







1、linux系统(ubuntu)下运行C程序
1、touch XX.c生成源文件。
2、vim打开并编写代码。
3、gcc XX.c编译源文件,然后就可以看见a.out的文件。
(这个花了最多时间,安装build-essential包绕了很多弯路)
4、在a.out文件的目录下打开终端并输入./a.out运行。
5、如果想要编译完的文件名不要用a.out文件,在编译时输入gcc XX.c -o XX.out就可以看见一个XX.out文件了。-o后面跟着编译生成的文件名。
2、进程控制
fork():
使用时需包含头文件 <sys/types.h> 和 <unistd.h>。
函数原型: pid_t fork(void);
功能: 以父进程为模版创建子进程,它从父进程处继承了整个进程的地址空间:包括代码,数据段,进程上下文、进程堆栈、打开的文件描述符等。
返回值: 需要注意的是fork()函数被调用一次,却会返回两次。两次返回的区别是,子进程的返回值的是0,而父进程返回的是子进程的ID。若调用出错则返回-1。
看下面一个程序:
void fork1()
{
int x = 1;
pid_t pid = fork();
if (pid == 0) {
printf("Child has x = %d\n", ++x);
}
else {
printf("Parent has x = %d\n", --x);
}
printf("Bye from process %d with x = %d\n", getpid(), x);
}
当在Linux系统上运行该代码,我们会得到如下结果:
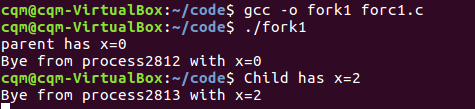
执行到fork()函数后,就创建了一个子进程,然后根据父进程和子进程返回值的不同,执行相应代码段。系统把原来的进程的所有代码,数据都复制到新进程中,所以子进程和父进程都会继续执行fork()调用之后的代码,一共打印了4次。(其中getpid()函数是返回调用进程的ID)
wait():
使用时需包含头文件<sys/types.h>和<sys/wait.h>
函数原型: int wait(int *status);
功能: 子进程退出,父进程如果不用wait()函数等待已终止的子进程,就可能造成“僵尸进程”(子进程无父进程的状态),进而造成内存泄露。父进程通过进程等待的方式,回收子进程资源,获取子进程退出信息。
参数: status用来保存子进程退出时的一些状态,它是一个指向int类型的指针。但如果我们对这个子进程是如何结束的毫不在意,只想把这个进程消灭掉,我们就可以设定这个参数为NULL。
返回值: 等待成功:返回子进程pid;等待失败:返回-1。
wait()要与fork()配套出现,如果在使用fork()之前调用wait(),wait()的返回值则为-1,正常情况下wait()的返回值为子进程的pid。
waitpid():
头文件同上。
函数原型: pid_t waitpid(pid_t pid,int *status,int options)
参数:
pid: pid=-1,等待任意一个子进程,与wait等效;pid=0,等待进程id与目前进程相同的任何子进程;pid>0,等待进程id与pid相等的子进程。
status: 同上。
options: 提供一些额外的选项来控制waitpid,如果不想使用这些选项,则可以把这个参数设为0。
主要使用的有以下两个选项:
| 参数 | 说明 |
|---|---|
| WNOHANG | 如果pid指定的子进程没有结束,则waitpid()函数立即返回0,而不是阻塞在这个函数上等待;如果结束了,则返回该子进程的进程号。 |
| WUNTRACED | 如果子进程进入暂停状态,则马上返回。 |
exec():
exec是一个函数簇,由6个函数组成,分别是以excl和execv打头的。
execl(const char* filepath,const char* arg1,char*arg2…)
execlp(const charfilename,const chararg1,const char*arg2… )
execle(const charfilepath,const chararg1,const chararg2,…,char cons envp[])
execv (const char* filepath,char* argv[])
execvp (const char* filename,char* argv[])
execve (const char* filepath,charargv[],char const envp[])
一个进程一旦调用exec类函数,它本身就"死亡"了,系统把代码段替换成新的程序的代码,废弃原有的数据段和堆栈段,并为新程序分配新的数据段与堆栈段,唯一留下的,就是进程id,也就是说,对系统而言,还是同一个进程,不过已经是另一个程序了。
exit():
终止一个进程。传入的参数是程序退出时的状态码,0表示正常退出,其他表示非正常退出,一般用-1或者1。
实验内容:
(1)编写一段程序,使用系统调用fork()来创建两个子进程,并由父进程重复显示某字符串和自己的标识数,而子进程则重复显示某字符串和自己的标识数。
程序如下:
#include<stdio.h>
#include<stdlib.h>
#include<sys/types.h>
#include<sys/wait.h>
#include<unistd.h>
int main()
{
if(fork()==0)
printf("child1 ID1:%d\n",getpid());
else
{
wait(NULL);
printf("parent ID:%d\n",getpid());
if(fork()==0)
printf("child2 ID2:%d\n",getpid());
else
{
wait(NULL);
printf("parent ID:%d\n",getpid());
}
}
return 0;
}
(2)编写一段程序,使用系统调用fork()来创建一个子进程。子进程通过系统调用exec()更换自己的执行代码,显示新的代码后,调用exit()结束。而父进程则调用waitpid()等待子进程结束,并在子进程结束后显示子进程的标识符,然后正常结束。
程序如下:
#include<stdio.h>
#include<stdlib.h>
#include<sys/types.h>
#include<sys/wait.h>
#include<unistd.h>
int main()
{
if(fork()==0)
{
execl("/bin/ls","ls",NULL);
exit(0);
}
else
{
printf("parent=%d\n",getpid());
printf("child=%d\n",waitpid(-1,NULL,0));
}
return 0;
}
3、进程间的通信
pipe():
创建管道。
函数原型: int pipe(int file_descriptor[2])
返回值:成功返回0,并通过值file_descriptor[2]传出两个文件描述符号。
file_descriptor[0] : 通过此文件描述符从管道读出数据
file_descriptor[1] : 通过此文件描述符向管道写数据
注:若关闭pipe的写入一端,则对于读取进程,read不会阻塞于等待数据,而是直接返回0
write()&read():
都位于<unistd.h>中。
函数原型:
ssize_t write(int fd,voidbuf,size_t count)
ssize_t read(int fd,voidbuf,size_t count)
write()参数说明:
fd: 是文件描述符,对应1
buf: 需要写入的数据,通常为字符串
count: 每次写入的字节数
read()参数说明:
fd: 是文件描述符,对应0
buf: 为读出数据的缓冲区
count: 为每次读取的字节数
实验内容:
编写一段程序,使用管道来实现父子进程之间的进程通信。子进程向父进程发送自己的进程标识符,以及某字符串。父进程则通过管道读出子进程发来的消息,将消息显示在屏幕上,然后终止。或者,编写一段程序,使其用消息缓冲队列来实现client和server进程之间的通信。
程序如下:
#include<stdio.h>
#include<unistd.h>
#include<string.h>
#include<stdlib.h>
#include<sys/types.h>
#include<sys/wait.h>
char msg[100];
int main()
{
int fd[2], pid;
if (pipe(fd) == 0)
{
pid = fork();
if (pid == 0)
{
sprintf(msg, "child_pid=%d\n", getpid());
write(fd[1], msg, strlen(msg));
sprintf(msg, "INTERPROCESS COMMUNICATION");
write(fd[1], msg, strlen(msg));
}
else if (pid > 0)
{
read(fd[0], msg, sizeof(msg)); puts(msg);
read(fd[0], msg, sizeof(msg)); puts(msg);
wait(NULL);
}
else { puts("Fork Error."); exit(1); }
return 0;
}
else exit(1);
}
4、使用动态优先权的进程调度算法模拟
动态优先级算法:
指在进程创建时先确定一个初始优先数, 以后在进程运行中随着进程特性的改变不断修改优先数,这样,由于开始优先数很低而得不到CPU的进程,就能因为等待时间的增长而优先数变为最高而得到CPU运行。
例如:在进程获得一次CPU后就将其优先数减少1(不一定是1),或者进程等待的时间超过某一时限时增加其优先数的值。
实验内容:
1.对N个进程采用动态优先权算法的进程调度。
2.每个用来标识进程的进程控制块PCB用结构来描述,包括以下字段:
- 进程标识数 ID。
- 进程优先数 priority,并规定优先数越大的进程,其优先权越高。
- 进程已占用的CPU时间cputime。
- 进程还需占用的CPU时间alltime。当进程运行完毕时,alltime变为0。
- 进程的阻塞时间startblock,表示当进程再运行startblock个时间片后,将进入阻塞状态。
- 进程被阻塞的时间blocktime,表示已足赛的进程再等待blocktime个时间片后,将转换成就绪状态。
- 进程状态stare。
- 队列指针next,用来将PCB排成队列。
3.优先数改变的原则:进程在就绪队列中呆一个时间片,优先数增加1,进程每运行一个时间片优先数减3。
4.设置调度前的初始状态。
5.将每个时间片内的进程情况显示出来。
程序如下:
priority= -1: 已执行完的进程或者已被阻塞的进程优先级设置为-1
temp[i]: 储存已阻塞的进程i的优先级
process[i].startblock= n : 表示进程再执行n个时间片开始阻塞;-1表示不会阻塞
#include <iostream>
#include<algorithm> //使用库中 max_element(first,last)函数,函数返回值为数组最大元素的地址
using namespace std;
enum State{ready,block,done}; //枚举变量 0-ready 1-block 2-done
struct Process //进程结构体定义
{
int ID;
int priority;
int cputime;
int alltime;
int startblock;
int blocktime;
State state;
};
Process process[5]=
{
{0,9,0,3,2,3,ready},
{1,38,0,3,-1,0,ready},
{2,30,0,6,-1,0,ready},
{3,29,0,3,-1,0,ready},
{4,0,0,4,-1,0,ready}
}; //初始化5个进程
void print()
{
cout<<"就绪队列:";
for(int j=0; j<5; j++)
{
if(process[j].state==ready)
cout<<"->"<<process[j].ID;
}
cout<<endl;
cout<<"阻塞队列:";
for(int j=0; j<5; j++)
{
if(process[j].state==block)
cout<<"->"<<process[j].ID;
}
cout<<endl;
cout<<"ID\tpriority\tcputime\talltime\tstartblock\tblocktime\tstate"<<endl;
for(int j=0; j<5; j++)
{
cout<<process[j].ID<<'\t'<<process[j].priority<<'\t'<<'\t'<<process[j].cputime<<'\t'<<process[j].alltime
<<'\t'<<process[j].startblock<<'\t'<<'\t'<<process[j].blocktime<<'\t'<<'\t'<<process[j].state<<endl;
}
cout<<"******************************************************************************"<<endl;
}
int main()
{
int timeslice=0; //时间片
int temp[5]; // 阻塞进程优先级 缓存数组
while(process[0].alltime||process[1].alltime||process[2].alltime||process[3].alltime||process[4].alltime) //存在进程没有执行完成
{
for(int i=0; i<5; i++)
{
int array[]= {process[0].priority,process[1].priority,process[2].priority,process[3].priority,process[4].priority}; //所有进程优先级 存储数组
if((process[i].state==ready) && (process[i].priority==*max_element(array,array+5))) //进程i开始执行
{
timeslice++;
process[i].priority-=3;
process[i].cputime+=1;
process[i].alltime-=1;
for(int j=0; j<5; j++) //其余就绪进程优先级加1
{
if(j==i) continue; //跳过当前进程的优先级+1操作
if(process[j].alltime>0&&process[j].state==ready)
process[j].priority+=1;
}
if(process[i].alltime==0)
{
process[i].state=done;
process[i].priority=-1;
}
for(int j=0; j<5; j++) //其他阻塞进程 blocktime -1
{
if(process[j].state==block&&process[j].blocktime>0)
{
process[j].blocktime-=1;
if(process[j].blocktime==0)
{
process[j].state=ready;
process[j].priority=temp[j]; //阻塞进程恢复阻塞前的优先级
}
}
}
if(process[i].startblock>0)
{
process[i].startblock-=1;
if(process[i].startblock==0)
{
process[i].state=block;
temp[i]=process[i].priority; //进程i阻塞后 将优先级保存到 temp[i]
process[i].priority=-1;
}
}
cout<<"时间片为:"<<timeslice<<endl;
cout<<"执行进程:"<<process[i].ID<<endl;
print();
}
}
}
return 0;
}
5、动态分区分配方式
最先适应算法:
将空闲区按其在存储空间中的起始地址递增的顺序排列。为作业分配存储空间时,从空闲区链的始端开始查找,选择第一个满足要求的空闲区,而不管它究竟有多大。
最佳适应算法:
空闲分区按从小到大进行排序,自表头开始查找到第一个满足要求的自由分区分配。这样找到的空闲分区是满足作业要求且大小最小的,这种方法能使碎片尽量小。
最坏适应算法:
将所有的空闲分区按其容量从大到小顺序形成一空闲分区链,查找时只要看第一个分区能否满足作业要求。
实验内容:
1、用C或其他语言分别实现采用首次适应算法、最佳适应算法和最坏适应算法的动态分区分配过程和回收过程。
2、设置初始状态,每次分配和回收后显示出空闲内存分区链的情况。
源程序如下:
#include<iostream>
#include<stdlib.h>
using namespace std;
#define Free 0 //空闲状态
#define Busy 1 //已用状态
#define OK 1 //完成
#define ERROR 0 //出错
#define MAX_length 640 //定义最大主存信息640KB
typedef int Status;
int flag;//标志位 0为空闲区 1为已分配的工作区
typedef struct FreAarea//定义一个空闲区说明表结构
{
long size; //分区大小
long address; //分区地址
int state; //状态
}ElemType;
typedef struct DuLNode// 线性表的双向链表存储结构
{
ElemType data;
struct DuLNode *prior; //前趋指针
struct DuLNode *next; //后继指针
}
DuLNode, *DuLinkList;
DuLinkList block_first; //头结点
DuLinkList block_last; //尾结点
Status Alloc(int);//内存分配
Status free(int); //内存回收
Status First_fit(int);//首次适应算法
Status Best_fit(int); //最佳适应算法
Status Worst_fit(int); //最差适应算法
void show();//查看分配
Status Initblock();//开创空间表
Status Initblock()//开创带头结点的内存空间链表
{
block_first = (DuLinkList)malloc(sizeof(DuLNode));
block_last = (DuLinkList)malloc(sizeof(DuLNode));
block_first->prior = NULL;
block_first->next = block_last;
block_last->prior = block_first;
block_last->next = NULL;
block_last->data.address = 0;
block_last->data.size = MAX_length;
block_last->data.state = Free;
return OK;
}
Status Alloc(int ch)//分配主存
{
int request = 0;
cout << "请输入需要分配的主存大小(单位:KB):"<<endl;
cin >> request;
if (request<0 || request == 0)
{
cout << "分配大小不合适,请重试!" << endl;
return ERROR;
}
if (ch == 2) //选择最佳适应算法
{
if (Best_fit(request) == OK) cout << "分配成功!" << endl;
else cout << "内存不足,分配失败!" << endl;
return OK;
}
if (ch == 3) //选择最差适应算法
{
if (Worst_fit(request) == OK) cout << "分配成功!" << endl;
else cout << "内存不足,分配失败!" << endl;
return OK;
}
else //默认首次适应算法
{
if (First_fit(request) == OK) cout << "分配成功!" << endl;
else cout << "内存不足,分配失败!" << endl;
return OK;
}
}
Status First_fit(int request)//首次适应算法
{
//为申请作业开辟新空间且初始化
DuLinkList temp = (DuLinkList)malloc(sizeof(DuLNode));
temp->data.size = request;
temp->data.state = Busy;
DuLNode *p = block_first->next;
while (p)
{
if (p->data.state == Free && p->data.size == request)
{//有大小恰好合适的空闲块
p->data.state = Busy;
return OK;
break;
}
if (p->data.state == Free && p->data.size>request)
{//有空闲块能满足需求且有剩余
temp->prior = p->prior;
temp->next = p;
temp->data.address = p->data.address;
p->prior->next = temp;
p->prior = temp;
p->data.address = temp->data.address + temp->data.size;
p->data.size -= request;
return OK;
break;
}
p = p->next;
}
return ERROR;
}
Status Best_fit(int request)//最佳适应算法
{
int ch; //记录最小剩余空间
DuLinkList temp = (DuLinkList)malloc(sizeof(DuLNode));
temp->data.size = request;
temp->data.state = Busy;
DuLNode *p = block_first->next;
DuLNode *q = NULL; //记录最佳插入位置
while (p) //初始化最小空间和最佳位置
{
if (p->data.state == Free && (p->data.size >= request))
{
if (q == NULL)
{
q = p;
ch = p->data.size - request;
}
else if (q->data.size > p->data.size)
{
q = p;
ch = p->data.size - request;
}
}
p = p->next;
}
if (q == NULL) return ERROR;//没有找到空闲块
else if (q->data.size == request)
{
q->data.state = Busy;
return OK;
}
else
{
temp->prior = q->prior;
temp->next = q;
temp->data.address = q->data.address;
q->prior->next = temp;
q->prior = temp;
q->data.address += request;
q->data.size = ch;
return OK;
}
return OK;
}
Status Worst_fit(int request)//最坏适应算法
{
int ch; //记录最大剩余空间
DuLinkList temp = (DuLinkList)malloc(sizeof(DuLNode));
temp->data.size = request;
temp->data.state = Busy;
DuLNode *p = block_first->next;
DuLNode *q = NULL; //记录最佳插入位置
while (p) //初始化最大空间和最佳位置
{
if (p->data.state == Free && (p->data.size >= request))
{
if (q == NULL)
{
q = p;
ch = p->data.size - request;
}
else if (q->data.size < p->data.size)
{
q = p;
ch = p->data.size - request;
}
}
p = p->next;
}
if (q == NULL) return ERROR;//没有找到空闲块
else if (q->data.size == request)
{
q->data.state = Busy;
return OK;
}
else
{
temp->prior = q->prior;
temp->next = q;
temp->data.address = q->data.address;
q->prior->next = temp;
q->prior = temp;
q->data.address += request;
q->data.size = ch;
return OK;
}
return OK;
}
Status free(int flag)//主存回收
{
DuLNode *p = block_first;
for (int i = 0; i <= flag; i++)
if (p != NULL)
p = p->next;
else
return ERROR;
p->data.state = Free;
if (p->prior != block_first && p->prior->data.state == Free)//与前面的空闲块相连
{
p->prior->data.size += p->data.size;//空间扩充,合并为一个
p->prior->next = p->next;//去掉原来被合并的p
p->next->prior = p->prior;
p = p->prior;
}
if (p->next != block_last && p->next->data.state == Free)//与后面的空闲块相连
{
p->data.size += p->next->data.size;//空间扩充,合并为一个
p->next->next->prior = p;
p->next = p->next->next;
}
if (p->next == block_last && p->next->data.state == Free)//与最后的空闲块相连
{
p->data.size += p->next->data.size;
p->next = NULL;
}
return OK;
}
void show()//显示主存分配情况
{
int flag = 0;
cout << "\n主存分配情况:\n";
cout << "++++++++++++++++++++++++++++++++++++++++++++++\n\n";
DuLNode *p = block_first->next;
cout << "分区号\t起始地址\t分区大小\t状态\n\n";
while (p)
{
cout << " " << flag++ << "\t";
cout << " " << p->data.address << "\t\t";
cout << " " << p->data.size << "KB\t\t";
if (p->data.state == Free) cout << "空闲\n\n";
else cout << "已分配\n\n";
p = p->next;
}
cout << "++++++++++++++++++++++++++++++++++++++++++++++\n\n";
}
void main()//主函数
{
int ch;//算法选择标记
cout << "请输入所使用的内存分配算法:\n";
cout << "(1)首次适应算法\n(2)最佳适应算法\n(3)最坏适应算法\n";
cin >> ch;
while (ch<1 || ch>3)
{
cout << "输入错误,请重新输入所使用的内存分配算法:\n";
cin >> ch;
}
Initblock(); //开创空间表
int choice; //操作选择标记
while (1)
{
show();
cout << "请输入您的操作:";
cout << "\n1: 分配内存\n2: 回收内存\n0: 退出\n";
cin >> choice;
if (choice == 1) Alloc(ch); // 分配内存
else if (choice == 2) // 内存回收
{
int flag;
cout << "请输入您要释放的分区号:"<<endl;
cin >> flag;
free(flag);
}
else if (choice == 0) break; //退出
else //输入操作有误
{
cout << "输入有误,请重试!" << endl;
continue;
}
}
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









