









Hbase简介
HBase 是一个构建在 Hadoop 文件系统之上的面向列的数据库管理系统。
Hbase 的表具有以下特点:
容量大:一个表可以有数十亿行,上百万列;
面向列:数据是按照列存储,每一列都单独存放,数据即索引,在查询时可以只访问指定列的数据,有效地降低了
系统的 I/O 负担;
稀疏性:空 (null) 列并不占用存储空间,表可以设计的非常稀疏 ;
数据多版本:每个单元中的数据可以有多个版本,按照时间戳排序,新的数据在最上面;
存储类型:所有数据的底层存储格式都是字节数组 (byte[])。
hbase中的数据怎么实现修改
hbase中的数据存储在hdfs中,而hdfs中的数据是不支持修改的,那hbase中的修改数据、delete等操作是怎么实现的呢?

如上图,客户端进行删除操作时,会往hdfs中的hfile文件中追加数据,数据中会记录用户的操作delete,为墓碑标记(标记着数据要删除),在下次获取该数据时,会发现有两个该数据,其中一条有墓碑标记,则不会返回客户端数据。
之后会将原来的数据和用户删除后生成的记录合并生成一个新的hfile文件。和hdfs不支持数据修改的是不相违背的,hbase实现修改是向文件后进行追加,再进行合并完成修改。
合并时机:
1、有大量的更新数据操作
2、有大量的小文件(列族太多,内存小)
3、TTL(有过期数据)
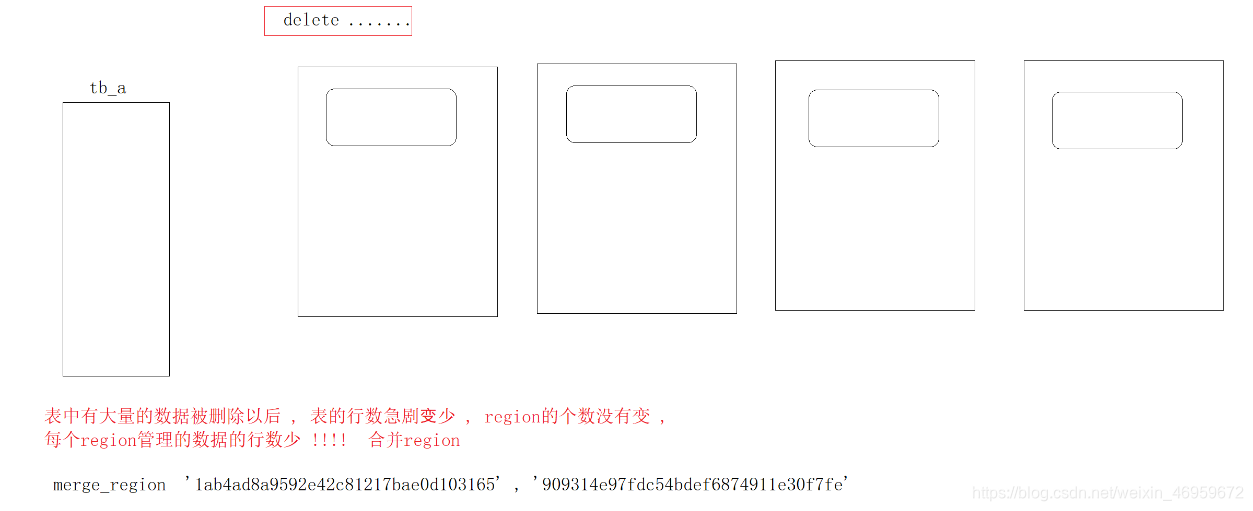
大合并和小合并
大合并是合并region,region在HDFS中对应一个文件夹,region的合并会涉及整个文件夹下的大量Hfile文件的合并,非常耗费资源;小合并是合并Hfile文件,将一个文件夹下的多个Hfile文件合并为一个Hfile文件
合并region操作 (shell)
merge_region ‘region_name’,‘region_name’
拆分
随着数据的增加,一个region管理的数据会越来越多,如果出现大量的查询此region数据的请求,那么这个region所在的RegionServer会出现并发热点问题,则需要拆分region。
缺点:拆分后要解决热点问题,实现负载均衡,就需要将拆分后的region移动到其他RegionServer上,拆分后的region会在Hdfs生成新的文件夹,其中会有很多的hfile文件,移动region和hdfs交互,会占用大量的IO资源。

















 707
707

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









