



zookeeper学习
Paxos算法
Paxos,它是一个基于消息传递的一致性算法,Leslie Lamport在1990年提出,近几年被广泛应用于分布式计算中,Google的Chubby,Apache的Zookeeper都是基于它的理论来实现的。Paxos还被认为是到目前为止比较有效的分布式一致性算法,其它的算法都是Paxos的改进或简化(只关注数据的一致性,不关注数据的正确性)。
Paxos描述了这样一个场景,有一个叫做Paxos的小岛(Island)上面住了一批居民,岛上面所有的事情由一些特殊的人决定,他们叫做议员(Senator)。
议员的总数(Senator Count)是确定的,不能更改。岛上每次环境事务的变更都需要通过一个提议(Proposal),每个提议都有一个编号(PID)。这个编号是一直增长的,不能倒退。每个提议都需要超过半数((Senator Count)/2 +1)的议员同意才能生效。
提议怎么通过呢?
每个议员只会同意大于当前编号的提议,包括已生效的和未生效的。如果议员收到小于等于当前编号的提议,他会拒绝,并告知对方:你的提议已经有人提过了。这里的当前编号是每个议员在自己记事本上面记录的编号,他不断更新这个编号。整个议会不能保证所有议员记事本上的编号总是相同的。
现在议会开始运作,所有议员一开始记事本上面记录的编号都是0。有一个议员发了一个提议:将电费设定为1元/度。他首先看了一下记事本,嗯,当前提议编号是0,那么我的这个提议的编号就是1,于是他给所有议员发消息:1号提议,设定电费1元/度。其他议员收到消息以后查了一下记事本,哦,当前提议编号是0,这个提议可接受,于是他记录下这个提议并回复:我接受你的1号提议,同时他在记事本上记录:当前提议编号为1。发起提议的议员收到了超过半数的回复,立即给所有人发通知:1号提议生效!收到的议员会修改他的记事本,将1好提议由记录改成正式的法令,当有人问他电费为多少时,他会查看法令并告诉对方:1元/度。
假设总共有三个议员S1-S3,S1和S2同时发起了一个提议:1号提议,设定电费。S1想设为1元/度, S2想设为2元/度。结果S3先收到了S1的提议,于是他做了和前面同样的操作。紧接着他又收到了S2的提议,结果他一查记事本,咦,这个提议的编号小于等于我的当前编号1,于是他拒绝了这个提议:对不起,这个提议先前提过了。于是S2的提议被拒绝,S1正式发布了提议: 1号提议生效。S2向S1或者S3打听并更新了1号法令的内容,然后他可以选择继续发起2号提议。
zookeeper的介绍与安装
hadoop属于单节点,容易出现单点故障,所以我们使用zookeeper来解决这个问题。
Zookeeper是一个高效的分布式协调服务,可以提供配置信息管理、命名、分布式同步、集群管理、数据库切换等服务。它不适合用来存储大量信息,可以用来存储一些配置、发布与订阅等少量信息。
Zookeeper应用场景:Hadoop、Storm、消息中间件、RPC服务框架、分布式数据库同步系统都需要依赖Zookeeper做信息同步。
客户端发起事务请求,事务请求的结果在整个Zookeeper集群中所有机器上的应用情况是一致的。不会出现集群中部分机器应用了该事务,而存在另外一部分集群中机器没有应用该事务的情况。
在Zookeeper集群中的任何一台机器,其看到的服务器的数据模型是一致的。Zookeeper能够保证客户端请求的顺序,每个请求分配一个全局唯一的递增编号,用来反映事务操作的先后顺序。Zookeeper将全量数据保存在内存中,并直接服务于所有的非事务请求,在以读操作为主的场景中性能非常突出。
zookeeper集群的安装
Zookeeper节点个数(奇数)为3个。Zookeeper默认对外提供服务的端口号2181 。Zookeeper集群内部3个节点之间通信默认使用2888:3888。
1.下载安装包并在三台Linux节点中解压
#下载安装zookeper的tar包apache-zookeeper-3.5.7-bin.tar
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz
# 重新命名
mv apache-zookeeper-3.5.7-bin zookeeper-3.5.7
2.修改配置文件zookeeper中conf目录下的zoo_sample.cfg为zoo.cfg
#复制一份
cp zoo_sample.cfg zoo.cfg
3.修改三个zookeeper节点中的zoo.cfg文件,修改dataDir,添加
server.0=ip:2888:3888
server.1=ip:2888:3888
server.2=ip:2888:3888
#先创建一个存放数据的文件夹
mkdir data
#修改dataDir 数据目录
dataDir=/usr/local/soft/zookeeper-3.5.7/data
#添加
server.0=master:2888:3888
server.1=node1:2888:3888
server.2=node2:2888:3888
4.同步数据到其他两台节点
scp -r ./zookeeper-3.5.7 node1:pwd
scp -r ./zookeeper-3.5.7 node2:pwd
5.创建data目录并在3个zookeeper节点中data目录下分别创建myid文件,并分别添加内容0、1、2
# master节点上 在刚刚创建的data目录下
vim myid #加入0
#其他节点分别是1,2
6.在节点中配置环境变量(三个节点都需要配置)
vim /etc/profile
添加内容:(具体路径为ZooKeeper安装目录)
ZOOKEEPER_HOME=/usr/local/soft/zookeeper-3.5.7
export PATH=$ZOOKEEPER_HOME/bin:$PATH
生效:
source /etc/profile
7.三个节点中分别启动并查看状态
zkServer.sh start
zkServer.sh status
master状态

node1状态

node2状态

注意:各节点的Mode不是绝对的,是通过内部选举的。
Zookeeper中的进程:
Zookeeper集群中的节点,根据其身份特性分为leader、follower、observer。leader负责客户端writer类型的请求;follower负责客户端reader类型的请求,并参与leader选举;observer是特殊的follower,可以接收客户端reader请求,但是不会参与选举,可以用来扩容系统支撑能力,提高读取速度。
Zookeeper是一个基于观察者模式设计的分布式服务管理框架,负责存储和管理相关数据,接收观察者的注册。一旦这些数据的状态发生变化,zookeeper就负责通知那些已经在zookeeper集群进行注册并关心这些状态发生变化的观察者,以便观察者执行相关操作。
zookeeper命令
进入zookeeper客户端
# 使用命令
zkCli.sh
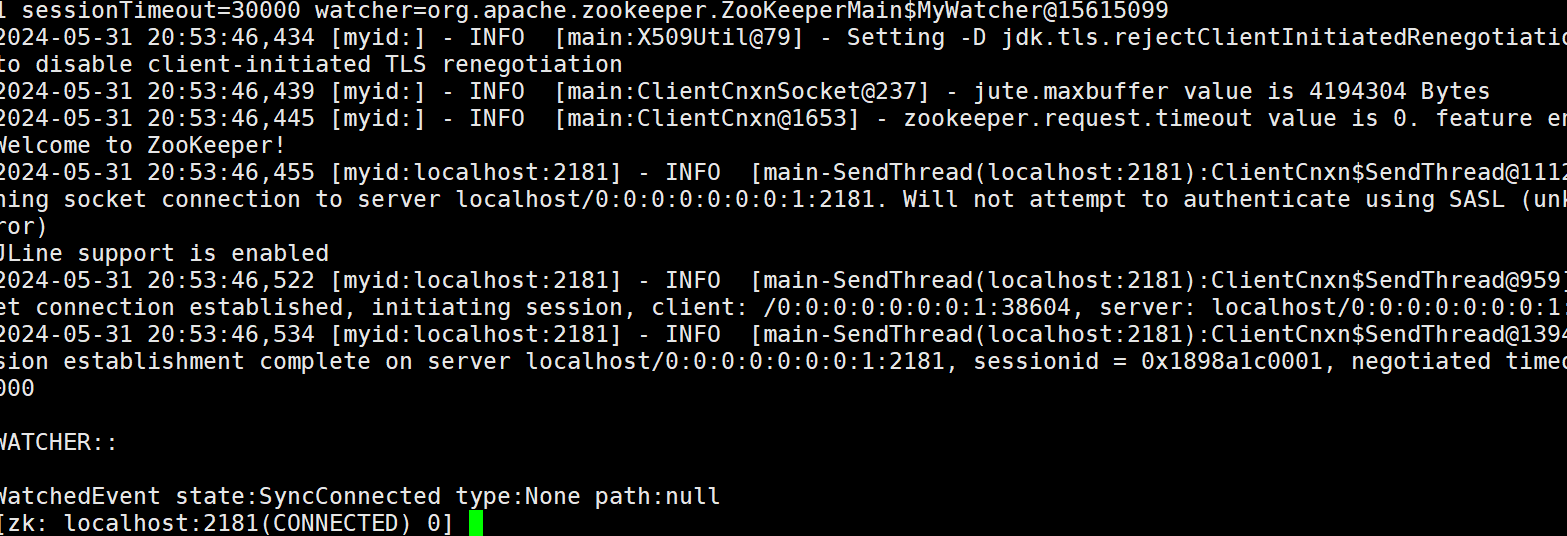
查看路径下的节点
ls path
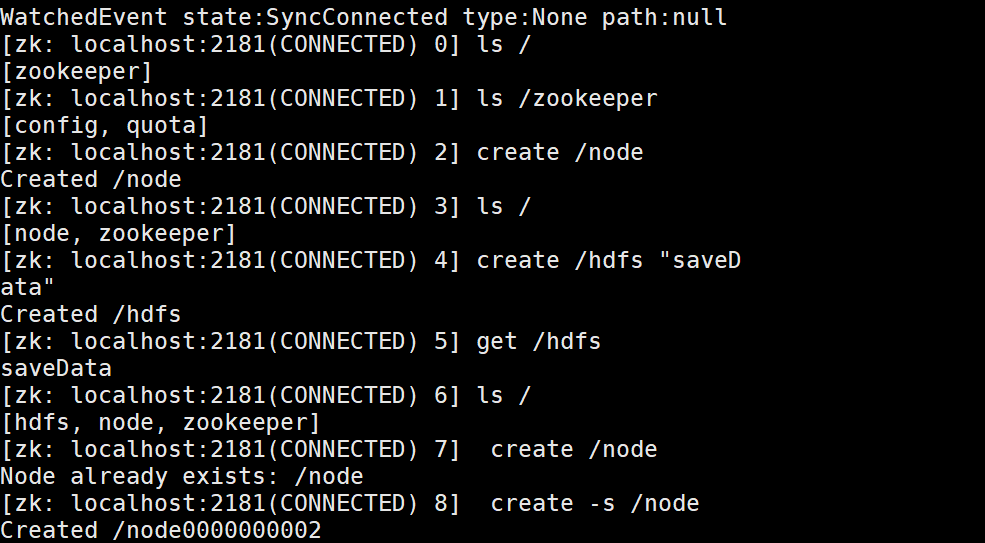
创建节点
create 节点 --> 创建普通节点
create 节点 节点数据 --> 创建普通节点并携带数据
create -s 节点 --> 创建节点并在节点名称后添加编号
create -e 节点 --> 创建临时节点
获取节点中的数据
get 节点
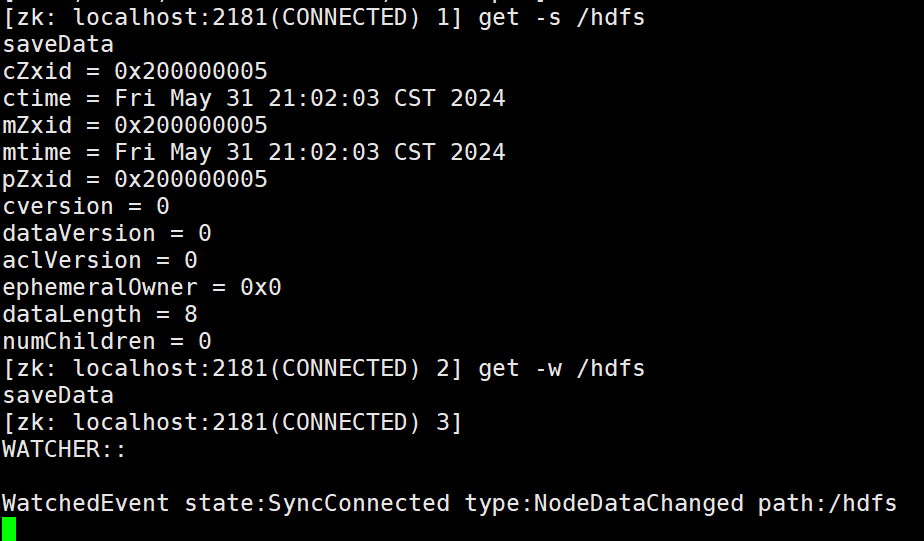
get -s 节点 查看节点中的数据并获取详细状态信息
get -w 节点 表示监听某个节点中的变化(只会触发一次效果)
设置节点中的数据
set 节点 数据 --> 给节点重新赋予数据
获取节点状态信息
stat 节点
删除节点
delete 节点 -- 可以删除一个不为空的节点(没有子节点)
deleteall 节点
退出客户端
quit
对于create -e 节点 :

随后断开连接,过一段时间后,tmp节点消失:
get- w 监控某个节点
此时重新打开一个master:启动zookeper :

监控到了变化:但是会触发一次。
zookeeperAPI的使用
在pom.xml中添加依赖:
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.5.7</version>
</dependency>
先测试Zookeeper连接:
public class Demo01ZooKeeperCon {
public static void main(String[] args) throws IOException, InterruptedException {
/*
* public ZooKeeper(String connectString, int sessionTimeout, Watcher watcher)
* connectString 连接信息 e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002"
* sessionTimeout 会话的超时时间 这里设置15s
* Watcher 一个接口
*运行发现:
* Zookeeper连接被获取,go!!!
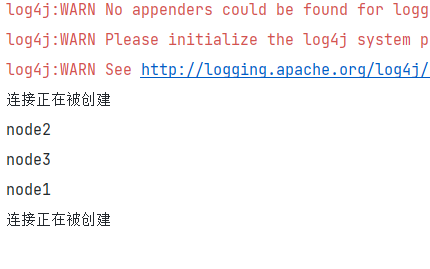
连接正在被创建
连接正在被创建
连接已关闭...
* TODO
* 解释: 1。由于"连接正在被创建"是在Watcher接口的匿名内部类中创建的
* process 方法被触发的时机是当Zookeeper连接发生变化时,才会触发process方法,当连接被创建或连接被关闭时process方法都会被创建。
* 2. System.out.println("Zookeeper连接被获取,go!!!"); 该代码会先执行的原因是:Zookeeper连接是一个异步调用的过程,相当于连接是一个线程操作的,
* 在main方法中是主线程,process放发是其他线程所调用的
* */
String con ="master:2181,node1:2181,node2:2181";
ZooKeeper zooKeeper = new ZooKeeper(con, 15 * 1000, new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println("连接正在被创建");
}
});
System.out.println("Zookeeper连接被获取,go!!!");
zooKeeper.close();
System.out.println("连接已关闭...");
}
}
实现功能:
①创建永久节点或临时节点
public class Demo02CreateNode {
public static void main(String[] args) throws IOException, InterruptedException, KeeperException {
/*
* 对于ZooKeeper在连接时要求本地必须有 master node1 node2的IP映射
* system32/drivers/etc/hosts
* 也可以只连接其中的一个节点
* */
String con ="master:2181,node1:2181,node2:2181";
ZooKeeper zooKeeper = new ZooKeeper(con, 15 * 1000, new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println("连接正在被创建");
}
});
/*
* public String create(final String path, byte data[], List<ACL> acl,
CreateMode createMode)
* path = /node 路径
* byte data[] 字节数组
* acl 权限 可以通过ZooDefs.Ids获取
* READ_ACL_UNSAFE 可读权限
* CREATOR_ALL_ACL 可写权限
* OPEN_ACL_UNSAFE 开放权限 可读可写
*createMode 创建节点的类型 枚举类
*PERSISTENT 持久化永久节点
* EPHEMERAL 临时节点
* CONTAINER 容器节点
* PERSISTENT_WITH_TTL 创建带有生命周期的永久节点
* */
// 永久节点
// zooKeeper.create("/api",
// "当前节点用于存储api中的数据".getBytes(StandardCharsets.UTF_8),
// ZooDefs.Ids.OPEN_ACL_UNSAFE,
// CreateMode.PERSISTENT);
// 临时节点 会话关闭后节点消失
zooKeeper.create("/api_tmp",
"当前节点用于存储api中的数据".getBytes(StandardCharsets.UTF_8),
ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL);
Thread.sleep(5*1000);
zooKeeper.close();
}
}
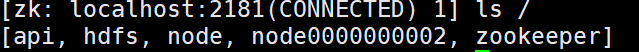

②获取节点数据
public class Demo03GetData {
public static void main(String[] args) throws IOException, InterruptedException, KeeperException {
String con ="master:2181,node1:2181,node2:2181";
ZooKeeper zooKeeper = new ZooKeeper(con, 15 * 1000, new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println("连接正在被创建");
}
});
/*
* getData: public byte[] getData(String path, boolean watch, Stat stat)
* path 路径
* boolean watch 是否监听
* stat 状态
*
* */
String path = "/api";
Stat stat = zooKeeper.exists(path, false);
// System.out.println(stat); 节点不存在时—>null
if (stat!=null) {
byte[] data = zooKeeper.getData(path, false, stat);
String dataStr = new String(data);
System.out.println(dataStr);
}
zooKeeper.close();
}
}

③获取当前节点的子节点
// 先在/api下创建几个节点
public class Demo04GetChild {
public static void main(String[] args) throws InterruptedException, IOException, KeeperException {
/*获取当前节点的子节点*/
String con ="master:2181,node1:2181,node2:2181";
ZooKeeper zooKeeper = new ZooKeeper(con, 15 * 1000, new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println("连接正在被创建");
}
});
// getChildren 方法
List<String> children = zooKeeper.getChildren("/api", false);
for (String child : children) {
System.out.println(child);
}
zooKeeper.close();
}
}
④监听节点变化
public class Demo05GetChange {
public static void main(String[] args) throws InterruptedException, IOException, KeeperException {
/*获取当前节点的子节点*/
String con ="master:2181,node1:2181,node2:2181";
ZooKeeper zooKeeper = new ZooKeeper(con, 15 * 1000, new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println("连接正在被创建");
}
});
watchData(zooKeeper);
watchChild(zooKeeper);
zooKeeper.close();
}
// 监听数据
public static void watchData(ZooKeeper zooKeeper) throws InterruptedException, KeeperException {
String path = "/api";
Stat exists = zooKeeper.exists(path, false);
byte[] data = zooKeeper.getData(path, new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println("发生变化,触发了监听");
}
}, exists);
System.out.println(new String(data));
// Watcher创建了一个新线程,但是主线程结束,从线程也会结束达不到监听效果所以:
Thread.sleep(10*1000);
}
// 监听节点
public static void watchChild(ZooKeeper zooKeeper) throws InterruptedException, KeeperException {
String path = "/api";
List<String> children = zooKeeper.getChildren(path, new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println("子节点发生变化...");
}
});
for (String child : children) {
System.out.println(child);
}
Thread.sleep(10*1000);
zooKeeper.close();
}
}
在虚拟机中对 /api 节点赋予数据:
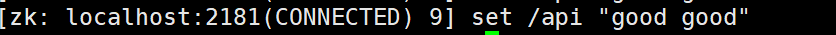
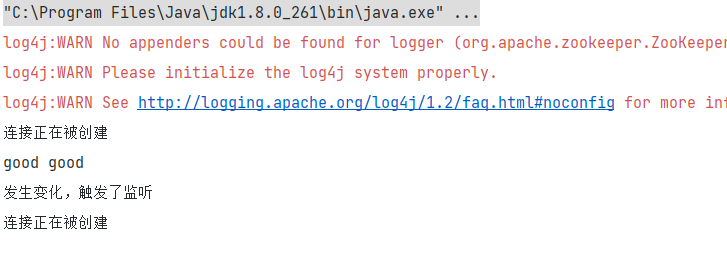
在/api下新创建一个节点:


⑤删除节点
public class Demo06DeleteNode {
public static void main(String[] args) throws IOException, InterruptedException, KeeperException {
String con ="master:2181,node1:2181,node2:2181";
ZooKeeper zooKeeper = new ZooKeeper(con, 15 * 1000, new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println("连接正在被创建");
}
});
// 如果要删除最新版本 就是-1
// 不能删除不为空的目录
zooKeeper.delete("/node0000000002",-1);
zooKeeper.close();
}
// 如何完成一个deleteAll操作? 循环遍历节点下的节点,数据。。。
}
删除node0000000002节点:
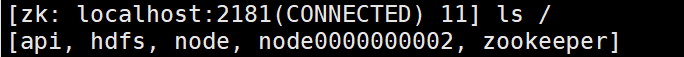

基于ZooKeeper构建HA
什么是HA?
HDFS的HA,指的是在一个集群中存在两个NameNode,分别运行在独立的物理节点上。在任何时间点,只有一个NameNodes是处于Active状态,另一种是在Standby状态。 Active NameNode负责所有的客户端的操作,而Standby NameNode用来同步Active NameNode的状态信息,以提供快速的故障恢复能力。
为了保证Active NN与Standby NN节点状态同步,即元数据保持一致。除了DataNode需要向两个NN发送block位置信息外,还构建了一组独立的守护进程”JournalNodes”,用来同步Edits信息。当Active NN执行任何有关命名空间的修改,它需要持久化到一半以上的JournalNodes上。而Standby NN负责观察JNs的变化,读取从Active NN发送过来的Edits信息,并更新自己内部的命名空间。一旦ActiveNN遇到错误,Standby NN需要保证从JNs中读出了全部的Edits,然后切换成Active状态。使用HA的时候,不能启动SecondaryNameNode,会出错。
HA步骤
配置之前先拍摄快照(重要)
快照名称设置为 Zookeeper
-
配置免密登录
# 在node1节点执行 ssh-keygen -t rsa # 三次回车之后 ssh-copy-id node1 ssh-copy-id node2 ssh-copy-id master -
关闭所有Hadoop
# 关闭Hadoop stop-all.sh -
在core-site.xml中添加如下配置:
-- 注意需要将原先的9000修改成cluster <property> <name>fs.defaultFS</name> <!-- <value>hdfs://master:9000</value> --> <value>hdfs://cluster</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>master:2181,node1:2181,node2:2181</value> </property> -
在hdfs-site.xml中添加如下配置:
<!-- //以下为HDFS HA的配置// --> <!-- 指定hdfs的nameservices名称为mycluster --> <property> <name>dfs.nameservices</name> <value>cluster</value> </property> <!-- 指定cluster的两个namenode的名称分别为nn1,nn2 --> <property> <name>dfs.ha.namenodes.cluster</name> <value>master,node1</value> </property> <!-- 配置nn1,nn2的rpc通信端口 --> <property> <name>dfs.namenode.rpc-address.cluster.master</name> <value>master:8020</value> </property> <property> <name>dfs.namenode.rpc-address.cluster.node1</name> <value>node1:8020</value> </property> <!-- 配置nn1,nn2的http通信端口 --> <property> <name>dfs.namenode.http-address.cluster.master</name> <value>master:9870</value> </property> <property> <name>dfs.namenode.http-address.cluster.node1</name> <value>node1:9870</value> </property> <!-- 指定namenode元数据存储在journalnode中的路径 --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://master:8485;node1:8485;node2:8485/cluster</value> </property> <!-- 指定journalnode日志文件存储的路径 --> <property> <name>dfs.journalnode.edits.dir</name> <value>/usr/local/soft/hadoop-2.7.6/data/journal</value> </property> <!-- 指定HDFS客户端连接active namenode的java类 --> <property> <name>dfs.client.failover.proxy.provider.cluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!-- 配置隔离机制为ssh --> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <!-- 指定秘钥的位置 --> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <!-- 开启自动故障转移 --> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <!-- 关闭权限验证 --> <property> <name>dfs.permissions.enabled</name> <value>false</value> </property> -
在hadoop-env.sh添加环境变量配置
export HDFS_ZKFC_USER=root export HDFS_JOURNALNODE_USER=root -
上传配置文件至master的 /usr/local/soft/hadoop-3.1.3/etc/hadoop 并分发其他节点
cd /usr/local/soft/hadoop-3.1.3/etc/hadoop scp hdfs-site.xml root@node1:`pwd` scp hdfs-site.xml root@node2:`pwd` scp core-site.xml root@node1:`pwd` scp core-site.xml root@node2:`pwd` scp hadoop-env.sh root@node1:`pwd` scp hadoop-env.sh root@node2:`pwd` -
删除所有节点中的tmp目录
# 在master node1 node2 节点删除 rm -rf /usr/local/soft/hadoop-3.1.3/data -
启动Zookeeper三台都需要启动
zkServer.sh start zkServer.sh status -
配置node1、node2 环境变量添加 HADOOP_HOME
vim /etc/profile # 添加: # HADOOP_HOME export HADOOP_HOME=/usr/local/soft/hadoop-3.1.3 export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH source /etc/profile -
启动JN 存储hdfs元数据
三台JN上执行 启动命令: hadoop-daemon.sh start journalnode -
格式化 在一台NN上执行(在master上执行)
hdfs namenode -format # 并启动NameNode hadoop-daemon.sh start namenode -
执行同步 没有格式化的NN上执行 在另外一个namenode上面执行(在node1上执行)
hdfs namenode -bootstrapStandby -
格式化ZK 在已经启动的namenode上面执行(在master上执行)
# 保证Zookeeper启动状态 hdfs zkfc -formatZK -
启动整个集群
start-all.sh
master成为备用节点

如果想要使用master节点,可以直接杀死node1下的NameNode进程。这样master就会变成active状态。此时就可以做上传数据等操作呢。再想启动node1可以使用:
hadoop-daemon.sh start namenode
注意:学习之后,回退到快照。

















 1647
1647

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









