







 本文探讨了Dropout技术如何通过随机失活神经元来防止模型过拟合,通过生物进化的比喻解释其作用,并展示了如何在代码中应用Dropout进行模型训练。实验结果表明,Dropout有效地保持了模型在训练集和测试集上的性能一致性。
本文探讨了Dropout技术如何通过随机失活神经元来防止模型过拟合,通过生物进化的比喻解释其作用,并展示了如何在代码中应用Dropout进行模型训练。实验结果表明,Dropout有效地保持了模型在训练集和测试集上的性能一致性。
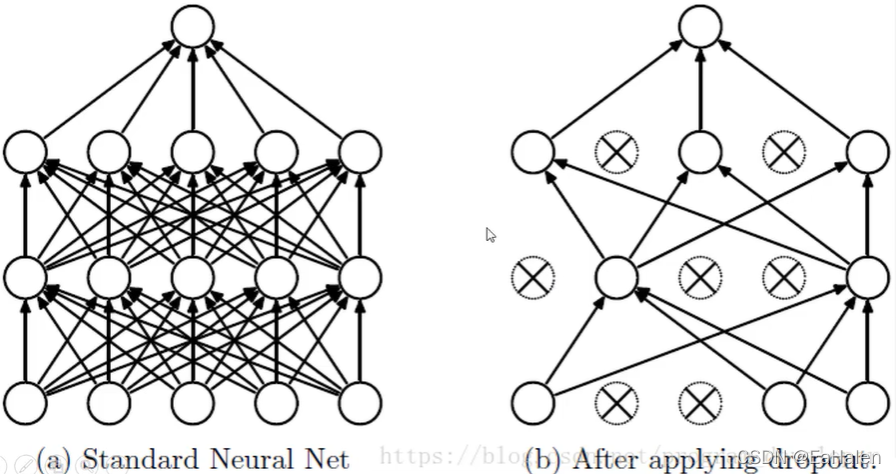
1)为什么说DropOut可以抑制过拟合?
(1)取平均的作用:
先回到标准的模型即没有dropout,我们用相同的训练数据去训练5个不同的神经网络,一般会得到5个不同的结果,此时我们可以采用“5个结果取均值”或者“多数取胜的投票策略”去决定最终结果。
(2)减少神经元之间复杂的共适应关系
因为dropout程序导致两个神经元不一定每次都在一个dropout网络中出现。这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况。
(3) Dropout类似于性别在生物进化中的角色
物种为了生存往往会倾向于适应这种环境,环境突变则会导致物种难以做出及时反应,性别的出现可以繁衍出适应新环境的变种,有效的阻止过拟合,即避免环境改变时物种可能面临的灭绝
2)在上一节代码基础上做优化
import keras
from keras import layers
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data = pd.read_csv('./dataset/credit-a.csv', header=None)
x = data.iloc[:, :-1].values
y = data.iloc[:,-1].replace(-1,0).values.reshape(-1, 1)
x_train = x[:int(len(x) * 0.75)]
x_test = x[int(len(x) * 0.75):]
y_train = y[:int(len(y) * 0.75)]
y_test = y[int(len(y) * 0.75):]
x_train.shape, x_test.shape, y_train.shape, y_test.shape
model = keras.Sequential()
model.add(layers.Dense(128, input_shape=(None, 15), activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['acc']
)
history = model.fit(x_train, y_train, epochs=1000,
validation_data=(x_test,y_test))
model.evaluate(x_train, y_train)
model.evaluate(x_test, y_test) # loss | acc 比较差 --- 过拟合的表现
plt.plot(history.epoch, history.history.get('val_acc'), c='r',label='val_acc')
plt.plot(history.epoch, history.history.get('acc'), c='b', label='acc')
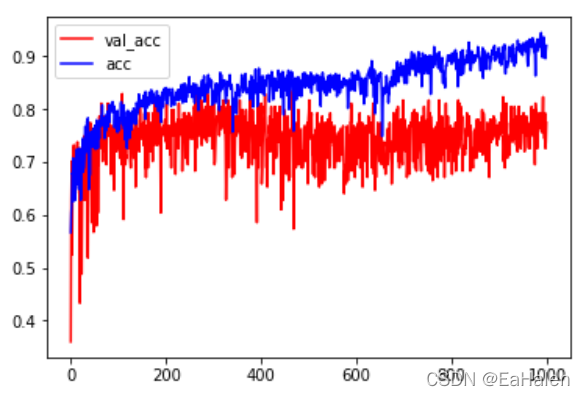
plt.legend()代码结果分析:

如上图所示,那是训练模型后最后的结果,发现,训练集上和测试集上是十分的接近的
说明:
基于JupyterNoteBook(Annaconda3)搭建的tensorflow开发环境。
所使用到的数据集见我的博客上传的资源中,欢迎大家下载。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









