







一、select
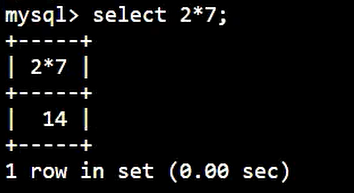
查询2*7的值:
SELECT
2 * 7;
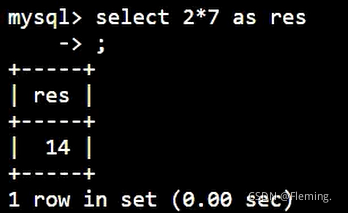
查询2*7的值并用res进行命名:
SELECT
2 * 7 AS res;
二、from
CREATE TABLE t1(
id INT,
name VARCHAR(20)
);
CREATE TABLE t2(
score1 INT(20),
score2 INT(20)
);
INSERT INTO t1 VALUES ( 1, 'frank' )( 2, 'jerry' );
INSERT INTO t2 VALUES ( 98, 98 )( 933, 91 );
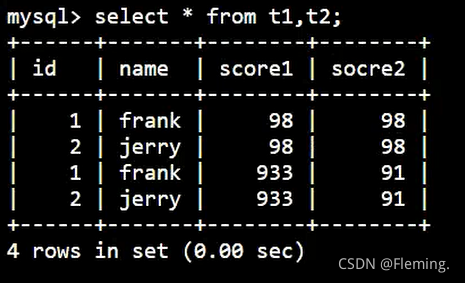
笛卡儿积:
SELECT * FROM t1,t2;
三、dual
dual是一个默认的伪表
SELECT
2 * 7 AS res;
SELECT
2 * 7 AS res
FROM
DUAL;
SELECT
2 * 7
FROM
DUAL;
四 、where
查出年龄大于30岁的教师:
SELECT
*
FROM
teacher
WHERE
age > 30;
查出家庭地址在shanghai或者beijing的数据:
SELECT
*
FROM
teacher
WHERE
address = 'shanghai'
OR address = 'beijing';
五、in
用in查询地址在shanghai和beijing的数据:
SELECT
*
FROM
teacher
WHERE
address IN ( 'shanghai','beijing'
);
用not in查询地址不在shanghai和beijing的数据:
SELECT
*
FROM
teacher
WHERE
address NOT IN ( 'shanghai','beijing'
);
六、between and
创建一个表:
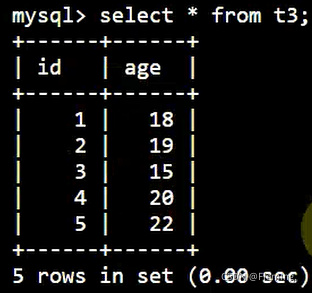
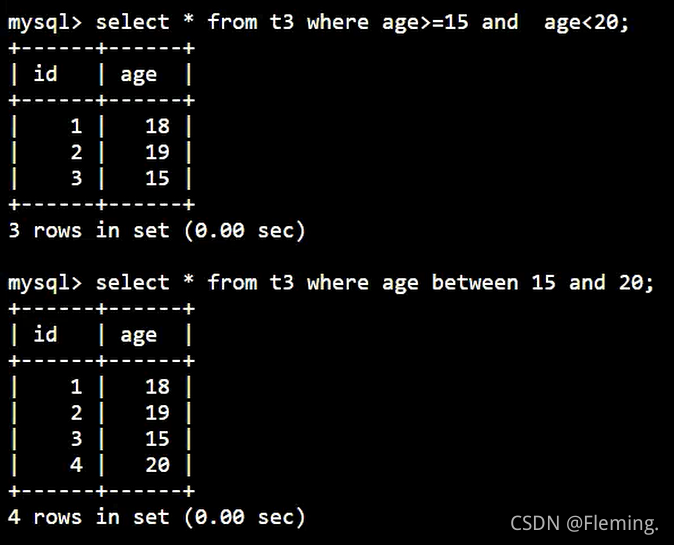
查询年龄在15到20岁之间的数据:
SELECT
*
FROM
t3
WHERE
age > 15
AND age < 20;
利用between and的另一种查询方式:
SELECT
*
FROM
t3
WHERE
age BETWEEN 15
AND 20;
两条语句查询的结果分别是:
由此可知 between and 包含临界值(=)
七、is null
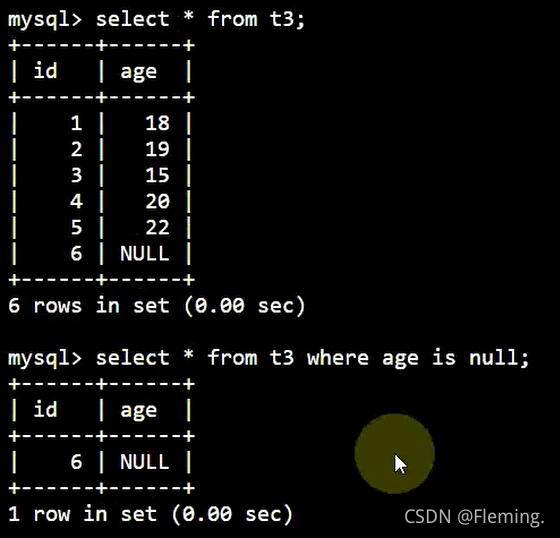
插入一条age字段为空的数据:
INSERT INTO t3
VALUES
( 6, NULL );
查询age字段为空的一整条数据:
SELECT
*
FROM
t3
WHERE
age IS NULL;
查询字段非空的数据:
SELECT
*
FROM
t3
WHERE
age IS NOT NULL;
八、聚合函数
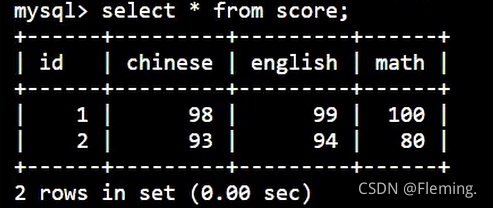
创建一个分数表:
CREATE TABLE score(
id INT,
chinese INT,
english INT,
math INT
);
插入一些数据:
INSERT INTO score VALUES(1,98,99,100),(2,93,94,80);
查看数据:
SELECT * FROM score;
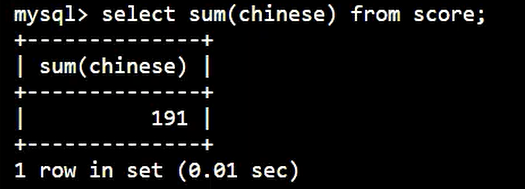
利用 SUM 查询求和:
SELECT
SUM( chinese )
FROM
score;
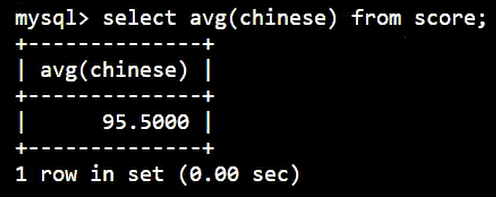
利用 AVG 查询平均值:
SELECT
AVG( chinese )
FROM
score;
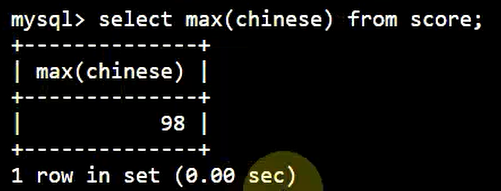
利用 MAX 查询最大值:
SELECT
MAX( chinese )
FROM
score;
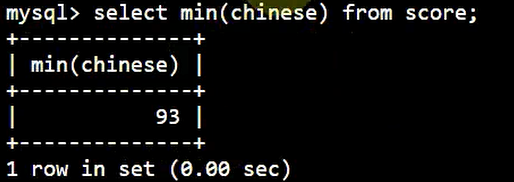
利用 MIN 查询最小值:
SELECT
MIN( chinese )
FROM
score;
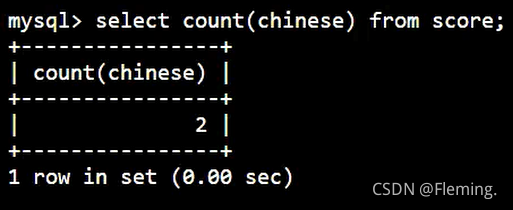
利用 COUNT 查询数量:
SELECT
COUNT( chinese )
FROM
score;
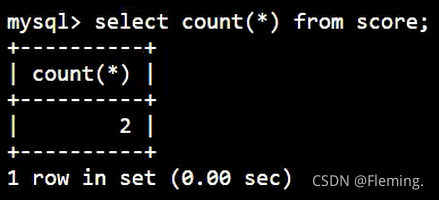
利用 COUNT(*) 查询数据总条数:
SELECT
COUNT(*)
FROM
score;
九、客户端的使用
安装配置 Navicat 客户端
十、like模糊查询
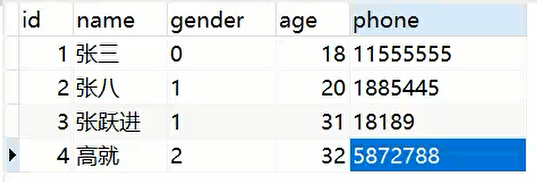
创建如图所示的表:
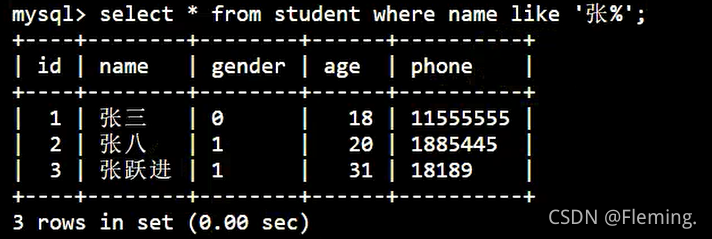
查询匹配多个字符的数据:
SELECT
*
FROM
student
WHERE
NAME LIKE '张%'
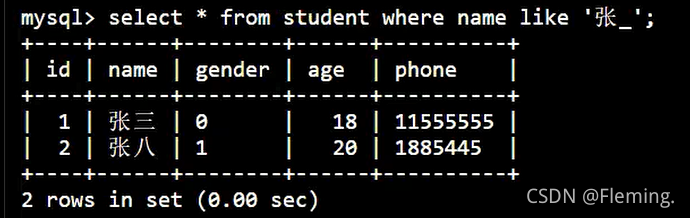
查询匹配一个字符的数据:
SELECT
*
FROM
student
WHERE
NAME LIKE '张_'
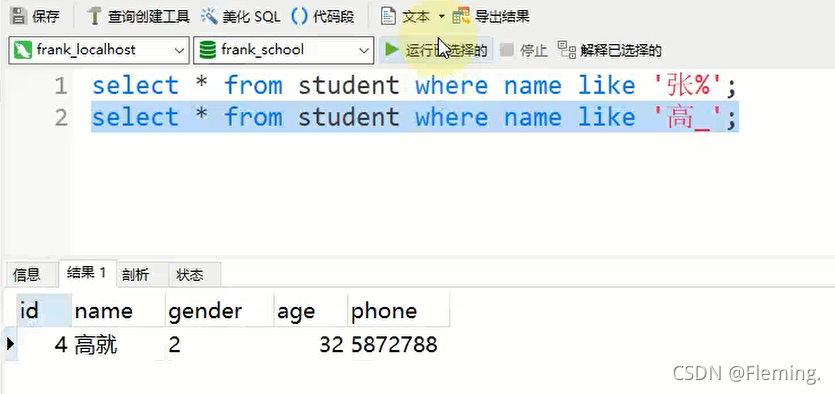
使用客户端进行查询,效果展示:
十一、order by排序查询
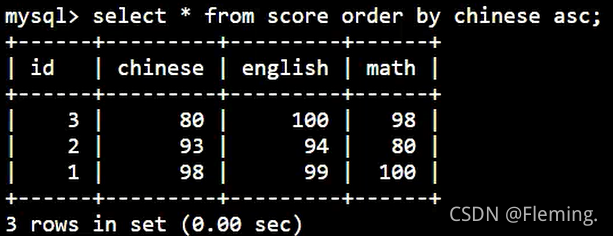
按照升序 (ASC) 进行排序:
SELECT
*
FROM
score
ORDER BY
chinese ASC;
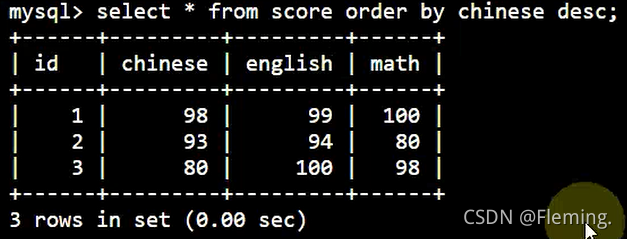
按照降序 (DESC) 进行排序:
SELECT
*
FROM
score
ORDER BY
chinese DESC;
十二、group by分组查询
创建一个叫做 info 的表,并插入数据:

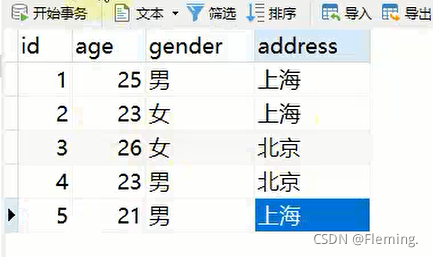
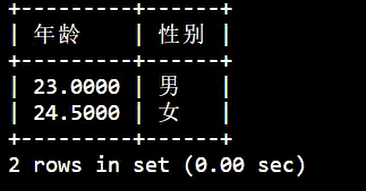
查询表中男性和女性的平均年龄:
SELECT
AVG( age ) AS '年龄',
gender AS '性别'
FROM
info
GROUP BY
gender;
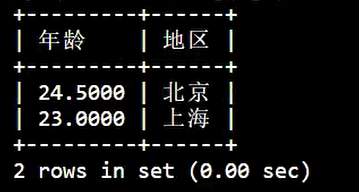
查询表中上海和北京的平均年龄:
SELECT
AVG( age ) AS '年龄',
address AS '地区'
FROM
info
GROUP BY
address;
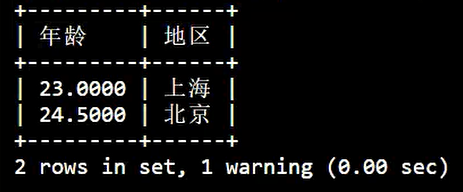
group by查询的字段必须是分组字段与聚合函数
同样可以多语句进行组合查询,
例如:按照平均年龄升序查询显示表中上海的平均年龄和北京的平均年龄:
SELECT
AVG( age ) AS '年龄',
address AS '地区'
FROM
info
GROUP BY
address DESC;
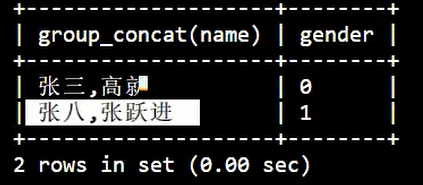
十三、group_concat
聚合显示:
SELECT
GROUP_CONCAT( NAME ),
gender
FROM
student
GROUP BY
gender;
十四、having
where是从表中一条一条的遍历筛选
having是对查询后的结果表进行再次筛选
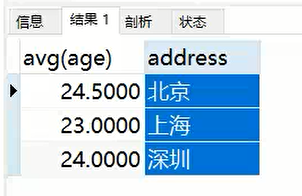
1.查询显示表中上海的平均年龄和北京的平均年龄:
SELECT
AVG( age ) AS 'age',
address AS 'address'
FROM
info
GROUP BY
address;
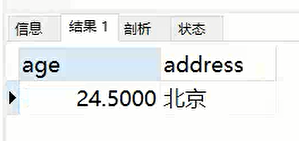
2.如果我们想对已经查询到的表中的数据进行再次筛选查询,可以引入having:
SELECT
AVG( age ) AS 'age',
address AS 'address'
FROM
info
GROUP BY
address
HAVING
age > 24;
十五、limit
limit后跟的数字(%,%),逗号前面的是起始点,后面的是长度(跨度)。
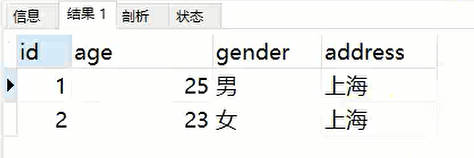
查询数据表中起始位置为1,跨度为2的数据:
SELECT
*
FROM
info
LIMIT 0,2;
查询数据表中起始位置为2,跨度为3的数据:
SELECT
*
FROM
info
LIMIT 1,3;

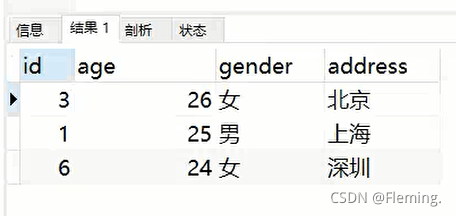
年龄按从大到小排序,查询年龄最大的三条数据:
SELECT
*
FROM
info
ORDER BY
age
LIMIT 3;
十六、distinct all
distinct 代表字段去重
原表数据为:
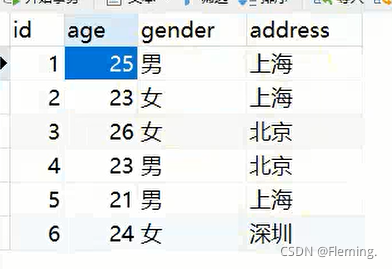
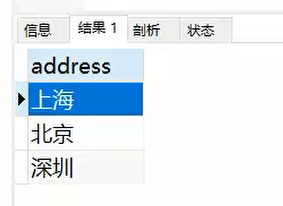
去重查询:
SELECT DISTINCT address
FROM
info;
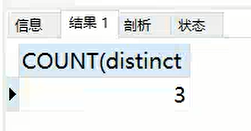
去重聚合查询:
SELECT
COUNT( DISTINCT address )
FROM
info;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









