






%pylab inline
是matplotlib的代码,但只有jupyter notbook,要用到
plt未定义,用import matplotlib.pyplot as plt#定义plt
import pandas as pd
train_df = pd.read_csv('F:/NLP/train_set.csv', sep='\t', nrows=100)
train_df.head()#显示前五行
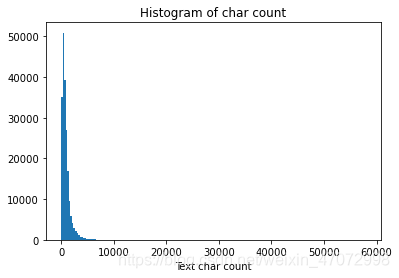
#句子长度分析
train_df['text_len'] = train_df['text'].apply(lambda x: len(x.split(' ')))
print(train_df['text_len'].describe())
import matplotlib.pyplot as plt#定义plt
#给句子长度绘制直方图
_ = plt.hist(train_df['text_len'], bins=200)
plt.xlabel('Text char count')
plt.title("Histogram of char count")
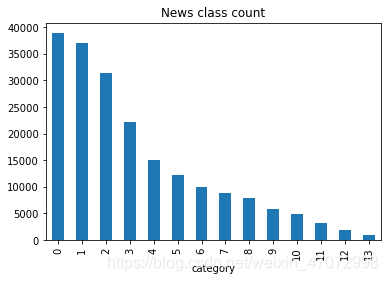
#新闻类别分布
train_df['label'].value_counts().plot(kind='bar')
plt.title('News class count')
plt.xlabel("category")
#字符分布统计
from collections import Counter
all_lines = ' '.join(list(train_df['text']))
word_count = Counter(all_lines.split(" "))
word_count = sorted(word_count.items(), key=lambda d:d[1], reverse = True)
print(len(word_count))
# 6869
print(word_count[0])
# ('3750', 7482224)
print(word_count[-1])
# ('3133', 1)
train_df['text_unique'] = train_df['text'].apply(lambda x: ' '.join(list(set(x.split(' ')))))
all_lines = ' '.join(list(train_df['text_unique']))
word_count = Counter(all_lines.split(" "))
word_count = sorted(word_count.items(), key=lambda d:int(d[1]), reverse = True)
print(word_count[0])
# ('3750', 197997)
print(word_count[1])
# ('900', 197653)
print(word_count[2])
# ('648', 191975)
作业:
#每类新闻中出现的字符,统计每类新闻中出现次数最多的字符
import numpy as np
temp = sample[['label','text_stop']]
temp_1 = temp.groupby(['label'])['text_stop'].apply(lambda x:np.concatenate(list(x))).reset_index()
freq = [ ]
for i in range(0,len(temp_1)):
word_count = Counter(temp_1['text_stop'][i])
word_count = sorted(word_count.items(), key=lambda d:d[1], reverse = True)
freq.append(word_count[i])
freq
#每篇新闻平均多少句子构成
stop = ['3750','900','648']
sample['text_stop'] = sample['text'].apply(lambda x: [i for i in x.split(' ') if i not in stop])
sample['text_len'] = sample['text'].apply(lambda x: len(x.split(' '))) # 原始文本长度
sample['text_len_stop'] = sample['text_stop'].apply(lambda x: len(x)) # 去除标点后文本长度
print("原始文本长度统计")
print(sample['text_len'].describe())
print('\n')
print('去除标点后的文本长度统计')
print(sample['text_len_stop'].describe())
作业部分参考sosososoon
前面代码参考datawhale

















 1786
1786

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









