到式完成上面的需求
newlist = [int(i)*2 for i in varstr]
# print(newlist) # [2, 4, 6, 8]
# 使用列表推到式+位运算完成
newlist = [int(i) << 1 for i in varstr]
# print(newlist) # [2, 4, 6, 8]
(2)带有判断条件的列表推到式
结果变量 = [变量或变量的处理结果 for i in 容器类型数据 条件表达式]
示例:
# 0-9 求所有的偶数,==> [0, 2, 4, 6, 8]
# 常规方法完成
newlist = []
for i in range(10):
if i % 2 == 0:
newlist.append(i)
# print(newlist) # [0, 2, 4, 6, 8]
# 列表推到式完成
newlist = [i for i in range(10) if i % 2 == 0]
# print(newlist) # [0, 2, 4, 6, 8]
3.对于嵌套循环的列表推到式
'''
# 下面这个 3x4的矩阵,它由3个长度为4的列表组成,交换其行和列
[
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
]
==>
[
[1, 5, 9],
[2, 6, 10],
[3, 7, 11],
[4, 8, 12]
]
'''
arr = [
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
]
# 常规方法完成
# newlist = []
# for i in range(4):
# res = []
# for row in arr:
# res.append(row[i])
# newlist.append(res)
# print(newlist)
# 使用列表推到式完成
newlist = [[row[i] for row in arr] for i in range(4)]
print(newlist)
三、元组
- 索引访问
- 切片操作
- 连接操作
- 成员关系操作
- 比较运算操作
- 计数:元组长度 len()、最大值 max()、最小值 min()、求和 sum()等。
元组和列表一样都是一组有序的数据的组合。
元组中的元素一但定义不可以修改,因此元组称为 不可变数据类型
1.元组定义
- 定义空元组 变量 = (),或者 变量=tuple()
- 还可以使用 变量 = (1,2,3) 定义含有数据的元组
- 注意:如果元组中只有一个元素时,必须加逗号 变量=(1,)
- 特例:变量=1,2,3 这种方式也可以定义为一个元组
2.元组的创建
由于元组是不可变的数据类型,因次只能使用索引进行访问,不能进行其它操作
元组可以和列表一样使用切片方式获取元素
(1)通过()创建元组。小括号可以省略。
a = (10,20,30)
#或者
a = 10,20,30
如果元组只有一个元素,则必须后面加逗号。这是因为解释器会把(1)解释为整数 1,(1,) 解释为元组。
>>> a = (1)
>>> type(a)
<class 'int'> >>> a = (1,) #或者 a = 1,
>>> type(a)
<class 'tuple'>
(2)通过 tuple()创建元组 tuple(可迭代的对象)
例如:
b = tuple() #创建一个空元组对象
b = tuple("abc")
b = tuple(range(3))
b = tuple([2,3,4])
总结:tuple()可以接收列表、字符串、其他序列类型、迭代器等生成元组。 list()可以接收元组、字符串、其他序列类型、迭代器等生成列表。
4.元组的切片操作
元组的切片操作 和列表是一样的
vart = (1,2,3,4,5,5,4,3,2,1)
res = vart[:] # 获取全部
res = vart[::] # 获取全部
res = vart[1:] # 从索引1开始获取到最后
res = vart[1:3] # 从索引1开始到索引3之前
res = vart[:3] # 从索引 0 开始 到 索引 3之前
res = vart[1:5:2] # 从索引1开始到索引5之前,步进值为2
res = vart[::2] # 从索引 0 开始 到 最后 ,步进值为2
res = vart[5:1:-1] # 从索引5开始 到索引 1,步进值为-1 倒着输出
5.zip
zip(列表 1,列表 2,…)将多个列表对应位置的元素组合成为元组,并返回这个 zip 对象。
>>> a = [10,20,30]
>>> b = [40,50,60]
>>> c = [70,80,90]
>>> d = zip(a,b,c)
>>> list(d)
[(10, 40, 70), (20, 50, 80), (30, 60, 90)]
6.元组推导式 生成器
列表推导式结果返回了一个列表,元组推导式返回的是生成器
语法:
列表推导式 ==> [变量运算 for i in 容器] ==> 结果 是一个 列表
元组推导式 ==> (变量运算 for i in 容器) ==> 结果 是一个 生成器
(1)生成器是什么?
生成器是一个特殊的迭代器,生成器可以自定义,也可以使用元组推导式去定义
生成器是按照某种算法去推算下一个数据或结果,只需要往内存中存储一个生成器,节约内存消耗,提升性能
(2)语法:
-
里面是推导式,外面是一个() 的结果就是一个生成器
-
自定义生成器,含有yield关键字的函数就是生成器
含有yield关键字的函数,返回的结果是一个迭代器,换句话说,生成器函数就是一个返回迭代器的函数
(3)如何使用操作生成器?
生成器是迭代器的一种,因此可以使用迭代器的操作方法来操作生成器
示例代码:
①列表推导式
varlist = [1,2,3,4,5,6,7,8,9]
# newlist = [i**2 for i in varlist]
# print(newlist) # [1, 4, 9, 16, 25, 36, 49, 64, 81]
②元组推导式 生成器 generator
newt = (i**2 for i in varlist)
print(newt) # <generator object <genexpr> at 0x1104cd4d0>
③使用next函数去调用
# print(next(newt))
# print(next(newt))
④使用list或tuple函数进行操作
# print(list(newt))
# print(tuple(newt))
⑤使用 for 进行遍历
# for i in newt:
# print(i)
元组总结
- 元组的核心特点是:不可变序列。
- 元组的访问和处理速度比列表快。
- 与整数和字符串一样,元组可以作为字典的键,列表则永远不能作为字典的键使用。

















 2156
2156

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









